火山引擎实时语音合成WebSocket V3协议Python实现demo_火山引擎 tts websocket 实践
火山引擎语音整体特点
火山引擎(字节跳动旗下)的语音合成产品确实非常面向多媒体内容创作,特别是短视频、有声书和多人场景。
1. 音色多样性与场景细分
火山引擎提供了极其丰富的音色选择(100+音色),并按以下场景精细分类:
多情感音色:支持情感变化,适合短视频叙事
通用场景:基础音色
趣味口音:各地方言口音,非常适合短视频创意内容
角色扮演:大量角色化音色(40+种),明显针对剧情类短视频、对白场景
视频配音:专为视频内容优化的音色
有声阅读:针对长文本朗读的优化音色
2. 适合抖音等短视频平台的特点
丰富的角色音色:如\"奶气萌娃\"、“病弱少女”、\"傲娇霸总\"等,这些音色非常适合抖音等平台上的角色扮演、情景剧类短视频
多方言支持:提供北京、台湾、广东、四川等多地方言音色,有助于创作地域特色内容
多情感支持:部分音色支持多种情感变化(如开心、悲伤、生气等),可以制作情感丰富的短视频内容
3. 有声书场景优势
专门的\"有声阅读\"分类:包含\"悬疑解说\"、\"儒雅青年\"等适合长文本朗读的音色
情感化表达:多情感支持使有声书朗读更具表现力
角色化音色:适合对话丰富的小说朗读,可以为不同角色分配不同音色
4. 多人对话场景支持
角色音色的多样性:从\"萌娃\"到\"婆婆\",从\"病娇弟弟\"到\"成熟姐姐\",提供了几乎所有可能的人物形象
互补性角色设计:如\"贴心男友\"与\"傲娇女友\"等角色对,适合多人对话场景
多情感支持:使对话更生动自然
与其他TTS产品的区别
相比其他TTS服务(如微软Azure、Amazon Polly等),火山引擎更加注重:
- 角色化与人设:其他平台往往只提供中性或基础的男女声音色,而火山引擎深度开发了具有鲜明人格特征的音色
- 中文场景优化:特别是中文方言和文化特色的表达 多媒体内容创作导向:明显针对视频内容创作者设计
总结
火山引擎(字节旗下)的TTS模型突出特点是丰富的角色化音色(100+种),特别优化了短视频、有声书和多人对话场景。提供大量具体人设音色(如\"傲娇霸总\"、“病弱少女”)、多情感表达能力、中文方言支持。
整体更适合有声书,短视频制作等场景,但是目前对于一些具身智能、导览机器人,跨语种的交互机器人上来说,感觉当前提供的模型不太够用。
代码说明
- 基于官方示例,添加注释
- 移除了websocket库的引用
- 修正了正确的音色列表https://www.volcengine.com/docs/6561/1257544
申请语音技术的appid和token
网站链接
https://console.volcengine.com/speech/app
大模型语音合成必选,其他的看自己需求。这个也可以后续来这个控制台修改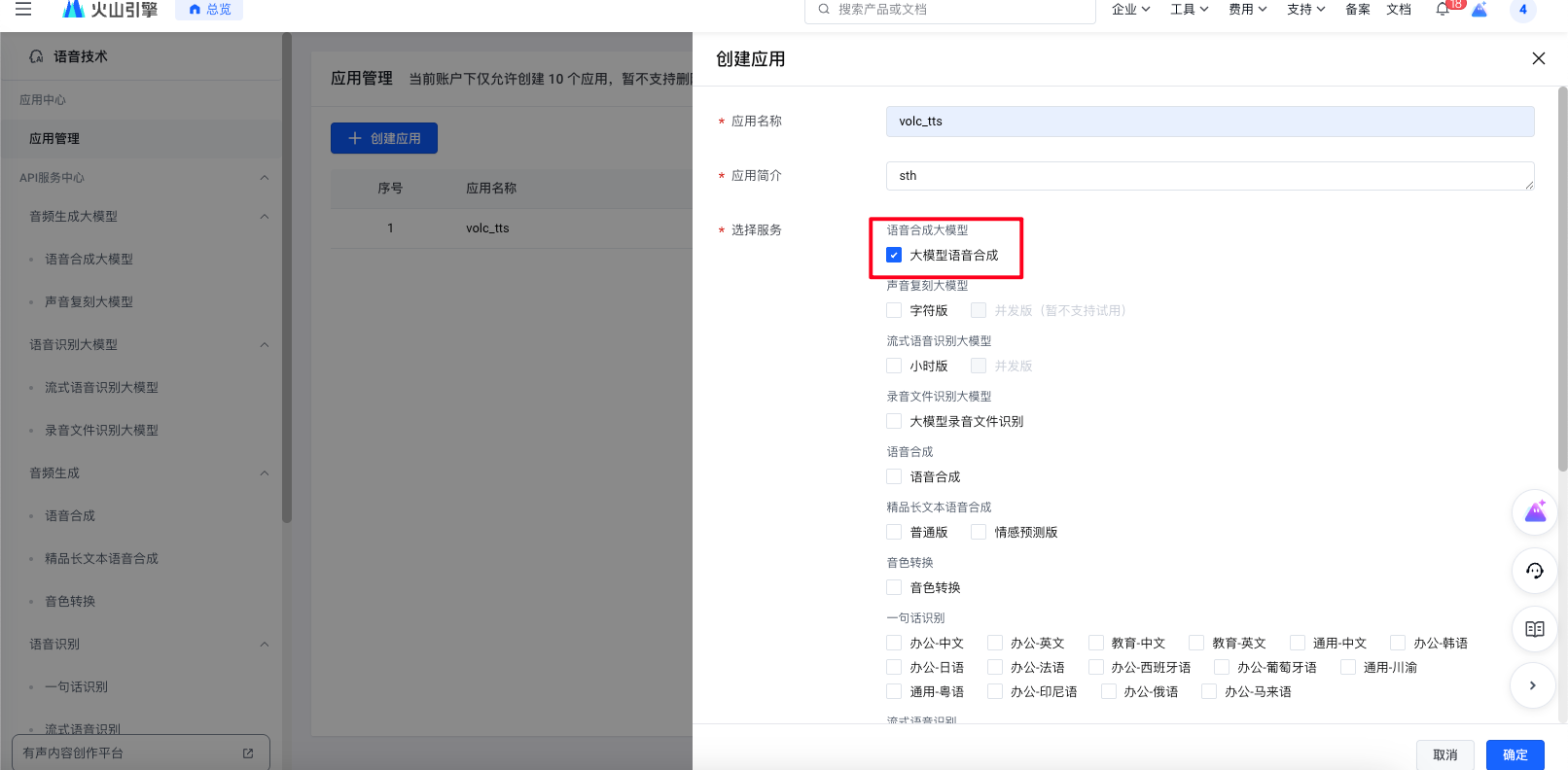
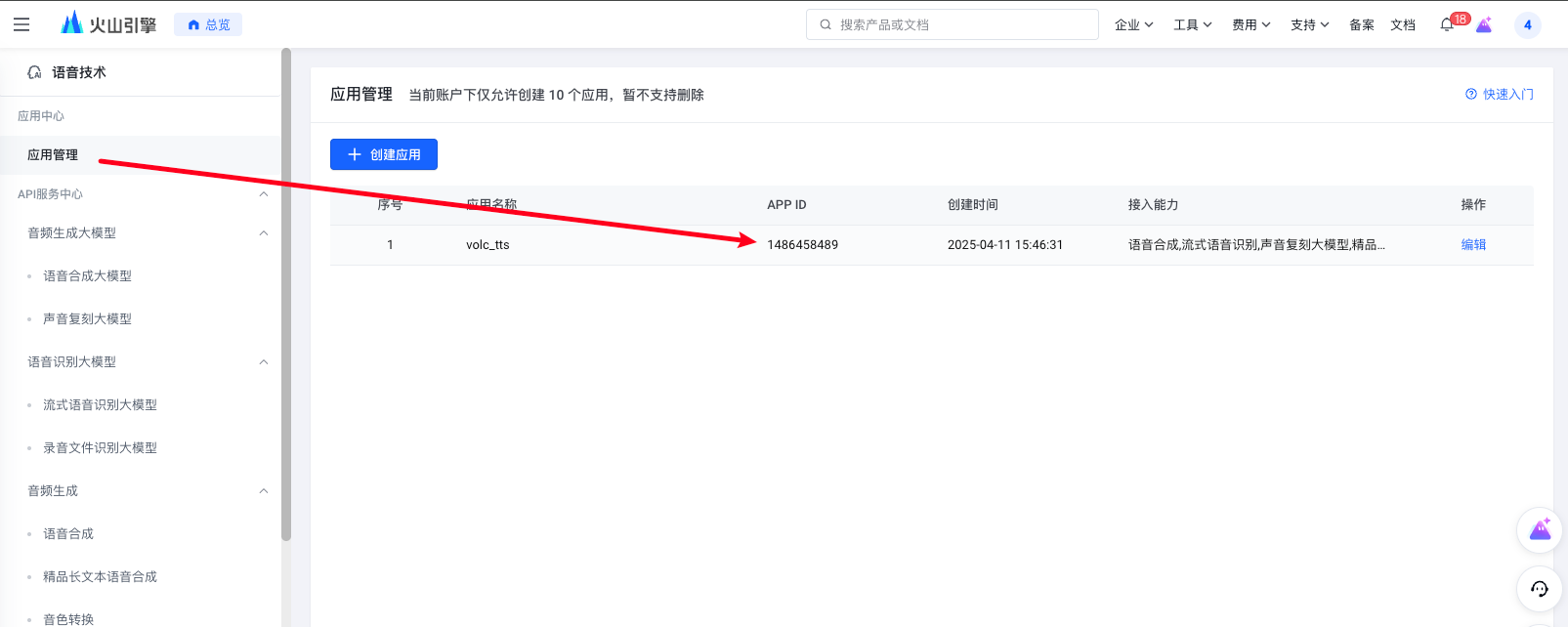
然后我们在应用管理就可以看到我们的appid。
切换到语音合成大模型,下拉,点开显示,就可以获取我们需要的token了。
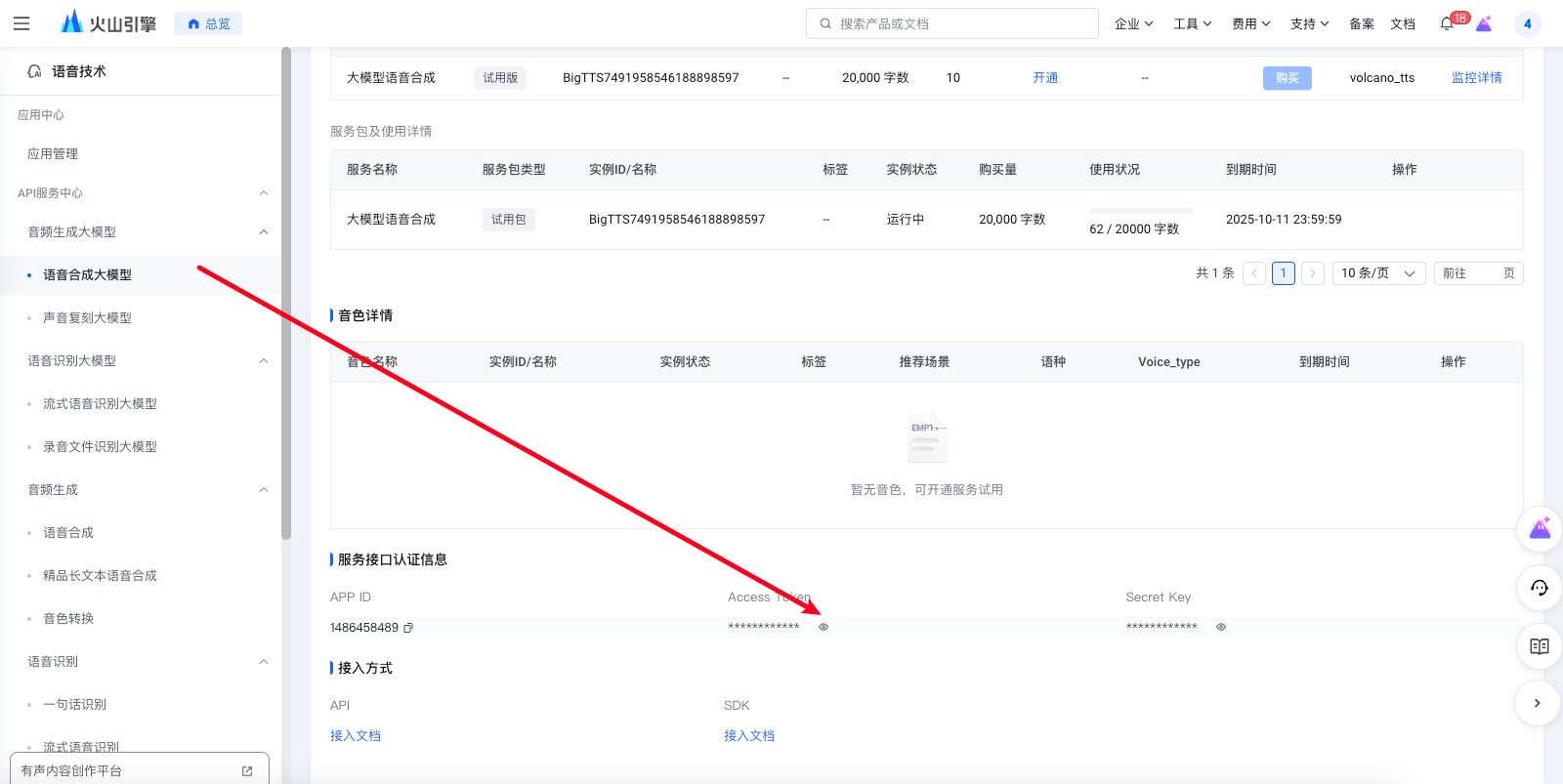
后面的代码中我们会用到这两个参数:
appId = \"\" # 替换为您自己的
token = \"\" # 替换为您自己的 Token
代码
# -*- coding: utf-8 -*-# @Time : 2025/4/22 10:28# @Author : Mark White# @FileName: vocal_notation.py# @Software: PyCharm# -*- coding: utf-8 -*-\"\"\"火山引擎实时语音合成 WebSocket V3 协议 Python 示例本脚本演示了如何使用 websockets 库通过 WebSocket V3 协议与火山引擎的实时语音合成服务进行交互。主要流程包括:1. 定义协议常量:包括协议版本、消息类型、标志位、序列化方法、压缩方法和事件代码。2. 定义数据结构:使用 `Header`, `Optional`, `Response` 类来封装协议消息的各个部分。3. 实现协议辅助函数: - `get_payload_bytes`: 构建符合协议要求的 JSON payload。 - `send_event`: 封装发送消息的逻辑,自动添加头部、可选部分和负载。 - `read_res_content`, `read_res_payload`: 从响应字节流中读取特定部分(字符串内容、负载)。 - `parser_response`: 解析服务器返回的二进制响应,填充 `Response` 对象。 - `print_response`: 打印响应对象的详细信息,用于调试。4. 实现核心 API 调用函数: - `start_connection`: 发送建立连接的请求。 - `start_session`: 发送开始一个合成会话的请求。 - `send_text`: 发送需要合成的文本。 - `finish_session`: 发送结束当前会话的请求。 - `finish_connection`: 发送断开连接的请求。5. 实现主业务逻辑函数 `run_demo`: - 设置必要的认证信息和请求参数。 - 建立 WebSocket 连接。 - 按顺序调用 API 函数:建立连接 -> 开始会话 -> 发送文本 -> 结束会话 -> 结束连接。 - 处理服务器响应,特别是接收音频数据并写入文件。 - 进行必要的错误检查。6. 主程序入口 (`if __name__ == \"__main__\":`): - 配置用户凭证、合成文本、发音人等参数。 - 使用 asyncio 运行主业务逻辑。使用的主要库:- asyncio: Python 标准库,用于编写异步代码。- websockets: 一个用于构建 WebSocket 客户端和服务器的库,支持异步操作。- aiofiles: 提供异步文件操作接口,用于非阻塞地写入音频文件。- json: Python 标准库,用于处理 JSON 数据(构建 payload)。- uuid: Python 标准库,用于生成唯一的 session ID 和 connection ID。\"\"\"import asyncioimport jsonimport uuid# 异步文件操作库import aiofiles# WebSocket 客户端库 (注意: 原代码导入了 websocket 和 websockets, 实际主要使用了 websockets)# import websocket # 这个库在本示例的异步流程中未使用,注释掉以减少混淆import websocketsfrom websockets.asyncio.client import ClientConnection # 明确导入 ClientConnection 类型提示# --- 协议常量定义 ---# 参考文档: https://www.volcengine.com/docs/6561/1329505#%E7%A4%BA%E4%BE%8Bsamples# 协议版本 (固定为 0b0001)PROTOCOL_VERSION = 0b0001# 默认头部大小 (固定为 0b0001, 表示 4 字节)DEFAULT_HEADER_SIZE = 0b0001# --- 消息类型 (Message Type) ---# 用于标识消息的主要目的# 客户端完整请求 (包含 header, optional, payload)FULL_CLIENT_REQUEST = 0b0001# 服务端响应:仅音频数据AUDIO_ONLY_RESPONSE = 0b1011# 服务端完整响应 (包含 header, optional, payload)FULL_SERVER_RESPONSE = 0b1001# 