机器人玩转之---嵌入式开发板基础知识到实战选型指南(包含ORIN、RDK X5、Raspberry pi、RK系列等)
1. 基础知识讲解
1.1 什么是嵌入式开发板?
嵌入式开发板是一种专门设计用于嵌入式系统开发的硬件平台,它集成了微处理器、内存、存储、输入输出接口等核心组件于单块印刷电路板上。与传统的PC不同,嵌入式开发板具有体积小、功耗低、成本适中、可定制性强等特点,是快速原型开发和产品验证的理想选择。
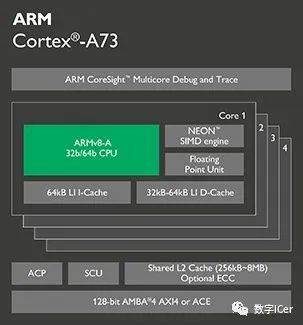
1.2 处理器架构深度解析
1.2.1 ARM架构发展历程
ARM(Advanced RISC Machine)架构自1985年诞生以来,已经经历了多个重要的发展阶段:
ARMv7架构(32位时代)
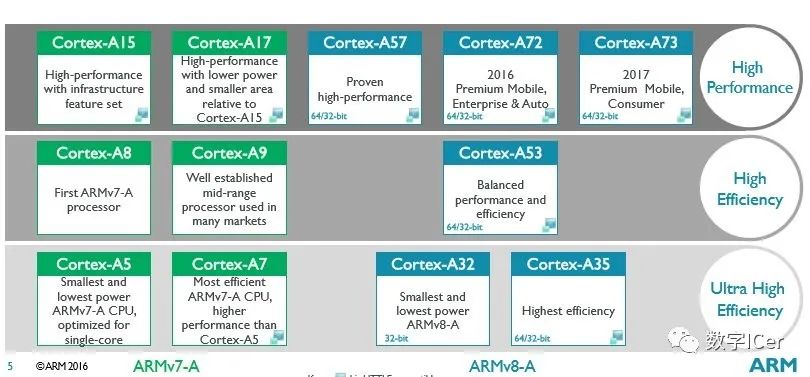
- Cortex-A系列性能对比:
- Cortex-A5:入门级,功耗极低,单核性能约400 DMIPS
- Cortex-A7:高能效,支持big.LITTLE架构,性能比A5提升50%
- Cortex-A8:单核王者,曾是智能手机主流选择,支持1GHz主频
- Cortex-A9:多核先锋,支持1-4核心配置,乱序执行
- Cortex-A15:高性能,支持2.5GHz+主频,比A9性能提升40%
- Cortex-A17:A15的改进版,平衡性能与功耗,能效提升60%
ARMv8架构(64位革命)

- Cortex-A50系列:
- Cortex-A53:64位入门级,兼容32位应用,功耗仅A15的1/3
- Cortex-A57:64位高性能,支持乱序执行,比A15性能提升20-40%
- Cortex-A72:A57的优化版,性能提升30%,功耗降低20%
- Cortex-A73:进一步优化的高端核心,面积减少25%
1.2.2 GHz、芯片性能与核数的关系深度解析
1. 主频与性能的复杂关系
主频(GHz)表示处理器的时钟频率,1GHz等于每秒10亿个周期。但是,现代处理器的性能不能仅凭主频来衡量:
性能 = 主频 × IPC × 核心数 × 架构效率其中:- IPC (Instructions Per Cycle): 每周期指令数- 架构效率: 包括缓存命中率、分支预测准确性等实际性能对比示例:
2. big.LITTLE架构深度技术

ARM的big.LITTLE技术是一种异构多核心设计:
-
大核(Big):如Cortex-A76、A78
- 高性能乱序超标量设计
- 复杂的分支预测和指令预取
- 适合CPU密集型任务
-
小核(Little):如Cortex-A55
- 顺序双发射设计
- 简化的预测机制
- 适合后台任务和轻负载
动态调度策略:
# 伪代码展示big.LITTLE调度逻辑def cpu_scheduler(task_load, power_budget): if task_load > 70% and power_budget > 50%: return \"big_cores\" # 使用大核 elif task_load < 30%: return \"little_cores\" # 使用小核 else: return \"mixed_cores\" # 混合使用1.2.3 关键参数解读指南
CPU相关参数详解
