【文章分享】基于NLP的非结构化高维大数据时序特征提取方法_非结构化数据处理nlp模型
1、简介
非结构化文本数据呈爆炸式增长,从非结构化高维大数据中提取有效的时间维度特征具有重要意义。因此,提出了一种基于 NLP 的非结构化高维大数据时间维度特征提取方法。通过 NLP 深度学习模型,结合关联规则挖掘技术和特征量化方法,对非结构化多维大数据的时间维度进行有效的特征提取优化。应用并行数据流重构和模糊 C 聚类算法搜索高维大数据并排列信息。基于空间框架,实现了非结构化高维大数据分析中时间视角特征提取的优化。
2、内容
2.1 维度特征提取模型
1、非结构化高维大数据时间维重建算法
非结构化高维大数据包含大量文本、图像、音频等非结构化信息数据集。其中,时间信息以自然语言形式存在,比如日期、时间戳和事件描述。通过非结构化时间信息转化为时间维度特征,可以采用预定义正则表达式匹配文本中的日期、时间等信息。针对不同语言和日期格式制定相应的正则表达式:
其中,分别表示字符串的起始和结束位置,
表示单词边界,
表示字符出现的次数。
对于时间信息,需要解析时、分、秒等组成部分,可以通过时间解析库或者自定义解析库实现。讲解析后的时间信息转化为统一的时间格式(如ISO8601标准格式),便于后续处理和分析。对于包含时区的时间信息构建时间序列。基于该时间序列,可以生成一系列的时间维度,比如:时间戳、时间维度(工作日、周末、节假日等)、时间间隔(事件间的时间差)、时间趋势(上升趋势、下降趋势等)。
2、基于熵权法的非结构化高维大数据时序特征提取
针对多维场景下的数据处理和特征提取,提出了一种融合信息熵的多维场景信息提取方法。该方法基于滑动窗口的原理,将数据划分为固定大小的窗口,并以固定步长在数据序列上滑动,实现动态数据更新和分析。将数据转化为结构化形式,提取关键特征向量。初始特征向量可能不完全适应于后续分析,需要根据数据特性和分析目标进行特征变换与融合,确保特征向量能够准确反映数据的本质。
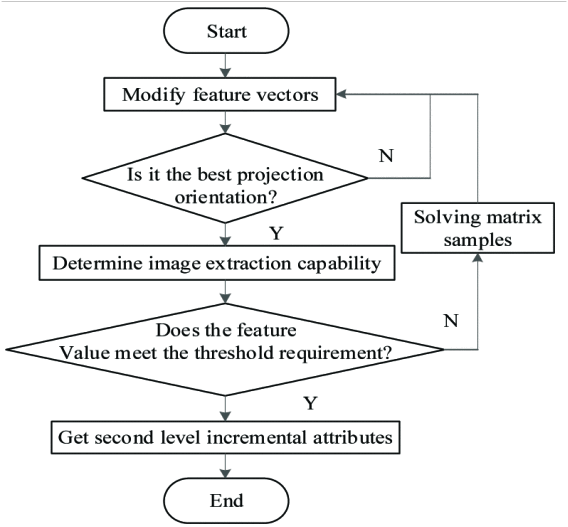
在特征提取过程中,选择合适的投影方向,将数据能够从高维空间映射至低维空间,同时最大限度保留有效信息。针对包含图像数据的非结构化数,需要评估其图像的提取能力。在设置阈值的基础上对各特征进行定量评估:构建具有m个指标和n个目标的网络样本矩阵f,并计算第i个指标的熵值和熵权:
信息熵低于阈值的特征被认为式次要特征,并且从特征集中剔除。
特征提取和选择后,构建特征矩阵来表示数据,矩阵的每一行表示一个数据样本,每一列表示一个特征,通过直接求解矩阵样本,计算特征值f:
两级增量属性是一个新功能,可以揭示数据之间更深层次的关系。为了进一步挖掘数据中隐藏的信息或者关系,采用机器学习算法计算两级增量属性。其中,self-encoder是一种无监督神经网络,用于学习数据的低维表征。通过将原始特征作为输入,提取编码层的表征作为二级增量属性。非结构化高维大数据的时间维度特征提取过程如下图所示:
2.2 基于NLP的维度特征提取优化
在自然语言处理任务中,文本预处理是关键环节,其包含但不限于以下步骤:
1、词汇处理:分词、停顿词过了、词干提取、词性还原等;
2、向量化表示:将文本转化为词频向量,统计词语出现频次;
3、向量加权:结合TF-IDF量化词语重要性;
4、语义表征:采用Word2vec、GloVe或BERT等预训练模型生成稠密向量,捕获语义信息;
5、关系抽取:通过依赖解析、语义角色标注等技术提取文本实体之间的关系信息。
其中,NLP提取优化模型如下图:
如上图,利用关联规则挖掘技术,有效挖掘非结构化高维大数据的时序维度信息。在NLP的训练框架下,
1、将NLP训练任务设定为T;
2、将非结构化高维大数据时间维度的信息提取任务设置为d;
3、分配各提取任务所需时间资源;
特征提取方案的完成时间如下:
利用并行数据流重建方法,结合NLP的深度学习计算,实现非结构化高维大数据的关键指标特征提取,从而能够在时限层面完成对获取数据的特征提取分析。在图像数据中进行特征提取的过程中,假设该参数为o,在时间限制角度设置序列标量,并使用特征量化关联规则阐明特征提取方法是应用范围。然后,结合模糊推理方法的推断,得到对数据流内容进行特征提取时产生的最大差值G,公式如下:
采用自动相关系数法,从分布式网络节点中提取关联规则并完成自动相关系数计算。在时间维度数据架构下,提供与分布式网络结构节点相关的数据流规则,通过非线性时间序列方法从时间层面获取数据流模型,然后结合模糊C聚类算法搜索高维度大数据,在线性时间条件下分配和排列信息。数据访问过程中的可靠性指标C表示为:
在该模型中,参数Z表示依据关联规则进行样本提取的优先顺序。基于时序维度分析,构建了空间化分析框架以获取数据信息流,具体实现过程如下:
-
通过聚类计算C建立空间结构基础
-
在时空耦合框架下实现非结构化高维大数据的特征提取优化
参考文章:一种基于 NLP 的非结构化高维大数据提取时间维度特征的方法 |IEEE 会议出版物 |IEEE Xplore


