Lua语言程序设计1:基础知识、数值、字符串与表
文章目录
- 第一章:Lua语言入门
-
- 1.1 Chunk(程序段)
-
- 1.1.1 Chunk
- 1.1.2 加载外部代码:prog、dofile 与 require
- 1.2 词法规范:标识符、保留字与注释
- 1.3 全局变量
- 1.4 数据类型和值
-
- 1.4.1 基本数据类型
- 1.4.2 nil类型
- 1.4.3 布尔类型与逻辑运算
- 1.5 独立解释器
-
- 1.5.1 脚本头部“#!”支持
- 1.5.2 命令行参数
- 1.5.3 环境变量
- 1.5.4 使用arg获取脚本参数
- 1.6 实战练习与答案参考
- 第二章:八皇后问题
-
- 2.1 背景
- 2.2 核心算法:回溯(Backtracking)
- 2.3 完整代码
- 2.5 练习与扩展
- 第三章:数值
- 第四章:字符串
-
- 4.1 转义字符
- 4.2 长字符串/多行字符串
- 4.3 类型转换
-
- 4.3.1 自动类型转换
- 4.3.2 字符串转换为数字(tonumber)
- 4.3.3 数字转换为字符串(tostring)
- 4.4 字符串标准库
- 4.5 Lua 中的 Unicode 和 UTF-8 支持
- 4.6 练习
- 第五章:表
-
- 5.1 表索引
- 5.2 表构造器
- 5.3 数组、列表和序列
- 5.4 遍历表
- 5.5 使用 `or {}`安全访问表字段
- 5.6 标准库table
第一章:Lua语言入门
Lua 是一门轻量级、可嵌入的脚本语言,以简洁高效著称,广泛应用于游戏开发、配置文件、嵌入式系统等地方。它的核心设计哲学是简单灵活,不仅是一门编程语言,也是一种数据描述格式。作为传统,我们从最简单的“Hello World”开始:
print(\"Hello World\")运行方式有两种:
- 交互式模式:直接输入
lua命令,进入 REPL(交互式解释器),逐行执行代码。 - 脚本模式:将代码保存为
hello.lua文件,执行lua hello.lua运行。
1.1 Chunk(程序段)
1.1.1 Chunk
Lua 中,每一段可执行的代码称为一个 Chunk。Chunk 可以是一个文件、一行交互式命令。例如:
-- 定义阶乘函数function fact(n) if n == 0 then return 1 else return n * fact(n - 1) endendprint(\"enter a number:\")a = io.read(\"*n\") -- 读取用户输入的数字print(fact(a))注意:Chunk 可以非常大,Lua 解释器对大小没有限制,几兆字节的 Chunk 也很常见。
交互式编程:Lua 5.3 开始,交互式模式下可以直接输入表达式,Lua 会自动打印结果。按下回车后Lua解释器会把每一行当成完整的程序块或表达式来执行。若检测到行未结束,解释器会等待后续输入直至完整,再统一解释执行。这样,我们也可以直接在交互模式下输入一个像阶乘函数示例那样的由很多行组成的多行定义,但通常做法是将其保存为代码文件后执行。
luaLua 5.3 Copyright (C) 1994-2016 Lua.org, PUC-Rio> math.pi / 40.78539816339745> a = 15> a^2225如果不想输出结果,可以在行末加上一个分号。分号使得最后一行在语法上变成了无效的表达式,但可以被当作有效的命令执行。
> io. flush()> true> io. flush();> 旧版本(如 5.2)需要加 = 前缀:
> =a^2225退出交互模式:按 Ctrl+D(Linux/macOS)或 Ctrl+Z(Windows),或输入 os.exit()。
1.1.2 加载外部代码:prog、dofile 与 require
-
-i:
-i参数可以让Lua解释器在执行完指定的程序段后进入交互模式,方便调试和手动测试。比如lua -i prog会先执行文件prog中的所有代码,然后进入交互模式。 -
dofile:在交互模式下调用 dofile 函数,可以立即加载并执行指定文件。
-- lib1.luafunction norm(x, y) return math.sqrt(x^2 + y^2)endfunction twice(x) return 2.0 * xend> dofile(\"lib1.lua\") -- 加载库> n = norm(3.4, 1.0)> twice(n)7.0880180586677在项目开发时,可打开两个窗口。第一个窗口编辑代码文件,例如
lib1.lua;文件保存后在第二个窗口(交互式编辑)中使用dofile(\"lib1.lua\")重新载入并测试,实现快速迭代。 -
require:模块化加载,会缓存结果,适合正式项目(后续章节详解)。
1.2 词法规范:标识符、保留字与注释
-
标识符规则:由字母、数字、下划线组成,不能以数字开头。
- 通常将“下画线+小写字母”组成的标识符用作哑变量(Dummy variable ),即临时变量。例如
_temp; - “下画线+大写字母”(如
_VERSION,_GLOBAL)组成的标识被Lua语言本身、库或框架保留,用于存储关键信息,应避免用作其他用途,否则可能会覆盖或冲突系统/库的默认值。
- 通常将“下画线+小写字母”组成的标识符用作哑变量(Dummy variable ),即临时变量。例如
-
保留字:以下单词为保留字,不能作为标识符:
and break do else elseif end false for function gotoif in local nil not or repeat return then true until whileLua语言是对大小写敏感的,
and是保留字,但And和AND就是两个不同的标识符。 -
注释写法
- 单行注释:
-- 这是注释 - 多行注释:
--[[ 这是多行注释 ]] - 取消多行注释:在第一行行首添加一个连字符即可快速取消多行注释,即
---[[ 取消行注释 ]]
--[[print(\"这行被注释掉了\")--]]---[[print(\"这行被激活了\")--]] - 单行注释:
Lua 的语法允许你连续写多条语句,且不需要在它们之间加任何分隔符(分号和换行符),以下写法都是等价的:
a = 1b = a * 2a = 1; b = a * 2-- 可读性差,不推荐a = 1 b = a * 2作者的习惯是:
- 几乎不会在同一行写多条语句,所以也就几乎不用分号。
- 如果非要写在一行,推荐使用分号
1.3 全局变量
在Lua语言中,全局变量(GlobalVariable)无须声明即可使用,使用未经初始化的全
局变量也不会导致错误(结果是nil):
> print(b) -- 未定义nil如果将一个全局变量赋值为nil,相当于删除了它,Lua会回收该变量占用的内存。所以,Lua语言不区分未初始化变量和被赋值为nil的变量。
> b = 10> print(b)10> b = nil> print(b)nil1.4 数据类型和值
1.4.1 基本数据类型
Lua一共有8种数据类型,可以使用 type() 函数来查看:
niltrue, false10, 3.14\"hello\"{}printio.stdincoroutine.create(...)> type(nil) --> nil> type(true) --> boolean> type(10.4 * 3) --> number> type(\"Hello world\") --> string> type(io.stdin) --> userdata> type(print) --> function> type(type) --> function> type({}) --> table> type(type(X)) --> string不管X是什么,最后一行返回的永远是\"string\"。这是因为函数type的返回值永远是一个字符串。
Lua语言是一种动态类型语言(Dynamically-typed language ),在这种语言中没有类型定义(type definition),每个值都带有其自身的类型信息。也就是说,变量没有预定义的类型,任何变量都可以包含任何类型的值:
> type(a) --> nil (\'a\' 尚未初始化)> a = 10> type(a) --> number> a = \"a string!!\"> type(a) --> string> a = nil> type(a) --> nil一般情况下,将一个变量用作不同类型时会导致代码的可读性不佳,但是在某些情况下谨慎地使用这个特性可能会带来一定程度的便利。例如,当代码发生异常时可以返回一个
nil以区别于其他正常情况下的返回值。
1.4.2 nil类型
nil类型只有一个nil值,Lua语言用它来表示无效值(non-value,即没有有用的值)的情况。一个
全局变量在第一次被赋值前的默认值就是nil,而将nil赋值给全局变量则相当于将其删除。
1.4.3 布尔类型与逻辑运算
Boolean类型具有两个值,true和false。在Lua中,只有 nil 和 false 为假,其余均为真(包括 0 和空字符串 \"\")。Lua语言支持常见的逻辑运算符:and、or和 not。
and:第一个为假则返回第一个,否则返回第二个。or:第一个为真则返回第一个,否则返回第二个。not:总是返回布尔值。
> 4 and 5 -- 4 为真,返回 5> nil and 13 -- nil 为假,返回 nil> false and 13 -- false 为假,返回 false> 0 or 5 -- 0 为真,返回 0> false or \"hi\"-- false 为假,返回 \"hi\"> not 0 --> 0 为真,not 0 为 false> not nil --> true> not false --> true> not not 1 --> true> not not nil --> falseand 和 or 都遵循短路求值(Short-circuit evaluation)原则,如果第一个操作数已经能够决定整个表达式的结果,就不再计算第二个操作数,避免无效或危险操作。
a and b:如果a是 假值(nil 或 false),整个表达式一定是假,不会计算b。如果a是真值,才会继续计算b;a or b:如果a是 真值,整个表达式一定是真,不会计算b。如果a是假值,才会继续计算b。
-
除零计算:在表达式
