机器学习算法系列专栏:K近邻(KNN)算法(初学者)
(一)机器学习
- 机器学习概念:利用数学中的公式,总结出数据中的规律
- 机器学习的步骤:

- 机器学习需要准备的库:numpy,scipy,matplotlib,pandas,sklearn
(二)KNN算法
(2.1)KNN算法概念
K近邻算法(K-Nearest Neighbors, 简称KNN)是一种简单却高效的机器学习算法,适用于分类和回归问题。它的核心思想是通过已知的训练数据集中的最近邻点来推断未知数据点的类别或数值

(2.2)KNN算法基本原理
对于一个新的输入实例,KNN会在训练数据集中找到与其距离最近的K个实例(称为“邻居”),如果用于分类,则根据这K个邻居所属类别的多数投票结果决定新实例的类别;如果是回归问题,则通常取这K个邻居目标值的平均作为预测值
(2.3)距离度量方式
为了判断两个样本之间的相似程度,KNN常用欧氏距离(Euclidean Distance),曼哈顿距离(Manhattan Distance)或其他形式的距离函数来进行测量
(2.3.1)常见机器学习算法使用的距离计算公式
(1)欧氏距离:是最容易直观理解的距离度量方法,我们小学、初中和高中接触到的两个点在空间中的距离一般都是指欧氏距离

(2)曼哈顿距离:在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