服务端错误信息ERROR_INFORMATION = 0b1111# --- 消息类型特定标志位 (Message Type Specific Flags) ---# 用于提供关于消息类型的额外信息MsgTypeFlagNoSeq = 0b0000 # 非终止数据包,无序列号 (sequence=0)MsgTypeFlagPositiveSeq = 0b1 # 非终止数据包,有正序列号 (sequence>0)MsgTypeFlagLastNoSeq = 0b10 # 最后一个数据包,无序列号 (sequence=0)MsgTypeFlagNegativeSeq = 0b11 # 最后一个数据包,有负序列号 (sequence<0),通常表示错误MsgTypeFlagWithEvent = 0b100 # 标志位,表示 Optional 部分包含 Event 字段 (用于区分是否携带事件)# --- 消息序列化方法 (Message Serialization) ---# 指示 Payload 部分的序列化方式NO_SERIALIZATION = 0b0000 # 无序列化 (通常用于纯音频数据)JSON = 0b0001 # JSON 序列化# --- 消息压缩方法 (Message Compression) ---# 指示 Payload 部分的压缩方式COMPRESSION_NO = 0b0000 # 无压缩COMPRESSION_GZIP = 0b0001 # Gzip 压缩 (本示例未使用)# --- 事件代码 (Event Codes) ---# 用于在 Optional 部分标识具体的业务事件EVENT_NONE = 0 # 无事件# --- 连接管理事件 ---EVENT_Start_Connection = 1 # 客户端请求建立连接EVENT_FinishConnection = 2 # 客户端请求关闭连接EVENT_ConnectionStarted = 50 # 服务端响应:成功建立连接EVENT_ConnectionFailed = 51 # 服务端响应:建立连接失败 (如认证失败)EVENT_ConnectionFinished = 52 # 服务端响应:连接已关闭# --- 会话管理事件 (上行 - 客户端发起) ---EVENT_StartSession = 100 # 客户端请求开始一个 TTS 会话EVENT_FinishSession = 102 # 客户端请求结束一个 TTS 会话# --- 会话管理事件 (下行 - 服务端响应) ---EVENT_SessionStarted = 150 # 服务端响应:会话已开始EVENT_SessionFinished = 152 # 服务端响应:会话已结束EVENT_SessionFailed = 153 # 服务端响应:会话失败# --- 通用业务事件 (上行 - 客户端发起) ---EVENT_TaskRequest = 200 # 客户端发送具体的业务请求 (如发送文本进行合成)# --- TTS 业务事件 (下行 - 服务端响应) ---EVENT_TTSSentenceStart = 350 # 服务端响应:开始处理一个句子EVENT_TTSSentenceEnd = 351 # 服务端响应:结束处理一个句子EVENT_TTSResponse = 352 # 服务端响应:返回 TTS 音频数据或相关信息# --- 数据结构类 ---class Header: \"\"\" 封装 WebSocket V3 协议的消息头部 (Header)。 头部固定为 4 字节,包含协议版本、头部大小、消息类型、特定标志、序列化方法、压缩方法等信息。 \"\"\" def __init__(self, protocol_version=PROTOCOL_VERSION, # 协议版本,默认为 PROTOCOL_VERSION header_size=DEFAULT_HEADER_SIZE, # 头部大小,默认为 DEFAULT_HEADER_SIZE message_type: int = 0, # 消息类型,如 FULL_CLIENT_REQUEST message_type_specific_flags: int = 0, # 消息类型特定标志,如 MsgTypeFlagWithEvent serial_method: int = NO_SERIALIZATION, # Payload 序列化方法,如 JSON compression_type: int = COMPRESSION_NO, # Payload 压缩方法 reserved_data=0): # 保留字段,默认为 0 \"\"\" 初始化 Header 对象。 参数按协议规范设置默认值或传入指定值。 \"\"\" self.header_size = header_size self.protocol_version = protocol_version self.message_type = message_type self.message_type_specific_flags = message_type_specific_flags self.serial_method = serial_method self.compression_type = compression_type self.reserved_data = reserved_data def as_bytes(self) -> bytes: \"\"\" 将 Header 对象转换为符合协议规范的 4 字节 bytes 对象。 使用位运算将各个字段组合到字节中。 Returns: bytes: 包含头部信息的 4 字节 bytes 对象。 \"\"\" # 第 1 字节: (协议版本 << 4) | 头部大小 byte1 = (self.protocol_version << 4) | self.header_size # 第 2 字节: (消息类型 << 4) | 消息类型特定标志 byte2 = (self.message_type << 4) | self.message_type_specific_flags # 第 3 字节: (序列化方法 << 4) | 压缩方法 byte3 = (self.serial_method << 4) | self.compression_type # 第 4 字节: 保留字段 byte4 = self.reserved_data # 组合成 bytes 对象 return bytes([byte1, byte2, byte3, byte4])class Optional: \"\"\" 封装 WebSocket V3 协议的可选部分 (Optional)。 这部分内容根据消息头中的标志位和事件类型决定是否存在及其具体内容, 通常包含事件代码 (Event)、会话 ID (SessionId)、序列号 (Sequence) 等。 \"\"\" def __init__(self, event: int = EVENT_NONE, sessionId: str = None, sequence: int = None): \"\"\" 初始化 Optional 对象。 Args: event (int, optional): 事件代码,默认为 EVENT_NONE。 sessionId (str, optional): 会话 ID,默认为 None。 sequence (int, optional): 序列号,默认为 None。 \"\"\" self.event = event # 事件代码 self.sessionId = sessionId # 会话 ID self.sequence = sequence # 序列号 (本示例中未使用,但协议支持) # 以下字段主要用于解析服务端响应,在客户端发送时通常不设置 self.errorCode: int = 0 # 错误码 (来自服务端响应) self.connectionId: str | None = None # 连接 ID (来自服务端响应) self.response_meta_json: str | None = None # 响应元数据 (来自服务端响应, JSON 字符串) def as_bytes(self) -> bytes: \"\"\" 将 Optional 对象中需要发送的字段(event, sessionId, sequence)转换为 bytes。 字段顺序和格式需严格遵守协议规范。 - Event: 4 字节大端整数 (如果 event 不是 EVENT_NONE) - SessionId: 4 字节长度 (大端) + SessionId 字符串的 UTF-8 bytes (如果 sessionId 不为 None) - Sequence: 4 字节大端整数 (如果 sequence 不为 None) Returns: bytes: 包含可选部分信息的 bytes 对象。 \"\"\" option_bytes = bytearray() # 使用 bytearray 方便追加 # 如果包含有效事件代码,则添加 Event 字段 (4 字节,大端序,有符号整数) if self.event != EVENT_NONE: # to_bytes(4, \"big\", signed=True) 将整数转为 4 字节大端序 bytes option_bytes.extend(self.event.to_bytes(4, \"big\", signed=True)) # 如果包含会话 ID,则添加 SessionId 字段 if self.sessionId is not None: # 将 SessionId 字符串编码为 UTF-8 bytes session_id_bytes = str.encode(self.sessionId) # 获取 SessionId bytes 的长度 size = len(session_id_bytes) # 添加长度字段 (4 字节,大端序,有符号整数) option_bytes.extend(size.to_bytes(4, \"big\", signed=True)) # 添加 SessionId 的 bytes 内容 option_bytes.extend(session_id_bytes) # 如果包含序列号,则添加 Sequence 字段 (4 字节,大端序,有符号整数) if self.sequence is not None: option_bytes.extend(self.sequence.to_bytes(4, \"big\", signed=True)) # 返回最终构建的 bytes 对象 return bytes(option_bytes)class Response: \"\"\" 用于封装从服务器接收到的已解析的响应消息。 包含解析后的 Header, Optional 部分,以及可能的 Payload (二进制或 JSON 字符串)。 \"\"\" def __init__(self, header: Header, optional: Optional): \"\"\" 初始化 Response 对象。 Args: header (Header): 解析得到的 Header 对象。 optional (Optional): 解析得到的 Optional 对象。 \"\"\" self.header = header # 消息头部对象 self.optional = optional # 可选部分对象 self.payload: bytes | None = None # 负载的原始二进制数据 (如音频) self.payload_json: str | None = None # 负载的 JSON 字符串内容 (如句子开始/结束事件的元信息) def __str__(self): \"\"\" 提供 Response 对象的基本字符串表示(可选,用于调试)。 \"\"\" # 可以根据需要自定义更详细的字符串输出 return f\"Response(Header={self.header.__dict__}, Optional={self.optional.__dict__}, Payload_len={len(self.payload or b\'\')}, Payload_json={self.payload_json})\"# --- 协议辅助函数 ---def get_payload_bytes(uid=\'1234\', event=EVENT_NONE, text=\'\', speaker=\'\', audio_format=\'mp3\',audio_sample_rate=24000) -> bytes: \"\"\" 构建用于发送给服务器的 JSON Payload,并将其编码为 bytes。 根据不同的事件类型和参数填充 JSON 结构。 Args: uid (str, optional): 用户 ID。默认为 \'1234\'。 event (int, optional): 当前请求关联的事件代码。默认为 EVENT_NONE。 text (str, optional): 需要合成的文本 (仅在 EVENT_TaskRequest 时有效)。默认为 \'\'。 speaker (str, optional): 发音人标识 (在 EVENT_StartSession 和 EVENT_TaskRequest 时需要)。默认为 \'\'。 audio_format (str, optional): 请求的音频格式。默认为 \'mp3\'。 audio_sample_rate (int, optional): 请求的音频采样率。默认为 24000。 Returns: bytes: 编码后的 JSON Payload bytes。 \"\"\" # 构建 Python 字典表示 JSON 结构 payload_dict = { \"user\": {\"uid\": uid}, # 用户信息 \"event\": event, # 事件代码 \"namespace\": \"BidirectionalTTS\", # 命名空间,固定为 \"BidirectionalTTS\" \"req_params\": { # 请求参数 \"text\": text, # 合成文本 \"speaker\": speaker, # 发音人 \"audio_params\": { # 音频参数 \"format\": audio_format, # 音频格式 \"sample_rate\": audio_sample_rate # 音频采样率 } } } # 使用 json.dumps 将字典转换为 JSON 字符串 # 使用 str.encode 将 JSON 字符串编码为 UTF-8 bytes return str.encode(json.dumps(payload_dict))async def send_event(ws: ClientConnection, header: bytes, optional: bytes | None = None, payload: bytes | None = None): \"\"\" 向 WebSocket 连接发送一个完整的 V3 协议消息。 自动组装 Header, Optional (如果提供), Payload Size (如果提供), Payload。 Args: ws (ClientConnection): 已建立的 websockets 客户端连接对象。 header (bytes): 序列化后的 Header (4 字节)。 optional (bytes | None, optional): 序列化后的 Optional 部分。如果为 None 则不发送。 