(i ~= 0 and a / i > b)(~=是不等于符号)中,如果i == 0,则i ~= 0为假,整个表达式必为假,不会再计算a / i,从而避免除零错误。 -
设置默认值:常见写法是
x = x or v,这等价于:if not x then x = v end即当 x 为 nil 或 false 时赋予其默认值 v。
-
模拟三元运算符:由于
and运算符的优先级高于or,所以当b不为false时,以下表达式是等价的,相当于C语言中的a ? b : c:result = (a and b) or c-- 或更简洁地result = a and b or c -
取两数最大值
max = (x > y) and x or y- 当
x>y时,and的第一个操作数为true,与第二个操作数(x)进行and运算后结果为x,最终与or运算后返回第一个操作数x。 - 当
x>y不成立时,and表达式的值为false,最终or运算后的结果是第二个操作数y。
- 当
1.5 独立解释器
在 Lua 的语境里,独立解释器(stand-alone interpreter)指的就是 一个可以直接运行 Lua 代码的可执行程序。它与“把 Lua 当作库嵌入到 C/C++ 程序里”相对,因此叫 stand-alone。由于源文件名为lua.c,所以也被称为lua.c;又由于可执行文件为lua,所以也被称为lua。
1.5.1 脚本头部“#!”支持
在类 Unix(POSIX)系统里,要运行 Lua 脚本得显式调用 lua 解释器:
lua myscript.lua假设Lua解释器位于 /usr /local/bin/,那么在脚本第一行加上:
#!/usr/local/bin/lua-- 或者是#!/usr/bin/env/lua那么系统会自动 用 /usr/local/bin/lua 去执行该文件(脚本文件需要有可执行权限),而无需用户手动写 lua 命令。此时直接在终端里敲./myscript.lua就行。
1.5.2 命令行参数
Lua命令完整额参数形式是如下,无参数则直接进入交互模式。
lua [options] [script [args]]-
-e参数允许直接在命令行执行一段代码(必须使用双引号),例如:lua -e \"print(math.sin(12))\" -- > -0.53657291800043 -
-i:处理完其他参数后进入交互模式。 -
-l用于加载库:lua -i -llib -e \"x = 10\"首先加载 lib库,再执行 x = 10语句,最后进入交互模式
- 脚本可通过全局变量
arg或...获取参数:
lua script.lua a b carg表结构:
arg[0] = \"script.lua\" -- 脚本名arg[1] = \"a\" -- 第一个参数arg[2] = \"b\" -- 第二个参数arg[-1] = \"-e\" -- 选项(如果有)1.5.3 环境变量
Lua 解释器在运行脚本前会优先查找会查找名为LUA_INIT_5_3的环境变量,如果找不到,就会再查找名为 LUA_INIT的环境变量。根据环境变量的内容有两种处理方式:
-
如果以
@开头(如 @filename):执行指定的文件。假设我们有一个 Lua 初始化文件init.lua,内容如下:-- init.luaprint(\"Hello from init.lua!\")_G.my_config = { debug = true } -- 设置全局变量在终端设置环境变量:
export LUA_INIT=\"@init.lua\" # Linux/macOS# 或set LUA_INIT=@init.lua # Windows (cmd)此时运行任何 Lua 脚本(比如lua my_script.lua),都会输出:
-- init.lua 会在 my_script.lua 运行前自动执行,并且 my_config 变量在脚本中可用。Hello from init.lua!也可以直接测试:
lua -e \"print(_G.my_config)\" # 检查是否加载如果 LUA_INIT 正确设置,会输出:
Hello from init.lua!{ debug = true } -
如果不以
@开头:直接将其作为 Lua 代码执行。# 设置环境变量set LUA_INIT=print(\"LUA_INIT running!\")运行lua代码:
lua -e \"print(\'Done\')\"LUA_INIT running!Done
综上所述,LUA_INIT使得我们可以灵活地配置独立解释器。比如预先加载程序包(Package)、修改路径、定义自定义函数、对函数进行重命名或删除函数,等等。
1.5.4 使用arg获取脚本参数
Lua 脚本可以通过arg(预定义的全局变量,是一个表)获取所有的脚本参数。
- arg[0]:脚本名称
- 正数索引(1,2,…):脚本后的参数
- 负数索引(-1,-2,…):解释器选项和其参数
以lua -e \"sin=math.sin\" script a b为例:
arg[-3] = \"lua\" -- 解释器名称arg[-2] = \"-e\" -- 选项arg[-1] = \"sin=math.sin\" -- 选项参数arg[0] = \"script\" -- 脚本名arg[1] = \"a\" -- 第一个参数arg[2] = \"b\" -- 第二个参数1.6 实战练习与答案参考
-
阶乘函数的负数处理:原代码输入负数会无限递归,修改如下:
function fact(n) if n < 0 then return nil, \"Negative numbers not allowed\" elseif n == 0 then return 1 else return n * fact(n - 1) endend -
加载文件的方式对比:
dofile更灵活,适合调试;-l适合模块化项目。
- -l 选项:
lua -l lib1.lua(模块名需符合 require 规则) - dofile:
dofile(\"lib1.lua\")(直接路径)
-
使用
--注释的语言:SQL、Haskell、Ada 等。 -
有效标识符判断
____endEndenduntil?nilNULLone-step-
表达式
type(nil) == nil的值:type(nil)返回字符串\"nil\",而nil是值,两者不相等,返回false -
不用 type 检查布尔值
function isBoolean(value) return value == true or value == falseend -
以下表达式中的括号是否是必要的:
(x and y and (not z)) or ((not y) and x)括号必要,因为
and优先级高于or,去掉括号会改变逻辑。 -
打印脚本自身名称
print(arg[0])
第二章:八皇后问题
2.1 背景
本章作为小插曲将讲解如何用Lua语言编写的简单但完整的程序来解决八皇后问题( eight-queen puzzle,其目标是把8个皇后合理地摆放在棋盘上,让每个皇后之问都不能相互攻击),目的是为了直观地展示Lua语言的特点。
在一个 8×8 的国际象棋棋盘上放置 8 个皇后,使得任意两个皇后不能互相攻击,即:
- 不能在同一列
- 不能在同一主对角线(左上到右下)
- 不能在同一副对角线(右上到左下)
要解决这个问题,必须认识到**每一行只能放一个皇后。**因此,可用一个长度为 8 的数组 a 来表示棋盘:
a = {3, 7, 2, 1, 8, 6, 5, 4}a[i]表示第 i 行的皇后放在第几列(行、列均从 1 开始计数)。- 因为每行只放一个皇后,所以数组天然满足「不同行」的约束。
- 若整个数组是 1…8 的一个排列,则同时满足「不同列」的约束。
2.2 核心算法:回溯(Backtracking)
整体思路:
- 从第 1 行开始,尝试把皇后放在第 1~8 列中的某一列。
- 每放一个皇后,立即检查是否与之前放置的皇后冲突。
- 如果冲突,剪枝(回溯);否则继续递归到下一行。
- 当 8 个皇后全部摆好,输出一个可行解。
冲突检测函数 isplaceok:给定当前部分解 a[1..n-1],尝试把第 n 个皇后放在第 c 列,需要检查:
- 同列:
a[i] == c - 主对角线:
(a[i] - i) == (c - n) - 副对角线:
(a[i] + i) == (c + n)
只要三者都不成立,位置合法。
2.3 完整代码
-- 八皇后问题回溯解法(Lua)N = 8 -- 棋盘大小-- 1. 判断第 n 行的皇后能否放在第 c 列(不被攻击)function isplaceok (a, n, c) for i = 1, n - 1 do -- 遍历之前已经放置的皇后 if (a[i] == c) or -- 同一列? (a[i] - i == c - n) or -- 同一主对角线? (a[i] + i == c + n) then -- 同一副对角线? return false -- 该位置会被攻击 end end return true -- 该位置安全end-- 2. 打印一个完整解(棋盘),其中a是一个长度为 8 的数组function printsolution (a) for i = 1, N do -- 遍历每一行 for j = 1, N do -- 遍历每一列 -- 如果该位置有皇后则打印 \"X\",否则打印 \"-\" io.write(a[i] == j and \"X\" or \"-\", \" \") end io.write(\"\\n\") end io.write(\"\\n\")end-- 3. 主函数,在棋盘 \'a\' 上放置从 \'n\' 到 \'N\' 的皇后-- 参数 a 是当前部分解(数组)-- 参数 n 表示当前正在放置第 n 行的皇后function addqueen (a, n) if n > N then -- 所有皇后都已放置完毕? printsolution(a)-- 所有行都放好了,输出解 else -- 尝试放置第 n 个皇后 for c = 1, N do-- 枚举第 n 行的所有列 if isplaceok(a, n, c) then a[n] = c -- 将第 n 个皇后放置在第 c 列 addqueen(a, n + 1)-- 递归到下一行。 无需显式回溯:a[n] 会在下一轮循环被覆盖 end end endendaddqueen({}, 1)-- 运行主程序:从空棋盘开始运行示例(部分输出):
