【linux】linux进程概念(五)——进程地址空间
小编个人主页详情<—请点击
小编个人gitee代码仓库<—请点击
linux系列专栏<—请点击
倘若命中无此运,孤身亦可登昆仑,送给屏幕面前的读者朋友们和小编自己!

目录
前言
【linux】linux进程概念(四)(环境变量)超详细版——书接上文 详情请点击<——
本文由小编为大家介绍——【linux】linux进程概念(五)——进程地址空间
一、程序地址空间
讲解
- 在我们c语言阶段的学习中,想必我们已经学习过下面这样的程序地址空间分布,从下向上,地址由低地址处向高地址增加,在32位环境下,下面的地址是16进制,以低地址处0000 0000为例,由于是16进制,一个16进制数对应这里的1个0代表4个比特位,那么一共有8个0,代表着4*8 == 32比特位,即对应32位环境
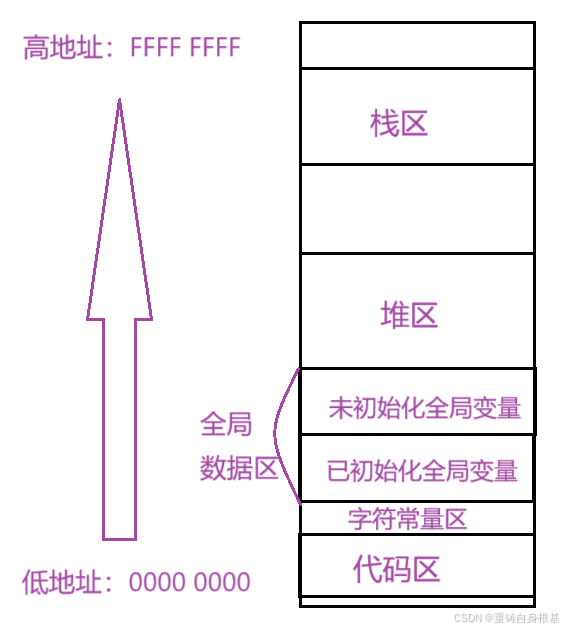
- 小编使用如下代码验证一下如下的程序地址空间的排布的地址是否由低地址向高地址增加
int g_val_1 = 0;int g_val_2;int main(){ printf(\"cond addr: %p\\n\", main); const char* str = \"yyy\"; printf(\"read only string addr: %p\\n\", str); printf(\"init global value addr: %p\\n\", &g_val_1); printf(\"uninit global value addr: %p\\n\", &g_val_2); char* heap = (char*)malloc(100); printf(\"heap addr: %p\\n\", heap); printf(\"stack addr: %p\\n\", str); return 0;}- 运行结果和程序地址空间都可以进行一 一对应,无误
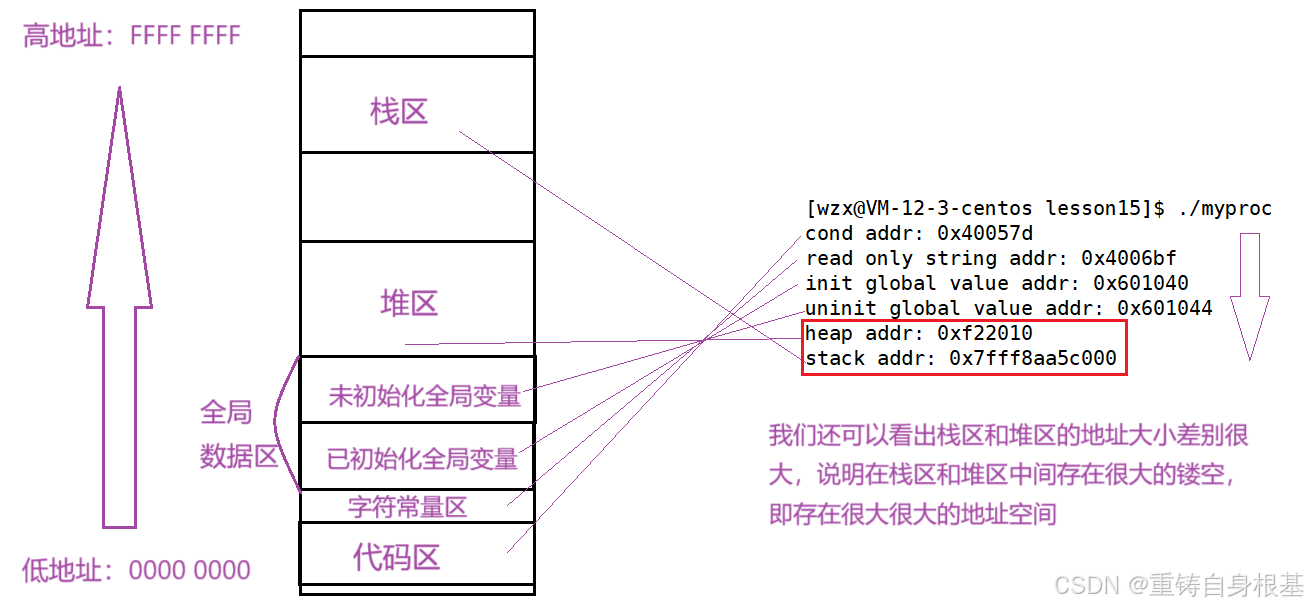
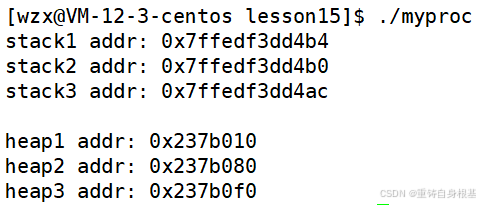
- 我们从图中对应的地址可以看出,栈区和堆区的地址中间存在很大的镂空,存在很大很大的地址空间,其实栈区和堆区是相对生长,即堆区是向上增长,栈区是向下增长,这也很好理解,因为栈区要入栈,所以就是向下增长的,下面我们通过代码来验证一下
#include #include int main(){ int a = 0; int b = 0; int c = 0; printf(\"stack1 addr: %p\\n\", &a); printf(\"stack2 addr: %p\\n\", &b); printf(\"stack3 addr: %p\\n\\n\", &c); char* heap1 = (char*)malloc(100); char* heap2 = (char*)malloc(100); char* heap3 = (char*)malloc(100); printf(\"heap1 addr: %p\\n\", heap1); printf(\"heap2 addr: %p\\n\", heap2); printf(\"heap3 addr: %p\\n\", heap3); return 0;}运行结果如下