离,这个实际驾驶距离就是“曼哈顿距离”,曼哈顿距离也称为“城市街区距离”(City Block distance)

(三)K近邻(KNN)算法用于(分类/回归)任务
(3.1)KNN用于分类任务
(3.1.1)基本流程
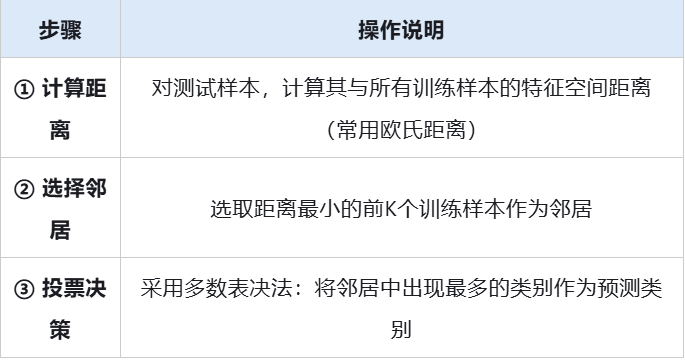
(3.1.2)具体案例1
鸢尾花数据集分类
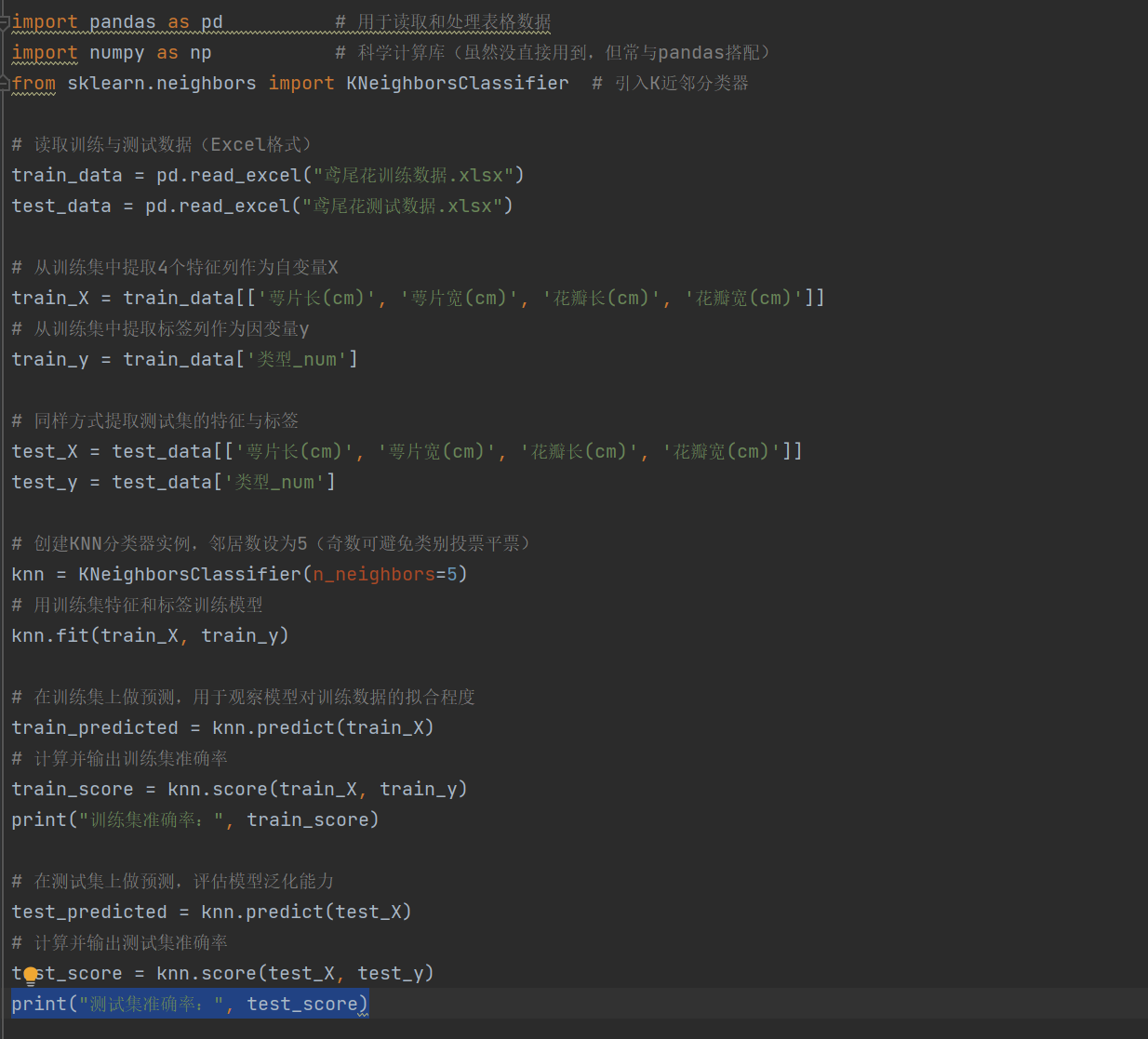
用经典的 K 近邻(KNN)算法,根据鸢尾花的 4 个测量指标(萼片长、萼片宽、花瓣长、花瓣宽)训练一个分类器,实现对新花朵品种的自动识别