payload (bytes | None, optional): Payload 数据。如果为 None 则不发送。 Raises: TypeError: 如果 ws 不是 ClientConnection 类型。 \"\"\" # 检查 ws 类型,确保是 websockets 的 ClientConnection if not isinstance(ws, ClientConnection): raise TypeError(f\"Expected websockets.asyncio.client.ClientConnection, got {type(ws)}\") # 使用 bytearray 构建完整的客户端请求消息 full_client_request = bytearray(header) # 如果 Optional 部分存在,则追加到消息中 if optional is not None: full_client_request.extend(optional) # 如果 Payload 部分存在 if payload is not None: # 计算 Payload 的长度 payload_size = len(payload) # 将长度转换为 4 字节大端序 bytes,并追加到消息中 (协议要求) full_client_request.extend(payload_size.to_bytes(4, \'big\', signed=True)) # 追加 Payload 的实际内容 full_client_request.extend(payload) # 通过 WebSocket 连接异步发送完整的消息 # print(f\"Sending message: {full_client_request.hex()}\") # 调试用:打印发送的消息内容 await ws.send(full_client_request)def read_res_content(res: bytes, offset: int) -> tuple[str, int]: \"\"\" 从响应字节流 `res` 的指定 `offset` 处读取一个 \"内容块\"。 内容块格式为:4 字节长度 (大端) + UTF-8 编码的字符串内容。 常用于读取 ConnectionId, SessionId, response_meta_json 等。 Args: res (bytes): 包含响应数据的字节流。 offset (int): 开始读取的偏移量。 Returns: tuple[str, int]: 返回包含读取到的字符串内容和更新后的偏移量的元组。 \"\"\" # 从 offset 处读取 4 字节,解析为内容长度 (大端序整数) content_size = int.from_bytes(res[offset: offset + 4], \'big\') # 假设长度为非负,用 \'big\' 即可 # 更新偏移量,跳过长度字段 offset += 4 # 根据解析出的长度,读取相应字节数的内容 content_bytes = res[offset: offset + content_size] # 将读取到的 bytes 使用 UTF-8 解码为字符串 content = str(content_bytes, encoding=\'utf8\') # 更新偏移量,跳过内容字段 offset += content_size # 返回解析到的字符串和新的偏移量 return content, offsetdef read_res_payload(res: bytes, offset: int) -> tuple[bytes, int]: \"\"\" 从响应字节流 `res` 的指定 `offset` 处读取 Payload 部分。 Payload 格式为:4 字节长度 (大端) + Payload 二进制数据。 Args: res (bytes): 包含响应数据的字节流。 offset (int): 开始读取的偏移量。 Returns: tuple[bytes, int]: 返回包含读取到的 Payload 二进制数据和更新后的偏移量的元组。 \"\"\" # 从 offset 处读取 4 字节,解析为 Payload 长度 (大端序整数) payload_size = int.from_bytes(res[offset: offset + 4], \'big\') # 假设长度为非负 # 更新偏移量,跳过长度字段 offset += 4 # 根据解析出的长度,读取相应字节数的 Payload 数据 payload = res[offset: offset + payload_size] # 更新偏移量,跳过 Payload 数据 offset += payload_size # 返回读取到的 Payload bytes 和新的偏移量 return payload, offsetdef parser_response(res) -> Response: \"\"\" 解析从 WebSocket 收到的原始响应数据 `res`,填充并返回一个 `Response` 对象。 根据 Header 中的信息(特别是消息类型和标志位)来决定如何解析 Optional 和 Payload 部分。 Args: res (bytes | str): 从 WebSocket 收到的原始数据。期望是 bytes,如果是 str 则表示出错。 Returns: Response: 包含解析后信息的 Response 对象。 Raises: RuntimeError: 如果输入的 res 是字符串,表示可能接收到了错误消息或非预期数据。 IndexError: 如果 res 的长度不足以解析预期字段。 \"\"\" # 如果收到的是字符串,通常表示连接出错或服务器发送了非二进制错误信息 if isinstance(res, str): raise RuntimeError(f\"Received string message, expected bytes. Message: {res}\") # 检查响应长度是否至少包含头部 (4 字节) if len(res) < 4: raise ValueError(f\"Response too short to contain a header. Length: {len(res)}\") # 初始化用于存储解析结果的 Response 对象 response = Response(Header(), Optional()) # --- 解析 Header (前 4 字节) --- header = response.header # 掩码,用于提取低 4 位 num_mask = 0b00001111 # 字节 0: 高 4 位是协议版本,低 4 位是头部大小 header.protocol_version = (res[0] >> 4) & num_mask header.header_size = res[0] & num_mask # 使用掩码提取低 4 位 # 字节 1: 高 4 位是消息类型,低 4 位是特定标志 header.message_type = (res[1] >> 4) & num_mask header.message_type_specific_flags = res[1] & num_mask # 字节 2: 高 4 位是序列化方法,低 4 位是压缩方法 header.serial_method = (res[2] >> 4) & num_mask # 注意:原文这里写反了,应为 >> 4 header.compression_type = res[2] & num_mask # 注意:原文这里写反了,应为 & 0x0f # 字节 3: 保留字段 header.reserved_data = res[3] # 注意:原文类属性名和这里变量名不一致,统一为 