- 我们可以很好的看出依次在栈上创建的变量的地址是逐个减小的,即地址是向下增长,在堆上申请的变量的地址是逐个增大的,即地址是向上增长的,即栈区和堆区是相对生长的
- static修饰的局部变量实际上是具有全局变量的属性的,只不过是受到局部作用域的限制,static修饰的局部变量其被编译的时候是被编译全局数据区的,下面我们验证一下
#include int g_val_1 = 0;int main(){ printf(\"init global value addr: %p\\n\", &g_val_1); static int g_val_2 = 1; printf(\"static init global value addr: %p\\n\", &g_val_2); return 0;}运行结果如下,static修饰的局部变量和全局变量仅仅相差及十字节,所以几乎十分相近
因此static修饰的局部变量其被编译的时候是被编译全局数据区的

- 上面小编画的程序地址空间只是为了便于引入,但是实际上还是不是很准确,应该使用下面的图片为准,后面小编进行讲解的时候会以下图位基准进行讲解
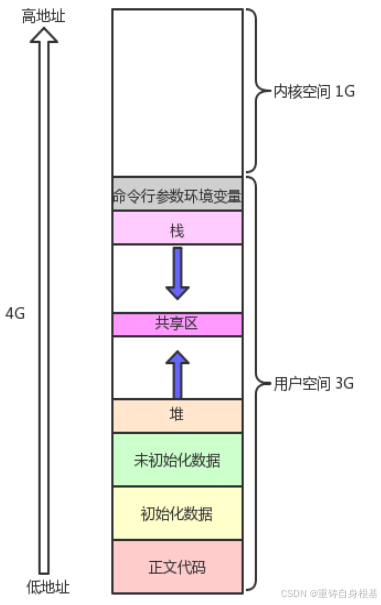
引入
- 下面我们看这样的一段代码,定义一个全局变量,分别使用子进程和父进程去死循环读取这个全局变量的值
- 当然如果想要退出这个死循环,可以连续按下ctrl+c即可退出进程
#include #include #include int g_val = 100;int main(){ pid_t id = fork(); if(id == 0)//子进程 { while(1) { printf(\"i am child, pid: %d, ppid: %d, g_val = %d, &g_val = %p\\n\", getpid(), getppid(), g_val, &g_val); sleep(1); } } else//父进程 { while(1) { printf(\"i am parent, pid: %d, ppid: %d, g_val = %d, &g_val = %p\\n\", getpid(), getppid(), g_val, &g_val); sleep(1); } } return 0;}运行结果如下
- 运行结果很好理解,子进程是以父进程为基准,子进程和父进程,共用代码和数据,由于子进程并没有对数据进行修改,所以取出并进行打印的全局变量的值和地址是相同的
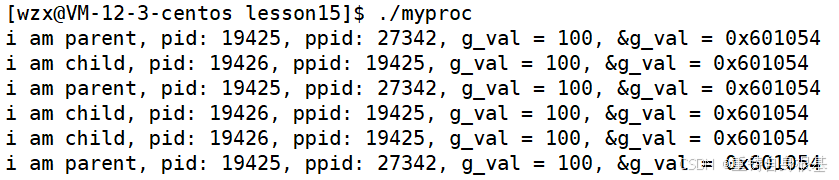
- 下面小编将数据进行修改一下,让子进程修改全局变量的值,那么我们观察一下现象
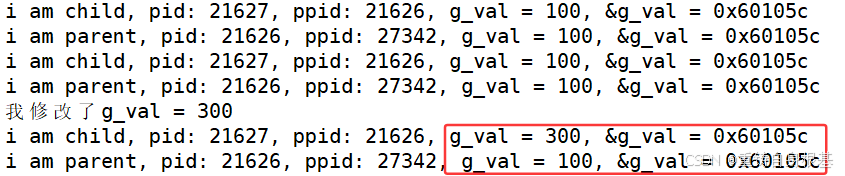
