Exploiting Intrinsic Multilateral Logical Rules for Weakly Supervised Natural Language Video Localiz

标题:利用内在多边逻辑规则进行弱监督自然语言视频定位
原文链接:https://aclanthology.org/2024.acl-long.247.pdf
发表:ACL main-2024
摘要
弱监督自然语言视频定位(WS-NLVL)旨在仅利用训练期间的视频-语言对,在视频中检索与语言查询对应的时刻。尽管已取得巨大成功,但现有的WS-NLVL方法很少考虑围绕语言查询的复杂时间关系(例如,语言查询与其分解的子查询或同义查询之间的关系),从而导致不合逻辑的预测。在本文中,我们提出了一种新颖的即插即用方法——内在多边逻辑规则(Intrinsic Multilateral Logical Rules,简称IMLR),以利用弱监督自然语言视频定位中的内在时间关系和逻辑规则。具体而言,我们将源自原始语言查询的查询形式化为有向图的节点,即内在时间关系图(ITRG),并将它们之间的时间关系作为边。我们没有直接提示预训练语言模型,而是引入了一种关系引导的提示方法,以分层方式生成ITRG。我们从ITRG中定制了四种多边时间逻辑规则(即同一性、包含性、同步性和连续性),并利用它们来训练我们的模型。实验证明了我们的方法在Charades-STA和ActivityNet Captions数据集上的有效性和优越性。
1 引言
自然语言视频定位(NLVL)(Gao等人,2017;Chen和Jiang,2019;Xu等人,2023b;Wang等人,2023;Zhang等人,2023)旨在在未修剪的视频中定位与语言查询在语义上对应的时间间隔(Zhang等人,2023;Xu等人,2023a;Lan等人,2023)。由于其在视频编辑和智能监控等各个领域的潜在应用,NLVL在过去几年中引起了越来越多的研究兴趣。
传统的NLVL模型在全监督下进行训练(Gao等人,2017),即利用准确的开始和结束时间戳进行训练。尽管取得了显著成功,但获取边界标注极其耗时且昂贵。为此,弱监督自然语言视频定位(WS-NLVL)(Mithun等人,2019)被引入,通过仅利用视频-语言对进行训练来降低标注成本。
图1:最先进的WS-NLVL方法(即CPL(Zheng等人,2022b)和CNM(Zheng等人,2022a))的不合逻辑预测示例。真实标签和预测结果分别用填充矩形和网格线表示。彩色查看效果更佳。
WS-NLVL的早期方法基于多实例学习(MIL)(Mithun等人,2019;Chen等人,2022),其中输入视频的每个片段被视为一个实例,输入视频被视为实例的集合。实例的预测被聚合以形成集合级别的预测。最近,基于重建的方法(Zheng等人,2022a,b;Huang等人,2023;Cao等人,2023;Lv等人,2023;Yoon等人,2023)被提出,通过结合重建损失进行联合学习来解决该任务,假设与语言查询对应的提议应能最好地重建该查询。
尽管取得了巨大成功,但现有的WS-NLVL方法直接将视频特征与词级或句子级语言特征融合,很少考虑围绕语言查询的复杂时间关系,从而导致不合逻辑的预测。如图1中的第一个示例所示,给定一个未修剪的视频和语言查询“Person sits in a chair”,其定位结果应该与其同义查询“Person sits down on a chair”的定位结果相同,并且应被其子查询“Person”的定位结果包含。然而,如图1中的网格线所示,最先进的WS-NLVL方法CPL(Zheng等人,2022b)的预测结果远非逻辑所能解释。图1还展示了另一个语言查询的示例:“A long curly haired woman inspecting the blow dryer then drying her hair looking irritated and bored”。其子查询(即“A long curly haired woman inspecting the blow dryer”和“A long curly haired woman drying her hair looking irritated and bored”)的时间间隔在时间上应该是连续的,并且合并后应与原始语言查询的时间间隔一致。不幸的是,现有方法未能捕捉到这种复杂的时间关系。
