YOLOv8 剪枝模型加载踩坑记:解决 YAML 覆盖剪枝结构的问题
1. 问题背景
模型剪枝是实现模型轻量化、加速推理的关键步骤。然而,在 Ultralytics YOLOv8 的生态中,在成功剪枝后,进行微调(Fine-tuning)时会遇到一个令人困惑的现象:明明加载的是剪枝后的模型(例如 20M 参数),但训练启动时打印的日志却显示为标准版模型的参数(例如 25M)。并且经过验证,微调后的模型参数就是标准的yolo模型。
加载代码如下:
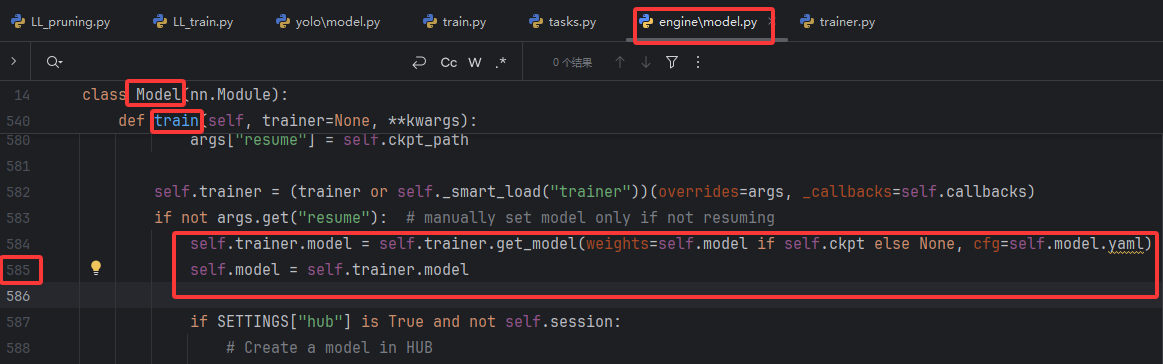
model = YOLO(\"pruned.pt\") # load a pretrained model (recommended for training) model.train(data=name_yaml, device=0, imgsz=640, epochs=50, batch=32, workers=16, name=path_fineturn) # train the model原因是Ultralytics 的 Trainer 仍会先依据 原始 YAML 构建标准结构(约 25M 参数)。随后仅将 .pt 文件中的权重加载到这张标准结构中。
2. 代码触发点与根本原因
问题的根源在于 Ultralytics 的 Trainer 在初始化模型时(get_model 方法)的执行顺序。
在ultralytics/engine/model.py中的Model类的train()方法中,原始代码如下:
self.trainer.get_model 方法的执行流程如下:
-
优先使用
cfg参数构建模型:该参数接收 cfg=self.model.yaml。由于 pruned.pt 在保存时不会自动更新其内部的 YAML 配置( model = YOLO(\"pruned.pt\")会构造出一个实例,里面的self.model有很多属性,其中self.model.model是模型网络,这是真正的、由网络层构成的可执行实体。我们的剪枝操作直接修改了这个对象,比如减少了某些卷积层的通道数,从而改变了它的实际结构。self.model.yaml是配置文件,剪枝时只修改了self.model.model,没有更新原始的self.model.yaml),所以这里的self.model.yaml仍然是标准版 YOLOv8m 的网络结构。 -
创建标准结构并打印摘要:
get_model会立即执行model = DetectionModel(cfg)通过self.model.yaml来构建一个完整的未剪枝模型(25.8M)。随后调用model.info()方法,这就是日志中显示\"标准版\"摘要的原因。完成标准结构创建后,get_model才会处理 weights 参数,将 pruned.pt 中的权重加载到刚创建的标准结构中。PyTorch 的load_state_dict会按照名称和形状匹配的原则加载对应层的权重,跳过不匹配的层,此时模型仍保持标准骨架结构。