Solution: { 1 5 8 6 3 7 2 4 }X - - - - - - -- - - - X - - -- - - - - - - X- - - - - X - -- - X - - - - -- - - - - - X -- X - - - - - -- - - X - - - -...复杂度分析:
回溯通过「提前剪枝」把搜索量降到暴力枚举的 5% 左右。
2.5 练习与扩展
-
只输出第一个解(Exercise 2.1):在
printsolution里加一句os.exit()即可:local function printsolution(a) printsolution(a) -- 原逻辑 os.exit(0) -- 找到第一个解后退出end -
暴力枚举(Exercise 2.2)
- 使用标准库或自定义函数生成 1…8 的所有排列。
- 对每个排列检查是否满足对角线约束。
- 统计总排列数与有效解数量。
-- 伪代码:local function valid(p) for i = 1, 8 do for j = i + 1, 8 do if math.abs(p[i] - p[j]) == j - i then return false end end end return trueend-- 使用 next_permutation 或自定义生成器
性能对比:
- 暴力枚举:固定 40 320 次检查。
- 回溯:平均约 2 000 次递归调用,优势明显。
第三章:数值
在 Lua 5.3 之前,所有的数字都使用双精度浮点数表示。从 Lua 5.3 开始,Lua 支持两种数字表示形式:64 位整数(integer)和双精度浮点数(float)。对于受限平台,Lua 5.3 可以编译为 Small Lua,使用 32 位整数和单精度浮点数。
3.1 数值常量
-
十进制整数与浮点数:我们可以使用科学计数法(带可选小数部分和可选小数指数的数字常量)书写数值常量,例如:
> 0.4 --> 0.4> 4.57e-3 --> 0.00457> 0.3e12 --> 300000000000.0带有小数点或指数的数字被视为浮点数,否则被视为整数。
> 3 --> 3> 3.0 --> 3.0> 1000 --> 1000> 1e3 --> 1000.0整数和浮点数都具有 “number” 类型:
> type(3) --> number> type(3.5) --> number由于整型值和浮点型值的类型都是\"number\",所以它们可以相互转换。同时,整数和浮点数在比较时被视为相等,只要它们的数学值相同:
> 1 == 1.0 --> true> -3 == -3.0 --> true> 0.2e3 == 200 --> true在少数情况下,当需要区分整型值和浮点型值时,可以使用函数math.type:
> math.type(3) --> integer> math.type(3.0) --> float -
十六进制常量与十六进制浮点数
Lua 还支持0x开头的十六进制常量与十六进制浮点数,后者由由小数部分和以p或P开头的指数部分组成,例如:> 0x1A3 --> 419> 0x0.2 --> 0.125> 0x1p-1 --> 0.5> 0xa.bp2 --> 42.75可以使用
%a参数,通过函数string.format对这种格式进行格式化输出:> string.format(\"%a\", 419) --> 0x1.a3p+8> string.format(\"%a\", 0.1) --> 0x1.999999999999ap-4虽然这种格式很难阅读,但是这种格式可以保留所有浮点数的精度,并且比十进制的转换速度更快。
3.2 算术运算
3.2.1 常见算术运算
Lua 提供了常见的算术运算符:加法、减法、乘法、除法和取负(一元减号)。它还支持地板除法、取模和指数运算。整数和浮点数的运算规则如下:
-
加法、减法、乘法和取负:如果操作数都是整数,结果是整数;否则,结果是浮点数。
> 13 + 15 --> 28> 13.0 + 15.0 --> 28.0> -(3 * 6.0) --> -18.0 -
除法:为了避免两个整型值相除和两个浮点型值相除导致不一样的结果,除法总是返回浮点数结果。
> 3.0 / 2.0 --> 1.5> 3 / 2 --> 1.5 -
floor除法(
//):Lua 5.3引入。顾名思义,floor除法会对得到的商向负无穷取整,从而保证结果是一个整数。这样,floor除法就可以与其他算术运算一样遵循同样的规则:如果操作数都是整数,结果是整数;否则,结果是浮点数。> 3 // 2 --> 1> 3.0 // 2 --> 1.0> 6 // 2 --> 3> 6.0 // 2.0 --> 3.0> -9 // 2 --> -5> 1.5 // 0.5 --> 3.0 -
指数运算: 与除法一样,结果总是浮点数。例如:
-- 计算平方根与立方根> 2^0.5 --> 1.4142135623731> 2^(1/3)--> 1.2599210498949
3.2.2 取模运算
模运算的数学定义如下:
a % b = a − ( ⌊ a b ⌋ × b ) a \\% b = a - \\left(\\left\\lfloor \\frac{a}{b} \\right\\rfloor \\times b\\right) a%b=a−(⌊ba⌋×b)
- ( a % b ) 表示 a 除以 b 的余数。
- ( ⌊ a b ⌋ ) \\left(\\left\\lfloor \\frac{a}{b} \\right\\rfloor \\right) (⌊ba⌋) 表示 a 除以 b 的商的整数部分(向下取整)。
特性:
- 如果操作数都是整数,结果是整数;否则,结果是浮点数。
- 模运算的结果总是与第二个操作数(除数)的符号相同。
说明:
- 对于任何正整数 ( K ),表达式 ( x % K ) ( x \\% K ) (x%K) 的结果范围是 ( [ 0 , K − 1 ] ) ([0, K-1]) ([0,K−1]),即使 x x x 是负数。例如对于任何整数 i i i, ( i % 2 ) ( i \\% 2 ) (i%2) 的结果总是 0 0 0 或 1 1 1。
- 模运算可以用于控制浮点数的精度: 比如 ( x − x % 0.01 ) ( x - x \\% 0.01) (x−x%0.01)将 x x x 保留两位小数, ( x − x % 0.001 ) ( x - x \\% 0.001) (x−x%0.001)将 x x x保留三位小数。
> x = math.pi> x - x%0.01 --> 3.14> x - x%0.001 --> 3.141
模运算可用于归一化:
- 归一化角度到 [ 0 , 360 ) [0, 360) [0,360)区间(角度单位为度):
angle = angle % 360检查角度是否接近 180 度(允许一定的误差范围):
local tolerance = 10function isturnback(angle) angle = angle % 360 return (math.abs(angle - 180) < tolerance)end-- 该函数对负数角度同样适用print(isturnback(-180)) --> true - 归一化角度到 [ 0 , 2 π ) [0, 2\\pi) [0,2π) 区间(角度单位为弧度):
angle = angle % (2 * math.pi)之前的代码可改为:
local tolerance = 0.17function isturnback(angle) angle = angle % (2 * math.pi) return (math.abs(angle - math.pi) < tolerance)end
3.3 关系运算符
Lua 提供了以下关系运算符:
-- ~= 表示不等于< > <= >= == ~=在 Lua 中,== 用于相等性测试,~= 用于不等性测试。
- 如果两个值的类型不同,Lua 认为它们不相等。否则进行进一步比较
- 在比较数值时,忽略其子类型(整型或浮点型),只比较算术值,但相同子类型的比较效率更高。
3.4 数学库
Lua 提供了一个标准的数学库math,包含一系列数学函数,如三角函数、对数函数、舍入函数、最大值和最小值函数、伪随机数生成函数 random,以及常量 pi 和 huge
huge:最大可表示的数字,通常是特殊值inf- 所有的三角函数都以弧度为单位,并通过函数deg和rad进行角度和弧度的转换。
3.4.1 随机数生成器
math.random 函数生成伪随机数。可以以三种方式调用:
- 无参数:返回
[0,1)区间内的伪随机实数。 - 一个参数 n:返回
[1,n]区间内的伪随机整数。 - 两个参数 l 和 u:返回
[l,u]区间内的伪随机整数。
-
伪随机数:Lua 中的随机数生成器是伪随机的,只要初始条件(种子)相同,生成的数列就会完全相同。
-
默认种子:如果未设置种子,Lua 默认使用 1 作为种子,导致每次程序运行时生成相同的随机数序列,这有利于调式。
-
动态种子:可以使用
math.randomseed函数设置伪随机数生成器的种子。通常使用当前时间作为种子,以确保每次运行程序时生成不同的随机数序列:math.randomseed(os.time())
3.4.2 取整函数
Lua 提供了三个舍入函数:floor 向负无穷舍入,ceil 向正无穷舍入,modf 向零舍入。它们返回整数结果(如果适合整数),否则返回浮点数(当然,具有整数值)。其中,modf还会返回小数值作为第二个结果。
> math.floor(3.3) --> 3> math.floor(-3.3) --> -4> math.ceil(3.3) --> 4> math.ceil(-3.3)--> -3> math.modf(3.3) --> 3 0.3> math.modf(-3.3) --> -3 -0.3> math.floor(2^70) --> 1.1805916207174e+21-
四舍五入:通过计算
math.floor(x + 0.5)即可实现四舍五入。
当 x 是一个非常大的整数值时可能导致舍入错误。 例如,x = 2^52 + 1,计算x + 0.5时,由于浮点数的精度限制,2^52 + 1.5无法精确表示,可能会被内部舍入为2^52 + 2,从而导致错误的四舍五入结果。改进方法如下:function round(x) local f = math.floor(x) if x == f then return f -- 如果 x 已经是整数,直接返回,避免浮点数精度问题。 else return math.floor(x + 0.5) -- 否则,使用简单四舍五入方法 endend -