为了解决上述问题,我们提出了一种新颖的框架,称为IMLR,以利用弱监督自然语言视频定位中的内在时间关系和逻辑规则。具体而言,我们首先提议通过生成其内在时间关系图(ITRG)来理解复杂的语言查询。在该图中,原始语言查询及其衍生查询被形式化为节点,而它们之间的时间关系被表示为边。我们系统地考虑了WS-NLVL的所有可能时间关系,并定制了四种具有相应多边时间逻辑规则(MTLRs)的关系,即同一性、包含性、同步性和连续性。由于通过手动设计规则或直接提示(Brown等人,2020)预训练语言模型(LM)来生成ITRG具有挑战性,因此我们引入了一种关系引导的提示方法,以分层方式生成ITRG。最后,来自该图的MTLRs被用于训练我们的边界感知Transformer模型。我们进行了实验,将我们的方法与两种最新的WS-NLVL方法(即CNM(Zheng等人,2022a)和CPL(Zheng等人,2022b))相结合,在Charades-STA和ActivityNet Captions数据集上验证了我们方法的有效性和优越性。
我们的贡献总结如下:
- 我们提议利用内在时间关系,并为WS-NLVL定制多边逻辑规则。
- 我们提出了一种新颖的框架,首先通过关系引导的提示生成ITRG,然后利用来自ITRG的MTLRs来监督我们模型的训练。
- 我们在Charades-STA和ActivityNet Captions数据集上验证了我们方法的有效性和优越性。
2 相关工作
2.1 全监督自然语言视频定位
全监督自然语言视频定位(FS-NLVL)方法利用准确的时间边界标注进行训练,可分为两类:(1)基于提议的方法(Gao等人,2017;Chen和Jiang,2019)和(2)无提议的方法(Yuan等人,2019;Chen等人,2020a;Mun等人,2020;Chen等人,2020b;Xu等人,2022;Jang等人,2023;Li等人,2023;Zhang等人,2020a;Wang等人,2023)。具体而言,基于提议的方法首先为给定视频生成一组候选提议,然后选择最相关的一个。由于基于提议的方法需要将所有提议与语言查询进行比较,因此其计算成本极高。因此,无提议的方法被提出,将NLVL视为回归问题,直接预测时间间隔。
尽管取得了显著成功,但为FS-NLVL获取时间边界标注既耗时又昂贵。
2.2 弱监督自然语言视频定位
弱监督自然语言视频定位(WS-NLVL)(Mithun等人,2019;Ma等人,2020;Huang等人,2021;Lin等人,2020;Wu等人,2020)被提出,以降低FS-NLVL的时间边界标注成本。TGA(Mithun等人,2019)提出了文本引导的注意力,以突出与语言查询相关的视频片段,并获得单个文本相关的视频特征。通过最小化文本相关视频特征与语言特征之间的距离来训练网络。VLANet(Ma等人,2020)提出了一种视频-语言对齐网络,以修剪不相关的提议,并考虑各种注意力流来学习多模态对齐。CPL(Zheng等人,2022b)提出了对比提议学习,使用多个高斯函数从同一视频生成正提议和负提议。Huang等人(Huang等人,2023)提出了第一种基于自训练的WS-NLVL方法,包括一对相互学习的教师和学生网络,分别采用弱增强和强增强。
图2:我们方法的整体框架。给定一个未修剪的视频和一个语言查询,我们首先通过关系引导的提示生成内在时间关系图(ITRG)。然后,使用两个编码器和一个边界感知Transformer来预测时刻的关键点和边界偏移。模型参数通过具有多边时间逻辑规则(MTLRs)的时间关系损失 L T R L_{TR} LTR、对比损失 L C O N L_{CON} LCON和重建损失 L R E L_{RE} LRE联合优化。
尽管取得了很大进展,但现有的WS-NLVL方法很少考虑围绕语言查询的复杂时间关系,从而导致不合逻辑的预测。在本文中,我们提出了一种新颖的即插即用方法来解决该问题。
2.3 视频中的时间关系建模
有几项工作利用时间关系进行视频理解。TRN(Zhou等人,2018)提议在多个时间尺度上学习和推理视频帧之间的时间依赖关系,用于动作识别。TRM(Zheng等人,2023)使用短语级预测来优化FS-NLVL的句子级预测,其中利用准确的边界标注来挖掘短语和句子之间的时间关系。CRM(Huang等人,2021)探索了段落中不同句子的时间顺序,用于WS-NLVL,这是与我们方法最相关的工作。然而,它需要额外的时间顺序标注进行训练,并且仅适用于段落中具有多个相邻句子的情况。相比之下,我们关注单个句子内的内在时间关系,并系统地考虑四种多边时间关系。
2.4 基于提示的学习
基于提示的学习(Liu等人,2023;Brown等人,2020;Wei等人,2022;Li和Liang,2021;Yao等人,2023)是自然语言处理中兴起的一种新范式,旨在通过直接提示预训练模型而不是微调单独的模型检查点来执行预测任务。Brown等人(Brown等人,2020)表明,扩大语言模型的规模可以极大地提高与任务无关的少样本性能,而无需任何梯度更新或微调。思维链提示(Wei等人,2022)通过一系列中间推理步骤提高了语言模型执行复杂推理的能力。在本文中,我们引入了关系引导的提示来为WS-NLVL生成ITRG,该图建模了语言查询的复杂内在时间关系。
3 方法