CPU核心架构: - ARMv7-A: 32位,支持NEON SIMD - ARMv8-A: 64位,向下兼容32位 - ARMv9-A: 最新架构,增强安全性和AI性能核心配置: - 单核: 简单应用,低功耗需求 - 双核: 基础多任务处理 - 四核: 主流配置,平衡性能与功耗 - 八核: 高性能需求,通常为big.LITTLE设计缓存层次: - L1缓存: 32KB-64KB,最快访问 - L2缓存: 128KB-1MB,核心私有或共享 - L3缓存: 1MB-8MB,全核心共享制程工艺影响: - 7nm/5nm: 最先进,高性能低功耗 - 12nm/16nm: 主流选择,成本效益平衡 - 22nm/28nm: 入门级,成本优先GPU与AI加速深度解析
GPU架构分类: Mali-G系列: - G31: 入门级,1-2个执行引擎 - G52: 中端,2-4个执行引擎 - G57: 高端,6-9个执行引擎 - G610: 旗舰,10个执行引擎 其他GPU: - Adreno: 高通专用,移动优化 - VideoCore: 博通树莓派系列 - PowerVR: 苹果早期使用AI加速器类型: NPU (Neural Processing Unit): - 专用神经网络加速器 - 支持INT8/INT16/FP16精度 - 算力单位: TOPS (万亿次运算/秒) DSP (Digital Signal Processor): - 数字信号处理专用 - 适合音频/图像处理 - 可编程灵活性高 GPU计算: - OpenCL/Vulkan计算着色器 - 通用性强但效率略低 - 适合大规模并行计算1.3 操作系统生态系统详解
1.3.1 Linux发行版深度对比
Ubuntu系列分析
Ubuntu版本特性: Ubuntu 18.04 LTS: - 支持期: 2023年4月结束 - 内核版本: 4.15 - 适用场景: 老设备兼容性 Ubuntu 20.04 LTS: - 支持期: 2025年4月 - 内核版本: 5.4 - 特色: 容器化支持增强 Ubuntu 22.04 LTS: - 支持期: 2027年4月 - 内核版本: 5.15 - 特色: Wayland默认、更好的ARM支持开发板适配状况: 树莓派: 官方支持,优化完善 RK3588: 第三方移植,稳定性良好 RDK X5: 官方定制版本 Jetson: NVIDIA官方JetPack实时操作系统对比
1.3.2 Android在嵌入式中的应用
Android版本适配分析:
Android 11 (API Level 30): 适配开发板: - RK3588系列: 完整支持 - RK3566/3568: 基础支持 - Amlogic A311D: 官方适配 特色功能: - 动态分区支持 - 5G网络优化 - 增强的隐私控制Android 12/13: 新特性: - Material You设计 - 更好的多媒体性能 - 增强的机器学习框架 硬件要求: - 最低4GB内存 - 至少32GB存储 - GPU硬件加速支持2. 主流开发板横向对比分析
2.1 地平线RDK系列深度解析
2.1.1 RDK X3 vs RDK X5 全面对比

地平线RDK系列是专门面向机器人和AI应用的开发板:
BPU(Brain Processing Unit)架构分析:
征程3 BPU特性: 架构: Bernoulli 1.0 算力: 5 TOPS@INT8 支持框架: Caffe, TensorFlow, PyTorch 优化模型: YOLOv3, ResNet, MobileNet 征程5 BPU特性: 架构: Bernoulli 2.0 算力: 10 TOPS@INT8 新增特性: Transformer模型支持 混合精度: INT4/INT8/INT16/FP16 内存带宽: 68GB/sTogetherROS机器人生态:
RDK系列独有的机器人开发框架,基于ROS2构建:
# TogetherROS安装示例sudo apt updatesudo apt install tros-ros-basesource /opt/tros/setup.bash# 启动示例AI节点ros2 run hobot_dnn hobot_dnn_node2.1.2 实际AI性能测试
计算机视觉任务性能对比:
2.2 树莓派系列全系对比
2.2.1 树莓派4B vs 树莓派5 详细分析

性能基准测试对比:
Geekbench 5测试结果: 树莓派4B: 单核: 183分 多核: 652分 内存带宽: 3.2GB/s 树莓派5: 单核: 692分 多核: 2350分 内存带宽: 8.4GB/s 性能提升倍数: 单核: 3.78倍 多核: 3.60倍 内存: 2.63倍2.2.2 树莓派生态系统优势
软件生态成熟度:
官方支持: - Raspberry Pi OS (基于Debian) - 完整的apt软件仓库 - 官方技术文档和教程 - 定期系统更新第三方支持: - Ubuntu官方适配 - Windows 11 ARM版本 - Android LineageOS - 各种专用Linux发行版开发工具: - Raspberry Pi Imager (系统烧录) - GPIO控制库 (Python/C++) - 摄像头和显示屏驱动 - HAT扩展板生态2.3 瑞芯微RK系列全景分析
2.3.1 RK3588系列深度剖析

RK3588核心规格详解:
CPU子系统: 大核: 4×Cortex-A76@2.4GHz - 64位ARMv8-A架构 - 乱序超标量执行 - 64KB L1指令缓存 + 64KB L1数据缓存 - 512KB L2缓存 小核: 4×Cortex-A55@1.8GHz - 高能效设计 - 32KB L1指令缓存 + 32KB L1数据缓存 - 128KB L2缓存 共享: 3MB L3缓存GPU子系统: 型号: ARM Mali-G610 MP4 架构: Valhall第2代 核心数: 4个着色器核心 频率: 1000MHz 性能: 约300 GFLOPS@FP32 NPU子系统: 算力: 6 TOPS@INT8 支持精度: INT4/INT8/INT16/FP16/BF16/TF32 框架支持: TensorFlow/PyTorch/ONNX/Caffe搭载RK3588的主流开发板对比:
Cortex-A55 x4
Cortex-A55 x4
2.3.2 RK3576新一代中高端选择
RK3576技术突破:
制程工艺: 6nm (相比RK3588的8nm)CPU配置: 4×A72@2.2GHz + 4×A53@1.8GHz + M0 MCUGPU升级: Mali-G52 MC3 (支持更多API)NPU保持: 6 TOPS@INT8 (与RK3588相同)新增特性: - AV1硬件解码支持 - WiFi 6E无线支持 - USB4/Thunderbolt兼容性 - 更低功耗设计2.3.3 RK3566/3568中端主力分析

RK3566 vs RK3568核心差异:
典型应用配置建议:
工业显示应用 (推荐RK3568): 内存: 4GB LPDDR4 存储: 32GB eMMC 显示: MIPI-DSI 1080P触摸屏 网络: 千兆以太网 + WiFi6 接口: RS485/CAN总线扩展智能网关应用 (推荐RK3566): 内存: 2GB LPDDR4 存储: 16GB eMMC 网络: 双千兆以太网 扩展: 4G/5G模组支持 协议: MQTT/HTTP/TCP/UDP2.3.4 RK3399经典回顾
尽管RK3399已是上一代产品,但在某些应用场景仍有其价值:
RK3399技术特点:
CPU架构: 双A72@1.8GHz + 四A53@1.5GHz制程工艺: 28nm (功耗较高)GPU: Mali-T860 MP4内存: DDR3/DDR3L/LPDDR3/LPDDR4优势: 成熟稳定,生态完善,成本低廉劣势: 功耗高,性能相对落后2.4 全志Allwinner系列分析
2.4.1 H618高性价比之选
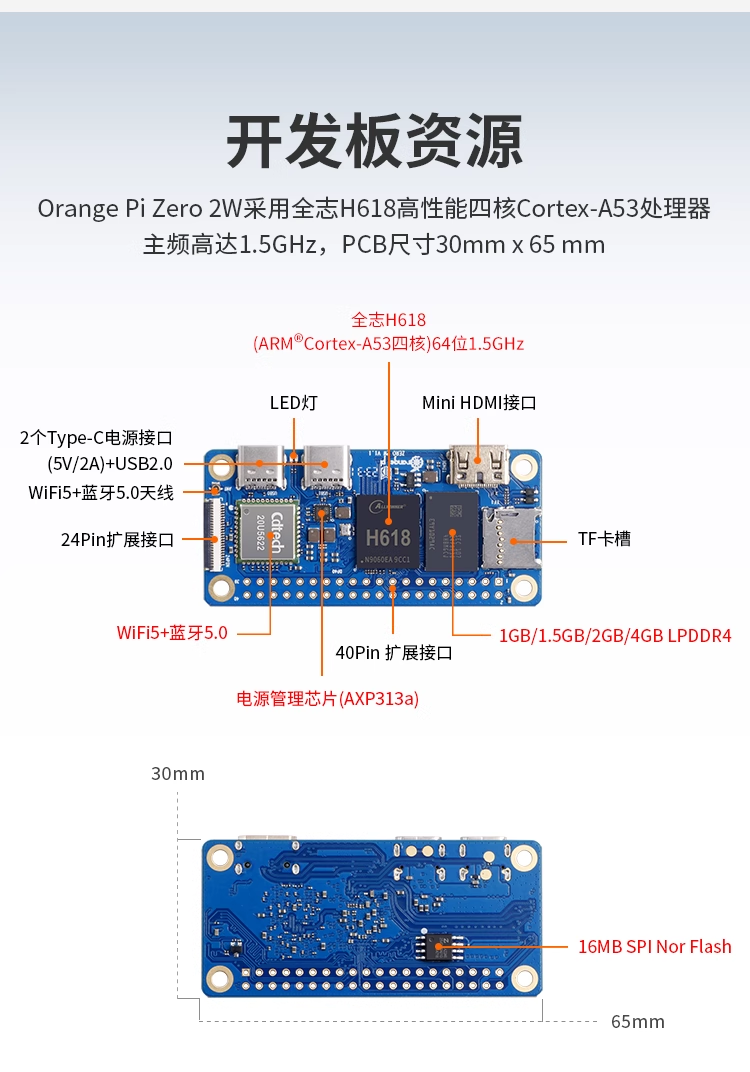
全志H618核心特性:
CPU配置: 4×Cortex-A53@1.5GHzGPU: Mali-G31 MP2制程: 28nm内存支持: LPDDR4 最大4GB视频解码: - H.264: 4K@60fps - H.265: 4K@30fps - VP9: 4K@25fps特色: 极致小尺寸 (30×65mm)Orange Pi Zero 2W详细规格:
2.4.2 T113-S3超低成本方案
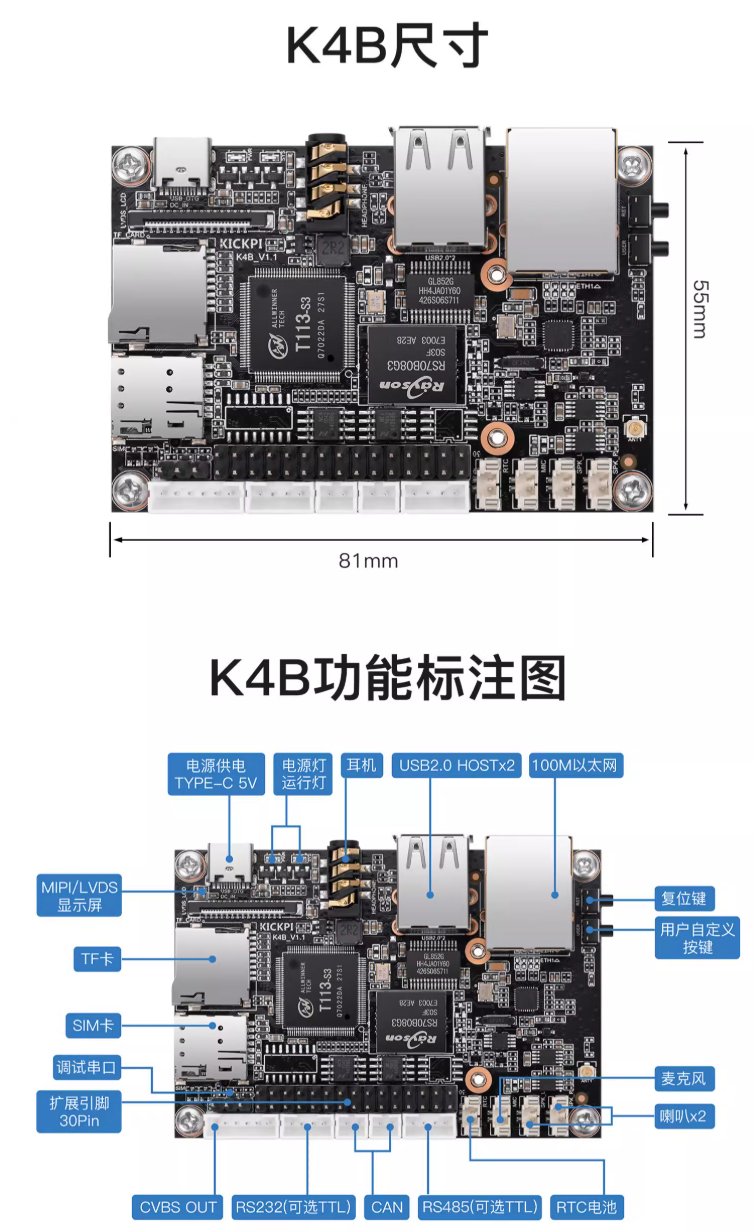
T113-S3极简配置:
CPU: 双核Cortex-A7@1.0GHz内存: 128MB DDR3 (芯片内置)尺寸: 81mm × 55mm系统: Buildroot/Ubuntu Server特点: - 极低成本 (整板<100元) - 集成度高 - 适合大批量部署应用场景: - 简单物联网传感器 - 工业数据采集 - 基础控制器2.5 其他重要芯片平台
2.5.1 Rockchip RK3562中端新选择

RK3562技术规格:
处理器配置: RK3562J: 4×Cortex-A53@1.8GHz RK3562: 4×Cortex-A53@2.0GHz GPU: Mali-G52-2EE 支持: OpenGL ES 3.2, OpenCL 2.0, Vulkan 1.1 NPU: 1 TOPS@INT8 精度: INT4/INT8/INT16/FP16视频处理: 编码: H.264 1080P@60fps 解码: H.265/VP9 4K@30fps, H.264 1080P@60fps工作温度: -40°C ~ +85°C (工业级)工作电压: DC 5V2.5.2 Amlogic A311D2专业级选择
A311D2是Amlogic面向AI和多媒体应用的旗舰芯片:
A311D2核心优势:
CPU: 4×A73@2.2GHz + 4×A53@2.0GHzGPU: Mali-G52 MP8 (8核心配置)NPU: 5.0 TOPS@INT8制程: 12nm特色功能: - 优秀的视频处理能力 - 支持8K@24fps解码 - 完整的Android TV认证 - 工业级温度范围3. NVIDIA Jetson系列专项分析
NVIDIA Jetson系列是边缘AI计算领域的标杆产品,从入门级的Nano到旗舰级的AGX Orin,为不同应用场景提供了完整的解决方案。
3.1 Jetson系列发展历程与架构演进
架构演进时间线:
2014年: Jetson TK1 - GPU架构: Kepler (192 CUDA核心) - CPU: 4核 ARM Cortex-A15 - 制程工艺: 28nm - AI算力: ~0.3 TOPS 2016年: Jetson TX1/TX2 - GPU架构: Maxwell (256 CUDA核心) - CPU: 4核/6核 ARM Cortex-A57/A78 - 制程工艺: 20nm/16nm - AI算力: 1.3 TOPS 2018年: Jetson Xavier NX - GPU架构: Volta (384 CUDA核心) - CPU: 6核 Carmel - 制程工艺: 12nm - AI算力: 21 TOPS 2022年: Jetson Orin系列 - GPU架构: Ampere (最高2048 CUDA核心) - CPU: 6-12核 ARM Cortex-A78AE - 制程工艺: 8nm - AI算力: 20-275 TOPS 2024年: Jetson Thor (下一代) - GPU架构: Ada Lovelace - CPU: 14核 ARM Neoverse (含AE扩展核心) - 制程工艺: 4nm - 预期AI算力: 1000+ TOPS3.2 Jetson Orin系列完整对比分析
数据来源:Connect Tech官方Jetson Orin模块对比、NVIDIA官方技术规格
3.2.1 Jetson Orin系列规格详细对比
4GB
8GB
8GB
16GB
32GB
Industrial
64GB
(2024)
16张量核心
32张量核心
32张量核心
32张量核心
56张量核心
64张量核心
64张量核心
TBD
34 GB/s
68 GB/s
102.4 GB/s
102.4 GB/s
205 GB/s
205 GB/s
205 GB/s
(CPU软编)
(CPU软编)
6×1080p60
H.264/H.265/AV1
6×1080p60
H.264/H.265/AV1
8×1080p60
2×4K30 H.265
2×4K30 H.265
3×4K30 H.265
2×4K60 H.265
2×4K60 H.265
3×4K60 H.265
3×4K60 H.265
8通道虚拟
8通道虚拟
8通道虚拟
8通道虚拟
PCIe Gen3
PCIe Gen3
PCIe Gen4
PCIe Gen4
PCIe Gen4
PCIe Gen4
PCIe Gen4
SO-DIMM
SO-DIMM
SO-DIMM
SO-DIMM
699引脚连接器
699引脚连接器
699引脚连接器
数据来源:Connect Tech Jetson Orin模块对比、NVIDIA官方技术文档
3.2.2 Jetson Thor下一代架构预览
Jetson Thor是NVIDIA计划于2025年发布的下一代边缘AI平台,基于最新的Blackwell GPU架构:
技术规格 (基于官方公布信息): 制程工艺: 4nm TSMC GPU架构: Blackwell (最新一代架构) AI算力: - 2070 TFLOPS@FP4 - 1035 TFLOPS@FP8 - 1000+ TOPS@INT8 CPU: 14核 ARM Neoverse (含AE扩展核心) 内存: 128GB LPDDR5X (高带宽版本) 网络: 4×25 GbE (实时多传感器处理) 主要改进: - 物理AI和机器人专用优化 - 支持生成式AI模型本地部署 - 增强的Transformer引擎 - 实时多传感器数据融合 - 支持下一代自动驾驶 目标应用: - 物理AI和具身智能机器人 - L4/L5级别自动驾驶 - 边缘大模型部署 - 工业AI和数字孪生 - 高端具身智能系统数据来源:Connect Tech Jetson Thor产品页面、NVIDIA官方新闻稿
3.2.3 性能与应用场景匹配分析
3.3 实际性能基准测试
3.3.1 AI推理性能对比(MLPerf Edge基准)