具体步骤:
- 把 4 个数值型特征作为输入 X
- 把已标注的“类型编号”作为输出 y
- 选用 KNeighborsClassifier,邻居数设为 5
- 用训练集数据完成模型训练
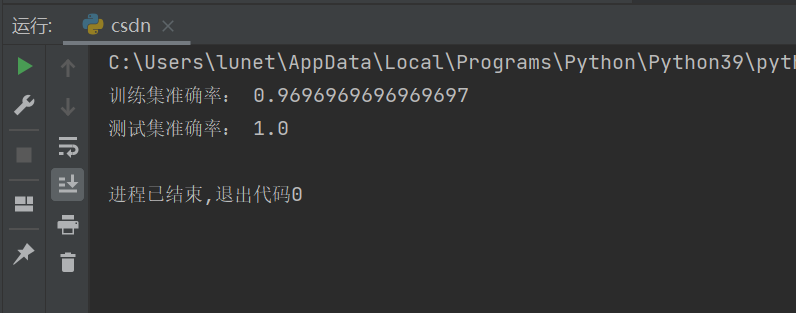
- 先在训练集上自测,查看“记忆”能力
- 再在独立测试集上预测,查看“泛化”能力
- 打印两个准确率,直观反映模型表现
代码实现:
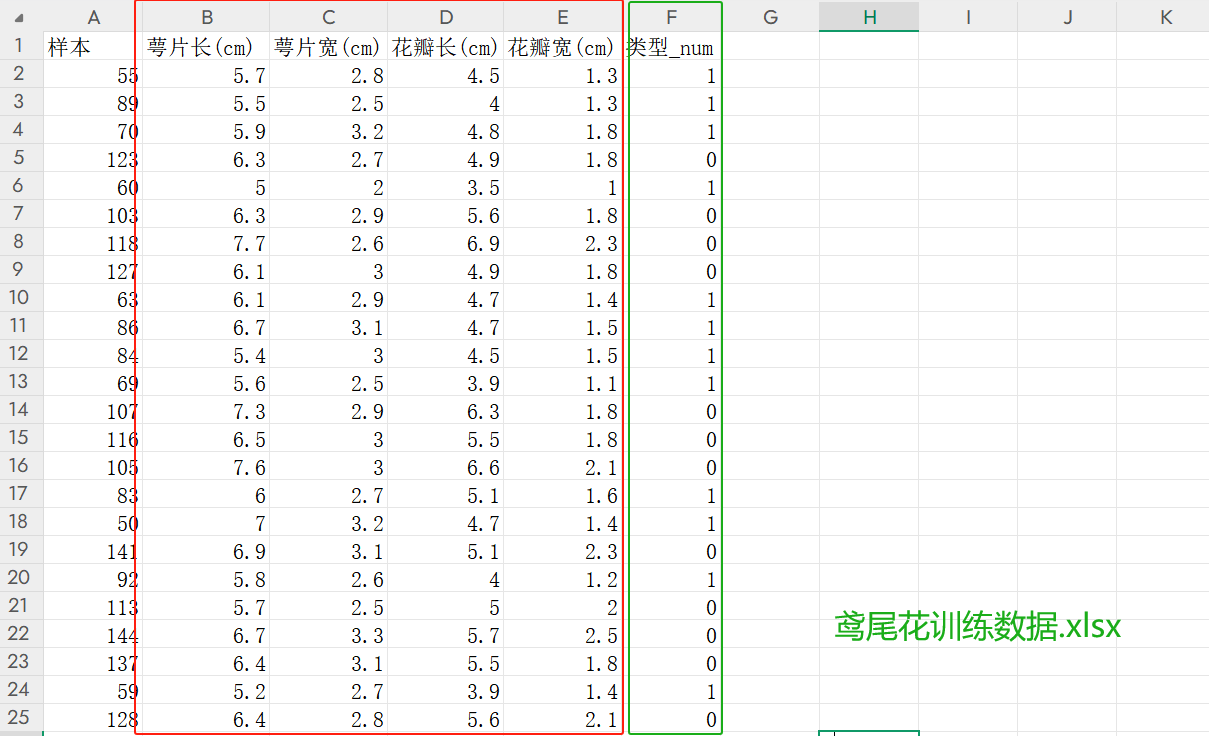
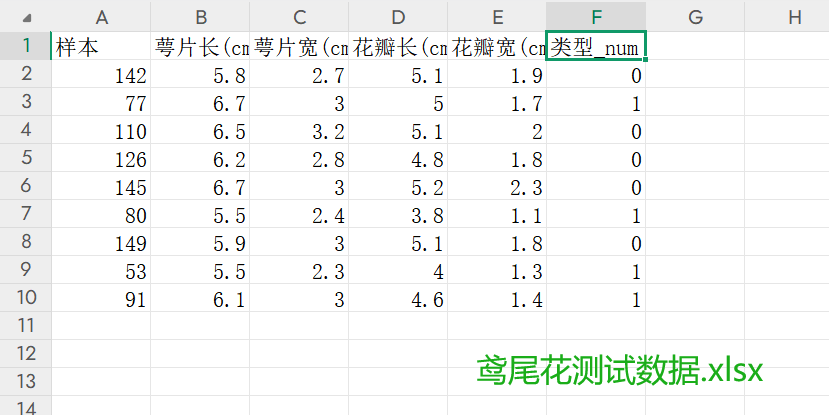
