优化日志分析店铺推荐方案:用户范围的精确度以及ES与MySQL的查询效率差异
目录
一、旧版方案
二、分析
修改方案
(一)问题1
(二)问题2
三、具体流程图
四、代码实现
一、旧版方案
二、分析
旧版方案的分析数据是通过查询近三天的全部日志数据,再查询近30天的全部日志数据,建立用户与日志的Map映射后逐一遍历进行分析。
这样会导致几个问题:
一是推荐用户对象范围不精确,应该推荐给频繁登录的用户,但旧版方案为平衡计算开销,只选择了近三天登陆过的用户。
二是分析的数据量级过大,可能导致oom,因此旧版方案采用了分片并行处理的方案,但是也正因如此导致耗时过大。
因此,我们需要进行修改。
修改方案
(一)问题1
首先针对第一个问题,我们应该记录用户一个月内登录的天数,当天数到达一定值的时候,将其标记为热点用户,作为日志分析的对象。
那如何记录呢,很多同学可能会想到使用Redis的BitMap数据结构,因为其占据内存小。
但我们并没有采用位图,而是采用的字符串,因为我们并不需要知道用户哪些天是登陆过的,我们只需要知道用户登录了几天就好了。
由于这是小程序项目,用户登陆数据是会存储到本地的,所以用户并不会每天都调用登录接口,我们应该寻找别的办法。
既然我们分析的日志是用户进店时产生的日志,那不妨我们将用户当天产生的第一次进店行为视作登录行为,在第一次进店时在Redis存储对应的数据,键名为UserId+当天日期,TTL为离当天23:59:59时刻的时间戳,每次进店都进行SETNX操作,这样就只有第一次进店会成功缓存到Redis,并且在缓存的同时对该用户该月的登陆天数Key做自增操作。以上都放在Lua脚本中保障原子性。
如此这般,我们就只需要获取该月登陆天数超过一定值的用户Id即可。
(二)问题2
对于第二个问题,旧版方案是将热数据存储到ES,但其实对于10w量级来说,ES和MySQL的效率差别并不大,但是如果MySQL建立了索引的情况下,反而MySQL的效率更高。
所以在修改方案中,我们将热数据存放到了MySQL,而将冷数据存到ES进行备份。
旧版是建立用户id与日志的映射关系,修改后改为了用户id与当月进过的店铺id的映射关系,节省了空间,而且操作的效率也大大提高。
三、具体流程图
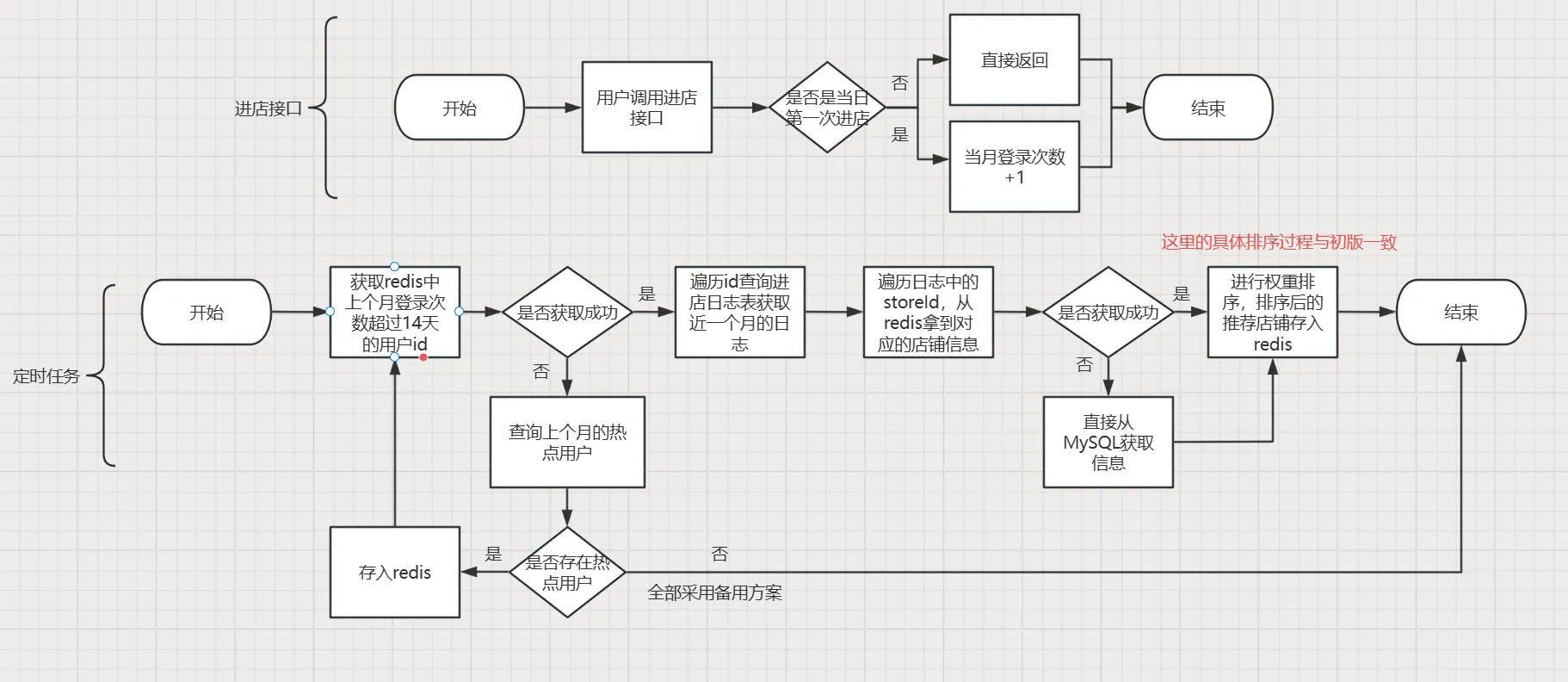
四、代码实现
-- 用户IDlocal uid = ARGV[1]-- 当前月份 格式 \"YYYY:MM\"local nowMonth = ARGV[2]-- 当前日期 格式 \"YYYYmmDD\"local nowDate = ARGV[3]-- 构建 Keylocal dateKey = \'report:enterStoreDaysInMonth:\' .. nowDate .. \':\' .. uidlocal monthKey = \'report:enterStoreDaysInMonth:\' .. nowMonth .. \':\' .. uid-- 判断是否为当日首次进店if redis.call(\'SETNX\', dateKey, 1) == 1 then -- 获取当前redis服务器时间 local time = redis.call(\'TIME\') local currentSeconds = tonumber(time[1]) -- 计算当天结束时间戳(即23:59:59的时间戳) local endOfDay = currentSeconds - (currentSeconds % 86400) + 86399 -- 计算剩余过期时间 local ttl = endOfDay - currentSeconds -- 如果刚好再到23:59:59,则设置为1秒后过期 if ttl < 0 then ttl = 1 end -- 设置过期时间 redis.call(\'EXPIRE\', dateKey, ttl) -- 增加当月累计进店天数 redis.call(\'INCR\', monthKey)end@RequiredArgsConstructor@Slf4j@Componentpublic class ReportStoreRecommendTask { private final RestHighLevelClient restHighLevelClient; private final StringRedisTemplate stringRedisTemplate; private final Top10MarkStoreMapper top10MarkStoreMapper; private final StoreMapper storeMapper; private final EnterStoreUserLogMapper enterStoreUserLogMapper; private final ThreadPoolExecutor threadPoolExecutor; @XxlJob( value = \"store-recommend\") public void processStoreRecommend() { LocalDateTime start = LocalDateTime.now(); log.info(\"开始执行用户进店日志分析,执行时间:{}\", start); // 获取热门榜的作品,只拿前4个 List top10MarkStoreList = top10MarkStoreMapper.selectList(new QueryWrapper() .orderByDesc(\"mark_score\") .last(\"LIMIT 4\")); // 如果db没有数据则需要抛出异常 if (top10MarkStoreList == null || top10MarkStoreList.isEmpty()){ throw new Top10MarkStoreException(MessageConstant.TOP10_MARK_IS_NULL); } // 打乱顺序 Collections.shuffle(top10MarkStoreList); List top4MarkStoreList = new ArrayList(); // 添加排序 int index = 1; for(Top10MarkStore markStore : top10MarkStoreList){ Store store = storeMapper.selectById(markStore.getStoreId()); Top10MarkStoreVO vo = BeanUtil.copyProperties(store, Top10MarkStoreVO.class); vo.setStoreId(markStore.getStoreId()); vo.setMarkScore(markStore.getMarkScore()); vo.setSort(index++); top4MarkStoreList.add(vo); } // 备用方案 String cacheAllKey = STORE_RECOMMEND_ONE + \"all\"; // 删除所有旧数据(包括用户的推荐数据) String all = STORE_RECOMMEND_ONE + \"*\"; Set keys = stringRedisTemplate.keys(all); if (keys != null && !keys.isEmpty()) { stringRedisTemplate.delete(keys); } // 缓存数据 List allStoreJsons = top4MarkStoreList.stream() .map(top4MarkStoreVO -> JSON.toJSONString(top4MarkStoreVO, SerializerFeature.WriteDateUseDateFormat)) .toList(); stringRedisTemplate.opsForList().rightPushAll(cacheAllKey, allStoreJsons); // 检查当前redis有没有上个月热点用户的id集合 String lastMoth = LocalDateTime.now().minusMonths(1).format(DateTimeFormatter.ofPattern(\"yyyy:MM\")); String idsKey = RedisConstant.MONTH_HOT_USER_KEY + lastMoth; // 如果不存在,则查询上个月的热点用户 if (Boolean.FALSE.equals(stringRedisTemplate.hasKey(idsKey))) { // 创建ids集合 Set hotUserIds = new HashSet(); String hotUserKey = RedisConstant.REPORT_ENTER_STORE_DAYS_IN_MONTH_KEY + lastMoth + \":*\"; // 若对应的值大于等于14,则加入集合 Set hotUserKeys = stringRedisTemplate.keys(hotUserKey); if (hotUserKeys != null && !hotUserKeys.isEmpty()) { for (String key : hotUserKeys) { if(Integer.parseInt(Objects.requireNonNull(stringRedisTemplate.opsForValue().get(key))) >= 14) { String[] split = key.split(\":\"); String userId = split[split.length - 1]; hotUserIds.add(userId); } } // 缓存到redis stringRedisTemplate.opsForSet().add(idsKey, hotUserIds.toArray(new String[0])); } } // 读取缓存 Set hotUserIds = stringRedisTemplate.opsForSet().members(idsKey); // ids为空则代表上个月没有热点用户,则都采用备用方案即可 if (hotUserIds == null || hotUserIds.isEmpty()) { return; } // 分批查询 List userIds = hotUserIds.stream().map(Long::valueOf).collect(Collectors.toList()); List<List> partitionedUserIds = ThreadPoolUtil.slicingData(userIds, 400); List<Map> logList = new CopyOnWriteArrayList(); // 批次并行处理 partitionedUserIds.forEach(batch -> { List<CompletableFuture> futures = new ArrayList(); batch.forEach(userId -> { CompletableFuture future = CompletableFuture.runAsync(() -> { List<Map> batchResult = enterStoreUserLogMapper.selectMaps(new QueryWrapper() .select(\"user_id\", \"store_id\") .in(\"user_id\", Collections.singletonList(userId)) .ge(\"create_time\", LocalDateTime.now().minusMonths(1))); logList.addAll(batchResult); }, threadPoolExecutor); futures.add(future); }); ThreadPoolUtil.allFuturesWait(futures); }); // 分组 Map<Long, List> userIdAndStoreIds = logList.stream() .collect(Collectors.groupingBy( map -> ((Number) map.get(\"user_id\")).longValue(), Collectors.mapping( map -> ((Number) map.get(\"store_id\")).longValue(), Collectors.toList() ) )); // 权重系数配置 final double STORE_WEIGHT = 0.5; final double CATEGORY_WEIGHT = 0.3; final double CLASSIFICATION_WEIGHT = 0.2; // 将用户数据分片(每 500 用户一批) List<Map.Entry<Long, List>> userEntries = new ArrayList(userIdAndStoreIds.entrySet()); List<List<Map.Entry<Long, List>>> batches = ThreadPoolUtil.slicingData(userEntries, 500); // 批次并行处理 batches.forEach(batch -> { List<CompletableFuture> futures = new ArrayList(); batch.forEach(entry -> { CompletableFuture future = CompletableFuture.runAsync(() -> { Long userId = entry.getKey(); List storeIds = entry.getValue(); try { analyseLog(userId, storeIds, STORE_WEIGHT, CATEGORY_WEIGHT, CLASSIFICATION_WEIGHT, top4MarkStoreList); }catch (Exception e){ // 即使有一个用户进店日志分析失败,也不影响其他用户的分析 log.error(\"用户id为{}的进店日志分析失败,失败时间:{}\",userId,LocalDateTime.now(),e); } }, threadPoolExecutor); futures.add(future); }); // 等待当前批次完成 ThreadPoolUtil.allFuturesWait(futures); }); log.info(\"用户进店日志分析结束,结束时间:{},花费时间:{}s\", LocalDateTime.now(), Duration.between(start, LocalDateTime.now()).getSeconds()); } private void analyseLog(Long userId, List storeIds, double STORE_WEIGHT, double CATEGORY_WEIGHT, double CLASSIFICATION_WEIGHT, List top4MarkStoreVOList) throws Exception { // 记录店铺、分区、分类的次数 Map storeCountMap = new HashMap(); Map categoryCountMap = new HashMap(); Map classificationCountMap = new HashMap(); // 记录店铺对应的分类和分区 Map storeCategoryMap = new HashMap(); Map storeClassificationMap = new HashMap(); // 统计基础数据 storeIds.forEach(id -> { // 获取店铺对应的分类和分区 String storeKey = RedisConstant.STORE_ALL_STORE_LIST_KEY + id; Store store = null; if(Boolean.FALSE.equals(stringRedisTemplate.hasKey(storeKey))){ // 如果redis没有店铺信息,则从mysql中查询 store = storeMapper.selectById(id); }else { // 如果redis有店铺信息,则从redis中查询并转化成对象 String storeJson = stringRedisTemplate.opsForValue().get(storeKey); store = JSONUtil.toBean(storeJson, Store.class); } // 