无偏四舍五入:半整数(如 2.5、3.5)应该四舍五入到最近的偶数整数(2.5->2、3.5->4)。此时简单方法
math.floor(2.5 + 0.5) = math.floor(3.0) = 3,错误,应该是 2。改进函数:function round(x) local f = math.floor(x) if (x == f) or (x % 2.0 == 0.5) then return f -- 如果 x 是整数,或者 x + 0.5 是奇数整数,直接返回整数部分 else return math.floor(x + 0.5) -- 否则,使用简单四舍五入方法 endendprint(round(2.5)) --> 2print(round(3.5)) --> 4print(round(-2.5)) --> -2print(round(-1.5)) --> -2
3.5 表示限制
3.5.1 整数限制
-
标准 Lua 使用 64 位整数,表示范围为 − 2 63-2^{63} −263到 2 63 − 1 2^{63}-1 263−1,即 -9223372036854775808到9223372036854775807。
-
Small Lua使用 32 位整数,范围是 − 2 31-2^{31} −231到 2 31 − 1 2^{31}-1 231−1,大约-20亿到20亿。
-
Lua 的数学库定义了两个常量
math.maxinteger和math.mininteger,分别表示可表示的最大和最小整数。当整数运算结果超出这些范围时,结果会回环(wrap around),这意味着结果会从另一端重新开始:> math.maxinteger + 1 == math.mininteger --> true> math.mininteger - 1 == math.maxinteger --> true> -math.mininteger == math.mininteger --> true> math.mininteger // -1 == math.mininteger --> true> math.maxinteger * 2 --> -2> math.mininteger * 2 --> 0> math.maxinteger * math.maxinteger --> 1> math.mininteger * math.mininteger --> 0 -
最大可以表示的整数是0x7ff…fff,即除最高位(符号位,零为非负数值)外其余比特位
均为1。当我们对0x7ff…fff加1时,其结果变为0x800…000,即最小可表示的整数(回环)。> math.maxinteger --> 9223372036854775807> 0x7fffffffffffffff --> 9223372036854775807> math.mininteger --> -9223372036854775808> 0x8000000000000000 --> -9223372036854775808
3.5.2 浮点数限制
在标准 Lua 中,双精度浮点数使用 IEEE 754 标准的 64 位表示法。其数学表示可以写为:
数值 = ( − 1 ) 符号位 × ( 1 + 尾数部分 ) × 2 指数部分 − 1023 \\text{数值} = (-1)^{\\text{符号位}} \\times (1 + \\text{尾数部分}) \\times 2^{\\text{指数部分} - 1023} 数值=(−1)符号位×(1+尾数部分)×2指数部分−1023
一共分为三个部分:
-
符号位(1 位):表示数字的正负。
0表示正数。1表示负数。
-
指数位(11 位):表示指数部分,采用偏移量表示法(Bias = 1023,指数的实际值为
E = 原始指数值 - 1023)。双精度浮点数可以精确表示的整数范围是 [ − 9.007199254740991 × 1 0 15 , 9.007199254740991 × 1 0 15 ] [-9.007199254740991 \\times 10^{15}, 9.007199254740991 \\times 10^{15}] [−9.007199254740991×1015,9.007199254740991×1015]- 最小正规化正数: 2 − 1022 2^{-1022} 2−1022,约为
2.2250738585072014e-308。 - 最大正规化正数: 2 1023 ∗ ( 1 − 2 − 52 ) 2^{1023} * (1 - 2^{-52}) 21023∗(1−2−52),约为
1.7976931348623157e+308。 - 最小正规化负数: − 2 − 1022 -2^{-1022} −2−1022,约为
-2.2250738585072014e-308。 - 最大正规化负数: − 2 1023 ∗ ( 1 − 2 − 52 ) -2^{1023}* (1 - 2^{-52}) −21023∗(1−2−52),约为
-1.7976931348623157e+308。
1.7976931348623157 是这个数的有效部分,它有大约 16 位有效数字, 1 0 308 10^ {308} 10308表示这个数的大小级别,而不是说它有 308 位整数。用十进制表示是 [ − 2 53 , 2 53 ] [-2^{53} , 2^{53} ] [−253,253],大约 ( [ − 9.007199254740992 × 1 0 15 , 9.007199254740992 × 1 0 15 ] ) ([-9.007199254740992 \\times 10^{15}, 9.007199254740992 \\times 10^{15}]) ([−9.007199254740992×1015,9.007199254740992×1015]),即双精度浮点数的整数部分最多可以表示 15 位十进制整数。
- 最小正规化正数: 2 − 1022 2^{-1022} 2−1022,约为
-
尾数位(52 位):表示小数部分,其精度可以表示为:
有效数字 ≈ log 10 ( 2 52 ) ≈ 15.65 \\text{有效数字} \\approx \\log_{10}(2^{52}) \\approx 15.65 有效数字≈log10(252)≈15.65
因此双精度浮点数的小数部分可以表示大约 15 到 16 位十进制小数。
3.5.3 注意事项
精度限制:如果我们使用十位表示一个数,那么1/7会被取整到0.142857142。如果我们使用十位计算1/7*7,结果会是0.999999994而不是1。此外,用十进制表示的有限小数在用二进制表示时可能是无限小数。例如,12.7-20+7.3即便是用双精度表示也不是0,这是由于12.7和7.3的二进制表示不是有限小数(参见练习3.5)。
由于整型值和浮点型值的表示范围不同,因此当超过它们的表示范围时,整型值和浮点型值的算术运算会产生不同的结果:
> math.maxinteger + 2 --> -9223372036854775807> math.maxinteger + 2.0 --> 9.2233720368548e+18以上计算出现了不同的问题:第一行对最大可表示整数进行了整型求和,结果发生了回环。第二行对最大可表示整数进行了浮点型求和,结果被取整成了一个近似值,这可以通过如下的比较运算证明:
> math.maxinteger + 2.0 == math.maxinteger + 1.0 --> true也就是说,浮点型能够表示的整数范围被精确地限制在 ([− 2 53 , 2 53 ]) ([-2^{53} , 2^{53} ]) ([−253,253])之间,在这个范围内,我们基本可以忽略整型和浮点型的区别。超出这个范围后,我们则应该谨慎地思考所使用的表示方式。
3.6 整数与浮点数的转换
3.6.1 整数转为浮点数
要将一个整数强制转换为浮点数,可以简单地加上 0.0
> -3 + 0.0 --> -3.0> 0x7fffffffffffffff + 0.0 --> 9.2233720368548e+18当整数大于 2 53 2^{53} 253 时(9007199254740992),转换为浮点数可能会丢失精度:
> 9007199254740991 + 0.0 == 9007199254740991 --> true> 9007199254740992 + 0.0 == 9007199254740992 --> true> 9007199254740993 + 0.0 == 9007199254740993 --> false3.6.2 浮点数转为整数
-
使用位运算符:可以通过位运算符(如
|)将浮点数转换为整数。Lua会检查浮点数是否有精确的整数表示(没有小数部分,且整数部分在64位整型的表示范围内)。> 2^53 --> 9.007199254741e+15 (float)> 2^53 | 0 --> 9007199254740992 (integer)> 3.2 | 0 -- 有小数部分stdin:1: number has no integer representation> 2^64 | 0 -- 超出范围stdin:1: number has no integer representation> math.random(1, 3.5) -- 没有确切的整型表示stdin:1: bad argument #2 to \'random\'(number has no integer representation) -
使用
math.tointeger函数:math.tointeger函数可以将浮点数转换为整数,如果浮点数无法精确表示为整数,则返回nil。> math.tointeger(-258.0) --> -258> math.tointeger(2^30) --> 1073741824> math.tointeger(5.01) --> nil (not an integral value)> math.tointeger(2^64) --> nil (out of range)这个函数可用于检查一个数字能否被转换成整型值。以下函数在可能时会将输入参数转换为整型值,否则保持原来的值不变:
function cond2int(x) local int_x = math.tointeger(x) return int_x or xendprint(cond2int(258.0)) --> 258print(cond2int(5.01)) --> 5.01
3.7 运算符优先级
Lua 语言中的运算符优先级如下(优先级从高到低):

在二元运算符中,除了幂运算和连接操作符是右结合的外,其他运算符都是左结合的。因此,以下各个表达式的左右两边等价:
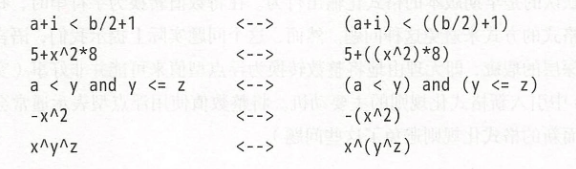
当不能确定某些表达式的运算符优先级时,应该显式地用括号来指定所希望的运算次序。
3.8 Lua 5.3 的兼容性
-
主要差异:Lua 5.3引入了整数类型,而Lua 5.2及更早版本中所有数字都是双精度浮点数。Lua 5.2可以精确表示的最大整数是 2 532^{53} 253,而Lua 5.3可以表示到 2 632^{63} 263。对于普通的计数操作,这种差异通常不是问题,但对于涉及位模式(如打包多个整数)的场景,差异可能非常重要。
-
C语言库函数中的整数问题:虽然Lua 5.2没有明确支持整数,但C语言实现的库函数经常接收整数参数。Lua 5.2没有明确定义如何将浮点数转换为整数,只是模糊地表示“以某种未指定的方式截断”。这可能导致在不同平台上,相同的浮点数转换为整数的结果不同(例如,
-3.2可能被转换为-3或-4)。Lua 5.3则明确地定义了这些转换,只在数字有精确整数表示时进行转换。数字被表示为浮点数通常是程序中的一个“坏味道”(bad smell,即潜在问题的迹象)。Lua 5.3的新格式化规则正是为了暴露这些问题,促使开发者更仔细地处理整数和浮点数的使用。
-
Lua 5.2缺少的功能:
- Lua 5.2没有
math.type函数,因为所有数字都是浮点数,没有子类型。 - Lua 5.2没有
math.maxinteger和math.mininteger常量,因为它没有整数类型。 - Lua 5.2没有提供地板除法(floor division),尽管它的模运算符(
%)已经基于地板除法定义了。
- Lua 5.2没有
-
字符串格式化的差异:Lua 5.2将任何整数值格式化为没有小数点的整数形式(例如,
3.0被格式化为\"3\"),而Lua 5.3将所有浮点数格式化为带有小数点或指数的形式(例如,3.0被格式化为\"3.0\")。尽管Lua从未明确规定数字到字符串的格式化规则,但许多程序依赖于Lua 5.2的行为。这种差异可能导致一些问题,但通常可以通过显式指定格式来解决。
第四章:字符串
-
不变值:Lua 中的字符串是不可变值,不能直接修改字符串中的某个字符,而是需要创建一个包含所需修改的新字符串。例如:
a = \"one string\"b = string.gsub(a, \"one\", \"another\") -- 修改字符串的一部分print(a) --> one stringprint(b) --> another stringLua 中的字符串和其他 Lua 对象(如表、函数等)一样,都受到自动内存管理的控制。这意味着我们无需手动释放,Lua会自动处理,避免内存泄漏风险。
-
字符串长度:我们可以使用长度运算符(
#)来获取字符串的长度(字节单位,不是字符数):a = \"hello\"print(#a) --> 5print(#\"good bye\") --> 8 -
字符串连接:我们可以使用连接运算符
..(两个点)将两个字符串连接起来。如果操作数之一是数字,Lua 会将这个数字转换为字符串:print(\"Hello \" .. \"World\") --> Hello Worldprint(\"result is \" .. 3) --> result is 3需要注意的是,连接运算符总是会创建一个新的字符串,而不会修改其操作数。
> a = \"Hello\"> a .. \" World\" --> Hello World> a --> Hello
Lua 提供三种字面量表示方式:
\"hello\" 或 \'hello\'\\n)[[ ... ]]\\u{3b1}(UTF-8 字符)4.1 转义字符
字符串字面量可以用单引号或双引号括起来,它们是等价的。唯一的区别是,在一种引号内部可以使用另一种引号,而不需要转义。例如:
a = \"a line\"b = \'another line\'此外,Lua 中的字符串字面量还可以包含一些类似于 C 语言的转义序列,例如:
\\a\\b\\f\\n\\r\\t\\v\\\\\\\"\\\'示例:
> print(\"one line\\nnext line\\n\\\"in quotes\\\", \'in quotes\'\")one linenext line\"in quotes\", \'in quotes\'> print(\'a backslash inside quotes: \\\'\\\\\\\'\')a backslash inside quotes: \'\\\'> print(\"a simpler way: \'\\\\\'\")a simpler way: \'\\\'此外,我们还可以通过 \\ddd 和 \\xhh 转义序列来指定字符的数值:
- 八进制转义
\\ddd:用 1 到 3 个八进制数字表示字符,例如\\10是换行符(ASCII 10); - 十六进制转义
\\xhh: 恰好 2 个 十六进制数字表示字符,例如\\x41是\'A\'(ASCII 65);
例如字符串 \"ALO\\n123\\\"\" 可等价表示为:
\'\\x41LO\\10\\04923\"\':混合八进制和十六进制转义。0x41(十进制的65)在ASCII编码中对应A,10对应换行符,49对应数字1(八进制转义后若紧跟数字,需用 3 位补零,所以49必须写成\\049,否则,Lua语言会将其错误地解析为\\492);\'\\x41\\x4c\\x4f\\x0a\\x31\\x32\\x33\\x22\':纯十六进制转义,每个字符显式编码。
从Lua 5.3开始,也可以使用转义序列\\u{h...h}来声明UTF-8字符,花括号中支持任意有效的的十六进制:
> \"\\u{3b1} \\u{3b2} \\u{3b3}\" --> α β γ4.2 长字符串/多行字符串
Lua 中的长字符串可以用匹配的双方括号 [[ 和 ]] 来分隔,这种形式的字符串可以跨越多行,并且不会解释转义序列。如果字符串的第一个字符是换行符,它会被忽略。这种语法非常适合用于包含大量代码或文本的字符串,例如 HTML 页面或配置文件。
page = [[An HTML Page Lua]]write(page) 如果字符串中包含类似于 ]] 的字符序列,可以在开头的方括号之间添加任意数量的等号,例如 [===[。在这种情况下,字符串会在下一个具有相同数量等号的闭合方括号 ]===] 处结束。这种机制也可以用于注释,例如:
--[=[ 这是一个多行注释 它可以包含其他已经注释掉的代码--]=] 非文本字面量:当代码中需要使用常量文本时,使用长字符串是一种理想的选择。但是,对于非文本的常量(如二进制数据)我们不应该滥用长字符串,因为文本编辑器可能无法正确处理这些数据,且换行序列(如 \\r\\n)可能会被规范化为 \\n。建议使用数值转义序列(十进制或十六进制)来编码任意二进制数据,例如:
data = \"\\x00\\x01\\x02\\x03\\x04\\x05\\x06\\x07\\x08\\x09\\x0A\\x0B\\x0C\\x0D\\x0E\\x0F\"\\z 转义序列:二进制转义表示的字符串往往非常长,难以阅读。针对这种情况,从Lua5.2开始引入了转义序列\\z,该转义符会跳过其后的所有空白字符,直到遇到第一个非空白字符。
data = \"\\x00\\x01\\x02\\x03\\x04\\x05\\x06\\x07\\z\\x08\\x09\\x0A\\x0B\\x0C\\x0D\\x0E\\x0F\" 以上示例中,第一行最后的\\z会跳过其后的EOF和第二行的制表符,因此在最终得到的字符串中,\\x08实际上是紧跟着\\x07 的。
4.3 类型转换
4.3.1 自动类型转换
当对字符串执行数值运算时,或其他需要数字参数的场景(例如 math.sin 函数),Lua会自动将字符串转为数值。相反,当 Lua 在需要字符串的地方遇到数字时,它会将数字转换为字符串:
print(10 .. 20) --> 1020在数字后面紧跟着使用连接运算符时,必须在它们之间加上一个空格,否则 Lua 会将第一个点误认为是小数点。
通常情况下,最好不要依赖这些自动转换。它们在少数地方很方便,但会增加语言和使用它们的程序的复杂性。在Lua 5.3 中,只有当两个操作数都是整数时,结果才是整数;因此任何涉及字符串的算术运算都被视为浮点运算:
print(\"10\" + 1) --> 11.0与算术运算符不同,在比较时,数字和字符串不会自自动转换类型。当混合字符串和数字进行顺序比较时会抛出错误,例如 2 < \"15\"。
作为数字进行比较,
2 < 1;但如果是字符串比较,\"2\" >\"15\"(按字母顺序比较)。为了避免不一致的结果,混合比较会直接导致错误。
4.3.2 字符串转换为数字(tonumber)
要显式地将字符串转换为数字,可以使用 tonumber 函数。如果字符串不能表示一个有效的数字,该函数会返回 nil。否则,它会根据 Lua 扫描器的规则返回整数或浮点数:
print(tonumber(\"-3\")) --> -3print(tonumber(\"10e4\")) --> 100000.0print(tonumber(\"10e\")) --> nil (不是有效的数字)print(tonumber(\"0x1.3p-4\")) --> 0.07421875默认情况下,tonumber 假设使用十进制表示法,但我们可以指定任何介于 2 到 36 之间的基数进行转换:
print(tonumber(\"100101\", 2)) --> 45print(tonumber(\"fff\", 16)) --> 4095print(tonumber(\"987\", 8)) --> nil (在给定基数下不是有效的数字)4.3.3 数字转换为字符串(tostring)
要将数字转换为字符串,可以调用 tostring 函数,但这个函数无法控制转换后的字符串的格式(控制格式,应该使用 string.format)。
print(tostring(10) == \"10\") --> true4.4 字符串标准库