reserved_data # --- 解析 Optional 和 Payload --- # 初始化偏移量,指向 Header 之后的位置 offset = 4 # Header 固定 4 字节 optional = response.optional # 根据消息类型判断如何解析后续部分 if header.message_type in [FULL_SERVER_RESPONSE, AUDIO_ONLY_RESPONSE]: # 对于服务端响应 (完整或仅音频),检查是否包含 Event 字段 # MsgTypeFlagWithEvent (0b100) 标志位指示 Optional 部分存在 Event if header.message_type_specific_flags & MsgTypeFlagWithEvent: # 使用位与操作检查标志位 # 检查是否有足够字节读取 Event (4 字节) if offset + 4 > len(res): raise ValueError(f\"Response too short for Event field. Offset: {offset}, Length: {len(res)}\") # 读取 4 字节的 Event 代码 (大端序,有符号) optional.event = int.from_bytes(res[offset:offset + 4], \"big\", signed=True) # 更新偏移量 offset += 4 # --- 根据具体的 Event 代码解析 Optional 中的其他字段 --- # 注意:这里的解析逻辑需要严格对应协议文档中每个事件的响应格式 if optional.event == EVENT_NONE: # 无事件,通常 Optional 部分结束 pass # 可能后面还有 Payload,继续解析 elif optional.event == EVENT_ConnectionStarted: # 连接成功事件,包含 ConnectionId optional.connectionId, offset = read_res_content(res, offset) elif optional.event == EVENT_ConnectionFailed: # 连接失败事件,包含错误信息的 JSON optional.response_meta_json, offset = read_res_content(res, offset) elif optional.event in [EVENT_SessionStarted, EVENT_SessionFailed, EVENT_SessionFinished]: # 会话开始/失败/结束事件,包含 SessionId 和可能的元信息 JSON optional.sessionId, offset = read_res_content(res, offset) optional.response_meta_json, offset = read_res_content(res, offset) elif optional.event == EVENT_TTSResponse: # TTS 响应事件 (通常是音频),包含 SessionId 和音频 Payload optional.sessionId, offset = read_res_content(res, offset) # 读取音频 Payload response.payload, offset = read_res_payload(res, offset) elif optional.event in [EVENT_TTSSentenceStart, EVENT_TTSSentenceEnd]: # 句子开始/结束事件,包含 SessionId 和元信息 JSON Payload optional.sessionId, offset = read_res_content(res, offset) # 注意:这里读取的是 JSON 字符串 Payload,不是二进制 Payload # 需要一个类似 read_res_payload 但返回 str 的函数,或者调整 read_res_payload # 暂时假设 read_res_content 可以读取这种 JSON payload (如果其格式是 长度+内容) # 或者,如果 payload_json 本身就是 payload 部分的内容: payload_bytes, offset = read_res_payload(res, offset) try: response.payload_json = payload_bytes.decode(\'utf-8\') except UnicodeDecodeError: print(f\"Warning: Could not decode payload as UTF-8 for event {optional.event}\") response.payload_json = repr(payload_bytes) # 存原始 repr # --- 解析可能存在的 Payload (即使没有 Event) --- # 对于 AUDIO_ONLY_RESPONSE,即使没有 Event 标志,也可能直接跟 Payload # 对于 FULL_SERVER_RESPONSE,在 Optional 之后可能还有 Payload # 检查是否还有剩余字节,并且剩余字节数大于等于 Payload 长度字段 (4 字节) if offset + 4 <= len(res): # 尝试读取 Payload (如果前面事件解析时未读取) # 注意:需要判断是否已经读取过 Payload,避免重复读取 if response.payload is None and response.payload_json is None: # 简单假设剩余的就是 Payload (需要根据协议确认此逻辑是否总是正确) # 或者更严谨地,检查 Header 中的序列化方法等信息 # 如果是 AUDIO_ONLY_RESPONSE,几乎总是音频 Payload if header.message_type == AUDIO_ONLY_RESPONSE: response.payload, offset = read_res_payload(res, offset) # 对于 FULL_SERVER_RESPONSE,需要更明确的规则判断是否有 Payload # (例如,检查序列化方法是否为 NO_SERIALIZATION 或 JSON) # 此处简化处理,如果还有数据且未被解析,尝试按 Payload 读取 elif header.message_type == FULL_SERVER_RESPONSE: # 检查剩余长度是否足够表示一个最小的payload(长度字段) if len(res) > offset + 4: # 尝试读取,如果失败(如长度超出范围)会抛出异常 try: # 这里需要区分是二进制 payload 还是 json payload if header.serial_method == JSON: payload_bytes, temp_offset = read_res_payload(res, offset) try: response.payload_json = payload_bytes.decode(\'utf-8\') offset = temp_offset except UnicodeDecodeError: print(f\"Warning: Could not decode JSON payload as UTF-8 for event {optional.event}\") # 不更新 offset,保留原始字节供调试 elif header.serial_method == NO_SERIALIZATION: response.payload, offset = read_res_payload(res, offset) # else: 其他序列化方法暂不处理 except Exception as e: print(f\"Warning: Error trying to parse trailing payload: {e}\") elif header.message_type == ERROR_INFORMATION: # 错误信息类型 # 检查是否有足够字节读取 ErrorCode (4 字节) if offset + 4 > len(res): raise ValueError(f\"Response too short for ErrorCode field. Offset: {offset}, Length: {len(res)}\") # 读取 4 字节的错误码 (大端序,有符号) optional.errorCode = int.from_bytes(res[offset:offset + 4], \"big\", signed=True) offset += 4 # 错误信息通常还包含一个描述性的 Payload response.payload, offset = read_res_payload(res, offset) # 可以尝试将 payload 解码为字符串以获取错误描述 try: response.payload_json = response.payload.decode(\'utf-8\') # 假设错误描述是 UTF-8 except (UnicodeDecodeError, TypeError): pass # 解码失败或 payload 为 None # 返回填充好的 Response 对象 return responsedef print_response(res: Response, tag: str): \"\"\" 打印 Response 对象的详细信息,用于调试。 Args: res (Response): 要打印的 Response 对象。 tag (str): 用于标识打印来源的前缀字符串。 \"\"\" # 打印 Header 字典 print(f\'===>{tag} header:{res.header.__dict__}\') # 打印 Optional 字典 print(f\'===>{tag} optional:{res.optional.__dict__}\') # 打印二进制 Payload 的长度 payload_len = 0 if res.payload is None else len(res.payload) print(f\'===>{tag} payload len:{payload_len}\') # 打印 JSON Payload 字符串 print(f\'===>{tag} payload_json:{res.payload_json}\')# --- 核心 API 调用函数 ---async def start_connection(ws: ClientConnection): \"\"\" 发送 \"Start Connection\" 事件 (EVENT_Start_Connection) 给服务器。 Args: ws (ClientConnection): WebSocket 连接对象。 \"\"\" # 构建 Header: 消息类型为客户端请求,带 Event 标志 header = Header(message_type=FULL_CLIENT_REQUEST, message_type_specific_flags=MsgTypeFlagWithEvent).as_bytes() # 构建 Optional: 包含 Start Connection 事件代码 optional = Optional(event=EVENT_Start_Connection).as_bytes() # 构建 Payload: 对于 Start Connection,通常为空 JSON 对象 \"{}\" payload = str.encode(\"{}\") # 发送事件 await send_event(ws, header, optional, payload) print(\"===> Sent Start Connection event\")async def start_session(ws: ClientConnection, speaker: str, session_id: str): \"\"\" 发送 \"Start Session\" 事件 (EVENT_StartSession) 给服务器。 Args: ws (ClientConnection): WebSocket 连接对象。 speaker (str): 请求使用的发音人标识。 session_id (str): 本次会话的唯一 ID。 \"\"\" # 构建 Header: 客户端请求,带 Event 标志,Payload 为 JSON header = Header(message_type=FULL_CLIENT_REQUEST, message_type_specific_flags=MsgTypeFlagWithEvent, serial_method=JSON).as_bytes() # 构建 Optional: 包含 Start Session 事件代码和 Session ID optional = Optional(event=EVENT_StartSession, sessionId=session_id).as_bytes() # 构建 Payload: 包含事件代码和发音人信息 payload = get_payload_bytes(event=EVENT_StartSession, speaker=speaker) # 发送事件 await send_event(ws, header, optional, payload) print(f\"===> Sent Start Session event (Session ID: {session_id})\")async def send_text(ws: ClientConnection, speaker: str, text: str, session_id: str): \"\"\" 发送 \"Task Request\" 事件 (EVENT_TaskRequest) 给服务器,携带要合成的文本。 Args: ws (ClientConnection): WebSocket 连接对象。 speaker (str): 发音人标识。 text (str): 需要合成的文本。 session_id (str): 当前会话的 ID。 \"\"\" # 构建 Header: 客户端请求,带 Event 标志,Payload 为 JSON header = Header(message_type=FULL_CLIENT_REQUEST, message_type_specific_flags=MsgTypeFlagWithEvent, serial_method=JSON).as_bytes() # 构建 Optional: 包含 Task Request 事件代码和 Session ID optional = Optional(event=EVENT_TaskRequest, sessionId=session_id).as_bytes() # 构建 Payload: 包含事件代码、文本和发音人信息 payload = get_payload_bytes(event=EVENT_TaskRequest, text=text, speaker=speaker) # 发送事件 await send_event(ws, header, optional, payload) print(f\"===> Sent Task Request event (Text: \'{text[:20]}...