【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(1)——Chat Client API
Spring AI框架快速入门
- Spring AI 系列文章:
- 一、前言
- 二、前期准备
-
- 2.1 运行环境
- 2.2 maven配置
- 2.3 api-key申请
- 三、Chat Client API
-
- 3.1 导入pom依赖
- 3.2 配置application.properties文件
- 3.3 创建 ChatClient
-
- 3.3.1 使用自动配置的 ChatClient.Builder
- 3.3.2 使用多个聊天模型
- 3.4 ChatClient请求
- 3.5 ChatClient 响应
-
- 3.5.1 返回 ChatResponse
- 3.5.2 返回实体
- 3.5.3 流式响应
- 3.6 提示模板
- 3.6 call() 返回值
- 3.7 stream() 返回值
- 3.8 使用默认值
-
- 3.8.1 默认系统文本
- 3.8.2 带参数的默认系统文本
- 3.8.3 其他默认值
- 3.9 Advisors
-
- 3.9.1 ChatClient 中的 Advisor 配置
- 3.9.2 日志记录
Spring AI 系列文章:
【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(1)——Chat Client API
【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(2)——Prompt(提示词)
【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(3)——Structured Output Converter(结构化输出转换器)
【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(4)——Chat Memory(聊天记录)
【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(5)——Tool Calling(工具调用)
一、前言
前言:Spring AI经历了八个版本的迭代(M1~M8)之后,Spring AI 1.0.0 正式版本,终于在 2025 年 5 月 20 日正式发布,这是另一个新高度的里程碑式的版本,标志着 Spring 生态系统正式全面拥抱人工智能技术,并且意味着 Spring AI 将会给企业带来稳定 API 支持。
Spring AI 项目旨在简化包含人工智能功能的应用程序的开发,避免不必要的复杂性。