原始的 Lua 解释器对字符串的处理能力非常有限(创建、连接、比较、#获取长度),完整的字符串处理功能依赖于string标准库。以下是string标准库的常用函数:
字符串库假设字符是单字节的。这种假设在许多编码(如 ASCII 或 ISO-8859-1)中是成立的,但在任何 Unicode 编码中都会被打破。然而,正如我们将看到的,字符串库的许多部分对 UTF-8 仍然非常有用。
string.len(s)s 的长度(等价于 #s)string.len(\"hello\") --> 5string.rep(s, n)s 重复 n 次的结果string.rep(\"abc\", 3) --> \"abcabcabc\"string.reverse(s)string.reverse(\"hello\") --> \"olleh\"string.lower(s)s 的小写副本string.lower(\"HELLO\") --> \"hello\"string.upper(s)s 的大写副本string.upper(\"hello\") --> \"HELLO\"string.sub(s, i, j)i 个到第 j 个字符的子串(包含两端)(索引从1开始,-1为最后一个字符)
string.sub(\"hello\", 2, 4) --> \"ell\"string.char(...)string.char(97, 98, 99) --> \"abc\"string.byte(s, i, j)i 到第 j 个字符的内部数值表示(可选参数 j)string.byte(\"abc\", 1, 3) --> 97 98 99string.format(fmt, ...)string.format(\"x = %d y = %d\", 10, 20) --> \"x = 10 y = 20\"string.find(s, pattern)pattern,返回起止位置(未找到返回 nil)string.find(\"hello world\", \"wor\") --> 7 9string.gsub(s, pattern, repl)pattern 全局替换为 repl,返回替换后的字符串和替换次数string.gsub(\"hello world\", \"l\", \".\") --> \"he..o wor.d\" 3-
如果我们要忽略大小写来比较两个字符串,可以这样写:
print(string.lower(a) < string.lower(b)) -
string.sub(s, 1, j)获取长度为j的前缀;string.sub(s, j, -1)获取从第j个字符开始的字符串的后缀;string.sub(s, 2, -2)返回一个去掉首尾字符的字符串副本:s = \"[in brackets]\"print(string.sub(s, 2, -2)) --> \"in brackets\"print(string.sub(s, 1, 1)) --> \"[\"print(string.sub(s, -1, -1)) --> \"]\"string.sub不会改变字符串的值(Lua 中的字符串是不可变的),而是返回一个新的字符串。要修改字符串,必须将新值赋给它:s = string.sub(s, 2, -2) -
string.char和string.byte函数在字符及其内部数值表示之间进行转换。string.byte(s, i)中第二个参数是可选的——string.byte(s)返回字符串s中第一个(或唯一一个)字符的内部数值表示。以下示例假设使用 ASCII 编码:print(string.char(97)) --> \"a\"i = 99print(string.char(i, i + 1, i + 2)) --> \"cde\"print(string.byte(\"abc\")) --> 97print(string.byte(\"abc\", 2)) --> 98print(string.byte(\"abc\", -1)) --> 99string.byte(s, i, j)调用会返回从索引i到j(包括)的所有字符的数值表示:print(string.byte(\"abc\", 1, 2)) --> 97 98一个很巧妙的用法是
{string.byte(s, 1, -1)},它会创建一个包含字符串s中所有字符代码的列表。(这个用法只适用于长度不超过 1MB 的字符串。Lua 限制了其堆栈大小,这反过来又限制了函数返回的最大值的数量。默认的堆栈限制是一百万个条目。) -
string.format格式字符串中的指令是一个百分号加上一个字母,指示如何格式化参数:d表示十进制整数,x表示十六进制,f表示浮点数,s表示字符串,完整描述,请参阅 C 语言中printf函数的文档( Lua 调用了标准 C 库来完成)print(string.format(\"x = %d y = %d\", 10, 20)) --> \"x = 10 y = 20\"print(string.format(\"x = %x\", 200)) --> \"x = c8\"print(string.format(\"x = 0x%X\", 200)) --> \"x = 0xC8\"print(string.format(\"x = %f\", 200)) --> \"x = 200.000000\"tag, title = \"h1\", \"a title\"print(string.format(\"%s\", tag, title, tag)) --> \"a title
\"在百分号和字母之间,指令可以包含其他选项,用于控制格式化的细节,例如浮点数的小数位数:
-- `%.4f` 表示一个有四位小数的浮点数print(string.format(\"pi = %.4f\", math.pi)) --> \"pi = 3.1416\"d, m, y = 5, 11, 1990-- `%02d` 表示一个至少有两位数字的十进制数,用零填充。如果去掉零(`%2d`),则会用空格填充。print(string.format(\"%02d/%02d/%04d\", d, m, y)) --> \"05/11/1990\" -
冒号操作符:可以将字符串库中的所有函数作为字符串的方法调用。例如,
string.sub(s, i, j)可重写为s:sub(i, j);string.upper(s)可重写为s:upper()。(详见第 21 章“面向对象编程”中的冒号操作符。) -
全局替换:
print(string.gsub(\"hello world\", \"l\", \".\")) --> \"he..o wor.d\" 3print(string.gsub(\"hello world\", \"ll\", \"..\")) --> \"he..o world\" 1print(string.gsub(\"hello world\", \"a\", \".\")) --> \"hello world\" 0
4.5 Lua 中的 Unicode 和 UTF-8 支持
自 Lua 5.3 起,Lua 引入了一个小型库来支持 UTF-8 编码的 Unicode 字符串操作。UTF-8 是 Web 上 Unicode 的主导编码,由于其与 ASCII 的兼容性,它也是 Lua 的理想编码。这种兼容性使得许多适用于 ASCII 字符串的字符串操作技术无需修改即可应用于 UTF-8 字符串。
UTF-8 编码特性:
- UTF-8 使用可变字节数表示每个 Unicode 字符。例如,ASCII 范围内的字符(如
A,代码为 65)用单字节表示;而希伯来字符 Aleph(代码为 1488)则用两字节序列(215–144)表示。 - UTF-8 的设计确保了字符的字节序列不会重叠,且单字节字符(小于 128 的字节)总是表示其对应的 ASCII 字符。
Lua 的 UTF-8 支持:
- 字符串操作:Lua 的字符串操作(如拼接、比较)对 UTF-8 字符串有效,但部分函数(如
reverse、upper、lower、byte和char)假设一个字符等于一个字节,因此不适用于 UTF-8 字符串。 - 文件和系统库:Lua 的文件和系统库对 UTF-8 的支持依赖于底层系统。例如,Linux 支持 UTF-8 文件名,而 Windows 使用 UTF-16,因此在 Windows 上操作 Unicode 文件名可能需要额外的库或对标准库的修改。
utf8 库(Lua 5.3 +):
utf8.len(s):返回 UTF-8 字符串s中的字符数(码点数),并验证字符串的有效性。如果发现无效字节序列,返回false和第一个无效字节的位置。utf8.char(...)和utf8.codepoint(s, i, j):分别用于生成 UTF-8 字符串和获取字符串中指定位置的码点,类似于string.char和string.byte。utf8.offset(s, n):将字符位置n转换为字节位置,支持负索引(从字符串末尾开始计数)。utf8.codes(s):用于遍历 UTF-8 字符串中的字符,返回每个字符的字节位置和码点。
-- utf8.lenprint(utf8.len(\"résumé\")) --> 6print(utf8.len(\"ação\")) --> 4print(utf8.len(\"Månen\")) --> 5print(utf8.len(\"ab\\x93\")) --> nil 3-- utf8.char 和 utf8.codepointprint(utf8.char(114, 233, 115, 117, 109, 233)) --> \"résumé\"print(utf8.codepoint(\"résumé\", 6, 7)) --> 109 233-- utf8.offsetlocal s = \"Nähdään\"print(utf8.codepoint(s, utf8.offset(s, 5))) --> 228-- utf8.codesfor i, c in utf8.codes(\"Ação\") do print(i, c)end--> 1 65--> 2 231--> 4 227--> 6 111限制:由于 Unicode 的复杂性(如字符与图标的多对一映射),Lua 无法提供完整的 Unicode 支持。对于更复杂的 Unicode 处理需求,建议使用外部库。
4.6 练习
- 如何在 Lua 程序中嵌入以下 XML 片段作为字符串?
