Spring AI之RAG入门_spring ai rag
目录
1. 什么是RAG
2. RAG典型应用场景
3. RAG核心流程
3.1. 检索阶段
3.2. 生成阶段
4. 使用Spring AI实现RAG
4.1. 创建项目
4.2. 配置application.yml
4.3. 安装ElasticSearch和Kibana
4.3.1. 安装并启动ElasticSearch
4.3.2. 验证ElasticSearch是否启动成功
4.3.3. 安装并启动Kibana
4.3.4. 验证Kibana是否启动成功
4.4. 实现ETL
4.5. 实现相似性检索
4.6. 结合检索结果生成答案
4.7. 创建controller测试接口
4.8. 启动应用并测试
4.8.1. 启动应用后到kibana查看自动创建的index编辑
4.8.2. 调用controller的loadDocuments接口导入数据到ES编辑
4.8.3. 调用controller的rag接口测试rag检索
5. 参考文档
前面的博文《Spring AI介绍及大模型对接》介绍了Spring AI的Models组件及聊天模型对接,本篇文章接着介绍下RAG组件,让我们基于Spring简洁的API和模块化设计快速集成RAG能力,掌握使用Spring AI构建企业级智能问答系统、动态知识引擎等场景应用的开发方法,为打造专业领域的AI解决方案提供可靠技术路径。
1. 什么是RAG
检索增强生成(Retrieval-Augmented Generation,RAG) 是一种结合信息检索与生成式AI的技术,它的核心思想是在生成答案前,先从外部知识库中检索与用户问题相关的信息,并将这些信息作为提示(Prompt)输入模型,从而弥补LLM的静态知识局限。
2. RAG典型应用场景
- 智能问答系统:如企业内部知识库问答,用户可直接提问“公司年假政策是什么?”,系统检索员工手册并生成答案
- 多轮对话增强:结合聊天会话内存(Chat Conversation Memory),支持上下文连贯的交互(如客服场景中的连续追问)
- 文档分析与摘要:从长文本(如法律合同、研究论文)中提取关键信息并生成结构化摘要
3. RAG核心流程
RAG的实现可分为检索和生成两大阶段。
3.1. 检索阶段