3. 改进写法(实际切换到剪枝后结构)
为了解决这个问题,我们必须在 Trainer 开始训练前,确保其内部持有的模型对象是我们剪枝后的那一个。
将代码调整为:
if not args.get(\"resume\"): # manually set model only if not resuming self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml) # ★ 关键修正:用我们剪枝后的模型对象,替换掉 Trainer 内部刚刚由 YAML 创建的模型 self.trainer.model.model = self.model.model print(\"\\n--- Verifying model after swapping in Trainer ---\") # 打印替换后的模型参数量 params_after_swap = sum(p.numel() for p in self.trainer.model.model.parameters()) / 1e6 print(f\"Parameters inside trainer: {params_after_swap:.2f}M\\n\") # 应显示约 20.8M self.model = self.trainer.model if SETTINGS[\"hub\"] is True and not self.session: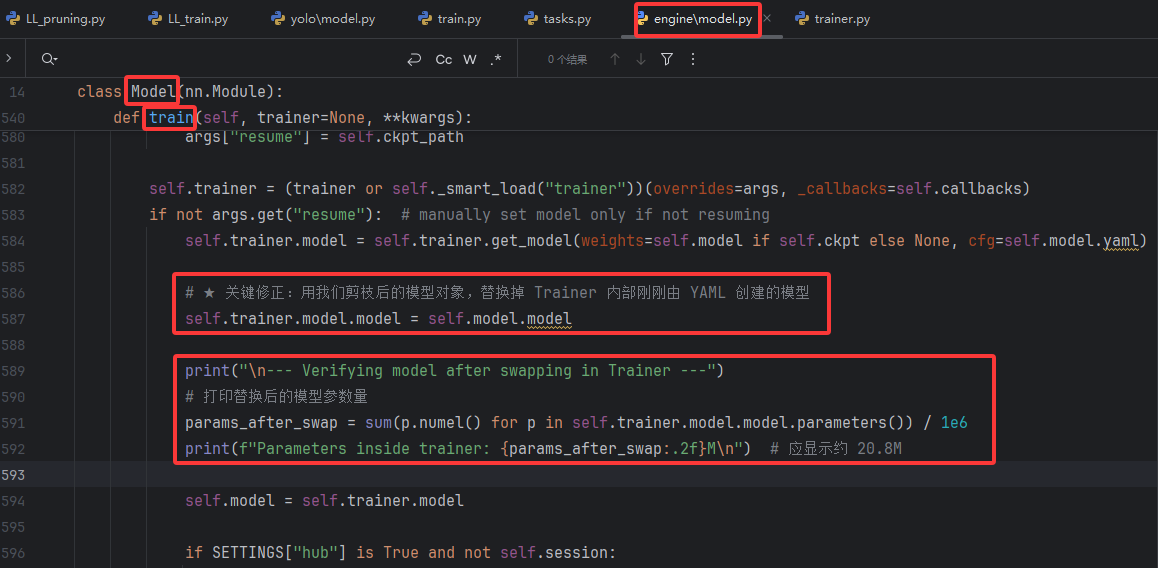
-
依然允许
get_model按部就班地完成它的初始化流程(包括打印那条“误导性”的日志)。 -
但在这之后,立即通过
self.trainer.model.model = self.model.model这行代码,强行将Trainer内部的nn.Module对象替换为我们真正的、剪枝后的模型 (self.model.model)。 -
启动阶段的日志已打印过标准版结构,因此显示上仍是标准参数量,但通过打印替换后的模型对象的参数量可以看到已经替换为剪枝后的模型。
深度解析:为什么是替换 .model.model 而不是 .model?
-
yolo.model对象 (DetectionModel等BaseModel的实例)
它是一个“功能完备的检测器”,不仅包含了网络结构,还封装了与之相关的元数据和方法(如.train(),.info(),.yaml等)。把它理解为一个高级接口。 -
yolo.model.model对象 (纯nn.Module实例)
这才是我们通常意义上所说的PyTorch 模型网络。它是一个纯粹的torch.nn.Module子类,由各种网络层搭建而成。我们的剪枝操作,直接修改的就是这个对象。
为什么不写成 self.trainer.model = self.model?