店铺不存在则记录日志,并跳过该次循环,不影响后续操作 if(store == null){ log.error(\"店铺id为{}的店铺不存在,请检查数据库\",id); return; } Integer categoryId = store.getCategoryId(); Integer classificationId = store.getStoreClassificationId(); // 统计次数 storeCountMap.merge(id, 1, Integer::sum); categoryCountMap.merge(categoryId, 1, Integer::sum); classificationCountMap.merge(classificationId, 1, Integer::sum); // 记录店铺元数据(首次出现时记录) storeCategoryMap.putIfAbsent(id, categoryId); storeClassificationMap.putIfAbsent(id, classificationId); }); // 计算店铺得分 List scoreList = new ArrayList(); storeCountMap.forEach((storeId, count) -> { // 获取店铺对应的分类和分区 Integer categoryId = storeCategoryMap.get(storeId); Integer classificationId = storeClassificationMap.get(storeId); //获取店铺实体 Store store = storeMapper.selectById(storeId); StoreVO storeVO = new StoreVO(); BeanUtils.copyProperties(store, storeVO); // 获取对应计数 int categoryCount = categoryCountMap.getOrDefault(categoryId, 0); int classificationCount = classificationCountMap.getOrDefault(classificationId, 0); // 计算加权得分 double score = STORE_WEIGHT * count + CATEGORY_WEIGHT * categoryCount + CLASSIFICATION_WEIGHT * classificationCount; scoreList.add(new StoreScore(storeId, storeVO, score)); }); // 按得分降序排序 scoreList.sort((a, b) -> Double.compare(b.getScore(), a.getScore())); // 生成推荐列表 List recommendedStores = new ArrayList(scoreList.stream() .limit(4) .map(StoreScore::getStoreVO) .toList()); // 去重(当个性化推荐和热门榜补充时可能会出现重复店铺) Set existStoreIds = recommendedStores.stream() .map(storeVO -> storeVO.getId().longValue()) .collect(Collectors.toSet()); String cacheKey = STORE_RECOMMEND_ONE + userId; // 将去重后的店铺数据存到集合里 List storeJsons = new ArrayList(); for(int i = 0; i < recommendedStores.size(); i++){ StoreVO store = recommendedStores.get(i); Top4MarkStoreVO top4MarkStoreVO = new Top4MarkStoreVO(); BeanUtils.copyProperties(store, top4MarkStoreVO); top4MarkStoreVO.setStoreId(Long.valueOf(store.getId())); top4MarkStoreVO.setMarkScore(store.getStoreRating()); top4MarkStoreVO.setSort(i + 1); storeJsons.add(JSONUtil.toJsonStr(top4MarkStoreVO)); } // 补充热门店铺 int count = 4 - recommendedStores.size(); for (int i = 0; i 0; i++) { Top10MarkStoreVO candidate = top4MarkStoreVOList.get(i); if (!existStoreIds.contains(candidate.getStoreId())) { candidate.setSort(recommendedStores.size() + i + 1); storeJsons.add(JSONUtil.toJsonStr(candidate)); count--; } } // 缓存数据 stringRedisTemplate.opsForList().rightPushAll(cacheKey, storeJsons); }}如果你有更好的方案,请在评论区告诉我!
~码文不易,点个赞再走吧~