- 数据准备
通过ETL流程(提取、转换、加载)处理外部知识库
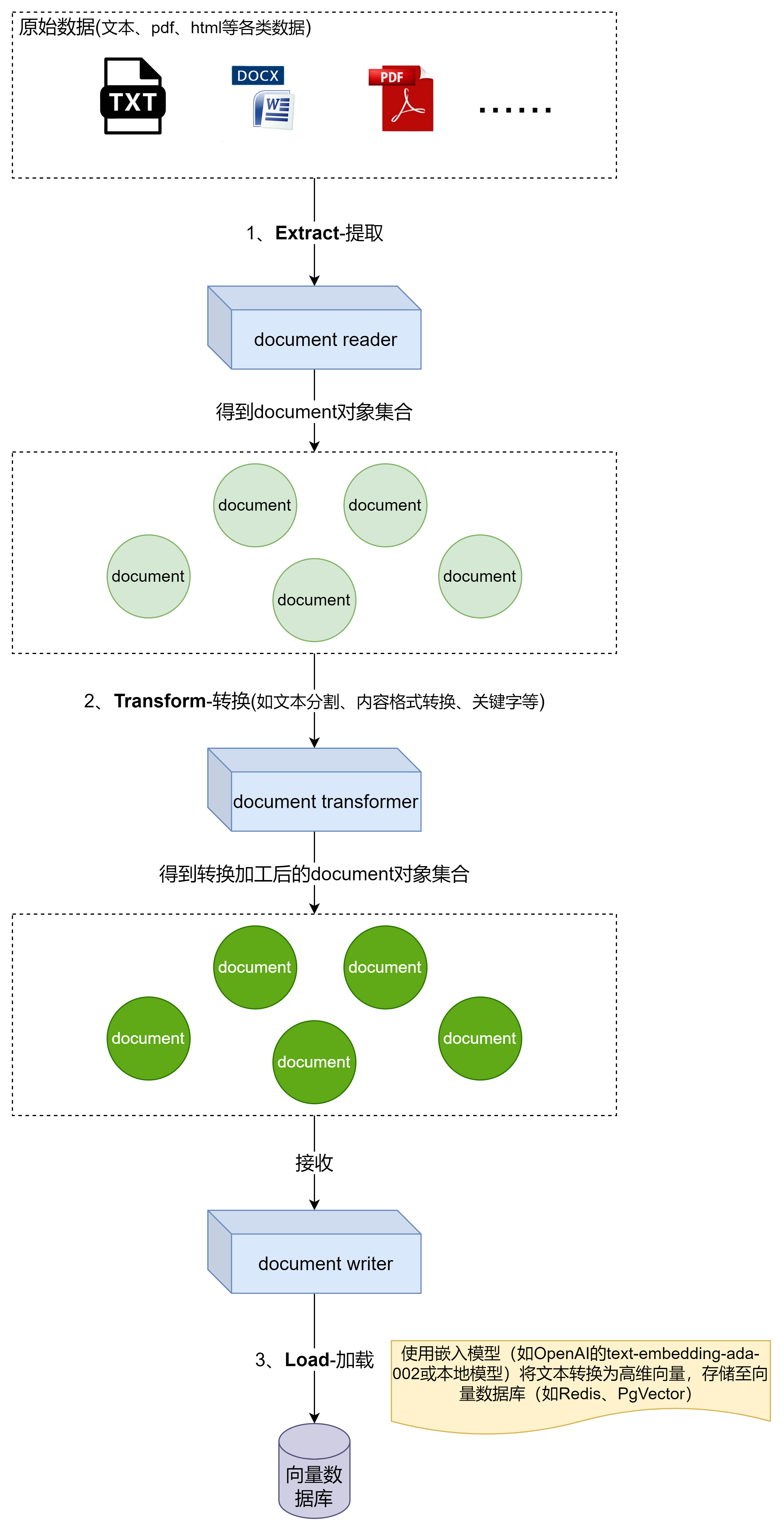
- 相似性检索
将用户查询向量化,并在数据库中搜索最相关的文档片段(如通过余弦相似度算法)
3.2. 生成阶段
- 上下文注入
将检索结果与用户问题结合,构造提示模板。例如:
以下是相关文档:[检索到的内容] 用户问题:[原始问题] 请基于上述文档生成回答: - 生成优化
通过调整提示词设计(如指定输出格式、限制回答范围)和模型参数(如温度值、最大生
成长度),控制生成结果的质量与合规性
4. 使用Spring AI实现RAG
理解了上面介绍的RAG核心流程,接下来我们用Spring AI + 智谱AI(语言模型&向量模型) + elasticsearch(向量数据库)去编写代码实现属于我们自己的RAG。
4.1. 创建项目
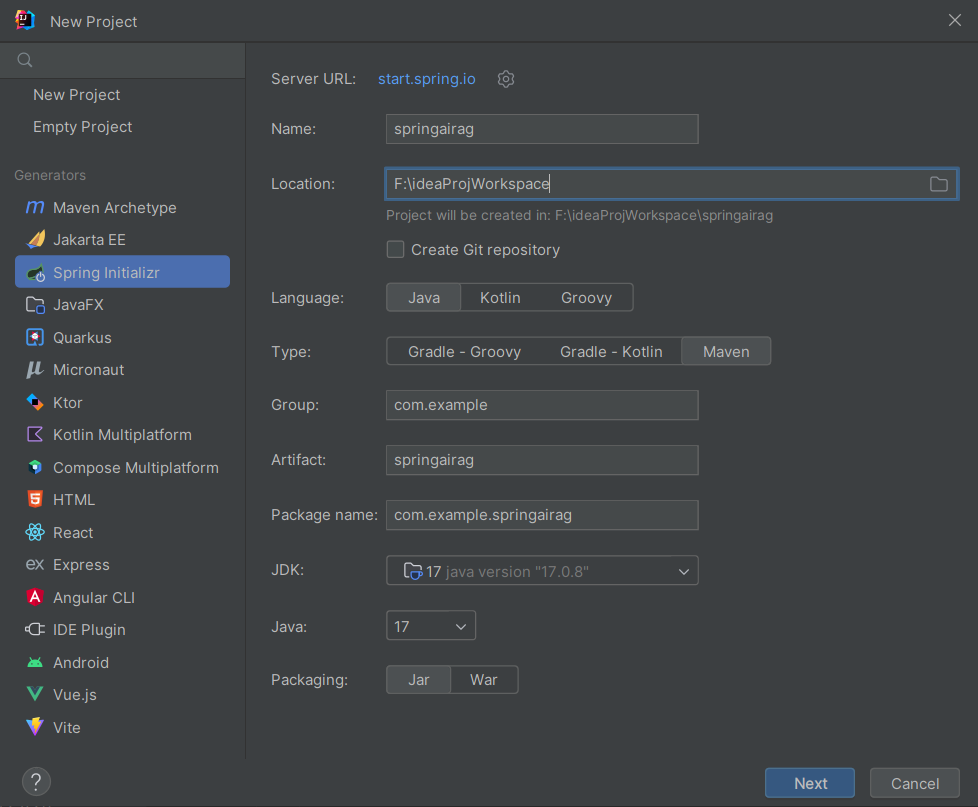
- 使用idea新建项目
- 选择web和ai相关依赖
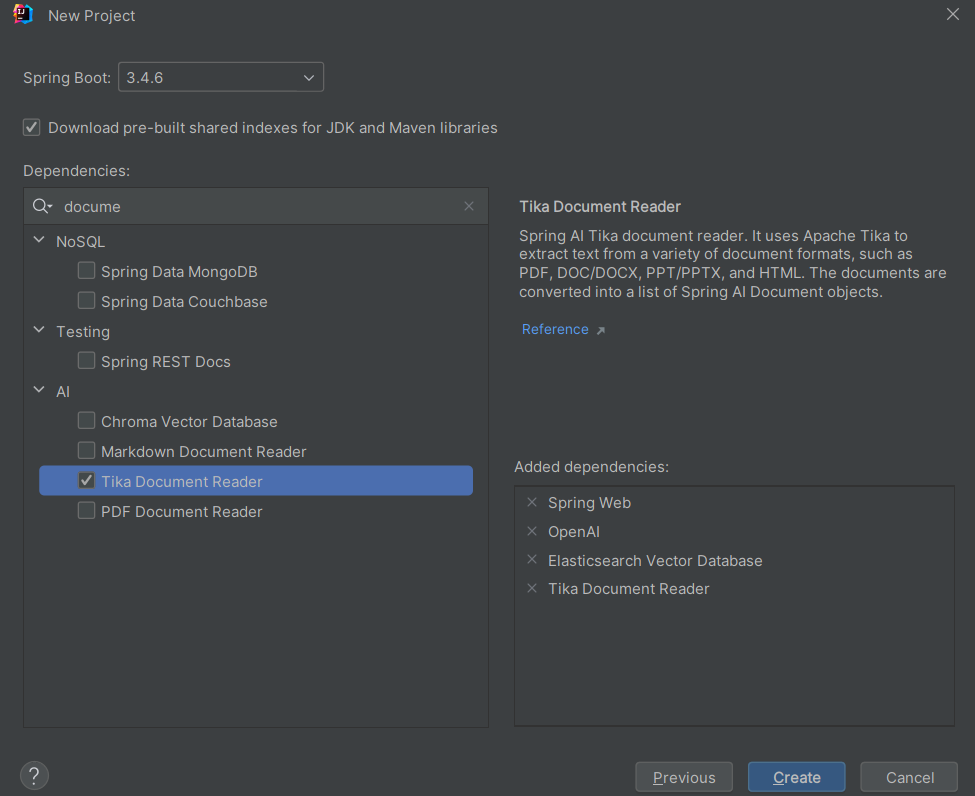
(这里因为智谱也能用OpenAI的API对接,所以引入了OpenAI的依赖,当然按照spring ai官方
文档引入spring-ai-starter-model-zhipuai也行)
- pom.xml
4.0.0 org.springframework.boot spring-boot-starter-parent 3.4.6 com.example springairag 0.0.1-SNAPSHOT springairag springairag 17 1.0.0 org.springframework.boot spring-boot-starter-web org.springframework.ai spring-ai-advisors-vector-store org.springframework.ai spring-ai-starter-model-openai org.springframework.ai spring-ai-starter-vector-store-elasticsearch org.springframework.ai