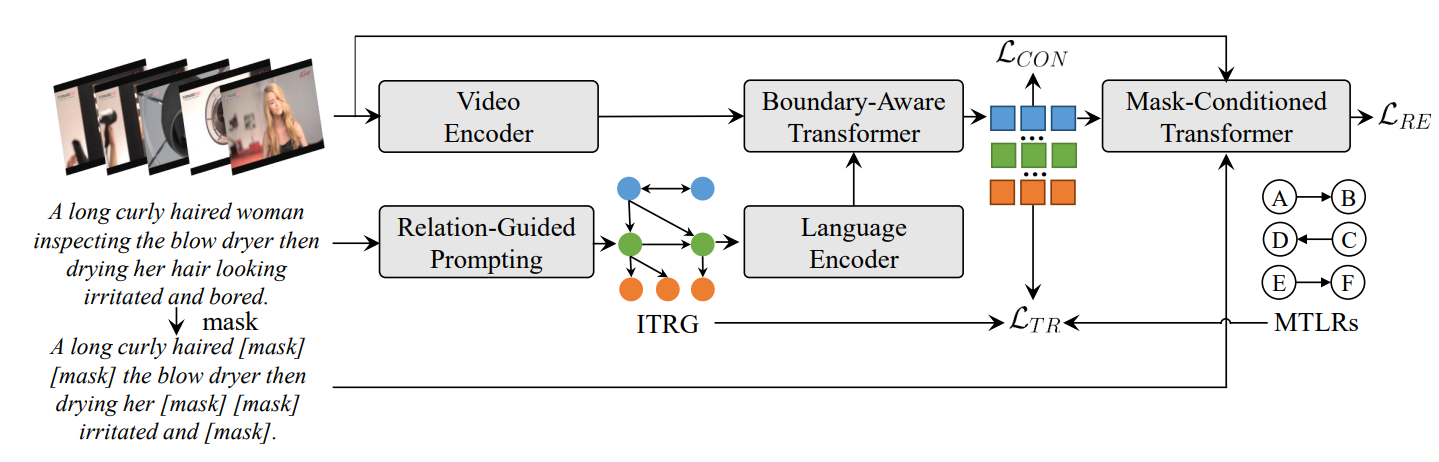
图2:我们方法的整体框架。给定一个未修剪的视频和一个语言查询,我们首先通过关系引导的提示生成内在时间关系图(ITRG)。然后,使用两个编码器和一个边界感知Transformer来预测该时刻的关键点和边界偏移。模型参数通过具有多边时间逻辑规则(MTLRs)的时间关系损失 L T R L_{TR} LTR、对比损失 L C O N L_{CON} LCON以及重建损失 L R E L_{RE} LRE进行联合优化。
给定一个未修剪的视频 V V V和一个自然语言查询 Q Q Q,NLVL旨在学习一个模型 f f f,该模型可以预测视频中与语言查询对应的时间间隔 I=( t s , t e ) I=(t^s, t^e) I=(ts,te),即 f:(V,Q)→I f:(V, Q) \\to I f:(V,Q)→I,其中 t s t^s ts和 t e t^e te分别表示开始时间和结束时间。与利用准确时间边界 { V m , Q m , I m } m = 1 M \\{V^m, Q^m, I^m\\}_{m=1}^M {Vm,Qm,Im}m=1M进行训练的FS-NLVL不同,WS-NLVL仅可使用视频-语言对 { V m , Q m } m = 1 M \\{V^m, Q^m\\}_{m=1}^M {Vm,Qm}m=1M。这里 M M M表示训练集中的样本数量。
图2显示了我们用于WS-NLVL的方法的整体框架,包括关系引导的提示、视频编码器、语言编码器、边界感知Transformer和掩码条件Transformer。给定一个语言查询,我们首先提出关系引导的提示来生成其内在时间关系图(ITRG)。然后,视频编码器、语言编码器和边界感知Transformer用于预测目标时刻的关键点和边界偏移。我们为时间关系损失 L T R L_{TR} LTR形式化了多边时间逻辑规则(MTLRs),该损失与对比损失 L C O N L_{CON} LCON和重建损失 L R E L_{RE} LRE一起用于训练我们的模型。下面,我们详细阐述我们方法的主要组件:(1)MTLRs的定义,(2)用于ITRG生成的关系引导提示,(3)具有MTLRs的WS-NLVL,以及(4)训练和推理。
3.1 MTLRs的定义
形式上,给定一个复杂的语言查询,其ITRG是一个有向图 G G G。每个节点 Q i ∈G Q_i \\in G Qi∈G表示一个查询,该查询要么是原始查询,要么是从原始查询衍生的查询(例如,其同义查询或从中分解的子查询),查询之间的边表示时间关系。
图3展示了两个ITRG示例,其中我们使用广度优先搜索(BFS)顺序枚举 G G G的节点, Q 0 Q_0 Q0是给定的语言查询。对于语言查询 Q 0 Q_0 Q0“A group of young people play field hockey on a field while a man watches from a fence bordering the playing field”,我们可以得到其同义查询 Q 1 Q_1 Q1“A bunch of teenagers engage in a game of field hockey on a grassy area while a man observes from a fence that runs alongside the playing field”。此外, Q 0 Q_0 Q0可以分解为两个在时间上重叠的子查询,即 Q 2 Q_2 Q2“A group of young people play field hockey on a field”和 Q 3 Q_3 Q3“A man watches from a fence bordering the playing field”。此外, Q 4 Q_4 Q4“A group of young people”、 Q 5 Q_5 Q5“A field”、 Q 6 Q_6 Q6“A man”和 Q 7 Q_7 Q7“A fence bordering the playing field”可以分别从 Q 2 Q_2 Q2和 Q 3 Q_3 Q3中提取。在给定语言查询 Q 0 Q_0 Q0“A girl wipes her face down with a towel and then puts lotion all over her face”的第二个示例中,我们可以类似地生成其ITRG,不同之处在于其子查询 Q 2 Q_2 Q2“A girl wipes her face down with a towel”和 Q 3 Q_3 Q3“A girl puts lotion all over her face”在时间上是连续发生的。