鸢尾花训练数据.xlsx和鸢尾花测试数据.xlsx:
运行结果:
(3.1.3)具体案例2

任务目标:
- 利用人工智能模型knn算法, 实现寝室的分配,将相同类型的分配在同一个寝室,爱学习的在一起,一般般在一起,爱玩在一起
- 历史数据:从大三、大四的学长得到历史数据,通过调查问卷来调查学生的特征,由负责的辅导员来决定学生的结果
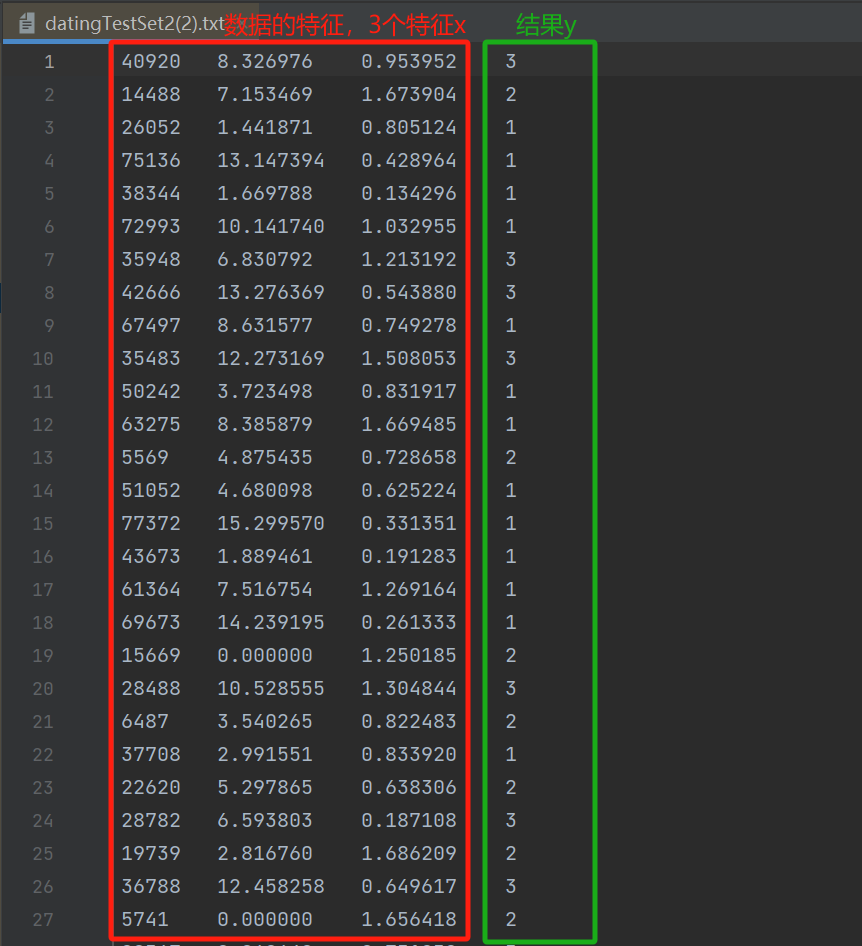
- 学生玩游戏的时间、看书的时间、旅游的路程
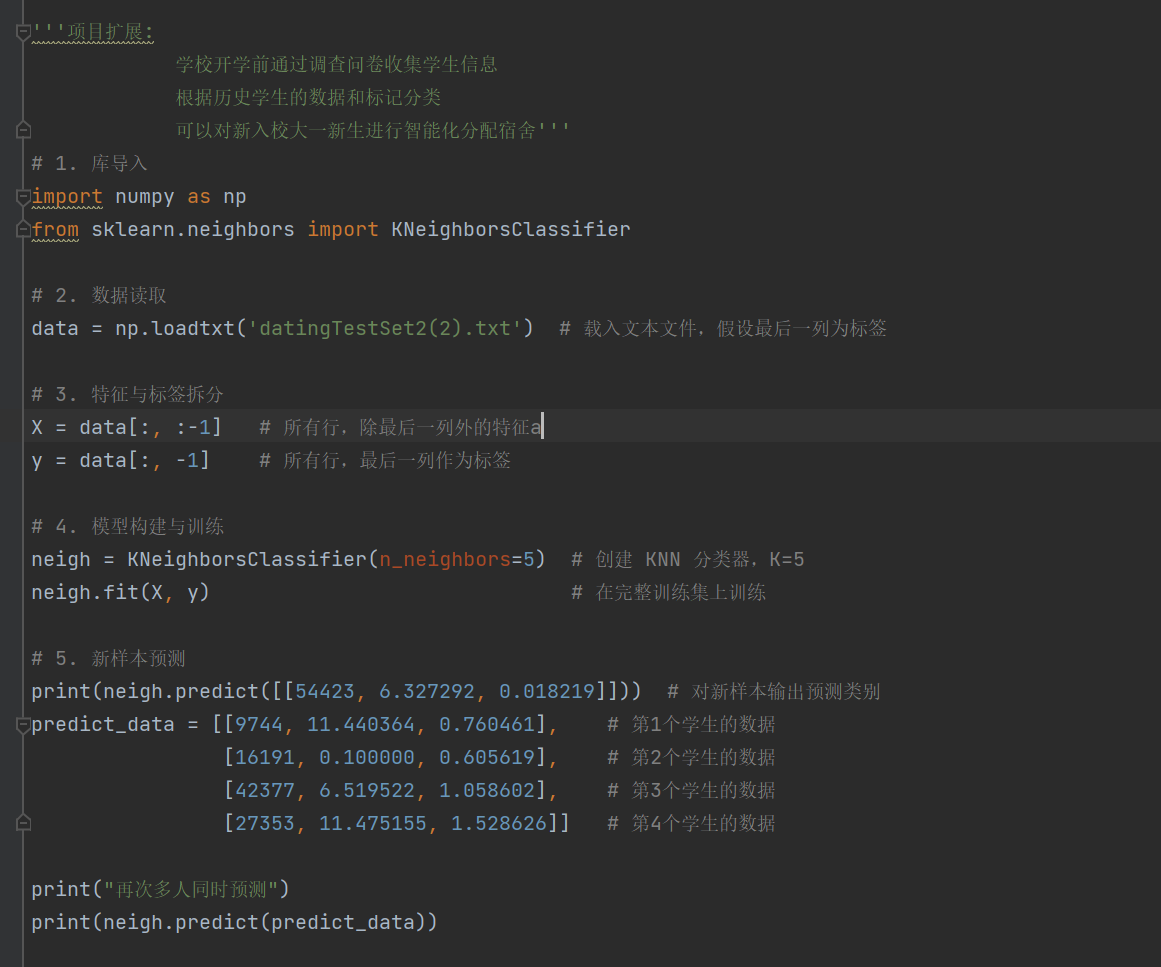
- knn算法实现模型KNeighborsClassifier([..])