-
源(Source):
self.model.model是我们从加载的pruned.pt中取出的、那个已经被剪枝过的纯粹网络结构。 -
目标(Destination):
self.trainer.model.model是Trainer内部那个标准结构的纯粹网络。
self.trainer.model 是一个高级的 BaseModel 对象,Trainer 在初始化时已经对其进行了一些配置(如设备分配等)。如果我们用self.trainer.model = self.model整个地替换掉它,可能会破坏这些已经完成的设置,存在潜在风险。只替换最底层的 nn.Module,既能保证网络结构正确,又不会干扰 Trainer 的其他工作流程。
注意替换模型必须在self.trainer.model构建好之后,如果直接使用self.trainer.model.model = self.model.model会显示self.trainer.model是个str,还不是对象。
4. 显示不一致的原因
-
Summary 打印时机:
get_model在构建标准结构后立即输出层数与参数量。 -
结构替换发生在 summary 之后:没有重新打印,因此日志没有更新为剪枝后的参数量。
-
保存阶段:调用
model.save()或torch.save({\'model\': ...})时,写入的是替换后的剪枝模型对象,所以最终.pt文件尺寸/参数量正确。
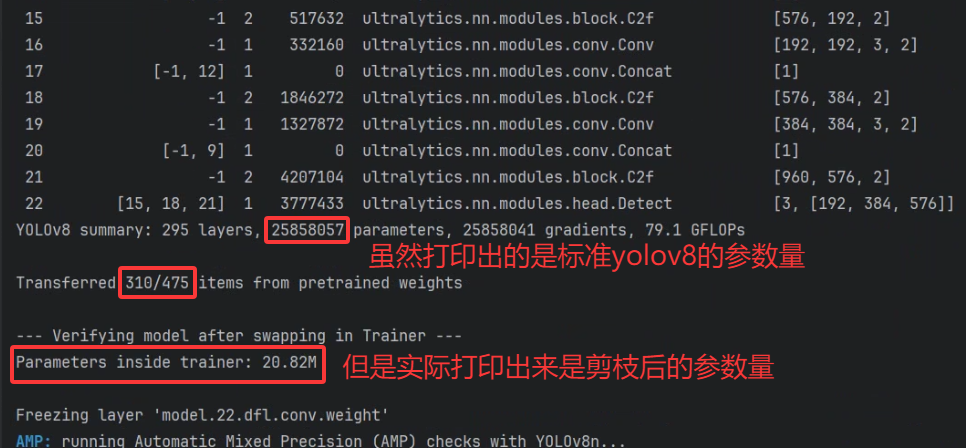
5. 验证流程建议
为了确保操作是正确的,最好进行验证。
步骤 1:验证初始剪枝模型
在开始微调训练前,先确认 pruned.pt 是真的被剪枝了。
from ultralytics import YOLOinitial_model = YOLO(\"pruned.pt\")print(\"--- Verifying initial pruned model ---\")initial_model.model.info(verbose=False) # 应显示约 20.8M 参数步骤 2:在替换后立即验证
在修正代码的核心行之后,立刻加入打印验证,就是之前的代码。
# ...self.trainer.model.model = self.model.modelprint(\"\\n--- Verifying model after swapping in Trainer ---\")# 打印替换后的模型参数量params_after_swap = sum(p.numel() for p in self.trainer.model.model.parameters()) / 1e6print(f\"Parameters inside trainer: {params_after_swap:.2f}M\\n\") # 应显示约 20.8M步骤 3:验证最终保存的模型
训练结束后,加载最终生成的权重文件,再次确认。
final_model = YOLO(\"runs/train/exp/weights/last.pt\")print(\"--- Verifying final saved model ---\")final_model.model.info() # 应显示约 20.8M 参数结果如图:


