Spark之从平台搭建到WordCount应用全解析
引言
在大数据时代,处理海量数据的需求日益增长。传统Hadoop MapReduce虽然解决了大数据处理的基本问题,但其性能瓶颈和功能局限性促使了更先进计算框架的出现。Spark作为新一代大数据处理引擎,以其卓越的性能和丰富的功能迅速成为行业标准。本文将全面介绍Spark的核心概念、技术优势、生态体系以及实际应用。
一、Spark概述
1.1 什么是Spark
Spark是由加州大学伯克利分校AMP实验室开发的通用内存并行计算框架。它最初诞生于2009年,旨在解决MapReduce在迭代计算和交互式查询方面的性能问题。2013年,Spark成为Apache顶级项目,标志着其在大数据领域的正式崛起。
1.2 Spark与Hadoop的关系
Spark并非Hadoop的替代品,而是Hadoop生态系统的补充和增强:
二、Spark核心优势
2.1 核心架构
https://spark.apache.org/images/spark-architecture.png
Spark采用主从架构:
-
Driver:运行应用main()函数,创建SparkContext
-
Cluster Manager:资源管理(YARN/Mesos/Standalone)
-
Executor:在工作节点上执行任务
2.2 性能优势
-
内存计算:减少磁盘I/O,中间结果保存在内存
-
DAG执行引擎:优化任务执行计划
-
延迟执行:支持流水线优化
-
分区并行:数据自动分区并行处理
官方测试数据:Spark在内存中的运行速度比Hadoop MapReduce快100倍,在磁盘上快10倍。
三、Spark生态系统
Spark生态系统由多个紧密集成的组件构成:
这些组件共享相同的执行引擎和优化策略,使得数据可以在不同处理模式间无缝流转。
四、环境准备
1.硬件软件要求:
1.1linux环境,必须搭建好hadoop平台,包括一个主机master和2个子节点slave1、slave2
1.2远程登录软件MobaXterm
2.MobaXterm连不上?康这里
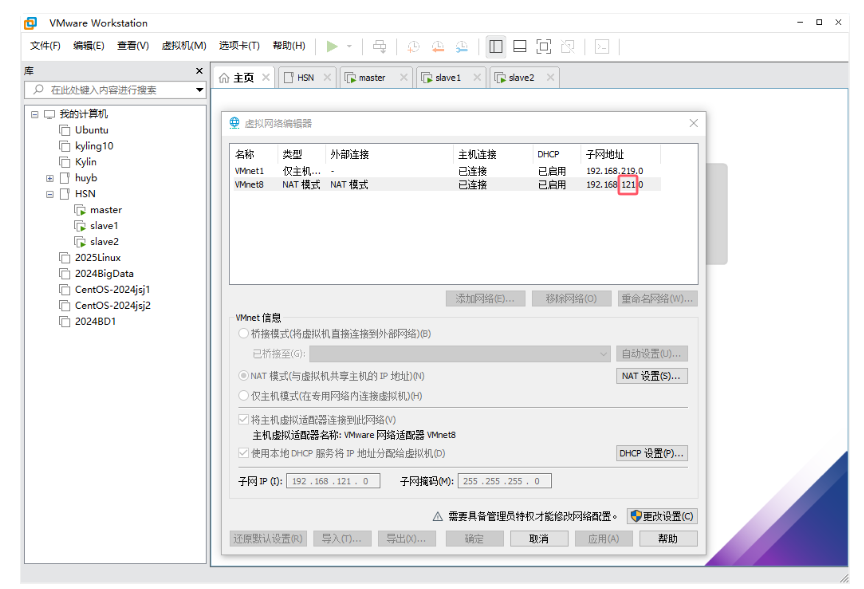
2.1检查vmware的vmnet8是不是192.168.121.0
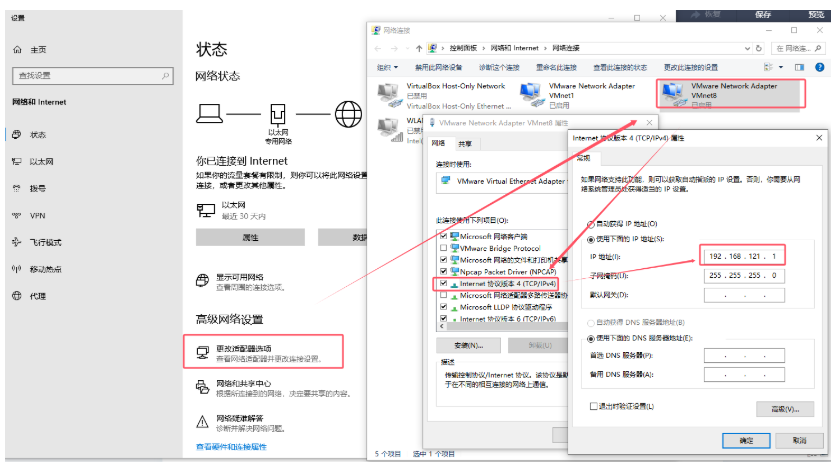
2.2检查Windows系统里的vmnet8是不是192.168.121.1
3.spark搭建关键语句
tar -xzvf spark-3.1.1-bin-hadoop3.2.tgz -C /usr/localSPARK_HOME和PATH,使Spark命令全局可用bash
echo \'export SPARK_HOME=/usr/local/spark-3.1.1-bin-hadoop3.2\' >> /etc/profile
echo \'export PATH=$SPARK_HOME/bin:$PATH\' >> /etc/profile
source /etc/profile
spark-env.sh和workers文件,定义集群环境变量和Worker节点列表bash
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
echo \"source /etc/profile\" >> spark-env.sh
cp workers.template workers
vim workers # 添加Worker节点主机名
rsync -av $SPARK_HOME/ worker1:/usr/local/rsync -av $SPARK_HOME/ worker2:/usr/local/bash
cd $SPARK_HOME/sbin
./start-all.sh
或jps(应看到Master和Worker`进程)bash
cd $SPARK_HOME/bin
./spark-submit --class org.apache.spark.examples.SparkPi --master yarn ../examples/jars/spark-examples_2.12-3.1.1.jar 10
spark-submit --master yarn --class com.example.YourApp /path/to/your-app.jar4.关键配置文件说明
spark-env.shbash
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk
export SPARK_MASTER_HOST=master
workers
worker1
worker2
spark-defaults.conf
spark.executor.memory 4g
spark.driver.memory 2g
5.注意事项
-
依赖环境:确保Hadoop/YARN已启动,且所有节点SSH免密登录配置完成。
-
端口检查:Master默认Web UI端口为
8080,通信端口为7077。 -
资源分配:根据集群实际资源调整
spark-env.sh中的内存和CPU配置。
五、Spark平台搭建实践
5.1 环境准备
搭建Spark集群需要以下基础环境:
-
Hadoop集群:提供分布式存储(HDFS)和资源管理(YARN)