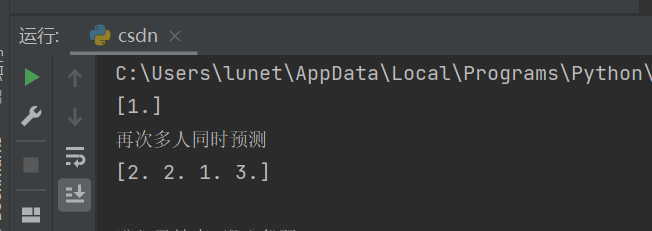
- 新的数据(大一的学生,提前预判学生是1、2、3)
代码实现:
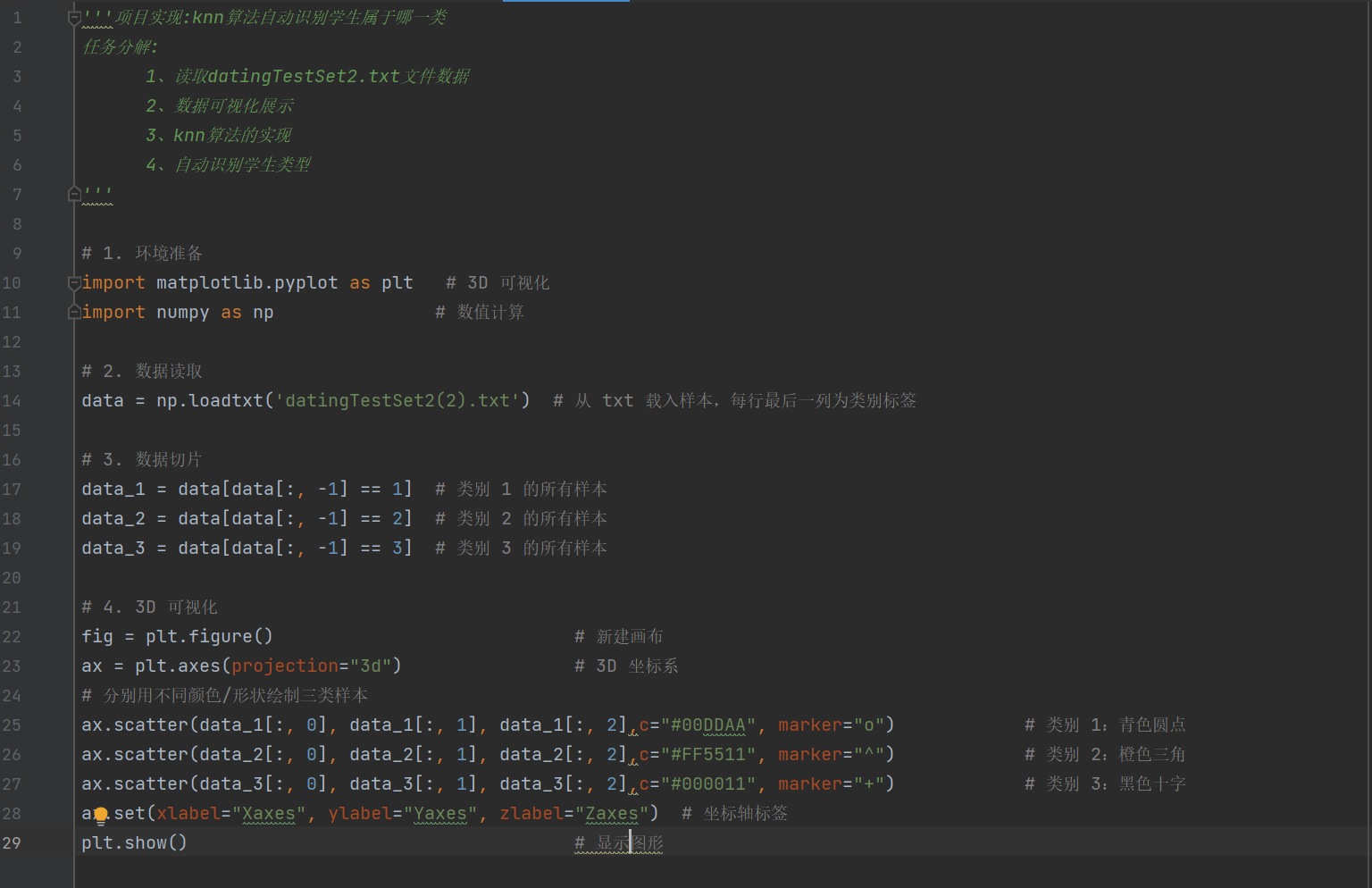
文本文件 datingTestSet2(2).txt 内容:
运行结果:
(3.1.4)具体案例3
手写数字的识别
- 使用knn算法模型
- 数据集:1张图片(2000像素宽度*1000像素高度)(包含100*50个手写数字)
- 将该张图片切割成5000份,每份占20*20像素(也就是说一个数字20*20像素)
- 通过opencv-python第三方库(专门用来读取视频,图片,摄像头,推流...)读取该图片,得到矩阵,该矩阵是图片的亮度值0~255(0为黑色,255为白色)
- 将5000份手写数字 切分出来,[00....200...]1*400的数据,直接当作是数字的特征
- 将数据切分成训练集和测试集
- 数据展开成400列
- [00...220.....] 0
- [00...220.....] 1
- [00...220.....] 2
- [00...220.....] 3
- [00...220.....] 4
- [00...220.....] 5
- [00...220.....] 6
- [00...220.....] 7
- [00...220.....] 8
- [00...220.....] 9
- 添加y
- knn算法训练
- 模型的好坏
代码实现:
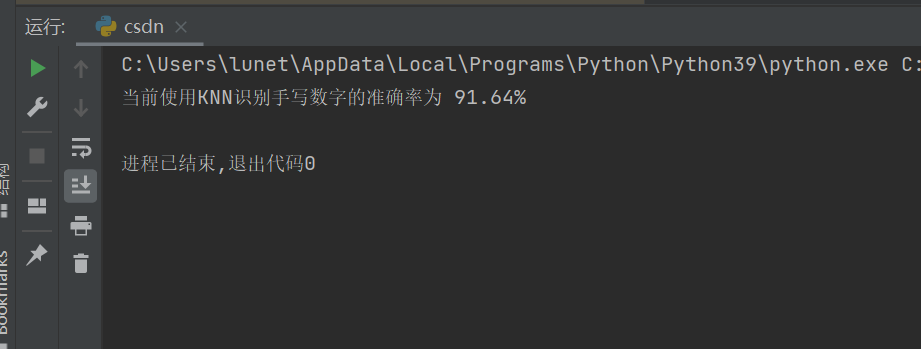
# 1. 环境准备 & 依赖导入import numpy as npimport cv2# 2. 读取并预处理原始图像# 2.1 以彩色方式读入 text.png# 2.2 转为灰度图,方便后续处理img = cv2.imread(\"text.png\")gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 3. 将整幅大图像切割成单个数字小图# 3.1 纵向切成 50 行# 3.2 每行横向再切成 100 列# 3.3 组装成 4 维数组 (50,100,20,20)cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]x = np.array(cells)# 4. 划分训练集 & 测试集# 训练集:每行前 50 列# 测试集:每行后 50 列train = x[:, :50]test = x[:, 50:100]# 5. 