[2025CVPR-少样本学习方向]使用 CLIP 进行 Logits DeConfusion 以进行少样本学习
1. 研究背景与问题陈述
CLIP作为一种强大的视觉-语言模型,通过大规模图像-文本对比学习,在零样本学习(Zero-Shot Learning, ZSL)和少样本学习中表现出色。它能够将图像和文本映射到共享嵌入空间,实现对新类别的泛化,减少对标注数据的依赖。然而,文档指出,CLIP在应用于下游少样本任务时存在一个关键缺陷:其logits(分类输出得分)出现严重的类间混淆问题。具体表现为,不同类别的预测得分难以区分,导致分类精度下降(尤其在类别相似度高或领域差异大的场景下)。这一问题的根源在于CLIP的预训练策略:
- CLIP通过对比学习优化图像-文本对齐,而非直接优化分类边界,导致分类任务中的判别能力不足。
- 下游数据与预训练数据的领域差异加剧了混淆现象。
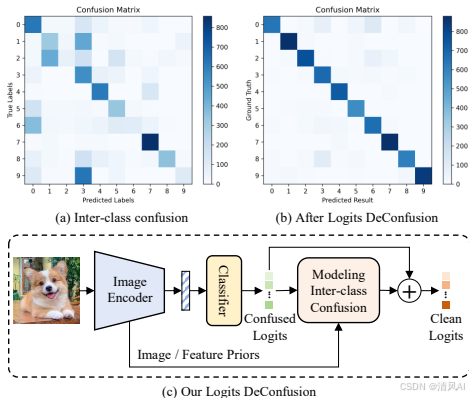
Figure 1 直观展示了这一问题:在CLIP-based ZSL中,logits存在显著混淆(图1a);消除混淆后(图1b),类别区分更清晰;LDC方法(图1c)通过建模和移除混淆来优化结果。
这一问题严重限制了CLIP在少样本学习中的性能提升,因为模型难以从少量样本中学习可靠的分类器。因此,作者的目标是开发一种方法,有效建模并消除类间混淆,提高CLIP在FSL任务中的准确性和泛化能力。
2. 方法设计:Logits DeConfusion (LDC)
LDC方法的核心是结合两个模块:Multi-level Adapter Fusion (MAF) 和 Inter-Class Deconfusion (ICD),并通过Adaptive Logits Fusion (ALF) 模块进行最终输出融合。整体架构旨在学习并移除logits中的混淆噪声,同时保留CLIP的丰富特征表示。方法基于残差学习思想,假设混淆可建模为一个可学习的噪声项。