#include #include #include int g_val = 100;int main(){ pid_t id = fork(); if(id == 0) { while(1) { static int cnt = 3; printf(\"i am child, pid: %d, ppid: %d, g_val = %d, &g_val = %p\\n\", getpid(), getppid(), g_val, &g_val); sleep(1); if(cnt == 0) { g_val = 300; printf(\"我修改了g_val = 300\\n\"); cnt--; } else { cnt--; } } } else { while(1) { printf(\"i am parent, pid: %d, ppid: %d, g_val = %d, &g_val = %p\\n\", getpid(), getppid(), g_val, &g_val); sleep(1); } } return 0;}运行结果如下
- 我们可以看出你子进程对全局变量修改成了300,即子进程要对数据发生写入,由于要维护进程的独立性,数据之间互不干扰,那么此时子进程就会发生写时拷贝,对g_val拷贝一份,在拷贝的空间位置上修改这个变量为300,那么修改后,子进程打印这个全局变量的值为300,以及父进程打印全局变量仍然为原数据100,这两点很好理解,没问题,归纳一下,变量的内容不一样,所以子进程和父进程打印的变量一定不是同一个变量
- 可以当我们看到父进程和子进程取出全局变量对应的地址进行打印之后,竟然离奇的发现,父进程和子进程打印的全局变量的地址是相同的,这就让然百思不得其解,我们知道地址分别虚拟地址(线性地址)和物理地址
- 小编先带量大家探讨一下是否是物理地址,由于物理地址上面存储什么就可以取出什么,如果这里打印的全局变量的地址是物理地址,那么父进程和子进程从这个物理地址上取出的全局变量进行打印的值一定是相同的,这里父进程和子进程打印的全局变量的值却是不相同的,所以这里打印的全局变量的地址一定不是物理地址
- 那么这里父进程和子进程打印的全局变量的地址一定是虚拟地址,即同一个虚拟地址映射到两个不相同的物理地址上
- 也就是说我们c/c++程序中所使用的指针中,所看到的地址全部都是虚拟地址,那么对于虚拟地址映射的物理地址,用于是无法看到的,全部由操作系统进行管理,在这个映射的过程中,操作系统必须将虚拟地址转化成物理地址
- 其实上面小编所提到的程序地址空间是不准确的,应该叫做进程地址空间更为准确,下面小编就来讲解一下进程地址空间的相关内容
二、进程地址空间
概念理解
- 那么小编针对上面父进程被CPU调度,父进程创建子进程,子进程修改数据g_val的情形画一个草图供大家了解学习
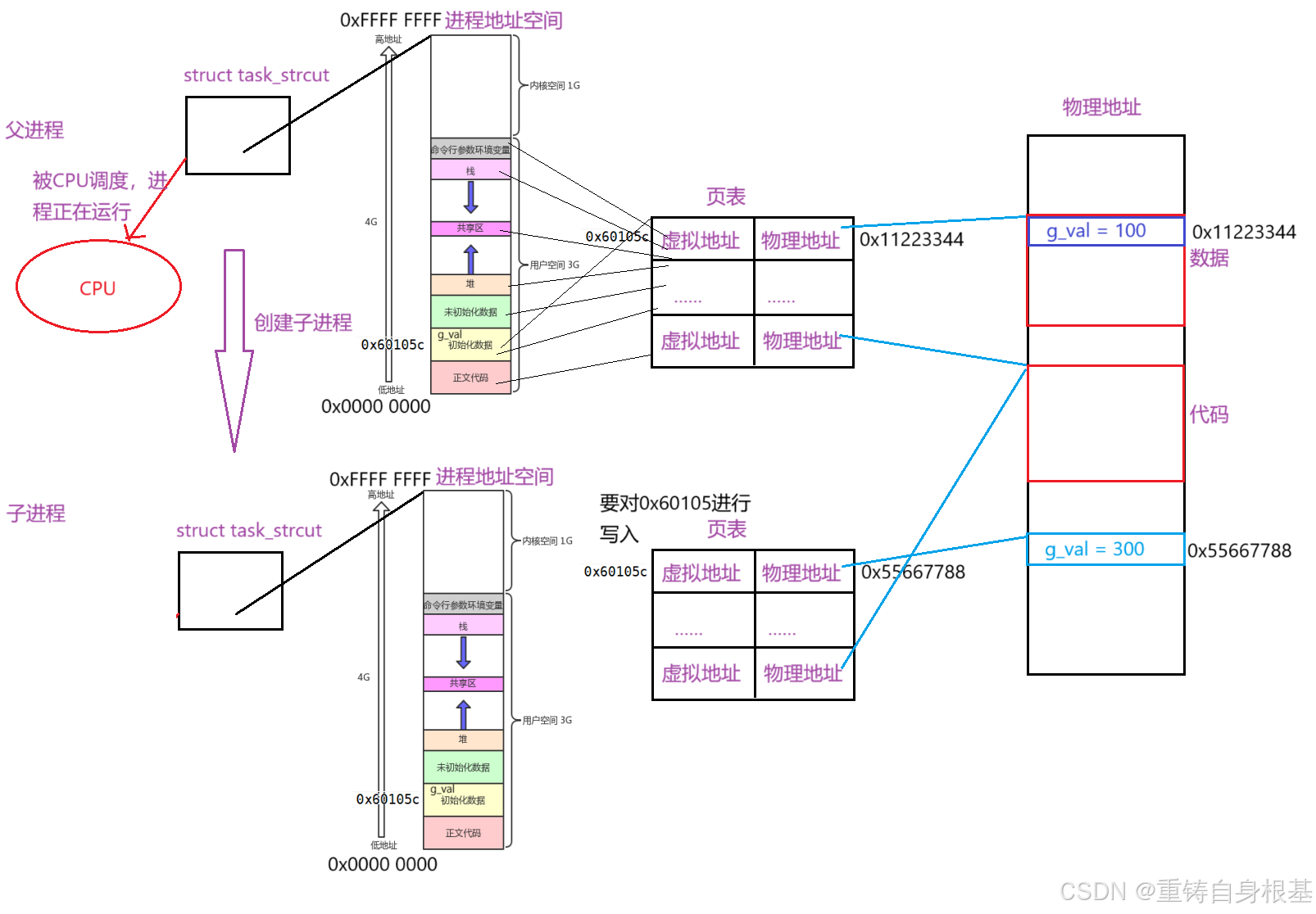
- 我们知道关于进程:进程 = 内核数据结构+代码和数据,在之前的文章中,小编仅仅只是将这个内核数据结构讲解成PCB(task_struct),其实这是不够的,这里小编要将其进行扩展,扩展并加入进程地址空间,页表,即内核数据结构 == PCB + 进程地址空间 + 页表,这样才算完善