spring-ai-tika-document-reader org.springframework.boot spring-boot-starter-test test org.springframework.ai spring-ai-bom ${spring-ai.version} pom import org.springframework.boot spring-boot-maven-plugin
4.2. 配置application.yml
spring: application: name: springairag elasticsearch: uris: http://localhost:9200 # ES 连接地址 ai: openai: base-url: https://open.bigmodel.cn/api/paas/v4/ # 智谱AI API地址 api-key: 从智谱官网注册获取https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys # 智谱AI APIKey embedding: embeddings-path: embeddings # 重新设置智谱AI的向量模型路径,覆盖openAi默认配置 options: model: embedding-3 # 使用embedding-3文本向量模型 dimensions: 2048 # 向量维度 chat: completions-path: chat/completions # 重新设置智谱AI的聊天模型路径,覆盖openAi默认配置 options: model: glm-4-flash-250414 # 使用glm-4-flash-250414语言模型 vectorstore: elasticsearch: index-name: rag-index # 索引名称 dimensions: 2048 # 必须与 Embedding 模型匹配 initialize-schema: true # 自动创建索引4.3. 安装ElasticSearch和Kibana
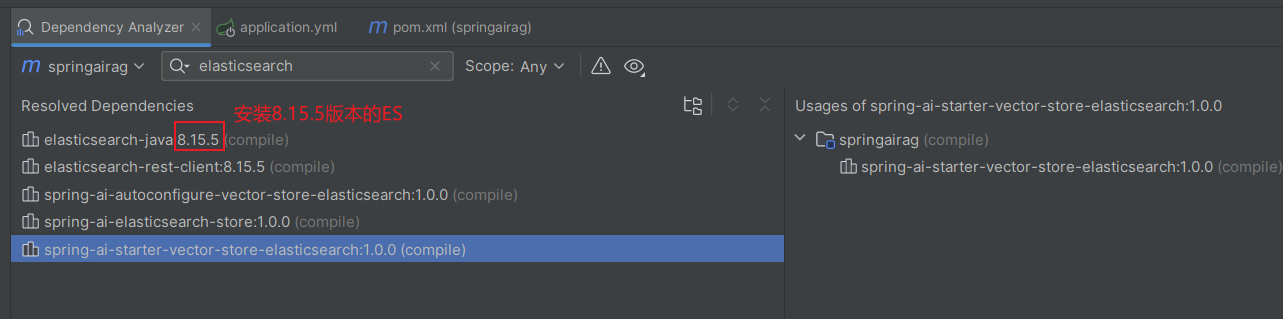