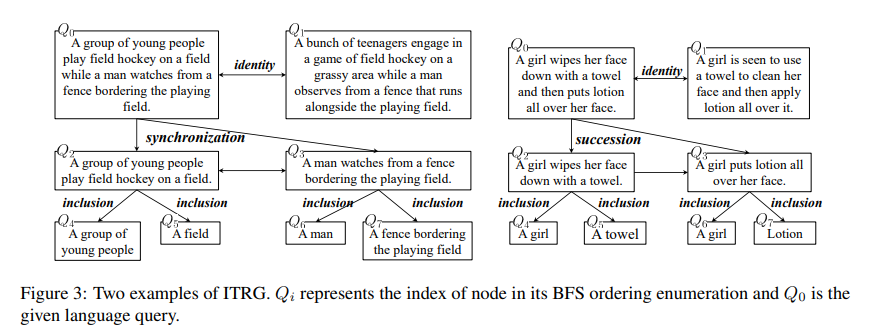
图3:ITRG的两个示例。 Q i Q_i Qi表示其BFS顺序枚举中的节点索引, Q 0 Q_0 Q0是给定的语言查询。
我们系统地考虑了WS-NLVL的所有可能内在时间关系,并定制了不同语言查询之间的四种具有多边时间逻辑规则(MTLRs)的关系,即同一性、包含性、同步性和连续性。
定义1(同一性)给定一个未修剪的视频 V V V、一个语言查询 Q Q Q及其同义查询 Q i d Q_{id} Qid, Q Q Q和 Q i d Q_{id} Qid的定位结果应该彼此相同:
f ( V , Q ) = f ( V , Q i d ) , ( 1 ) f(V, Q)=f\\left(V, Q_{id}\\right), \\quad(1) f(V,Q)=f(V,Qid),(1)
其中 f f f表示定位模型。
定义2(包含性)给定一个未修剪的视频 V V V、一个语言查询 Q Q Q以及从 Q Q Q中提取的名词短语查询 Q n p Q_{np} Qnp, Q Q Q的定位结果应被 Q n p Q_{np} Qnp的定位结果包含:
f ( V , Q ) ⊆ f ( V , Q n p ) . ( 2 ) f(V, Q) \\subseteq f\\left(V, Q_{np}\\right) . (2) f(V,Q)⊆f(V,Qnp).(2)
定义3(同步性)给定一个未修剪的视频 V V V、一个语言查询 Q Q Q以及从 Q Q Q中分解的、描述在时间上重叠事件的子查询 Q s y 1 ,⋯ , Q s y N Q_{sy_1}, \\cdots, Q_{sy_N} Qsy1,⋯,QsyN, Q, Q s y 1 ,⋯ , Q s y N Q, Q_{sy_1}, \\cdots, Q_{sy_N} Q,Qsy1,⋯,QsyN的定位结果应满足:
f ( V , Q ) = ⋂ n = 1 N f ( V , Q s y n ) . f(V, Q)=\\bigcap_{n=1}^{N} f\\left(V, Q_{sy_n}\\right) . f(V,Q)=n=1⋂Nf(V,Qsyn).
定义4(连续性)给定一个未修剪的视频 V V V、一个语言查询 Q Q Q以及从 Q Q Q中分解的、描述连续发生事件的子查询 Q s u 1 ,⋯ , Q s u N Q_{su_1}, \\cdots, Q_{su_N} Qsu1,⋯,QsuN, Q, Q s u 1 ,⋯ , Q s u N Q, Q_{su_1}, \\cdots, Q_{su_N} Q,Qsu1,⋯,QsuN的定位结果应满足:
f ( V , Q ) = ⋃ n = 1 N f ( V , Q s u n ) , ( 4 ) f(V, Q)=\\bigcup_{n=1}^{N} f\\left(V, Q_{su_n}\\right), \\quad (4) f(V,Q)=n=1⋃Nf(V,Qsun),(4)
3.2 用于ITRG生成的关系引导提示
由于NLVL中语言查询的复杂性,通过手动设计规则生成ITRG具有挑战性。一种简单的解决方案是利用预训练语言模型(LM)的强大语言理解能力进行提示。然而,使用少量输入-输出对直接提示LM无法准确捕捉围绕查询的复杂时间关系。
为此,我们提出了一种关系引导的提示方法,以分层方式生成ITRG。图4显示了我们方法的流程。具体而言,我们引入了三种提示模板,即分解提示、同一性提示和包含性提示。分解提示用于确定给定的语言查询是否可以分解为不同的子查询,并在适用时列出子查询及其关系。同一性提示输出给定语言查询的同义查询。包含性提示提取查询的名词短语。不同提示的结果被整合以生成ITRG。
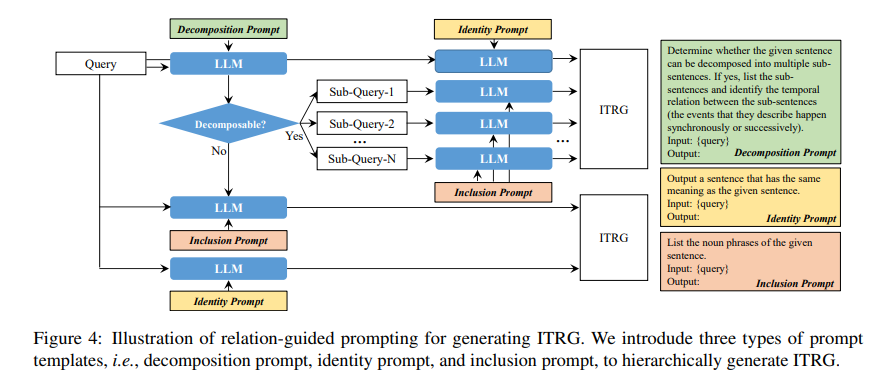
图4:用于生成ITRG的关系引导提示的说明。我们引入了三种提示模板,即分解提示、同一性提示和包含性提示,以分层方式生成ITRG。
3.3 具有MTLRs的弱监督自然语言视频定位
编码器
给定一个未修剪的视频、一个语言查询及其内在时间关系图 G G G,我们首先使用预训练模型提取视频和查询特征。具体来说,视频特征 V={ v 1 , v 2 ,⋯ , v L V }∈ R L V × D V V=\\{v_1, v_2, \\cdots, v_{L_V}\\} \\in \\mathbb{R}^{L_V \\times D_V} V={v1,v2,⋯,vLV}∈RLV×DV是通过预训练的3D卷积网络(Carreira和Zisserman,2017;Tran等人,2015)编码得到的,其中 L V L_V LV表示每个视频的片段数量, D V D_V DV是视频片段特征的维度。查询特征 { Q i ={ w i , 1 , w i , 2 ,⋯ , w i , L Q }∈ R L Q × D Q } i = 0G − 1 \\{Q_i=\\{w_{i,1}, w_{i,2}, \\cdots, w_{i,L_Q}\\} \\in \\mathbb{R}^{L_Q \\times D_Q}\\}_{i=0}^{G-1} {Qi={wi,1,wi,2,⋯,wi,LQ}∈RLQ×DQ}i=0G−1是通过预训练的Glove(Pennington等人,2014)模型获得的,其中 L Q L_Q LQ、 D Q D_Q DQ和 G G G分别表示每个句子的单词数量、查询特征的维度和 G G G中的节点数量。
然后,视频和查询特征被嵌入到一个共同的潜在空间中:
V ← W V V , Q i ← W QQ i , ( 5 ) V \\leftarrow W_V V, Q_i \\leftarrow W_Q Q_i, (5) V←WVV,Qi←WQQi,(5)
其中 W V ∈ R D H × D V W_V \\in \\mathbb{R}^{D_H \\times D_V} WV∈RDH×DV和 W Q ∈ R D H × D Q W_Q \\in \\mathbb{R}^{D_H \\times D_Q} WQ∈RDH×DQ是可学习矩阵, D H D_H DH是潜在空间的维度。
边界感知Transformer
我们引入了一个边界感知Transformer来执行多模态交互,并预测时刻的关键点和边界偏移。具体来说,在视频特征的末尾添加一个可学习的[CLASS]标记 v c l s v_{cls} vcls,即 V ^ ={ v 1 , v 2 ,⋯ , v L V , v c l s }∈ R ( L V + 1 ) × D H \\hat{V}=\\{v_1, v_2, \\cdots, v_{L_V}, v_{cls}\\} \\in \\mathbb{R}^{(L_V+1) \\times D_H} V^={v1,v2,⋯,vLV,vcls}∈R(LV+1)×DH。我们通过一个双Transformer融合查询特征 { Q i ∈ R L Q × D H } i = 0G − 1 \\{Q_i \\in \\mathbb{R}^{L_Q \\times D_H}\\}_{i=0}^{G-1} {Qi∈RLQ×DH}i=0G−1和 V ^ \\hat{V} V^,以获得隐藏特征 { H i ={ h 1 , i , h 2 , i ,⋯ , h L V , i , h c l s , i }∈ R ( L V + 1 ) × D H } i = 0G − 1 \\{H_i=\\{h_{1,i}, h_{2,i}, \\cdots, h_{L_V,i}, h_{cls,i}\\} \\in \\mathbb{R}^{(L_V+1) \\times D_H}\\}_{i=0}^{G-1} {Hi={h1,i,h2,i,⋯,hLV,i,hcls,i}∈R(LV+1)×DH}i=0G−1:
H i = D ( V ^ , E ( Q i ) ) , ( 6 ) H_i=D\\left(\\hat{V}, E\\left(Q_i\\right)\\right), \\quad(6) Hi=D(V^,E(Qi)),(6)
其中 E E E和 D D D分别表示Transformer编码器和解码器。
与直接预测时刻的中心和宽度的现有方法不同,我们提议使用预测头 P P P来预测关键点和边界偏移:
k i , s ~ i , e ~ i = P ( h c l s , i ) , ( 7 ) k_i, \\tilde{s}_i, \\tilde{e}_i=P\\left(h_{cls,i}\\right), \\quad(7) ki,s~i,e~i=P(hcls,i),(7)
其中 k i k_i ki、 s ~ i \\tilde{s}_i s~i和 e ~ i \\tilde{e}_i e~i分别表示归一化的关键点坐标、开始偏移和结束偏移。这从架构角度建模了时刻的内在时间关系。因此,开始和结束时间戳为 s i = k i − s ~ i s_i=k_i-\\tilde{s}_i si=ki−s~i和 e i = k i + e ~ i e_i=k_i+\\tilde{e}_i ei=ki+e~i。目标时刻的中心和宽度可以重新表示为 c i = k i +( e ~ i − s ~ i )/2 c_i=k_i+(\\tilde{e}_i-\\tilde{s}_i)/2 ci=ki+(e~i−s~i)/2和 w i = s ~ i + e ~ i w_i=\\tilde{s}_i+\\tilde{e}_i wi=s~i+e~i。
在获得不同语言查询的预测结果后,我们应用3.1节中的MTLRs来指导模型训练。形式上,同一性损失 L I D L_{ID} LID强制给定语言查询 Q 0 Q_0 Q0与其同义查询 Q i d Q_{id} Qid的预测时间间隔相同:
L I D= ∥ s 0 − s i d ∥ F 2 + ∥ e 0 − e i d ∥ F 2 , ( 8 ) \\mathcal{L}_{ID}=\\left\\| s_0-s_{id}\\right\\| _{F}^{2}+\\left\\| e_0-e_{id}\\right\\| _{F}^{2}, \\quad(8) LID=∥s0−sid∥F2+∥e0−eid∥F2,(8)
其中 s 0 s_0 s0、 e 0 e_0 e0和 s i d s_{id} sid、 e i d e_{id} eid分别表示 Q 0 Q_0 Q0和 Q i d Q_{id} Qid的预测结果。 ∥⋅ ∥ F \\|\\cdot\\|_F ∥⋅∥F表示弗罗贝尼乌斯范数。
包含性损失 L I N L_{IN} LIN鼓励 Q i Q_i Qi的预测结果被从中提取的名词短语 Q n p Q_{np} Qnp的预测结果包含,其可以表示为:
L I N =E ∀ ( Q i, Q n p ) ∈ G [ m a x ( s n p − s i + γ , 0 ) + m a x ( e i − e n p + γ , 0 ) ] , \\begin{aligned} \\mathcal{L}_{IN}= & \\underset{\\forall\\left(Q_i, Q_{np}\\right) \\in \\mathcal{G}}{\\mathbb{E}}\\left[max \\left(s_{np}-s_i+\\gamma, 0\\right)\\right. \\\\ & \\left.+max \\left(e_i-e_{np}+\\gamma, 0\\right)\\right], \\end{aligned} LIN=∀(Qi,Qnp)∈GE[max(snp−si+γ,0)+max(ei−enp+γ,0)],
其中 γ \\gamma γ是超参数。
同步性损失 L S Y L_{SY} LSY用于强制 Q 0 Q_0 Q0的预测结果与其分解的、在时间上重叠的 Q s y 1 ,⋯ , Q s y N Q_{sy_1}, \\cdots, Q_{sy_N} Qsy1,⋯,QsyN的预测结果的交集一致:
L S Y =E ∀ ( Q 0, Q s y 1 , ⋯ , N ) ∈ G [ ∥ s 0 − m a x ( s s y 1 , ⋯ , N ) ∥ F 2 + ∥ e 0 − m i n ( e s y 1 , ⋯ , N ) ∥ F 2 ] . \\begin{aligned} \\mathcal{L}_{SY}= & \\underset{\\forall\\left(Q_0, Q_{sy_{1,\\cdots,N}}\\right) \\in \\mathcal{G}}{\\mathbb{E}}\\left[\\left\\| s_0-max \\left(s_{sy_{1,\\cdots,N}}\\right)\\right\\| _{F}^{2}\\right. \\\\ & \\left.+\\left\\| e_0-min \\left(e_{sy_{1,\\cdots,N}}\\right)\\right\\| _{F}^{2}\\right] . \\end{aligned} LSY=∀(Q0,Qsy1,⋯,N)∈GE[ s0−max(ssy1,⋯,N) F2+ e0−min(esy1,⋯,N) F2].
此外,连续性损失 L S U L_{SU} LSU用于建模 Q 0 Q_0 Q0与其分解的、连续发生的 Q s u 1 ,⋯ , Q s u N Q_{su_1}, \\cdots, Q_{su_N} Qsu1,⋯,QsuN之间的时间关系:
L S U = E ∀ ( Q 0, Q s u 1 , ⋯ , N ) ∈ G [ ∥ s 0 − m i n ( s s u 1 , ⋯ , N ) ∥ F 2 + ∥ e 0 − m a x ( e s u 1 , ⋯ , N ) ∥ F 2 + ∥ e s u n − s s u n + 1 ∥ F 2 ] \\begin{aligned} & \\mathcal{L}_{SU}=\\underset{\\forall\\left(Q_0, Q_{su_{1,\\cdots,N}}\\right) \\in \\mathcal{G}}{\\mathbb{E}}\\left[\\left\\| s_0-min \\left(s_{su_{1,\\cdots,N}}\\right)\\right\\| _{F}^{2}\\right. \\\\ & \\left.+\\left\\| e_0-max \\left(e_{su_{1,\\cdots,N}}\\right)\\right\\| _{F}^{2}+\\left\\| e_{su_n}-s_{su_{n+1}}\\right\\| _{F}^{2}\\right] \\end{aligned} LSU=∀(Q0,Qsu1,⋯,N)∈GE[ s0−min(ssu1,⋯,N) F2+ e0−max(esu1,⋯,N) F2+∥esun−ssun+1∥F2]
