LangGraph范式-web_voyager_langgraph 多模态
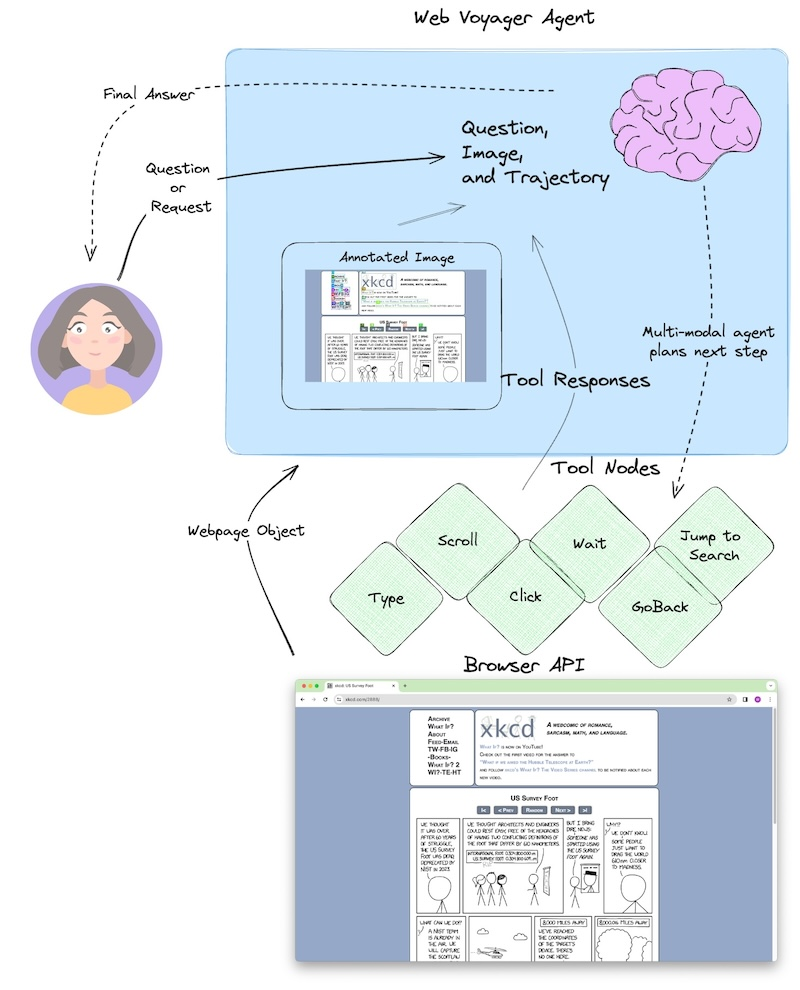
Web Voyager是一个基于多模态大模型(Multi-modal Agent)的AI Agent,旨在通过浏览器API与网页交互,完成用户提出的任务。其核心功能是根据用户的“问题、图像或请求”(Question, Image, or Request),生成网页操作的“工具响应”(Tool Responses),并最终返回“最终答案”(Final Answer)。
它的工作原理是查看每次轮次带注释的浏览器屏幕截图,然后选择下一步操作。该代理架构是一个基本的推理和行动 (ReAct) 循环。该代理的独特之处在于:
它使用类似标记集的图像注释作为代理的 UI 功能。
它通过使用工具控制鼠标和键盘,在浏览器中实现应用。
整体设计如下所示:
从示意图来看,其流程包括:
- 输入:用户提供问题、图像或请求。
- 处理:
- 多模态Agent(Multi-modal Agent)接收输入,分析网页内容(Webpage Object)。
- Agent通过工具模式(Tool Modes)生成下一步操作(Type、Scroll、Click、Wait、Jump to Search、GoBack)。
- 借助浏览器API执行操作,获取新的网页状态。
- 输出:最终答案。
定义状态(State)
LangGraph的工作流需要定义一个状态对象,用于在节点之间传递信息。Web Voyager的状态可能包括:
- 当前网页的截图(base64编码)。
- 用户的请求。
- 当前的操作历史(Trajectory)。
- 工具调用的结果。
from typing import TypedDict, Listclass WebVoyagerState(TypedDict): user_request: str # 用户的请求 webpage_screenshot: str # 当前网页截图(base64编码) trajectory: List[str] # 操作历史 tool_response: str # 工具调用的响应 final_answer: str # 最终答案
(3) 定义工具(Tools)
Web Voyager的核心是工具模式(Tool Modes),包括 Type、Scroll、Click 等操作。这些操作通过浏览器API(如Playwright)实现。
@toolasync def click_element(element_id: str) -> str: \"\"\"点击网页中的某个元素\"\"\" async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() # 假设已经在某个页面上 await page.click(f\"#{element_id}\") screenshot = await page.screenshot() await browser.close() return base64.b64encode(screenshot).decode(\"utf-8\")@toolasync def type_text(text: str, element_id: str) -> str: \"\"\"在网页的某个元素中输入文本\"\"\" async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() await page.fill(f\"#{element_id}\", text) screenshot = await page.screenshot() await browser.close() return base64.b64encode(screenshot).decode(\"utf-8\")@toolasync def scroll_page(direction: str) -> str: \"\"\"滚动网页\"\"\" async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() if direction == \"down\": await page.evaluate(\"window.scrollBy(0, window.innerHeight)\") screenshot = await page.screenshot() await browser.close() return base64.b64encode(screenshot).decode(\"utf-8\")# 其他工具:wait、jump_to_search、go_back 等
(4) 定义多模态Agent
多模态Agent基于用户请求和网页截图,决定下一步操作。它通常使用一个提示模板(PromptTemplate)来引导模型推理。