-
使用长字符串语法,忽略转义序列:
local xml = [[<![CDATA[Hello world ]]>]]print(xml) -
使用单引号或双引号,并确保内部的引号被正确转义:
local xml = \"\\\"\"print(xml)
-
假设你需要在 Lua 中写一个长的任意字节序列作为字符串字面量。你会选择什么格式?考虑可读性、最大行长度和大小等因素。
在这种情况下,使用十六进制转义序列(\\xhh)是最佳选择,因为它可以清晰地表示每个字节的值,同时避免了可读性问题。例如:local data = \"\\x00\\x01\\x02\\x03\\x04\\x05\\x06\\x07\\x08\\x09\\x0A\\x0B\\x0C\\x0D\\x0E\\x0F\"如果数据非常长,可以将其分成多行,每行使用
\\z转义序列跳过换行符和缩进,以保持代码的整洁:local data = \"\\x00\\x01\\x02\\x03\\x04\\x05\\x06\\x07\\x08\\x09\\x0A\\x0B\\x0C\\x0D\\x0E\\x0F\\z \\x10\\x11\\x12\\x13\\x14\\x15\\x16\\x17\\x18\\x19\\x1A\\x1B\\x1C\\x1D\\x1E\\x1F\" -
编写一个函数,将一个字符串插入到另一个字符串的指定位置:
insert(\"hello world\", 1, \"start:\") --> \"start:hello world\"insert(\"hello world\", 7, \"small \") --> \"hello small world\"function insert(str, pos, insertStr) return string.sub(str, 1, pos - 1) .. insertStr .. string.sub(str, pos)endprint(insert(\"hello world\", 1, \"start:\")) --> \"start:hello world\"print(insert(\"hello world\", 7, \"small \")) --> \"hello small world\" -
为 UTF-8 字符串重新实现上述练习:
insert(\"ação\", 5, \"!\") --> \"ação!\"对于 UTF-8 字符串,我们需要使用
utf8.offset来处理字符位置:function insert_utf8(str, charPos, insertStr) local bytePos = utf8.offset(str, charPos) return string.sub(str, 1, bytePos - 1) .. insertStr .. string.sub(str, bytePos)endprint(insert_utf8(\"ação\", 5, \"!\")) --> \"ação!\" -
编写一个函数,从字符串中移除一个切片;切片由其起始位置和长度指定:
remove(\"hello world\", 7, 4) --> \"hello \"function remove(str, start, length) return string.sub(str, 1, start - 1) .. string.sub(str, start + length)endprint(remove(\"hello world\", 7, 4)) --> \"hello \" -
为 UTF-8 字符串重新实现上述练习:
remove(\"ação\", 2, 2) --> \"ao\"function remove_utf8(str, charStart, charLength) local byteStart = utf8.offset(str, charStart) local byteEnd = utf8.offset(str, charStart + charLength) return string.sub(str, 1, byteStart - 1) .. string.sub(str, byteEnd)endprint(remove_utf8(\"ação\", 2, 2)) --> \"ao\" -
编写一个函数,检查给定字符串是否是回文,并忽略空格和大小写的差异:
ispali(\"Step on no pets\") --> trueispali(\"Banana\") --> falsefunction ispali_ignore_case_and_spaces(str) str = string.gsub(str, \"%s\", \"\"):lower() local reversed = string.reverse(str) return str == reversedendprint(ispali_ignore_case_and_spaces(\"Step on no pets\")) --> trueprint(ispali_ignore_case_and_spaces(\"Banana\")) --> false
第五章:表
表是 Lua 中唯一、也是最主要的数据结构,可用来表示数组、集合、记录、模(package)、以及其它对象。键可以是数字、字符串或除 nil 外的任意值。
在 Lua 里,“表”本身是一种动态分配的“对象”(object),而不是像数字或布尔值那样的“值”(value),也不是变量(variable)。程序只能操作指向表的引用(或指针)”,也就是说:
- 写
t = {}时,Lua 在内存里真正创建了一块“表对象”; - 变量
t里保存的并不是这张表的“全部内容”,而只是一个引用/指针,指向那块对象(只保存对表的引用); - 以后你把
t赋给另一个变量s = t,两个变量指向同一块对象,改s.x就等于改t.x。 这和 Java 的数组、对象或 Scheme 的 vector 行为一致。 - Lua 不会隐式拷贝表,除非你明确使用
{}或者table.clone,才会产生新的表对象。
以math库为例,math库本身也是一个表(table),math.sin 这个写法,对 Lua 来说并不是“调用某个库函数”,而是:
- 先拿到变量
math(它指向一张表); - 再用字符串
\"sin\"作为键,去这张表里查值; - 查到的那一项正好保存了一个函数对象,于是可以执行它。
所以以下两种写法是等价的:
math.sin(math.pi/2)--> 1.0math[\"sin\"](math.pi/2)--> 1.0-
创建表:最简单的表构造器是
{}:-- 例1:基本增删改查a = {} -- 创建一张空表,变量 a 保存的是表的“引用”k = \"x\" -- 字符串变量 k 的值是 \"x\"a[k] = 10 -- 把键 \"x\" 对应的值设为 10;等价于 a[\"x\"] = 10a[20] = \"great\" -- 把键 20 对应的值设为 \"great\"a[\"x\"] -- 10 (读取键 \"x\" 的值)k = 20 -- 把变量 k 的值改成数字 20a[k] -- \"great\"(此时 a[20])a[\"x\"] = a[\"x\"] + 1 -- 把键 \"x\" 的值加 1a[\"x\"] -- 11 -
引用表:
- 表永远是匿名的:执行
a = {}时,真正创建的表对象在内存里是没有名字的;a 只是给它起的一个“别名”。因此,表 ≠ 变量名。 - 表本身和保存表的变量之间没有固定的关系:同一个表可以同时被多个变量引用(a 和 b),也可以随时把某个变量改成指向别的表或设为 nil,这对表本身毫无影响,只是少了一个引用路径。
-- 例2:多变量指向同一张表a = {} -- 新建一张表a[\"x\"] = 10 -- 键 \"x\" 置为 10b = a -- b 与 a 指向同一张表(不是复制)b[\"x\"] -- 10b[\"x\"] = 20 -- 修改 b 的键 \"x\" 也会反映到 aa[\"x\"] -- 20a = nil -- 断开 a 对表的引用,此时只有 b 还指向这张表b = nil -- b 也断开,这张表将最终被垃圾回收对于一个表而言,当程序中不再有指向它的引用时,垃圾收集器会最终删除这个表并重用其占用的内存。
- 表永远是匿名的:执行
5.1 表索引
- 表的大小自动扩容;
- 表可以混用任何类型的键,未定义的键返回 nil,把字段设成 nil 等于删除它;
- 可以用点号
a.x作为a[\"x\"]的语法糖,但两种写法在语义上等价,只是阅读意图不同。a.x更像在操作“结构体/对象”的固定字段;a[\"x\"]则暗示键可能是动态计算或任意字符串,更灵活。
-- 例3:用数字键批量填充a = {} -- 空表for i = 1, 1000 do a[i] = i * 2 -- 把 1~1000 作为键,值设为 i*2enda[9] -- 18 (9*2)a[\"x\"] = 10 -- 再加一个字符串键a[\"x\"] -- 10a[\"y\"] -- nil (未赋值,默认 nil)-- 例4:点号语法糖a = {} -- 空表a.x = 10 -- 等价于 a[\"x\"] = 10a.x -- 10 (等价于 a[\"x\"])a.y -- nil (等价于 a[\"y\"])键的类型决定表里的元素:
- a.x VS a[x]:二者容易混淆。但前者是a[“x”]的语法糖,键是字符串 “x”;后者的键取自变量 x 的当前值,可以是任意类型。
- 不同类型的键,引用的元素也不同:比如字符串 “0”、“+1”、“01” 与数字 0、数字 1 都互不相同。如果不确定索引类型,用
tonumber/tostring显式转换可避免隐蔽 bug。 - 整型与浮点数的例外规则:当浮点数能无损转换成整数时,Lua 会把它先转成整数再存键,因此
2和2.0指向同一条元素;不能整除的浮点数(如 2.1)则保持原样,单独成键。
-- 例5:区分 a.x 与 a[x]a = {}x = \"y\" -- 变量 x 的值是字符串 \"y\"a[x] = 10 -- 等价于 a[\"y\"] = 10a[x] -- 10 (因为 x 等于 \"y\",所以取到 a[\"y\"])a.x -- nil (这里访问的是 a[\"x\"],不存在)a.y -- 10 (显式地访问 a[\"y\"])-- 例6:键类型的区别与显式转换i = 10 -- 数字 10j = \"10\" -- 字符串 \"10\"k = \"+10\" -- 字符串 \"+10\"a = {}a[i] = \"number key\" -- 键是数字 10a[j] = \"string key\" -- 键是字符串 \"10\"a[k] = \"another string key\" -- 键是字符串 \"+10\"a[i] -- \"number key\"a[j] -- \"string key\"a[k] -- \"another string key\"a[tonumber(j)] -- \"number key\"(把字符串 \"10\" 转成数字 10,找到同一条目)a[tonumber(k)] -- \"number key\"(把 \"+10\" 转成数字 10,同样指向数字键 10)-- 例7:整型与浮点数的例外规则a = {}a[2.0] = 10 -- 实际键是整数 2a[2.1] = 20 -- 键仍是浮点数 2.1a[2] --> 10a[2.1] --> 20总结:写 Lua 表索引时,心里先想“键的实际类型”:数字与可转整数的浮点视为同一键,其他情况一律按原类型区分。
练习:以下代码输出是什么?