该项目的灵感来源于著名的 Python 项目,如 LangChain 和 LlamaIndex,但 Spring AI 并非这些项目的直接移植。 该项目坚信,下一波生成式人工智能应用程序将不仅仅面向 Python 开发人员,而是将普及到多种编程语言中。
注意:Spring AI 解决了人工智能集成的基本挑战:将企业数据和 API 与人工智能模型连接起来。
Spring AI 提供了作为开发人工智能应用程序基础的抽象。 这些抽象有多种实现,从而能够以最少的代码更改轻松替换组件。
Spring AI 提供以下功能:
-
跨 AI 提供商的聊天、文本到图像和嵌入模型的便携式 API 支持。支持同步和流式 API 选项。也提供对模型特定功能的访问。
-
支持所有主要的
AI 模型提供商,例如 Anthropic、OpenAI、Microsoft、Amazon、Google 和 Ollama。支持的模型类型包括:-
聊天补全 -
嵌入 -
文本到图像 -
音频转录 -
文本到语音 -
内容审核
-
-
结构化输出- 将 AI 模型输出映射到 POJO。 -
支持所有主要的
向量数据库提供商,例如 Apache Cassandra、Azure Cosmos DB、Azure Vector Search、Chroma、Elasticsearch、GemFire、MariaDB、Milvus、MongoDB Atlas、Neo4j、OpenSearch、Oracle、PostgreSQL/PGVector、PineCone、Qdrant、Redis、SAP Hana、Typesense 和 Weaviate。 -
跨向量存储提供商的便携式 API,包括新颖的类 SQL 元数据过滤 API。
-
工具/函数调用- 允许模型请求执行客户端工具和函数,从而根据需要访问必要的实时信息并采取行动。 -
可观察性- 提供对 AI 相关操作的洞察。 -
用于数据工程的文档提取
ETL 框架。 -
AI 模型评估- 帮助评估生成内容并防止幻觉响应的实用程序。 -
AI 模型和向量存储的 Spring Boot 自动配置和启动器。
-
ChatClient API- 用于与 AI 聊天模型通信的流畅 API,在习惯用法上类似于 WebClient 和 RestClient API。 -
Advisors API- 封装了重复出现的生成式 AI 模式,转换进出语言模型 (LLM) 的数据,并提供跨各种模型和用例的可移植性。 -
支持
聊天对话记忆和检索增强生成 (RAG)。
基于以上Spring AI特性,我将分多篇博客详细讲解Spring AI的用法,有帮助麻烦点赞、收藏、评论,给我点小小鼓励!!!点关注就最好了
Spring AI 1.0.0源码:GitHub
本文代码:GitHub