整体时间关系损失 L T R L_{TR} LTR总结为:
L T R= λ 1L I D+ λ 2L I N+ λ 3L S Y+ λ 4L S U, ( 12 ) \\mathcal{L}_{TR}=\\lambda_1 \\mathcal{L}_{ID}+\\lambda_2 \\mathcal{L}_{IN}+\\lambda_3 \\mathcal{L}_{SY}+\\lambda_4 \\mathcal{L}_{SU},(12) LTR=λ1LID+λ2LIN+λ3LSY+λ4LSU,(12)
其中 λ 1 \\lambda_1 λ1、 λ 2 \\lambda_2 λ2、 λ 3 \\lambda_3 λ3和 λ 4 \\lambda_4 λ4是权重系数。
3.4 训练和推理
我们的方法基于两种最新的WS-NLVL模型构建,即CNM(Zheng等人,2022a)和CPL(Zheng等人,2022b),它们的源代码是公开可用的。除了时间关系损失 L T R L_{TR} LTR,还使用对比损失 L C O N L_{CON} LCON和重建损失 L R E L_{RE} LRE进行训练。具体来说, L C O N L_{CON} LCON用于对比正提议和负提议,而 L R E L_{RE} LRE用于衡量使用正提议重建的查询与原始查询之间的差异。在推理时,我们遵循基础模型相同的流程。
4 实验
4.1 数据集
遵循先前工作(Mithun等人,2019;Ma等人,2020;Zheng等人,2022a,b),我们在两个公开数据集上评估所提出的方法:ActivityNet Captions(Krishna等人,2017)和Charades-STA(Gao等人,2017)。
- ActivityNet Captions:该数据集包含37,417、17,505和17,031个视频-语言对,分别用于训练、验证和测试。语言查询的平均长度和视频的平均持续时间分别为13.48个词和117.6秒。由于测试集不公开,我们使用验证集进行评估。
- Charades-STA:该数据集基于Charades数据集构建,用于自然语言视频定位任务。它包含12,408和3,720个视频-语言对,分别用于训练和测试。语言查询的平均长度和视频的平均持续时间分别为8.6个词和29.8秒。
4.2 评估指标
我们遵循先前工作(Zheng等人,2022a;Huang等人,2023),使用IoU@n和mIoU来衡量WS-NLVL的性能:
- IoU@n指的是测试样本中排名第一的预测结果与真实标签(GT)的交并比(IoU)高于n的百分比。在实验中,对于ActivityNet Captions数据集,我们报告n={0.1,0.3,0.5}的结果;对于Charades-STA数据集,我们报告n={0.3,0.5,0.7}的结果。
- mIoU表示所有测试样本的平均IoU。
4.3 实现细节
在数据预处理方面,我们遵循先前工作(Zheng等人,2022b;Huang等人,2023;Yoon等人,2023),分别使用预训练的C3D(Tran等人,2015)和I3D(Carreira和Zisserman,2017)模型为ActivityNet Captions和Charades-STA数据集提取视频特征。采用Glove(Pennington等人,2014)提取语言查询的词特征。我们将最大描述长度设置为20,每个视频的最大片段数量设置为200。ActivityNet Captions和Charades-STA数据集的词汇表大小分别为8,000和1,111。此外,我们提示公开可用的语言模型Phi-2来生成ITRG。
我们的方法使用PyTorch(Paszke等人,2019)实现,并通过ADAM(Kingma和Ba,2014)优化器进行优化,学习率为0.0004。式(9)中的γ以及式(12)中的λ₁、λ₂、λ₃和λ₄通过网格搜索确定,分别设置为0.15、20、20、10和10。对于基础模型,我们使用其官方实现中的超参数。
4.4 与最先进方法的比较
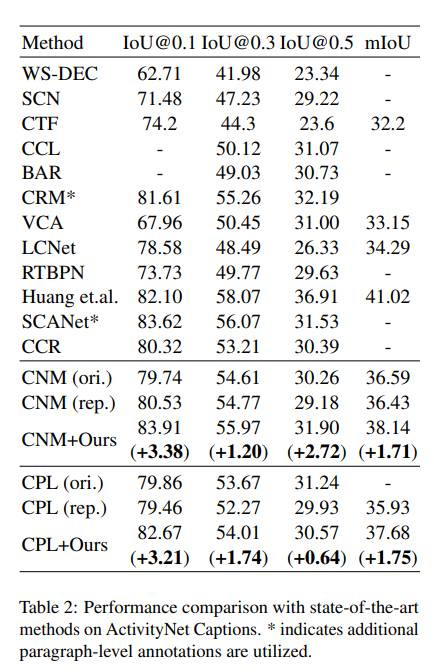