这里我们使用了elasticsearch作为向量数据库存储知识库的数据,用docker安装好对应版本,项目启动时连接使用。ES版本可以在idea maven依赖查看:
4.3.1. 安装并启动ElasticSearch
如果是window可以使用docker desktop,通过命令行按顺序执行如下命令:
# 拉取支持向量搜索的 Elasticsearch 镜像docker pull docker.elastic.co/elasticsearch/elasticsearch:8.15.5# 创建专用网络(可选,避免端口冲突)docker network create elastic-network# 启动单节点 Elasticsearchdocker run -d --name elasticsearch-ai --net elastic-network -p 9200:9200 -p 9300:9300 -e \"discovery.type=single-node\" -e \"ES_JAVA_OPTS=-Xms1g -Xmx1g\" -e \"xpack.security.enabled=false\" docker.elastic.co/elasticsearch/elasticsearch:8.15.5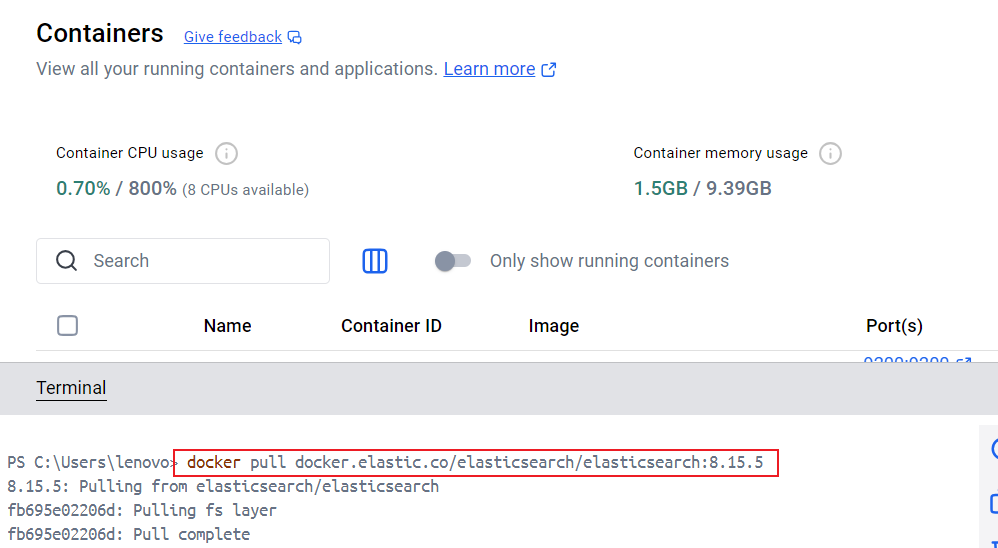
4.3.2. 验证ElasticSearch是否启动成功
浏览器访问http://localhost:9200/正常返回数据说明容器启动完成
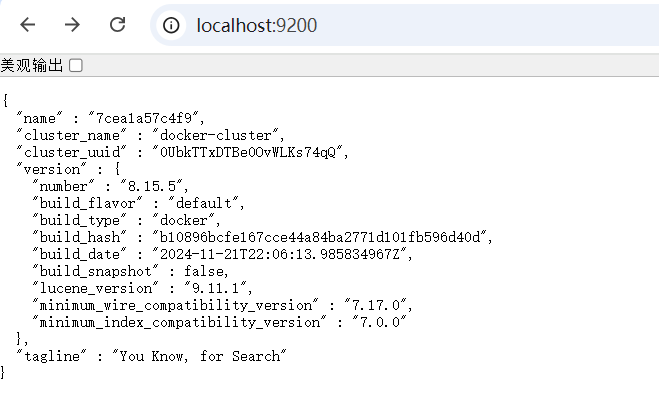
4.3.3. 安装并启动Kibana
同样通过docker desktop命令行按顺序执行如下命令:
# 拉取与 Elasticsearch 版本匹配的 Kibana 镜像docker pull docker.elastic.co/kibana/kibana:8.15.5# 启动 Kibana(确保与 Elasticsearch 使用同一网络)docker run -d --name kibana-ai --net elastic-network -p 5601:5601 -e \"ELASTICSEARCH_HOSTS=http://elasticsearch-ai:9200\" docker.elastic.co/kibana/kibana:8.15.54.3.4. 验证Kibana是否启动成功
浏览器访问http://localhost:5601正常显示Kibana主页说明容器启动完成
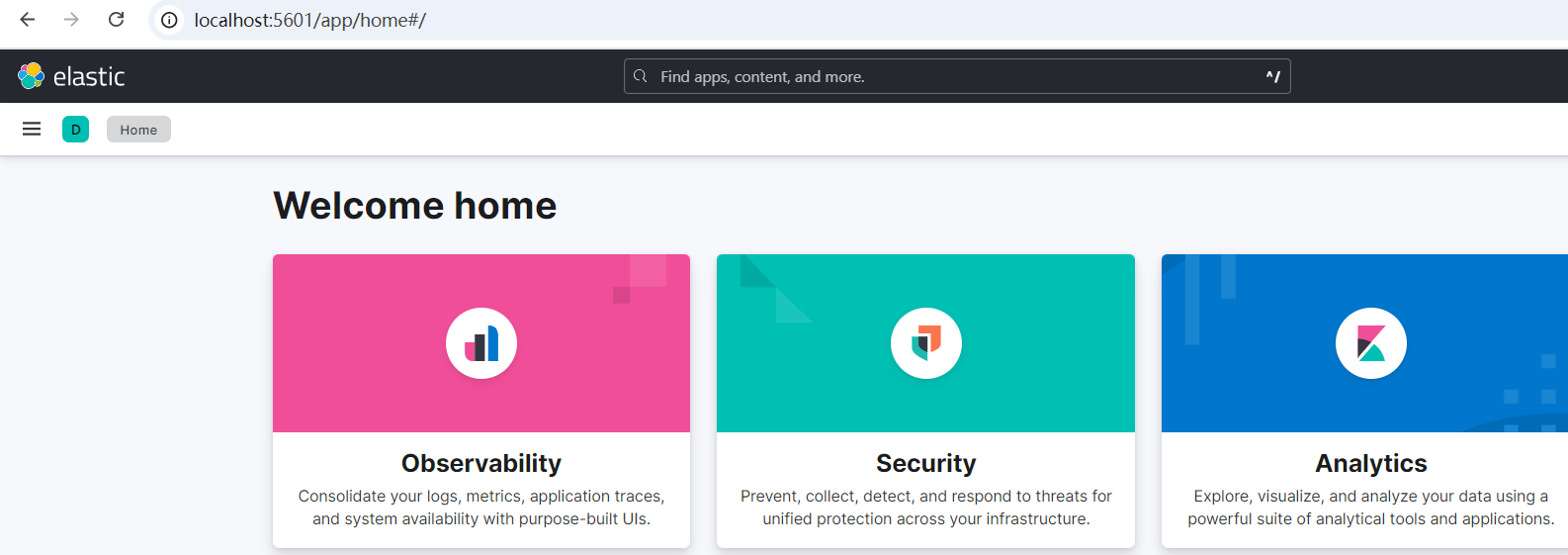
4.4. 实现ETL
- 创建DataLoaderService类,实现ETL的提取、转换、加载三个步骤
package com.example.springairag.service;import jakarta.annotation.Resource;import org.springframework.ai.document.Document;import org.springframework.ai.reader.TextReader;import org.springframework.ai.transformer.splitter.TokenTextSplitter;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.beans.factory.annotation.Value;import org.springframework.stereotype.Service;import java.util.List;/** * ETL类 */@Servicepublic class DataLoaderService { @Value(\"classpath:text-source.txt\") private org.springframework.core.io.Resource txtResource; @Resource private VectorStore vectorStore; public void loadDocuments() { // 提取: 使用文本读取器 TextReader txtReader = new TextReader(txtResource); List documents = txtReader.get(); // 转换:按Token拆分 TokenTextSplitter splitter = new TokenTextSplitter(); List chunks = splitter.apply(documents); // 加载: 存储到ES向量数据库 vectorStore.add(chunks); }}