- 操作系统为每一个进程创建自己独立的进程地址空间和页表,我们在进程地址空间上访问,堆区,栈区,全局数据区(未初始化全局变量,已初始化全局变量),字符常量区,代码区等等上面的数据的时候,在进程地址空间上所拿到的变量的地址都是虚拟地址,我们要访问的数据(变量)实际上都是存放在物理内存上的,由于每一个进程都有自己的页表,这张页表的左侧是虚拟地址,与之对应的右侧映射物理内存上的物理地址,这种映射关系是通过MMU实现的,当我们想要访问一个变量,例如想要访问上面代码中的全局变量g_val,那么此时就会去进程地址空间上的全局数据区中已初始化全局变量区域中去找到这个全局变量g_val对应的虚拟地址,然后操作系统会拿着这个虚拟地址去页表上找对应的物理地址,操作系统拿到这个物理地址后就可以去物理内存中访问到物理地址上存储的变量的值了
- 父进程由操作系统为它创建了对应的进程地址空间以及页表,那么当父进程创建子进程的时候,子进程被创建初始时没有自己独立的进程地址空间以及页表,并且也没有对应的代码和数据,由于子进程是以父进程为基准,所以操作系统就会将父进程对应的进程地址空间以及页表中的大部分数据为子进程拷贝一份,此时子进程就有了自己独立的进程地址空间和页表了,由于进程地址空间的区域实际上的虚拟地址都是对应页表上的虚拟地址,并且页表上有对应的物理地址,父进程的代码和数据都是存储在物理内存上的,由于子进程的进程地址空间和页表是拷贝的父进程的,那么子进程进程地址空间和页表上的虚拟地址和父进程的虚拟地址是相同的,所以子进程和父进程共用同一份代码和数据
- 当子进程要对数据(全局变量g_val = 100)进行修改,修改为300的时候,此时就会发生写时拷贝(写时拷贝是由操作系统自动完成的),会在物理内存上重新开辟空间(在这个过程中,左侧的虚拟地址是0感知的,左侧虚拟地址不关系它,也不会影响左侧的虚拟地址,即左侧的虚拟地址会维持并不会改变),将g_val = 100拷贝到重新开辟的空间上,会在新开辟的空间上完成对g_val的值修改成300的操作,由于子进程上的g_val的虚拟地址对应的物理地址已经发生了改变,此时MMU就会重新将新的物理地址映射到页表中,因此子进程中修改的数据的虚拟地址虽然未发生改变,数据实际的值已经发生了改变,即页表中虚拟地址映射的物理地址已经发生了改变,那么此时对于前面的现象我们就可以很好的理解了,对于全局变量g_val,子进程对g_val进行修改后,父进程的值是100,子进程的值是300,子进程和父进程中,全局变量g_val的地址是相同的,这个地址是虚拟地址,虚拟地址会分别在父进程和子进程各自的页表上映射对应的物理地址,父进程映射的物理地址和子进程映射的物理地址不相同,那么此时操作系统就会去物理内存中对应不同的物理地址上去取出不同的g_val对应的值,所以就会呈现出变量的值不相同,但是地址是相同的这种现象
三、地址空间
什么是地址空间
- 在32位计算机中,有32位的地址和数据总线,也就是说有32根地址总线,每一根地址总线可以表示0,1两种状态,那么32根地址总线,可以表示2^32种状态,访问地址的最小单位是byte,那么32位机器的总大小就是2^32 * 1byte,而1GB = 2^10MB = 2^20KB = 2^30byte,所以32位机器的内存大小就是2^32 * 1byte = 2^30byte * 4 = 4GB
- 所以地址空间就是地址总线排列组合所形成的空间范围[0, 2^32)
- 其实linux中的进程是十分多的,每一个进程都要有自己独立的进程地址空间,进程一旦十分多,那么就容易混乱,那么我们应该先描述再组织,使用结构体描述进程地址空间,在linux中是mm_struct描述进程地址空间
如何理解地址空间上的区域划分
- 那么地址空间上的区域划分实际上就是将进程上的每个区域,命令行参数环境变量,栈,共享区,堆,未初始化数据,已始化数据,正文代码进行划分(默认划分的区域是4GB,虽然给每个进程划分区域的是4GB,但是其实进程实际所使用的空间,仅仅是很小很小的一部分)
- 那么如何进行划分呢?其实很简单,在linux中就是使用mm_struct结构体存储每个区域的起始和结束即可对进程地址空间进行区域划分即可
- 同时如果想要对划分的区域进行调整,那么只需要调整这个区域的起始和结束的变量即可
再次理解地址空间
- 所谓的进程地址空间,本质是描述一个进程可视范围的大小,地址空间一定要存在各种的区域划分,即对线性地址进行start和end划分区域
- 地址空间的本质是内核的数据结构对象,和PCB一样,地址空间也要被操作系统管理起来,即先描述再组织
- 在划分后的区域范围,连续的空间中,我们不能单单的看到区域的开始和结束,还应该看到每一个最小单位byte都有其对应的地址,这个地址都可以被直接进行使用
- 并且在进程的PCB结构体中实际上有一个struct mm_struct* mm指向这个进程地址空间对象
struct mm_struct{unsigned long start_code, end_code, start_data, end_data;unsigned long start_brk, brk, start_stack;unsigned long arg_start, arg_end, env_start, env_end;}四、进程及进程地址空间
什么叫做进程
- 此时当我们了解到了这个进程地址空间实际上是一个mm_struct结构体之后,小编就可以对前面小编讲述的进程进一步进行细化
- 进程 == 内核数据结构(task_struct && mm_struct && 页表)+ 程序的代码和数据
为什么要有进程地址空间
- 可以让进程以统一的视角看待内存(解释:由于有页表的存在,保证了我们所访问的虚拟地址是线性存在的,所以进程不再需要关心物理内存的布局,将无序变有序,所有的进程都可以以进程地址空间的角度看待内存)
- 增加进程虚拟地址空间,可以让我们访问内存的时候,增加一个转换的过程,在这个转化的过程中,可以对我们的寻址请求进行审查,一旦异常访问,操作系统就会直接拦截,这个请求就不会到达物理内存上,这也是对物理内存的保护
- 因为有地址空间和页表的存在,可以将进程管理模块和内存管理模块进行解耦合(原因会在下面进行解释)
五、页表
- 关于页表,小编画了如下草图,并进行讲解三个点
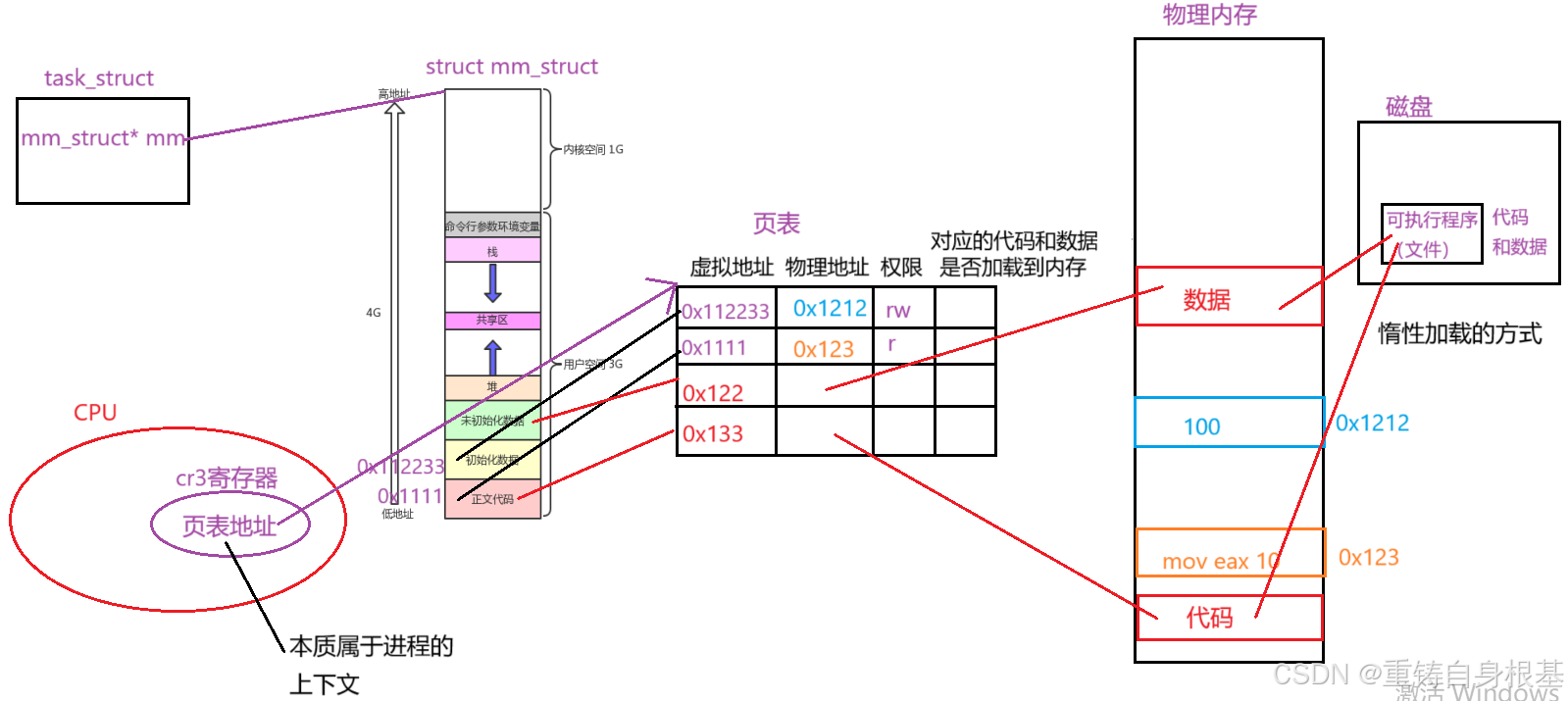
页表地址
- 当进程被CPU调度的时候,此时CPU上会有一个cr3寄存器,这个cr3寄存器是专门用于存储页表地址的(物理地址),这个页表的地址本质是属于进程的上下文,当进程切换的时候,上下文也会切换,页表的地址在上下文中也会被一并带走切换
- 进程的PCB中会有一个进程地址空间的结构体对象的指针mm,用于指向该进程对应的进程地址空间的结构体对象,同时当进程被切换的时候,PCB会离开CPU,那么此时由于PCB中有进程地址空间的结构体对象的指针mm,所以会一并将进程地址空间一并带走切换,所以当进程切换的时候,PCB,进程地址空间,页表都会一并进行切换
为什么代码区,字符常量区是只读的
- 如下,我们知道字符串是存储在常量区的,常量区的内容不可以修改,只允许读,那么小编取出第一个字符h修改为字符x的操作,势必会被操作系统拦截,直接报错
#include int main(){ char* str = \"hello world\"; *str = \'x\'; return 0;}运行结果如下,报错
- 那么我们思考,操作系统如何做的才可以达到让我们无法修改诸如代码区的代码,字符常量区的字符呢?其实是通过页表实现的

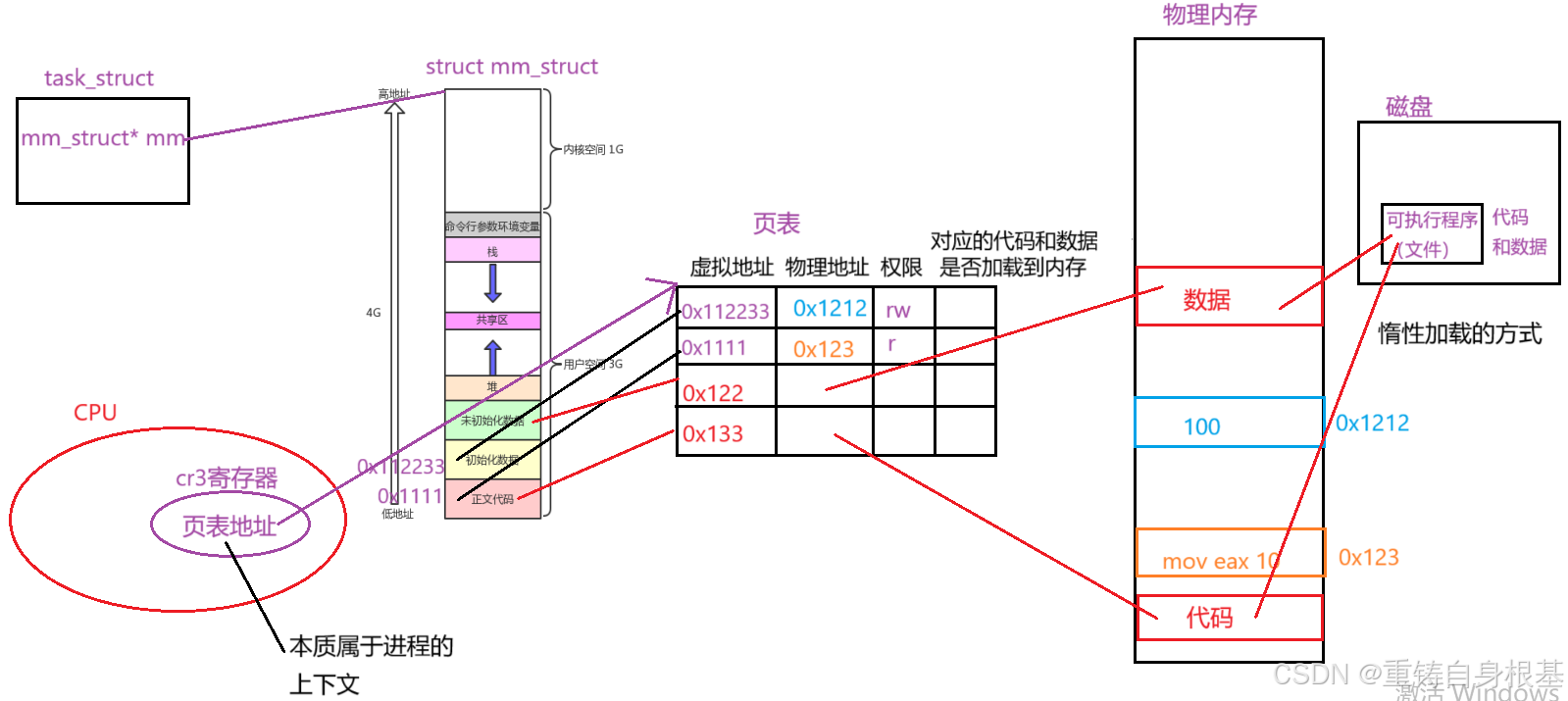
- 页表其实还有一栏用于标识当前的权限分别是r只读,rw可读可写,例如如果你想要访问的数据是初始化数据区中的,那么权限就是rw可读可写,当你对初始化数据区中的数据进行读写操作,操作系统通过页表查看到数据的权限是可读可写的,所以不会拦截,会允许你进行读写操作
- 当你想要访问的数据是代码区的数据,那么权限是r只读,即只允许你对代码区的数据进行读,当我们想要对代码区进行写入的时候,此时操作系统通过页表查看到我们所访问的数据只允许读,不允许写入,那么此时我们进行的写入操作就是非法的,所以操作系统会对我们的操作进行拦截,并且会直接报错,不允许我们对代码区的数据进行修改,同理对字符常量区的数据进行修改也是一样的道理
- 其实我们应该理解到一个点,我们从学习c语言的时候就知道代码区和字符常量区的数据不允许修改,这个是通过页表实现的,可是代码区和字符常量区的数据是存储在物理内存上面的,最初的时候物理内存上面对应的代码区和字符常量区也没有数据,我们需要向物理内存上面的代码区和字符常量区进行写入之后,代码区和字符常量区才有数据,其实这里的本质就是拿到物理地址,只要有物理地址就可以对物理地址上的内容进行写入,物理内存上并没有权限一类的东西,物理内存就很简答,你拿到我们的地址就可以对我物理地址上的内容进行写入,正是因为有了页表这一层壳,才可以实现诸如权限限制这一类的操作
如何知道进程的代码和数据是否在内存中?
- 我们知道我们的进程是可以被挂起的,当进程挂起之后进程对应的代码和数据不在内存中了,可是在linux中,对于进程的状态并没有挂起的状态,只有S,T,Z等,并没有标识进程挂起的状态,那么操作系统又是如何得知这个进程被挂起了,这个进程的代码和数据不再内存了呢?答案还是页表
- 在页表中还有一栏用于标识进程的代码和数据是否加载到内存,类似于0,1,其中0就是没有加载到内存中,1就是加载到内存中了,此时我们的操作系统就可以通过页表中的标识判断进程的代码和数据是否被加载到内存中了