二、前期准备
2.1 运行环境
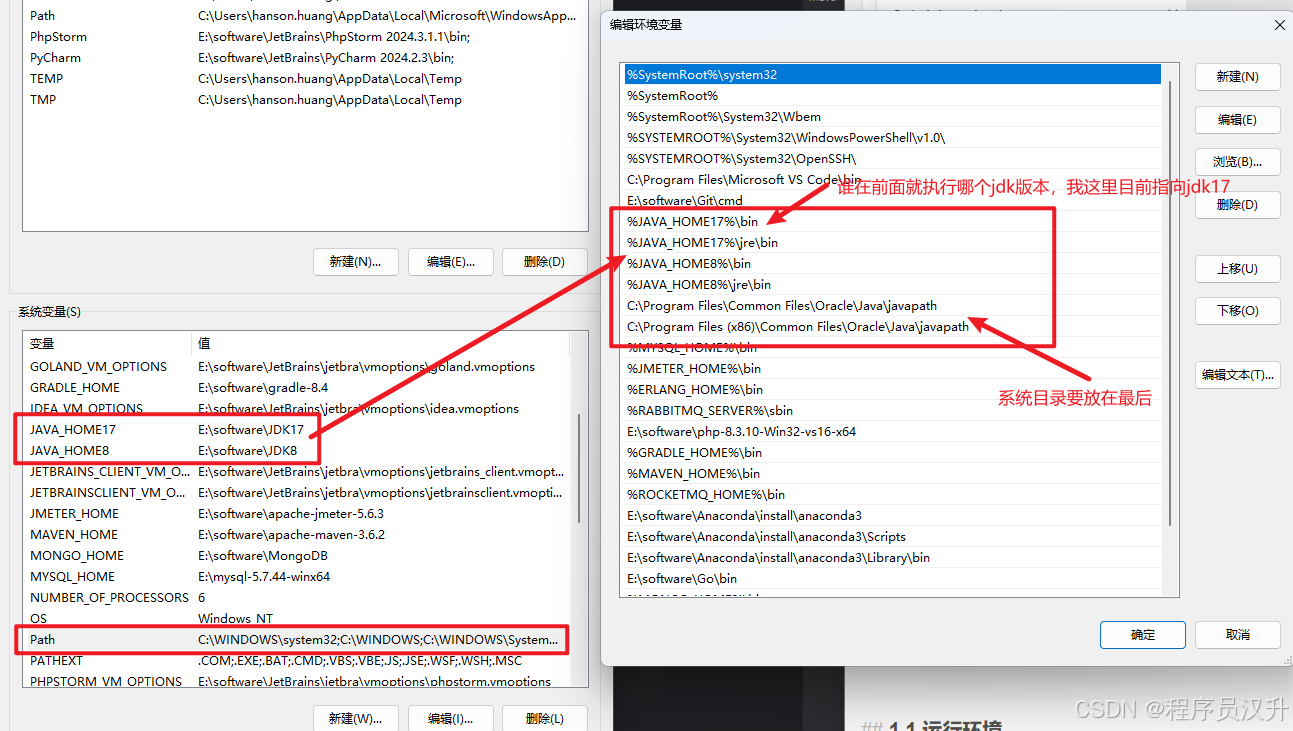
Spring AI基于Sping Boot 3.x版本及以上,本文选取3.4.5(Spring AI 1.0.0源码为3.4.5),需要JDK 17以上,JDK 8需要升级,也可以配置双jdk环境,具体配置如下图,谁排在Path环境中的前面谁的优先级高

2.2 maven配置
maven的setting.xml文件中需要添加快照仓库
<profile> <id>spring-snapshots</id> <repositories> <repository> <id>spring-snapshots</id> <url>https://repo.spring.io/snapshot</url> <snapshots> <enabled>true</enabled> </snapshots> <releases> <enabled>false</enabled> </releases> </repository> </repositories> </profile> </profiles> <activeProfiles> <activeProfile>spring-snapshots</activeProfile> </activeProfiles>2.3 api-key申请
Spring AI提供多种类型的模型,包括聊天模型、嵌入模型、图像模型、音频模型、内容审核模型等。提供了多家 AI 提供商的便携式 Model API,例如:Claude、OpenAI、DeepSeek、ZhiPu等等
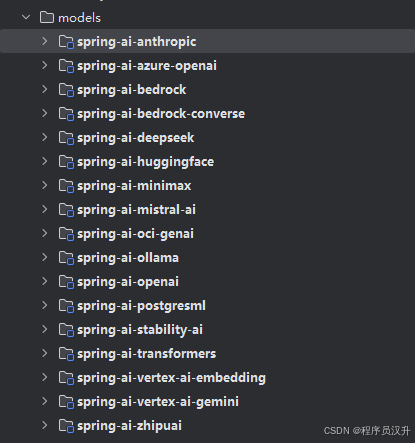
例如聊天模型,又会有许多的实现
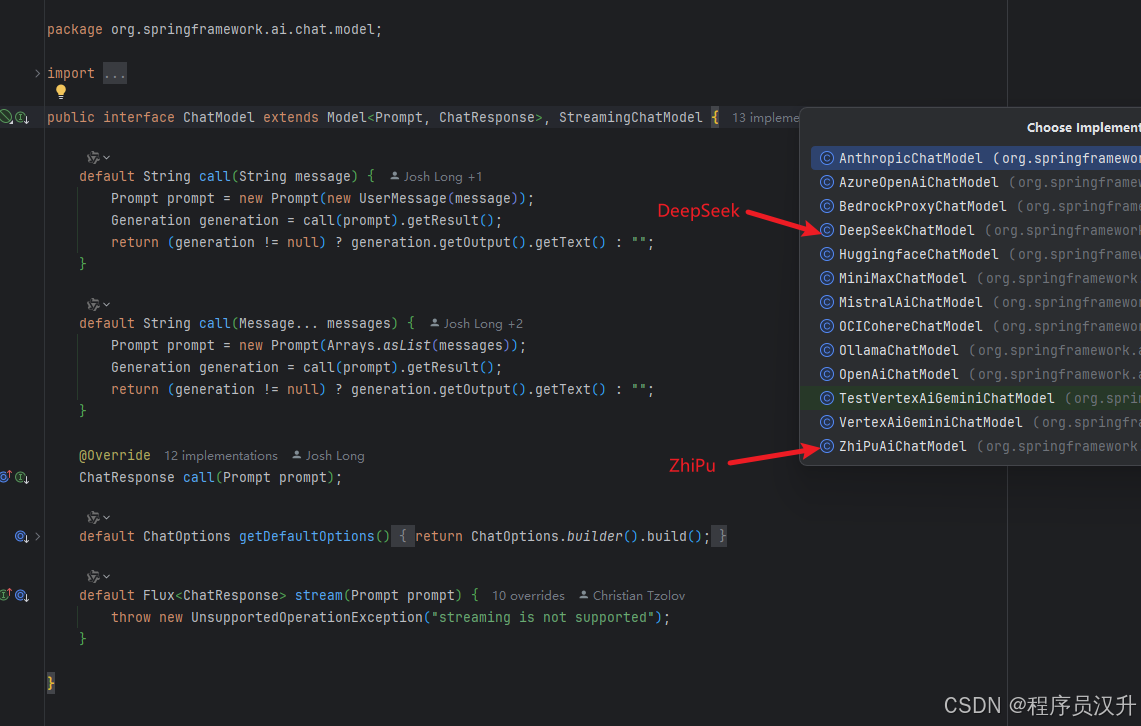
聊天模型对比
此表格比较了 Spring AI 支持的各种聊天模型,详细说明了它们的功能:
-
多模态: 模型可以处理的输入类型(例如,文本、图像、音频、视频)。
-
工具/函数调用: 模型是否支持函数调用或工具使用。
-
流式响应: 模型是否提供流式响应。
-
重试: 是否支持重试机制。
-
可观测性: 用于监控和调试的功能。
-
内置 JSON: 原生支持 JSON 输出。
-
本地部署: 模型是否可以在本地运行。
-
OpenAI API 兼容性: 模型是否兼容 OpenAI 的 API。
本文采用DeepSeek用于聊天模型,ZhiPu用户文生图模型,其他模型同理
DeepSeek api-key获取:https://platform.deepseek.com/api_keys,DeepSeek创建完需要充值
新用户可以使用ZhiPu,能白嫖!!!
ZhiPu api-key获取:https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
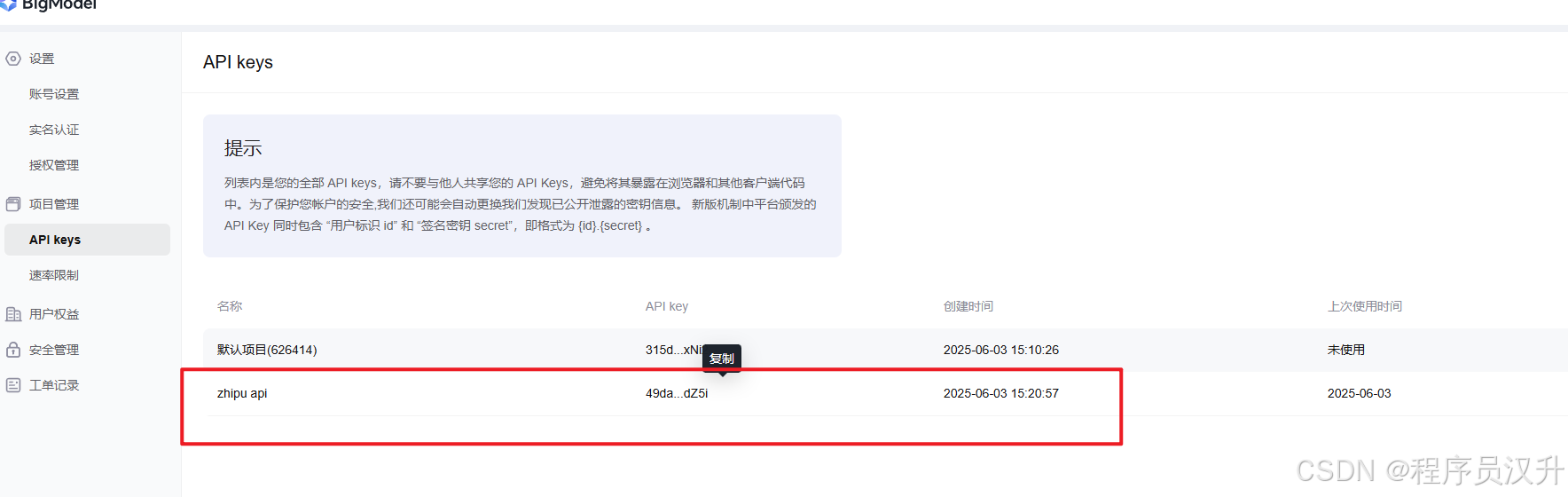
三、Chat Client API
ChatClient 提供了一个流畅的 API 用于与 AI 模型进行通信。 它同时支持同步和流式编程模型。
3.1 导入pom依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-deepseek</artifactId> </dependency><!-- --><!-- org.springframework.ai--><!-- spring-ai-starter-model-zhipuai--><!-- --></dependencies><repositories> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </repository> <repository> <name>Central Portal Snapshots</name> <id>central-portal-snapshots</id> <url>https://central.sonatype.com/repository/maven-snapshots/</url> <releases> <enabled>false</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository></repositories><dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>${spring-boot.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.0.0-SNAPSHOT</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies></dependencyManagement>3.2 配置application.properties文件
spring: ai: deepseek: # API 密钥 api-key: <your-deepseek-api-key> # 可选:DeepSeek API 基础地址,默认是 https://api.deepseek.com # base-url: https://api.deepseek.com chat: options: # DeepSeek 使用的聊天模型,可选 deepseek-chat 或 deepseek-reasoner # deepseek-chat为聊天模型,deepseek-reasoner为推理模型,推理模型会生成推理过程,比较消耗token model: deepseek-chat # 模型的温度值,控制生成文本的随机性(0.0 = 最确定,1.0 = 最随机) temperature: 0.83.3 创建 ChatClient