我们将我们的方法与以下最先进的方法进行比较:TGA(Mithun等人,2019)、WSDEC(Duan等人,2018)、SCN(Lin等人,2020)、CTF(Chen等人,2020c)、BAR(Wu等人,2020)、VLANet(Ma等人,2020)、RTBPN(Zhang等人,2020b)、LoGAN(Tan等人,2021)、CRM(Huang等人,2021)、VCA(Wang等人,2021)、LCNet(Yang等人,2021)、CNM(Zheng等人,2022a)、CPL(Zheng等人,2022b)、Huang等人(Huang等人,2023)、SCANet(Yoon等人,2023)和CCR(Lv等人,2023)。值得注意的是,将CRM和SCANet与其他方法直接比较是不公平的,因为它们需要额外的段落级标注进行训练。
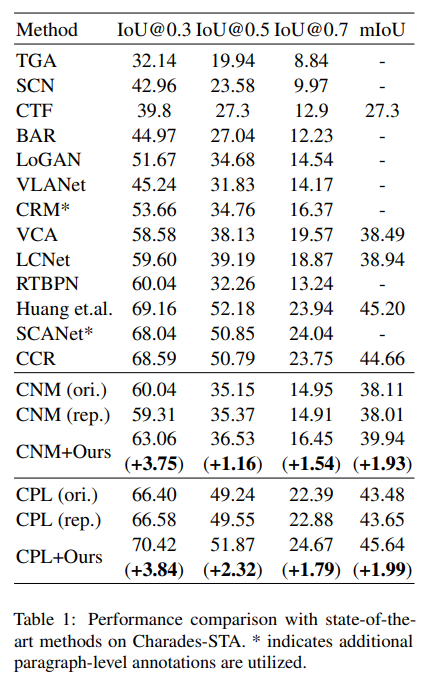
表1和表2分别展示了在Charades-STA和ActivityNet Captions数据集上的结果。我们将我们的方法与两种最新的WS-NLVL方法(即CNM和CPL)相结合,这些方法公开了它们的源代码。CNM(ori.)和CPL(ori.)表示其原始论文中报告的结果,而CNM(rep.)和CPL(rep.)表示我们重现的结果。如表所示,我们的方法可以显著提高基础模型的性能,甚至优于那些在训练中使用额外标注的方法。
表2:ActivityNet Captions数据集上与最先进方法的性能比较。*表示使用了额外的段落级标注。
4.5 消融研究
方法各组件的有效性
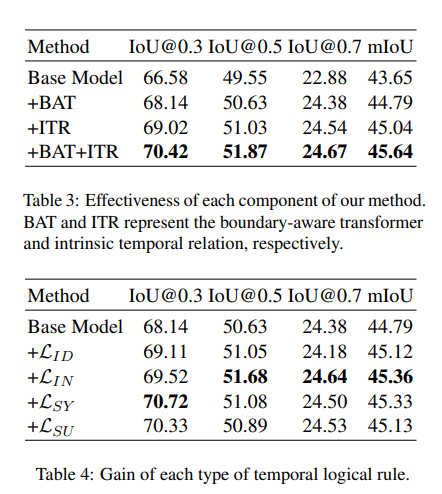
我们进行消融研究以探究方法中每个组件的有效性。比较了我们模型的四种变体:(1)基础模型,(2)+BAT,(3)+ITR,(4)+BAT+ITR。具体而言,基础模型利用对比损失L_CON和重建损失L_RE直接预测目标时刻的中心和宽度。+BAT表示带有边界感知Transformer的方法,该Transformer预测关键点和边界偏移。+ITR表示通过内在时间关系建模训练的方法,即额外的时间关系损失L_TR。+BAT+ITR是我们的完整模型,同时包含边界感知Transformer和内在时间关系建模。
表3展示了不同模型在Charades-STA数据集上的结果。同时添加BAT和ITR可以在很大程度上改进基础模型,例如,在IoU@0.3指标上分别提高1.56%和2.44%。当同时使用这两个组件时,获得了最佳性能,验证了我们方法各组件的有效性。
每种时间逻辑规则的增益
我们定制了四种多边时间逻辑规则(即同一性、包含性、同步性和连续性)。在本实验中,我们探究了它们的影响,并在表4中展示了在Charades-STA数据集上的结果。每种关系类型都能显著提高基础模型的性能,验证了它们的有效性。
表4:每种时间逻辑规则的增益。
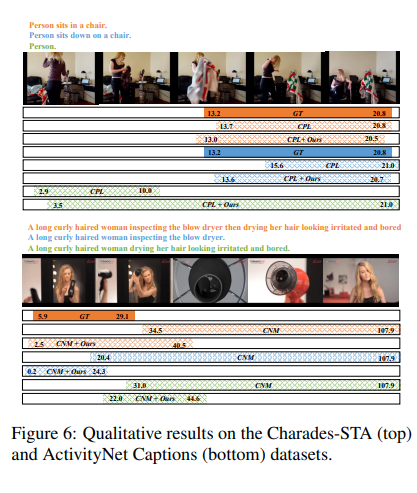
4.6 关系引导提示的有效性
我们提出了关系引导提示以分层方式生成ITRG。为了验证其有效性,在本实验中,我们将我们的方法与传统的少样本提示(Brown等人,2020)进行比较,传统方法使用少量输入-输出对直接提示语言模型(在我们的实验中使用20个提示)。图5展示了一个示例。给定语言查询“A girl wraps the rope around her saddle while others practice on placed saddles.”,传统提示无法将其分解为同步子查询,而我们的方法能够成功捕捉复杂的内在时间关系。
图5:我们的关系引导提示与传统少样本提示的比较。
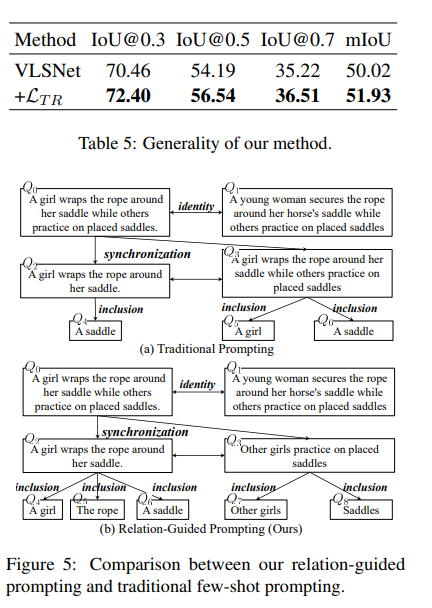
4.7 方法的通用性
我们关注WS-NLVL任务,因为它仅需要视频-语言对进行训练,因此更适合实际场景。为了探究我们方法的通用性,我们将其与全监督方法VSLNet(Zhang等人,2020a)相结合。表5展示了在Charades-STA数据集上的结果,验证了我们方法的通用性。
4.8 定性结果
我们在图6中展示了一些定性结果。我们的方法可以提高CPL和CNM模型的性能。此外,与基础模型相比,我们的方法产生的预测更具逻辑性,证明了边界感知Transformer和内在时间关系建模的有效性。
图6:Charades-STA(上)和ActivityNet Captions(下)数据集上的定性结果 。
5 结论与讨论
在本文中,我们提出利用内在时间关系和多边逻辑规则来解决弱监督自然语言视频定位问题。源自给定查询的语言查询被形式化为有向图的节点,它们之间的时间关系被形式化为边。我们引入关系引导的提示方法,通过利用预训练语言模型来分层生成该图。定制了四种多边时间逻辑规则(即同一性、同步性、连续性和包含性),以指导我们模型的训练。在Charades-STA和ActivityNet Captions数据集上的大量实验证明了我们方法的有效性和优越性。
局限性:由于训练期间仅可使用视频-语言对,我们方法的性能仍落后于一些使用准确标注进行训练的最先进全监督方法。