1.1Windows下HADOOP配置
1.2 变量名:HADOOP_HOME
1.3变量值:E:\\wpj\\HDM\\Java\\hadoop-3.1.0(注意,变量值写入你自己存放的路径)
1.4配置PATH:%HADOOP_HOME%\\bin
-
Java环境:Spark运行依赖Java 8或更高版本
-
SSH免密登录:方便集群管理
5.2 详细部署步骤
步骤1:上传并解压Spark
# 上传Spark安装包到master节点scp spark-3.1.1-bin-hadoop3.2.tgz user@master:/tmp# 在master节点解压tar -xzvf /tmp/spark-3.1.1-bin-hadoop3.2.tgz -C /usr/local步骤2:配置环境变量
# 上传Spark安装包到master节点scp spark-3.1.1-bin-hadoop3.2.tgz user@master:/tmp# 在master节点解压tar -xzvf /tmp/spark-3.1.1-bin-hadoop3.2.tgz -C /usr/local使配置生效:
source /etc/profile验证配置:
which spark-submit步骤3:修改Spark配置
-
进入配置目录:
cd /usr/local/spark-3.1.1-bin-hadoop3.2/conf -
创建并配置
spark-env.sh:
cp spark-env.sh.template spark-env.shecho \"source /etc/profile\" >> spark-env.sh-
配置worker节点:
cp workers.template workers# 编辑workers文件,添加所有worker节点主机名-
将配置同步到所有节点:
rsync -av /usr/local/spark-3.1.1-bin-hadoop3.2 worker1:/usr/local/rsync -av /usr/local/spark-3.1.1-bin-hadoop3.2 worker2:/usr/local/步骤4:启动Spark集群
cd /usr/local/spark-3.1.1-bin-hadoop3.2/sbin./start-all.sh验证进程:
ps -ef | grep spark5.3 运行示例程序验证
cd /usr/local/spark-3.1.1-bin-hadoop3.2/bin./run-example SparkPi六、Spark应用开发全流程
6.1 开发环境准备
-
创建Java项目
-
添加Spark依赖(可从Spark安装目录的
jars文件夹获取) -
配置开发工具(如IntelliJ IDEA)
6.2 典型开发流程
-
代码开发:编写Spark应用逻辑
-
本地测试:使用local模式测试
-
打包:生成不含依赖的JAR包
-
提交集群:通过spark-submit提交到YARN
6.3 示例代码片段
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;public class SparkHDFSReader { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName(\"HDFS Reader\"); JavaSparkContext sc = new JavaSparkContext(conf); // 从HDFS读取文件 JavaRDD textFile = sc.textFile(\"hdfs://namenode:9000/hello.txt\"); // 打印文件内容 textFile.foreach(line -> System.out.println(line)); sc.stop(); }}6.4 提交应用到集群
spark-submit --master yarn --class com.example.SparkHDFSReader /path/to/your-app.jar七、Spark应用场景
7.1 新能源汽车大数据分析案例
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;public class NewEnergyVehicleAnalysis { public static void main(String[] args) { // 1. 创建Spark配置和上下文 SparkConf conf = new SparkConf() .setAppName(\"NewEnergyVehicle Analysis\") .setMaster(\"yarn\"); JavaSparkContext sc = new JavaSparkContext(conf); // 2. 读取HDFS上的车辆日志数据 JavaRDD logs = sc.textFile(\"hdfs://master:9000/vehicle_logs/*.log\"); // 3. 分析故障代码出现频率 logs.filter(line -> line.contains(\"ERROR_CODE\")) .mapToPair(line -> { String code = line.split(\":\")[1].trim(); return new Tuple2(code, 1); }) .reduceByKey((a, b) -> a + b) .sortByKey() .saveAsTextFile(\"hdfs://master:9000/output/error_stats\"); sc.close(); }}新能源汽车大数据平台需要解决两大核心问题:
第一个Spark应用开发--新能源汽车大数据分析平台搭建
Spark非常适合处理新能源汽车产生的海量数据:
-
车辆状态监控:实时分析车辆运行数据
-
电池性能分析:通过机器学习预测电池寿命
-
用户行为分析:分析驾驶习惯和充电模式
spark-submit --master=yarn /root/spark_demo.jar yarnyarn logs -applicationId application_1632840026531_0003
报错
vi /etc/profile.d/my_env.sh
添加以下内容:
export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.3/etc/hadoop/
export YARN_CONF_DIR=/usr/local/hadoop-3.1.3/etc/hadoop/
保存后,source /etc/profile
7.2 其他行业应用
-
金融风控:实时欺诈检测
-
电商推荐:个性化推荐系统
-
物联网:设备数据分析
-
医疗健康:基因组数据分析
八、WordCount深度解析与实践
8.1 业务场景
新能源汽车每天产生大量运行日志数据,包含车辆状态、故障代码等信息。我们需要统计特定关键词出现的频率,为故障预测和用户行为分析提供支持。
8.2 完整实现代码
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;public class WordCount { public static void main(String[] args) { // 1. 创建Spark配置和上下文 SparkConf conf = new SparkConf() .setAppName(\"NewEnergyVehicle WordCount\") .setMaster(\"yarn\"); JavaSparkContext sc = new JavaSparkContext(conf); // 2. 读取HDFS文件 JavaRDD lines = sc.textFile(\"hdfs://master:9000/hello.txt\"); // 3. 转换操作 JavaRDD words = lines.flatMap(line -> Arrays.asList(line.split(\" \")).iterator()); // 4. 行动操作 - 统计总数 long count = words.count(); System.out.println(\"单词数量为:\" + count); // 5. 排序并输出 words.sortBy(word -> word, true, words.partitions().size()) .collect() .forEach(System.out::println); // 6. 关闭上下文 sc.close(); }}8.3 核心算子对比
性能优化技巧:
-
合理设置分区数:
repartition()或coalesce() -
持久化常用RDD:
cache()或persist() -
广播大变量:
broadcast() -
减少shuffle操作
九、生产环境最佳实践
9.1 资源配置建议
spark-submit --master yarn \\ --executor-memory 4G \\ --num-executors 10 \\ --executor-cores 2 \\ --class com.example.YourApp \\ /path/to/your-app.jar9.2 常见问题解决
问题1:内存不足
yarn.nodemanager.vmem-pmem-ratio 2.5问题2:资源分配不合理
yarn.scheduler.maximum-allocation-mb 81929.3 监控与调优
-
Spark UI:访问
http://master:4040查看作业详情 -
日志分析:
yarn logs -applicationId -
性能指标:关注GC时间、任务倾斜、shuffle大小等
十、Spark未来发展趋势
-
AI集成:与TensorFlow、PyTorch等深度学习框架深度整合
-
实时计算增强:Structured Streaming功能强化
-
云原生支持:更好的Kubernetes集成
-
性能优化:持续提升执行引擎效率
-
多语言支持:增强Python/R API功能对等性
结语
Spark作为当今最流行的大数据处理框架,凭借其卓越的性能、丰富的功能和活跃的社区支持,已经成为大数据领域的事实标准。通过本文的介绍,希望您已经对Spark有了全面的了解,并能够开始自己的Spark开发之旅。
无论是新能源汽车大数据分析,还是其他行业应用,Spark都能提供高效、灵活的解决方案。随着技术的不断发展,Spark必将在更多领域展现其价值。