4.5. 实现相似性检索
package com.example.springairag.service;import jakarta.annotation.Resource;import org.springframework.ai.document.Document;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.stereotype.Service;import java.util.List;/** * 检索服务类 */@Servicepublic class RetrievalService { @Resource private VectorStore vectorStore; public List retrieveContext(String query) { // 检索前5个最相关的文档片段 return vectorStore.similaritySearch( SearchRequest.builder().query(query).topK(5).build()); }}4.6. 结合检索结果生成答案
package com.example.springairag.service;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.chat.messages.UserMessage;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.document.Document;import org.springframework.stereotype.Service;import java.util.List;import java.util.stream.Collectors;@Servicepublic class GenerationService { private final ChatClient chatClient; public GenerationService(ChatClient.Builder chatClientBuilder) { this.chatClient = chatClientBuilder.build(); } public String generateAnswer(String question, List context) { // 知识库文本 String contextText = context.stream() .map(Document::getText) .collect(Collectors.joining()); // 提示词模板 String PROMPT_TEMPLATE = \"\"\" 请根据以下上下文回答问题: {context} 用户问题:{question} 回答时需注意: 1. 仅基于上下文内容回答 2. 若上下文不相关,回答“暂未收录相关信息” \"\"\"; Prompt prompt = new Prompt(new UserMessage( PROMPT_TEMPLATE .replace(\"{context}\", contextText) .replace(\"{question}\", question) )); // 调用模型生成 return chatClient.prompt(prompt).call().chatResponse().getResult().getOutput().getText(); }}4.7. 创建controller测试接口
package com.example.springairag.controller;import com.example.springairag.service.DataLoaderService;import com.example.springairag.service.GenerationService;import com.example.springairag.service.RetrievalService;import jakarta.annotation.Resource;import org.springframework.ai.document.Document;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController@RequestMapping(\"/api\")public class RagController { @Resource private DataLoaderService dataLoader; @Resource private RetrievalService retrievalService; @Resource private GenerationService generationService; /** * 导入文档数据接口 */ @GetMapping(\"/loadDocuments\") public void loadDocuments() { dataLoader.loadDocuments(); } /** * 获取 rag 聊天结果接口 * @param question 用户问题 * @return String 聊天结果 */ @GetMapping(\"/rag\") public String ragChat(@RequestParam String question) { List context = retrievalService.retrieveContext(question); return generationService.generateAnswer(question, context); }}4.8. 启动应用并测试
4.8.1. 启动应用后到kibana查看自动创建的index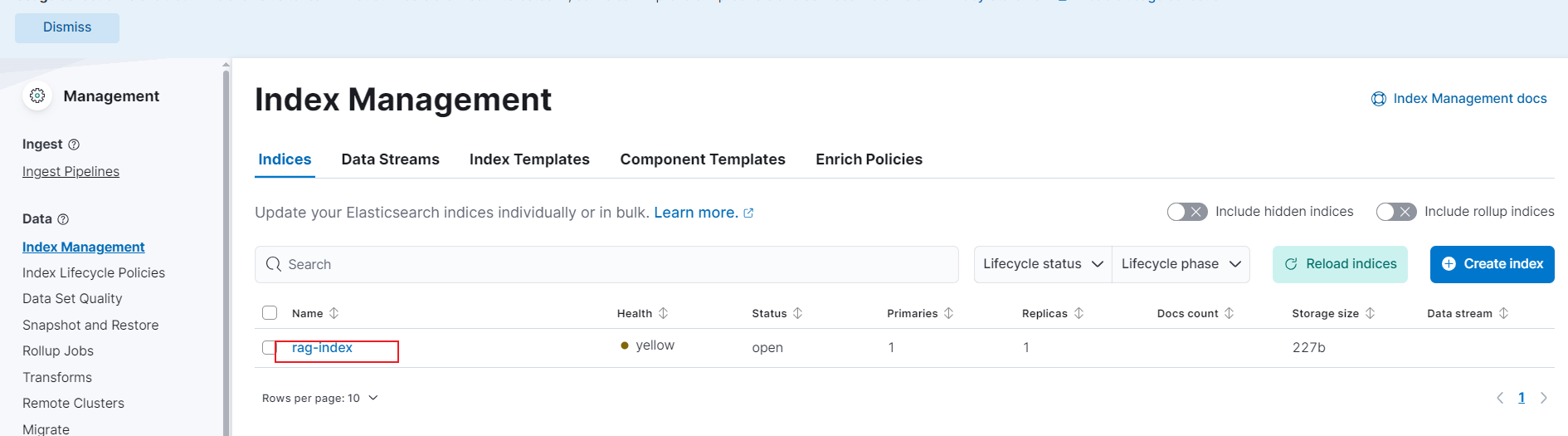
4.8.2. 调用controller的loadDocuments接口导入数据到ES
用以下ES命令查询成功导入的数据:
GET /rag-index/_search{ \"query\": { \"match_all\": {} }, \"size\": 10}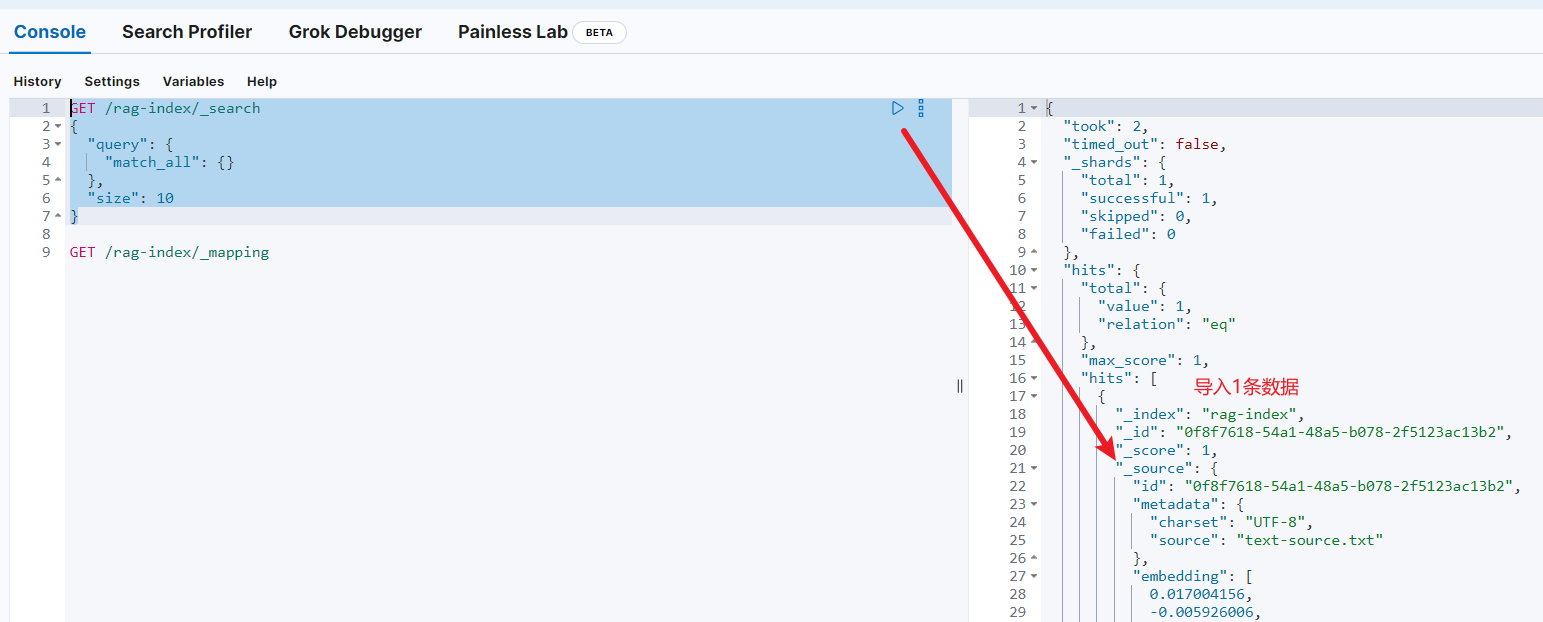
4.8.3. 调用controller的rag接口测试rag检索

5. 参考文档
Spring AI官方文档-智谱向量模型
Spring AI官方文档-Elasticsearch向量数据库
Spring AI官方文档-RAG
智谱大模型-接口文档
智谱大模型-创建api key