\')\")async def finish_session(ws: ClientConnection, session_id: str): \"\"\" 发送 \"Finish Session\" 事件 (EVENT_FinishSession) 给服务器。 Args: ws (ClientConnection): WebSocket 连接对象。 session_id (str): 要结束的会话的 ID。 \"\"\" # 构建 Header: 客户端请求,带 Event 标志,Payload 为 JSON (虽然内容为空) header = Header(message_type=FULL_CLIENT_REQUEST, message_type_specific_flags=MsgTypeFlagWithEvent, serial_method=JSON).as_bytes() # 构建 Optional: 包含 Finish Session 事件代码和 Session ID optional = Optional(event=EVENT_FinishSession, sessionId=session_id).as_bytes() # 构建 Payload: 通常为空 JSON 对象 \"{}\" payload = str.encode(\'{}\') # 发送事件 await send_event(ws, header, optional, payload) print(f\"===> Sent Finish Session event (Session ID: {session_id})\")async def finish_connection(ws: ClientConnection): \"\"\" 发送 \"Finish Connection\" 事件 (EVENT_FinishConnection) 给服务器。 Args: ws (ClientConnection): WebSocket 连接对象。 \"\"\" # 构建 Header: 客户端请求,带 Event 标志,Payload 为 JSON (虽然内容为空) header = Header(message_type=FULL_CLIENT_REQUEST, message_type_specific_flags=MsgTypeFlagWithEvent, serial_method=JSON).as_bytes() # 构建 Optional: 包含 Finish Connection 事件代码 optional = Optional(event=EVENT_FinishConnection).as_bytes() # 构建 Payload: 通常为空 JSON 对象 \"{}\" payload = str.encode(\'{}\') # 发送事件 await send_event(ws, header, optional, payload) print(\"===> Sent Finish Connection event\")# --- 主业务逻辑 ---async def run_demo(appId: str, token: str, speaker: str, text: str, output_path: str): \"\"\" 运行 TTS WebSocket V3 示例的主函数。 完成连接、认证、发送文本、接收音频、关闭连接的完整流程。 Args: appId (str): 应用 ID (从火山引擎获取)。 token (str): 访问令牌 (从火山引擎获取)。 speaker (str): 发音人标识。 text (str): 要合成的文本。 output_path (str): 保存输出音频文件的路径。 \"\"\" # WebSocket 连接地址 url = \'wss://openspeech.bytedance.com/api/v3/tts/bidirection\' # 构建 WebSocket 连接请求头,用于身份认证和资源指定 ws_header = { \"X-Api-App-Key\": appId, # 应用 ID \"X-Api-Access-Key\": token, # 访问令牌 \"X-Api-Resource-Id\": \'volc.service_type.10029\', # 请求的资源 ID (TTS 服务) \"X-Api-Connect-Id\": str(uuid.uuid4()), # 本次连接的唯一 ID } print(f\"Connecting to {url}...\") # 使用 websockets.connect 建立异步 WebSocket 连接 # additional_headers: 传递认证等头部信息 # max_size: 设置接收消息的最大尺寸 (设置为较大值以处理长音频) async with websockets.connect(url, additional_headers=ws_header, max_size=1000000000) as ws: print(\"WebSocket connection established.\") # 1. 发送 Start Connection 请求 await start_connection(ws) # 接收服务器响应 res_bytes = await ws.recv() # 解析响应 res = parser_response(res_bytes) # 打印响应信息 print_response(res, \'start_connection response:\') # 检查响应事件是否为连接成功 if res.optional.event != EVENT_ConnectionStarted: raise RuntimeError(f\"Start connection failed. Response: {res.optional.response_meta_json or res.payload_json or \'Unknown error\'}\") print(\"Connection started successfully.\") # 2. 发送 Start Session 请求 # 生成一个唯一的 Session ID session_id = uuid.uuid4().__str__().replace(\'-\', \'\') await start_session(ws, speaker, session_id) # 接收响应并解析 res = parser_response(await ws.recv()) print_response(res, \'start_session response:\') # 检查响应事件是否为会话开始成功 if res.optional.event != EVENT_SessionStarted: raise RuntimeError(f\"Start session failed! Response: {res.optional.response_meta_json or res.payload_json or \'Unknown error\'}\") print(f\"Session started successfully (Session ID: {session_id}).\") # 3. 发送文本 (Task Request) await send_text(ws, speaker, text, session_id) # 4. 发送 Finish Session 请求 (表明文本已发送完毕) await finish_session(ws, session_id) # 5. 循环接收音频数据并写入文件 print(f\"Receiving audio data and writing to {output_path}...\") # 使用 aiofiles 异步打开文件进行二进制写入 async with aiofiles.open(output_path, mode=\"wb\") as output_file: while True: # 接收服务器响应 res_bytes = await ws.recv() # 解析响应 res = parser_response(res_bytes) # 打印响应信息 (调试) # print_response(res, \'audio_receive loop:\') # 判断响应类型 if res.optional.event == EVENT_TTSResponse and res.header.message_type == AUDIO_ONLY_RESPONSE: # 如果是 TTS 音频响应,并且消息类型是仅音频 if res.payload: # 将接收到的音频数据块写入文件 await output_file.write(res.payload) # print(f\"Received and wrote {len(res.payload)} bytes of audio.\") # 调试信息 else: print(\"Warning: Received EVENT_TTSResponse with empty payload.\") elif res.optional.event in [EVENT_TTSSentenceStart, EVENT_TTSSentenceEnd]: # 如果是句子开始/结束事件,打印信息并继续接收 print(f\"Received event: {\'Sentence Start\' if res.optional.event == EVENT_TTSSentenceStart else \'Sentence End\'}. Info: {res.payload_json}\") continue elif res.optional.event == EVENT_SessionFinished: # 如果收到会话结束事件,表示音频流结束,退出循环 print(\"Received Session Finished event. Audio stream ended.\") print_response(res, \'session_finished response:\') break elif res.optional.event == EVENT_SessionFailed: # 如果收到会话失败事件,抛出异常 print_response(res, \'session_failed response:\') raise RuntimeError(f\"Session failed during audio receive. Info: {res.optional.response_meta_json or res.payload_json}\") elif header.message_type == ERROR_INFORMATION: # 如果收到错误信息 print_response(res, \'error_information response:\') error_desc = res.payload.decode(\'utf-8\') if res.payload else \'Unknown error\' raise RuntimeError(f\"Received error information. Code: {res.optional.errorCode}, Desc: {error_desc}\") else: # 收到其他未预期事件,打印并可能退出或忽略 print(f\"Warning: Received unexpected event or message type during audio receive.\") print_response(res, \'unexpected_response:\') # 根据需要决定是否退出 break # break # 暂时选择退出 print(f\"Audio saved to {output_path}\") # 6. 发送 Finish Connection 请求 await finish_connection(ws) # 接收最后的响应 res = parser_response(await ws.recv()) print_response(res, \'finish_connection response:\') # 理论上应该收到 EVENT_ConnectionFinished 或类似确认 print(\'===> Demo finished successfully.\')# --- 主程序入口 ---if __name__ == \"__main__\": # --- 用户配置 --- # 请替换为您的火山引擎应用 ID 和访问令牌 # 重要提示:请勿将您的 AppID 和 Token 硬编码在代码中并公开分享。 # 建议使用环境变量、配置文件或其他安全方式管理凭证。 appId = \"\" # 替换为您自己的 AppId token = \"\" # 替换为您自己的 Token # 检查 AppID 和 Token 是否已配置 if not appId or not token: print(\"错误:请在代码中设置您的 appId 和 token。\") print(\"请访问 https://console.volcengine.com/iam/keymanage/ 获取。\") exit(1) # 要合成的文本 text = \'火山引擎,让智能增长。欢迎使用火山引擎实时语音合成服务。\' text = (\'我是松下机器人SuperMAX ジョジョの力は無限大だ!\' ) # 使用的发音人标识 # 可选的发音人请参考文档: https://www.volcengine.com/docs/6561/1257544 speaker = \'zh_female_shuangkuaisisi_moon_bigtts\' # 示例发音人 # 输出音频文件的路径 (请确保目录存在或有写入权限) output_path = \'./tts_output.mp3\' # 将保存在当前目录下 print(\"Starting TTS demo...\") print(f\" App ID: {appId[:4]}...\") # 仅显示部分 AppID print(f\" Speaker: {speaker}\") print(f\" Text: {text}\") print(f\" Output Path: {output_path}\") try: # 使用 asyncio.run() 运行异步的 run_demo 函数 asyncio.run(run_demo(appId, token, speaker, text, output_path)) except RuntimeError as e: # 捕获并打印运行时错误 print(f\"\\nAn error occurred: {e}\") except websockets.exceptions.ConnectionClosedError as e: print(f\"\\nWebSocket connection closed unexpectedly: {e}\") except Exception as e: # 捕获并打印其他未预料的异常 import traceback print(f\"\\nAn unexpected error occurred: {e}\") traceback.print_exc() # 打印详细的堆栈跟踪信息