定义提示模板prompt = PromptTemplate( input_variables=[\"user_request\", \"webpage_screenshot\", \"trajectory\"], template=\"\"\" 你是一个网页导航Agent。用户请求:{user_request} 当前网页截图(base64编码):{webpage_screenshot} 操作历史:{trajectory} 基于当前网页状态,决定下一步操作。可能的工具包括: - click_element(element_id): 点击某个元素 - type_text(text, element_id): 输入文本 - scroll_page(direction): 滚动页面 - wait(): 等待 - jump_to_search(): 跳转到搜索 - go_back(): 返回上一页 返回下一步操作的工具调用,例如:{{\"tool\": \"click_element\", \"args\": {{\"element_id\": \"button1\"}}}} 如果任务已完成,返回最终答案,例如:{{\"final_answer\": \"任务完成\"}} \"\"\")# 初始化多模态模型llm = ChatOpenAI(model=\"gpt-4o\", temperature=0) # 使用支持多模态的模型agent = llm.bind_tools([click_element, type_text, scroll_page])
(5) 定义LangGraph工作流
LangGraph的工作流由节点和边组成。Web Voyager可能包含以下节点:
- agent_node:调用多模态Agent,生成下一步操作。
- tool_node:执行工具操作,更新网页状态。
- end_node:输出最终答案。
定义图workflow = StateGraph(WebVoyagerState)# 节点:Agent决策def agent_node(state: WebVoyagerState) -> WebVoyagerState: response = agent.invoke({ \"user_request\": state[\"user_request\"], \"webpage_screenshot\": state[\"webpage_screenshot\"], \"trajectory\": state[\"trajectory\"] }) if \"final_answer\" in response: state[\"final_answer\"] = response[\"final_answer\"] return state state[\"tool_response\"] = response return state# 节点:工具执行async def tool_node(state: WebVoyagerState) -> WebVoyagerState: tool_call = state[\"tool_response\"] tool_name = tool_call[\"tool\"] args = tool_call[\"args\"] if tool_name == \"click_element\": screenshot = await click_element(args[\"element_id\"]) elif tool_name == \"type_text\": screenshot = await type_text(args[\"text\"], args[\"element_id\"]) elif tool_name == \"scroll_page\": screenshot = await scroll_page(args[\"direction\"]) # 其他工具调用... state[\"webpage_screenshot\"] = screenshot state[\"trajectory\"].append(f\"执行工具:{tool_name},参数:{args}\") return state# 添加节点workflow.add_node(\"agent\", agent_node)workflow.add_node(\"tool\", tool_node)# 添加边workflow.set_entry_point(\"agent\")workflow.add_conditional_edges( \"agent\", lambda state: \"end\" if state.get(\"final_answer\") else \"tool\", {\"end\": END, \"tool\": \"tool\"})workflow.add_edge(\"tool\", \"agent\")# 编译图app = workflow.compile()
Paragoger衍生者AI训练营