sunday = \"monday\"; monday = \"sunday\"t = {sunday = \"monday\", [sunday] = monday}print(t.sunday, t[sunday], t[t.sunday])逐步解析:
-
变量赋值:
sunday = \"monday\" -- 全局变量 sunday 的值是字符串 \"monday\"monday = \"sunday\" -- 全局变量 monday 的值是字符串 \"sunday\" -
表构造:
t = { sunday = \"monday\", -- 键为字符串 \"sunday\",值为 \"monday\" [sunday] = monday -- 键为变量 sunday 的值(即 \"monday\"),值为变量 monday 的值(即 \"sunday\")}这等价于:
t = { [\"sunday\"] = \"monday\", -- t.sunday 或 t[\"sunday\"] [\"monday\"] = \"sunday\" -- t[\"monday\"]} -
最终结果是
monday sunday sunday:t.sunday→ 访问键\"sunday\"→ 得到\"monday\"。t[sunday]→sunday的值是\"monday\",即访问t[\"monday\"]→ 得到\"sunday\"。t[t.sunday]→t.sunday是\"monday\",即访问t[\"monday\"]→ 得到\"sunday\"。
5.2 表构造器
构造器是 一次性创建并初始化表 的表达式,是 Lua 最常用、最灵活的机制之一。一共有四种写法:
-
空表:
{} -
列表式:按 1,2,3… 索引,例如:
days = {\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\",\"Thursday\", \"Friday\", \"Saturday\"}print(days[4]) --> Wednesday -
记录式:直接在创建时指定键值(必须是合法标识符)
a = {x = 10, y = 20}--这等价于:a = {}; a.x = 10; a.y = 20在第一种写法中,由于能够提前判断表的大小,所以运行速度更快。
在同一个构造器中,可以混用记录式(record-style)和列表式(list-style)写法,也可以随时增加或删除表元素:
w = {x = 0, y = 0, label = \"console\"} -- 用记录式构造器创建表 wx = {math.sin(0), math.sin(1), math.sin(2)} -- 用列表式构造器创建表 x,存放 3 个数值w[1] = \"another field\" -- 新增一个数字键 1(列表风格)-- 4) x.f = w -- 给 x 新增一个字符串键 \"f\",让它同样指向整张表 wprint(w[\"x\"]) --> 0,访问字段 xprint(w[1]) --> another field,访问数字键 1print(x.f[1]) --> another field,通过 x.f 再访问 w[1]w.x = nil -- 删除字段\"x\"-- 演示嵌套表与混合构造器polyline = { color = \"blue\", -- 记录式字段,指定了键值 thickness = 2, npoints = 4, {x = 0, y = 0}, -- 列表式, Lua 会自动按 连续整数 1, 2, 3… 作为键 {x = -10, y = 0}, -- polyline[2] 第二个子表 {x = -10, y = 1}, -- polyline[3] 第三个子表 {x = 0, y = 1} -- polyline[4] 第四个子表}-- 访问嵌套数据print(polyline[2].x) --> -10,取第二个点的 x 坐标print(polyline[4].y) --> 1,取第四个点的 y 坐标 -
通用格式:前两种构造方法,不能使用负数索引初始化表元素,必须使用合法标识符作为键。用 [expr] = value(带方括号) 可突破标识符限制,可以使用任意表达式做键。
opnames = {[\"+\"] = \"add\", [\"-\"] = \"sub\",[\"*\"] = \"mul\", [\"/\"] = \"div\"}i = 20; s = \"-\"a = {[i+0] = s, [i+1] = s..s, [i+2] = s..s..s}print(opnames[s]) --> subprint(a[22]) --> ---列表式、记录式都只是这种通用写法的语法糖,所以以下写法是等价的:
{x = 0, y = 0} <--> {[\"x\"] = 0, [\"y\"] = 0}{\"r\", \"g\", \"b\"} <--> {[1] = \"r\", [2] = \"g\", [3] = \"b\"}额外语法糖:表的最后一个元素可以加一个逗号或者分号,也可以不加:
a = {[1] = \"red\", [2] = \"green\", [3] = \"blue\",}
5.3 数组、列表和序列
在 Lua 中,用整数键的表 表示传统数组或列表,无需预先声明大小,直接初始化元素即可。所有元素都不为空洞(nil值) 的列表称之为序列(Sequences)。
-- 读取10行,并保存在表a中a = {}for i = 1, 10 doa[i] = io.read()end 索引习惯从 1 开始,长度操作符 #仅对序列有效,返回最后一个非 nil 的整数键。 比如a = {10, 20, 30, nil, nil},这其实与a={10, 20, 30}等价,所以其长度为3。 若表中有空洞(nil值),则# 的结果不可预测,需手动存储表的长度(比如变量 n)。
长度操作符也为操作序列提供了几种有用的写法:
print(a[#a])-- 输出序列\'a\'的最后一个值a[#a] = nil-- 移除最后一个值a[#a + 1]=v-- 把\'v\'加到序列的最后5.4 遍历表
-
使用
pairs遍历键值:t = {10, print, x = 12, k = \"hi\"}for k, v in pairs(t) doprint(k, v)end--> 1 10--> k hi--> 2 function: 0x420610--> x 12受限于表在Lua语言中的底层实现机制,遍历过程中元素的出现顺序可能是随机的,但是每个元素都会被遍历到。
-
使用
ipairs遍历列表。由于索引都是整数,所以遍历按顺序进行:t = {10, print, 12, \"hi\"}for k, v in ipairs(t) doprint(k, v)end--> 1 10--> 2 function: 0x420610--> 3 12--> 4 hi也可以使用for循环:
t = {10, print, 12, \"hi\"}for k = 1, #t doprint(k, t[k])end--> 1 10--> 2 function: 0x420610--> 3 12--> 4 hi
5.5 使用 or {}安全访问表字段
在编程中,我们经常需要检查嵌套的表结构是否存在某个字段。例如,要安全地访问 company.director.address.zipcode,如果 company、director 或 address 中任意一个是 nil,直接访问会导致运行时错误。 传统解决方案如下:
zip = company and company.director and company.director.address and company.director.address.zipcode 这种写法代码冗长且低效,每个层级都要显式检查且可能多次检查(该写法在一次成功的访问中对表进行了6次访问而非3次访问)。在C#中可以使用 安全访问操作符 ?. ——对于表达式a?.b,当a为nil时,其结果是nil而不会产生异常。上式可改写为:
zip = company?.director?.address?.zipcode; 这种写法非常简洁,遇到 nil 会直接返回 nil, 但 Lua 不支持这种语法,因为该语法可能鼓励不严谨的编程风格,取而代之的是 or {} ——对于表达式a or {},当a为nil返回空表,s上式可重写为:
zip = (((company or {}).director or {}).address or {}).zipcode更进一步地,可改写为:
E = {} -- 可复用的空表 ... zip = (((company or E).director or E).address or E).zipcode 上式中,每个字段名只需要被访问一次,还避免了引入新的操作符, 符合 Lua 的极简设计哲学。
5.6 标准库table
Lua 的 table 库提供了一些操作**列表(list)和序列(sequence)**的实用函数,主要包括:
-
table.insert(t, [pos], value): 在指定位置插入元素,后面的元素自动后移。 如果省略位置参数, 默认插入到末尾(相当于t[#t + 1] = value)。t = {10, 20, 30} table.insert(t, 1, 15) --> t = {15, 10, 20, 30} table.insert(t, 40) --> t = {15, 10, 20, 30, 40} -
table.remove(t, [pos]):移除指定位置的元素,后续元素前移填补空缺,最后返回该元素。 如果省略位置参数,则移除最后一个元素(相当于t[#t] = nil)。t = {10, 20, 30} table.remove(t, 1) --> 返回 10,t = {20, 30} table.remove(t) --> 返回 30,t = {20} -
table.move(a, f, e, t, [,dest]): 表示将表a中从索引f到e的元素(包含索引两端)移动到目标表dest的索引t开始的位置。table.move是 Lua 5.3+ 的高效底层实现,比手动循环移动更快。-- 在队首插入元素a = {10, 20, 30} table.move(a, 1, #a, 2) --> a = {10, 10, 20, 30} a[1] = 5 --> a = {5, 10, 20, 30} -- 删除队首元素table.move(a, 2, #a, 1) --> a = {10, 20, 30, 30} a[#a] = nil--> a = {10, 20, 30} ,移除队尾元素b = table.move(a, 1, #a, 1, {}) --> 克隆表a到一个新表中 b = {1, 2, 3} table.move(a, 1, #a, #b + 1, b) --> b = {1, 2, 3, 10, 20, 30} -
table.concat(list, [,sep [,i [,j]]]):将表中元素拼接为字符串,可指定分隔符和范围。local t = {\"a\", \"b\", \"c\"}print(table.concat(t, \"-\")) -- 输出 \"a-b-c\" -
table.sort(t [,comp]):原地排序序列,可自定义比较函数。local t = {3, 1, 4, 1, 5}table.sort(t) -- 默认升序 {1, 1, 3, 4, 5}table.sort(t, function(a,b) return a>b end) -- 降序 {5, 4, 3, 1, 1}-- 合并两个有序列表local a = {1, 3, 5}local b = {2, 4, 6}table.move(b, 1, #b, #a+1, a) -- a变为 {1, 3, 5, 2, 4, 6}table.sort(a) -- 合并后排序 {1, 2, 3, 4, 5, 6}
table.insert 和 table.remove 可用于实现简单的栈、队列和双端队列操作,但在队首操作时效率较低,所以只适用于小规模数据(几百个元素以内)。对于大规模数据,应考虑更高效的数据结构(如链表或双端队列库)。
- 栈(Stack):
push=table.insert(t, x)pop=table.remove(t)
- 队列(Queue)(低效):
push=table.insert(t, x)(入队尾)pop=table.remove(t, 1)(出队首)
- 双端队列(Deque)(低效):
- 队首插入:
table.insert(t, 1, x) - 队首移除:
table.remove(t, 1) - 队尾插入:
table.insert(t, x) - 队尾移除:
table.remove(t)
- 队首插入:


