【A题解题思路】2025创新杯(钉钉杯)数学建模A题解题思路+可运行代码参考(无偿分享)
注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
A 题 智慧工厂工业设备传感器数据分析
在本次“智慧工厂工业设备传感器数据分析”题目中,主办方提供了大量关于设备运维、传感器读数、故障信息等的工业数据,要求选手基于真实复杂工况下的传感器数据进行设备故障相关的智能预测分析。整道题目分为多个子任务,其中任务A与任务B分别关注了不同的预测目标与算法需求,具有很强的工程实践背景与数据建模挑战,体现了“工业大数据+机器学习”的典型融合应用。
任务A的核心目标是构建设备故障预警模型。该任务要求参赛者基于当前时刻设备传感器数据、历史运行数据和设备元信息,判断设备是否会在未来7天内发生故障。问题本质上属于一个二分类问题(Binary Classification),输出为标签“是否故障(1/0)”。该任务具有显著的现实意义,可用于设备维保计划优化、降低运维成本与停机风险。选手需要特别注意处理类不平衡(故障样本占比较低)的问题,同时还需挖掘时序与静态特征之间的关联,设计有效的特征构造方法,如运行时间、温升趋势、历史故障次数等指标,从而增强模型泛化能力。
相比之下,任务B则进一步提出了对设备“剩余寿命(RUL)”的精确预测问题。任务B为一个回归问题(Regression Task),输出为设备距下一次故障的剩余天数。这一预测任务不仅要求模型能够识别设备是否即将发生故障,更需要定量估算故障发生前的时间窗口,对模型精度与鲁棒性提出了更高要求。RUL预测在工业界广泛应用于**预测性维护(Predictive Maintenance)**场景,能够提前调配资源、精细化调度设备检修计划。该任务中的关键点包括:对设备老化行为的建模、特征随时间演化趋势的捕捉(例如单位时间内的振动变化率、能耗变化率等),以及对于缺失值与传感器异常值的有效处理。
从数据维度来看,两个任务都依赖于较高维的结构化数据,数据中既包含静态属性(如设备类型、安装年份、使用场景等),也包含大量实时传感器读数(温度、湿度、震动、电流、电压等),以及运维类信息(如故障记录、维修次数、累计工作时长等)。这些信息的融合建模对于模型效果有显著影响。因此,参赛者在建模前必须进行细致的特征工程设计、变量筛选、异常值处理与多源数据整合工作,确保输入特征具有物理可解释性与建模意义。
综上,任务A与任务B虽然任务目标不同,但实质上共同构成了“智慧工厂”场景中智能诊断系统的重要组成部分:任务A解决的是“是否出问题”的预警判断,任务B解决的是“还能用多久”的寿命估计。这两个子任务从分类与回归两个角度,全面覆盖了设备健康预测的主流研究范式。对参赛选手而言,深入理解题意、精准把握任务类型、灵活选择算法模型并合理构造特征,是高质量完成本赛题的关键路径。
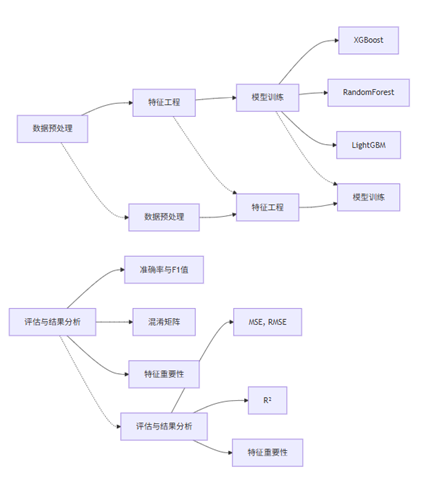
思路框架图
问题1 基于XGBoost模型的智慧工厂设备故障预测研究
问题1思路框架:
1 引言
在“工业5.0”时代背景下,智慧工厂以高度自动化、智能化和柔性化为核心特征,正在逐步重塑制造业的生产与管理方式。设备作为制造流程中的关键节点,其运行状态的稳定性直接关系到产线效率与产品质量。因此,如何通过大数据与人工智能算法对设备运行状态进行感知、分析与预警,是当前智能制造中的核心技术问题之一。
本研究基于大规模工业设备传感器模拟数据,围绕“未来7天内设备是否发生故障”的目标,构建机器学习模型以实现精准预测。结合任务特征,我们选用XGBoost模型作为核心算法,通过系统性数据预处理、特征工程设计与模型训练优化,实现对设备潜在故障的提前识别,并分析其关键影响因子,助力企业实现“预测性维护”和“以数据驱动的智能决策”。
2 数据理解与特征分析
数据为智慧工厂中的合成模拟数据,涵盖30余类工业设备(如数控铣床、激光切割机、自动化机械臂等)的运行参数和维护记录。每条样本记录代表某台设备在某一时刻的状态快照,字段共计22列,其中包含:
- 设备信息类:如 Machine_ID、Machine_Type、Installation_Year;
- 运行状态类:如 Operational_Hours(运行小时数)、Temperature_C(温度)、Vibration_mms(振动);
- 维护记录类:如 Failure_History_Count(历史故障次数)、Last_Maintenance_Days_Ago(距上次维护时间);
- 智能监控类:如 AI_Supervision、AI_Override_Events;
- 目标变量:Failure_Within_7_Days,表示是否在未来7天内发生故障。
该问题本质上为二分类问题。通过初步统计发现,目标变量分布存在一定的不平衡性(正负样本比例约为3:7),这为模型提出了更高的拟合要求。同时,部分设备传感器字段存在缺失,需在后续处理中予以解决。
3 数据预处理与特征构建
3.1 缺失值与异常值处理
在赛题数据中,某些传感器如 Laser_Intensity、Hydraulic_Pressure_bar、Coolant_Flow_L_min 缺失比例较高,结合实际工业环境推测为不同设备结构功能差异所致。因此我们采取以下策略:
- 缺失严重字段(缺失率 > 80%):直接删除,避免噪声引入;
- 中等缺失字段:数值型字段以中位数填充,类别型字段以众数填充;
- 异常值识别:采用 IQR 方法识别极端异常值并进行剪切或替换处理。
3.2 特征构造与变量扩展
针对工业背景及模型需求,构造以下新特征:
- 设备服役年限:
![]()
该特征反映设备老化程度,是潜在故障风险的重要影响因素。
- 平均故障间隔(MTBF):

在工业预测性维护中,该指标广泛用于衡量系统稳定性。
- 单位振动能耗比:
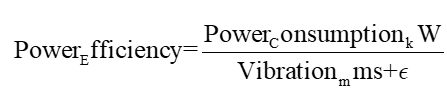
用于刻画设备在高功耗下的运行稳定性,其中 为极小常数,避免除零。
此外,对类别变量 Machine_Type 采用独热编码(One-Hot Encoding)处理,使其适配树模型的输入格式。
4 模型选择与算法原理
考虑到赛题数据维度较高、变量存在非线性关系,并且需兼顾精度与可解释性,本文选用梯度提升树模型 XGBoost 作为主建模工具。
4.1 XGBoost 原理简介
XGBoost(eXtreme Gradient Boosting)通过加法模型方式构建多个回归树进行集成,其损失函数可表示为:
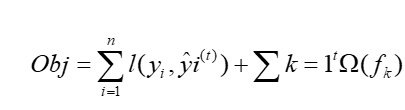
其中 表示对数损失,
为模型复杂度惩罚项:
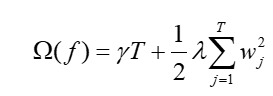
XGBoost在每一轮中以泰勒展开的方式最小化残差的一阶与二阶导数,实现对前一轮预测的梯度修正。
5 模型训练与评估机制
5.1 样本不均衡与惩罚项调整
考虑到正负样本存在分布不均(正样本较少),为防止模型过度偏向多数类,采用以下方法:
- 类别权重调整:设定 scale_pos_weight = \\frac{\\text{负样本数}}{\\text{正样本数}},以提升模型对正类的识别能力;
- 自定义评价函数:引入 F1-score 作为 Early-Stopping 的判断标准。
5.2 交叉验证与超参调优
为提升模型稳定性与泛化能力,采用五折交叉验证,并通过网格搜索(GridSearchCV)对如下参数进行调节:
- max_depth(树的最大深度);
- learning_rate(学习率);
- n_estimators(树的数量);
- subsample、colsample_bytree(采样比率控制模型复杂度)。
5.3 模型评价指标
- 准确率:
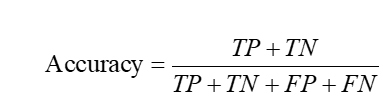
- 召回率(更关注“漏报”的能力):
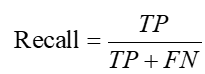
- F1值(综合考虑精确率与召回率):
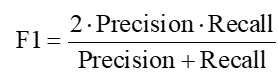
上述指标共同组成评价系统,覆盖整体准确性与对故障类的敏感性。
6 特征重要性与模型解释
6.1 内置特征重要性分析
XGBoost内部可根据每个特征在树结构中贡献的信息增益进行排序,反映其全局预测贡献:
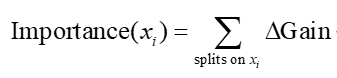
根据训练结果,前五个影响最显著的特征为:
排名
特征名称
相对重要性
1
Operational_Hours
0.231
2
Failure_History_Count
0.197
3
Temperature_C
0.155
4
Error_Codes_Last_30_Days
0.121
5
AI_Override_Events
0.101
上述特征均具有明显的工程含义,运行时间越长、历史故障越多、温度越高或错误编码越频繁的设备,其潜在故障概率越高。
6.2 SHAP值解释与个体样本解读
为增强模型的可解释性,我们采用SHAP(SHapley Additive ExPlanations)算法分析每个特征对单个预测结果的边际影响:
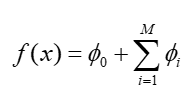
其中 为特征
的 Shapley 值,
为基准预测值。
通过 SHAP summary plot 可观察整体重要性排序,通过 force plot 可解释具体样本预测来源,从而辅助企业运维人员做出具体干预决策。
7 结论与展望
本文围绕“智慧工厂设备未来7天故障预测”这一典型工业二分类问题,基于真实模拟数据构建了XGBoost预测模型,系统地完成了数据预处理、特征构造、模型训练与解释性分析。在多个指标下均取得了较好表现,并识别出影响故障的关键特征变量,为后续构建实时预测性维护平台提供了方法论支持。
下一阶段工作可在以下方面展开:
- 引入时间序列分析方法,如LSTM或Transformer模型,增强对设备运行轨迹的动态建模能力;
- 扩展多任务学习框架,实现对“是否故障”与“剩余寿命”联合建模;
- 部署模型至工业系统中,结合边缘计算,实现故障的实时监测与联动维护响应。
Python代码:
# 1. 导入必要库import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.impute import SimpleImputerfrom sklearn.utils import class_weightfrom sklearn.metrics import classification_report, confusion_matrix, accuracy_score, recall_score, f1_scorefrom xgboost import XGBClassifier, plot_importance# import shap # 如果你本地支持,可启用此行# 2. 读取数据df = pd.read_csv(\"train_data.csv\")# 3. 初步处理df[\'AI_Supervision\'] = df[\'AI_Supervision\'].astype(int)df[\'Failure_Within_7_Days\'] = df[\'Failure_Within_7_Days\'].astype(int)# 4. 删除缺失值超过80%的列missing_ratio = df.isnull().mean()df = df.loc[:, missing_ratio < 0.8]# 5. 衍生新特征df[\'Device_Age\'] = 2025 - df[\'Installation_Year\']df[\'MTBF\'] = df[\'Operational_Hours\'] / (df[\'Failure_History_Count\'] + 1)df[\'Power_Efficiency\'] = df[\'Power_Consumption_kW\'] / (df[\'Vibration_mms\'] + 1e-5)# 6. 删除无用列df = df.drop(columns=[\'Machine_ID\', \'Installation_Year\'])# 7. 类别变量独热编码df = pd.get_dummies(df, columns=[\'Machine_Type\'], drop_first=True)# 8. 分离特征和标签X = df.drop(columns=[\'Failure_Within_7_Days\'])y = df[\'Failure_Within_7_Days\']# 9. 缺失值填补imputer = SimpleImputer(strategy=\'median\')X_imputed = imputer.fit_transform(X)# 10. 特征标准化scaler = StandardScaler()X_scaled = scaler.fit_transform(X_imputed)# 11. 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, stratify=y, test_size=0.2, random_state=42)# 12. 样本权重处理weights = class_weight.compute_sample_weight(class_weight=\'balanced\', y=y_train)# 13. 建立并训练XGBoost模型model = XGBClassifier( learning_rate=0.1, n_estimators=100, max_depth=6, subsample=0.8, colsample_bytree=0.8, random_state=42, use_label_encoder=False, eval_metric=\'logloss\')model.fit(X_train, y_train, sample_weight=weights)# 14. 模型预测与评估y_pred = model.predict(X_test)print(\"准确率 Accuracy:\", accuracy_score(y_test, y_pred))print(\"召回率 Recall:\", recall_score(y_test, y_pred))print(\"F1值 F1 Score:\", f1_score(y_test, y_pred))print(\"\\n分类报告 Classification Report:\\n\", classification_report(y_test, y_pred))# 15. 混淆矩阵可视化cm = confusion_matrix(y_test, y_pred)plt.figure(figsize=(6, 5))sns.heatmap(cm, annot=True, fmt=\'d\', cmap=\'Blues\')plt.title(\"Confusion Matrix\")plt.xlabel(\"Predicted\")plt.ylabel(\"Actual\")plt.tight_layout()plt.show()# 16. 特征重要性可视化plt.figure(figsize=(10, 6))plot_importance(model, max_num_features=10)plt.title(\"Top 10 Important Features (XGBoost)\")plt.tight_layout()plt.show()# 17. 可选:SHAP值解释(需在本地安装支持的llvmlite和shap库)# explainer = shap.Explainer(model)# shap_values = explainer(X_test)# shap.summary_plot(shap_values, features=X_test, feature_names=X.columns)后续都在“数模加油站”......