- 那么请看下面的场景是否合理,当我们玩一些电脑游戏的时候,那些游戏光下载就要10多个GB,假设我们电脑的内存只有4GB,除去其它内存占用,电脑可用内存只有3G,但是我们的电脑还能运行这个游戏,并且不卡顿,这个游戏占用10多个G啊,如何做到的,我们知道程序要运行那么程序的代码和数据就要加载到内存中,那么这个游戏加载到内存中,不应该是把内存占满然后卡死崩溃吗?为什么这里却运行的好好的?这也就说明我们的操作系统对大文件可以实现分批加载
- 我们现在有一个共识:现代操作系统几乎不做任何浪费时间和空间的事情,任何浪费时间和空间的事情,几乎都操作系统被优化了
- 假设要加载这个游戏程序占用内存10GB,操作系统给你3GB进行加载,那么对于大文件采取的是分批加载,程序假设先加载了500MB,让程序先跑起来,当这块内存用完了,那么释放到这块内存,再去加载下一批,所以此时就实现了对大文件的分批加载
- 但是加载了500MB,代码是一行行执行的,对于这500MB你进行加载代码和数据,但是由于代码是一行行执行的,在一个时间段内短期才只能用到5MB,那么剩下的495MB内存就相当于短期内不使用浪费掉了,其它进程也无法使用,那么由于进程调度,时间片,以及计算机CPU本身的配置,短期内加载的500MB内存用不了这么多,仅仅使用到5MB,对于多加载的495MB的内存短期内是用不上的,所以其实没有必要一次性加载这么多的内存,那么这就变成了将空间给你使用,但是你却没有充分的合理的去进行使用,那么这就造成了浪费
- 所以为了提高效率,同时最大化的合理利用内存,操作系统在这里采用了惰性加载的方式,即对于页表中左侧的虚拟地址我全部都填上,但是对于右侧对应的物理地址不不填,即并不实际的加载内存和数据或者加载的很少很少,即你虽然要运行这个游戏,即加载缓存这个游戏程序的代码和数据,但是此时我仅仅加载几MB的代码和数据,因为就算给你多了你短时间内也用不上,会造成浪费
- 那么当访问这个游戏时候,即访问游戏也就是访问代码和数据,那么就会访问进程地址空间,找到对应的虚拟地址,去页表上找对应的物理地址,可是此时由于我们并没有将游戏程序的代码和数据加载到内存,所以此时操作系统优先查看页表中的标识程序的代码和数据是否加载到内存之后,发现是没有加载到内存中,此时就会触发缺页中断,那么操作系统就会优先去对应的磁盘上找到对应的程序加载对应的代码和数据,去物理内存上申请内存,用于缓存程序对应的代码和数据,当缓存完成这一部分之后,那么此时就会利用MMU将物理内存上的物理地址映射到页表中对应的虚拟地址上即可,所以此时左侧进程管理模块就不需要关心右侧内存管理模块,我左侧进程管理模块不关心你右侧内存管理模块,当我左侧进程管理模块需要内存了,由操作系统出面向右侧内存管理模块要内存,所以也就实现了左侧进程管理模块和右侧内存管理模块的解耦合,如果不采用这种模式,那么左侧进程一旦需要内存,那么就要自己去调用内存去申请内存,并且左侧进程要可以感知到内存的申请情况,一旦内存不足此时内存的调度就会受到影响,此时形成了强耦合的情况,不利于进程的调度,所以要采用上面的方式解耦合
- 那么此时我们就可以回答一个问题了:进程在被创建的时候,是先创建内核数据结构呢?还是先加载可执行程序对应的代码和数据呢?