数据整形与类型转换# 5.1 把 20×20 的二维小图展平成 1×400 的向量# 5.2 转换为 float32,适配 OpenCV KNN 要求train_new = train.reshape(-1, 400).astype(np.float32)test_new = test.reshape(-1, 400).astype(np.float32)# 6. 生成对应标签# 6.1 数字 0–9 重复 250 次 → (2500,)# 6.2 转成列向量 (2500,1)k = np.arange(10)labels = np.repeat(k, 250)train_labels = labels[:, np.newaxis]test_labels = np.repeat(k, 250)[:, np.newaxis]# 7. 构建并训练 KNN 模型# 7.1 创建 OpenCV KNN 对象# 7.2 用训练数据与标签完成训练knn = cv2.ml.KNearest_create()knn.train(train_new, cv2.ml.ROW_SAMPLE, train_labels)# 8. 在测试集上预测并评估# 8.1 执行 K=3 的最近邻搜索# 8.2 计算预测准确率ret, result, neighbours, dist = knn.findNearest(test_new, k=3)matches = result == test_labelscorrect = np.count_nonzero(matches)accuracy = correct * 100.0 / result.sizeprint(\"当前使用KNN识别手写数字的准确率为 {:.2f}%\".format(accuracy))运行结果:
text.png内容:

(3.2)KNN用于回归任务
(3.2.1)基本流程

(3.2.2)具体案例
卖蓝色房子价格:
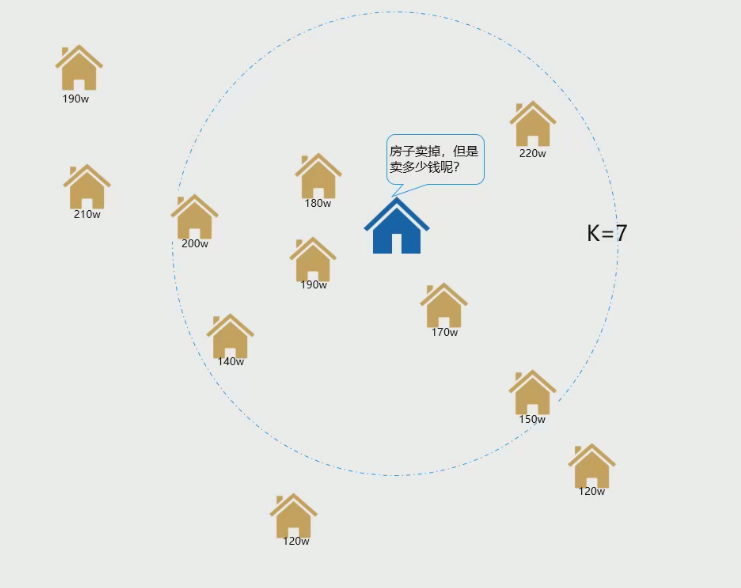
- 历史数据(黄色房子价格就是历史数据),(坐标位置x,y,price已知)
- 预测蓝色新数据(坐标位置x,y已知,没有price)
- 选择k值,例如k=7
- 将所有黄色房子和蓝色房子的距离都计算出来,进行从小到大排序
将距离最小的前7个黄色房子的price进行平均值计算