ResNet-50图像分类(ImageNet数据集):
单张推理速度 (Images/Second):AGX Orin 64GB: 15,000 IPS (TensorRT FP16)AGX Orin 32GB: 12,500 IPS Orin NX 16GB: 8,500 IPSOrin NX 8GB: 6,200 IPSOrin Nano 8GB: 3,800 IPSOrin Nano 4GB: 2,100 IPSXavier NX: 2,800 IPS (对比参考)YOLOv8目标检测(COCO数据集,640×640输入):
实时检测帧率 (FPS):AGX Orin 64GB: 185 FPS (TensorRT INT8)AGX Orin 32GB: 150 FPSOrin NX 16GB: 95 FPS Orin NX 8GB: 75 FPSOrin Nano 8GB: 45 FPSOrin Nano 4GB: 28 FPS功耗效率 (FPS/W):Orin Nano 8GB: 45/12 = 3.75 FPS/W (最优)Orin NX 8GB: 75/18 = 4.17 FPS/W AGX Orin 32GB: 150/35 = 4.29 FPS/W3.3.2 多媒体编解码性能实测
4K H.265编码性能:
测试数据来源:e-con Systems Jetson性能对比
4. x86架构开发板解析
4.1 Intel平台高性能方案
4.1.1 12代i9-12900HK移动工作站级性能

12th Gen Core技术突破:
架构: Intel 7制程 (Enhanced 10nm SuperFin)核心配置: 6P + 8E = 14核心20线程 Performance Core (P-Core): - 架构: Golden Cove - 基频: 2.5GHz, 睿频: 5.0GHz - 二级缓存: 1.25MB × 6 - 超线程: 支持 Efficiency Core (E-Core): - 架构: Gracemont - 基频: 1.8GHz, 睿频: 3.8GHz - 二级缓存: 2MB × 2 (clusters) - 超线程: 不支持三级缓存: 24MB Intel Smart Cache内置GPU: Intel Iris Xe Graphics (96EU)内存支持: DDR5-4800 / DDR4-3200TDP: 45W (基准), 最高115Whybrid架构调度优势:
Thread Director智能调度: - 硬件级线程调度 - 针对任务类型自动分配核心 - P-Core处理性能敏感任务 - E-Core处理后台和并行任务 性能提升数据: - 单线程性能: 比11代提升19% - 多线程性能: 比11代提升28% - 能效比: 比11代提升25% - AI工作负载: AVX-512指令集支持在嵌入式开发中的应用优势:
4.1.2 Intel NUC系列开发平台
NUC 12 Enthusiast技术规格:
处理器选项: - Core i7-12700H (6P+8E, 20线程) - Core i5-12500H (4P+8E, 16线程) 内存支持: - DDR4-3200 SODIMM ×2 - 最大64GB容量 - 双通道配置存储接口: - M.2 2280 PCIe 4.0 ×2 - SATA 2.5\" ×1 - 支持RAID 0/1网络连接: - Intel 2.5G以太网 - WiFi 6E (802.11ax) - 蓝牙5.3尺寸: 117 × 112 × 51mm功耗: 28W-45W TDP