- 答案是先创建内核数据结构,由于有了页表的存在,以及缺页中断的机制,甚至可以做到仅仅有内核数据结构,仅有虚拟地址,不加载可执行程序对应的代码和数据,也就没有物理地址,所以虚拟地址在进程被创建的时候也就没有对应的物理地址,当需要程序对应的代码和数据的时候,通过缺页中断进行加载
六、验证命令行参数和环境变量的地址是在栈的地址之上
- 我们可以看到图片中命令行参数和环境变量的地址是在栈的地址的上面,关于命令行参数和环境变量我们接触的并不多,下面小编带领大家验证一下
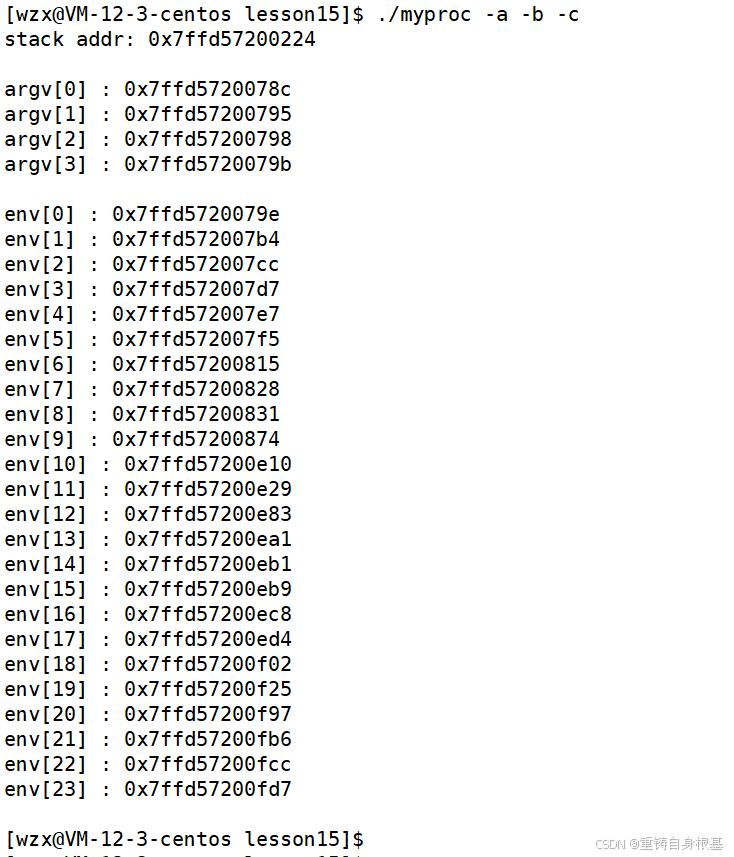
- 使用如下代码打印栈和命令行参数和环境变量的地址进行比较
#include int main(int argc, char* argv[], char* env[]){ int a = 0; printf(\"stack addr: %p\\n\\n\", &a); int i = 0; for(; argv[i]; i++)//命令行参数 { printf(\"argv[%d] : %p\\n\", i, argv[i]); } printf(\"\\n\"); int j = 0; for(; env[j]; j++)//环境变量 { printf(\"env[%d] : %p\\n\", j, env[j]); } printf(\"\\n\"); return 0;}运行结果如下
- 我们可以看出命令行参数和环境变量的地址是在栈的地址的上,并且环境变量的地址又是在命令行参数的地址之上
- 那么我们可以得出栈的地址之上是命令行参数的地址,命令行参数的地址之上是环境变量的地址
总结
以上就是今天的博客内容啦,希望对读者朋友们有帮助
水滴石穿,坚持就是胜利,读者朋友们可以点个关注
点赞收藏加关注,找到小编不迷路!