\"\"\"步骤 1. 环境准备\"\"\"import numpy as npfrom sklearn.neighbors import KNeighborsRegressor # KNN 回归器\"\"\"步骤 2. 构造历史数据(黄色房子) 这里用随机数演示,实际替换成你的 CSV / Excel / 数据库读取即可\"\"\"# 历史坐标及价格yellow_X = np.array([ [1.0, 2.0], [3.5, 4.1], [5.2, 1.8], [2.3, 3.3], [4.4, 4.4], [6.1, 2.9], [7.0, 3.5], [2.8, 1.1], [3.3, 5.0], [5.9, 5.9]], dtype=np.float32)yellow_y = np.array([ 100, 250, 180, 220, 300, 270, 330, 150, 310, 390], dtype=np.float32).reshape(-1, 1) # 列向量\"\"\"步骤 3. 构造待预测数据(蓝色房子)\"\"\"blue_X = np.array([ [2.0, 2.5], [4.0, 3.0], [6.5, 4.5]], dtype=np.float32)\"\"\"步骤 4. 选择 k 值并训练 KNN 回归模型\"\"\"k = 7knn_reg = KNeighborsRegressor(n_neighbors=k, weights=\'distance\') # 权重可选 \'uniform\' 或 \'distance\'knn_reg.fit(yellow_X, yellow_y) # 用历史数据训练\"\"\"步骤 5. 对蓝色房子做价格预测\"\"\"blue_pred = knn_reg.predict(blue_X)\"\"\"步骤 6. 输出结果\"\"\"print(\"蓝色房子预测价格:\")for coord, price in zip(blue_X, blue_pred.flatten()): print(f\"坐标 {coord} → 预测价格 {price:.2f}\")代码运行结果:
蓝色房子预测价格:坐标 [2. 2.5] → 预测价格 190.00坐标 [4. 3. ] → 预测价格 260.00坐标 [6.5 4.5] → 预测价格 350.00额外补充:
- 若数据量大,可从 CSV / Excel 读取
df = pd.read_csv(\"house.csv\")yellow_X = df[[\'x\', \'y\']].valuesyellow_y = df[\'price\'].values.reshape(-1, 1)