ChatClient 是使用 ChatClient.Builder 对象创建的。 可以为任何 ChatModel Spring Boot 自动配置获取一个自动配置的 ChatClient.Builder 实例,或者以编程方式创建一个。由于依赖中导入了DeepSeek,会默认采用DeepSeek模型。
3.3.1 使用自动配置的 ChatClient.Builder
Spring AI 提供了 Spring Boot 自动配置,创建一个原型 ChatClient.Builder bean,可以将其注入到的类中。 以下是一个简单的示例,展示如何获取对简单用户请求的 String 响应:
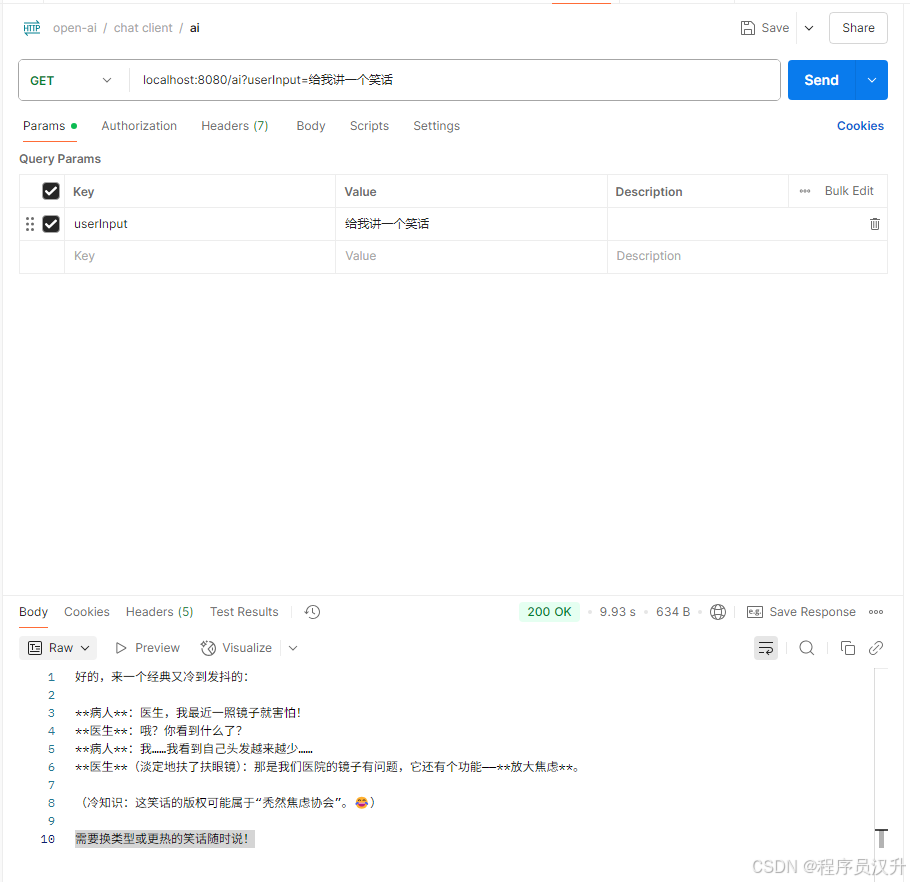
@RestControllerpublic class ChatClientController { private final ChatClient chatClient; public ChatClientController(ChatClient.Builder chatClientBuilder) { this.chatClient = chatClientBuilder.build(); } @GetMapping(\"/ai\") String generation(@RequestParam(\"userInput\") String userInput) { return this.chatClient.prompt() .user(userInput) .call() .content(); }}在这个简单的示例中,用户输入设置了用户消息的内容。 call() 方法向 AI 模型发送请求,content() 方法返回 AI 模型的响应作为 String。
3.3.2 使用多个聊天模型
在单个应用程序中使用多个聊天模型有几种场景:
-
为不同类型的任务使用不同的模型(例如,
使用强大的模型进行复杂推理,使用更快、更便宜的模型处理简单任务) -
当一个模型服务不可用时实现回退机制
-
对不同的模型或配置进行 A/B 测试 -
根据用户偏好提供模型选择 -
组合专业模型(一个用于代码生成,另一个用于创意内容等)
默认情况下,Spring AI 自动配置单个 ChatClient.Builder bean。但是,可能需要在应用程序中使用多个聊天模型。以下是处理这种情况的方法:
在所有情况下,都需要通过设置属性 spring.ai.chat.client.enabled=false 来禁用 ChatClient.Builder 自动配置。
这允许手动创建多个 ChatClient 实例。
引入ZhiPu model依赖和配置
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-zhipuai</artifactId></dependency>spring: ai: # 禁用默认的 Chat Client chat: client: enabled: false zhipuai: # ZhiPu AI 的 API 密钥 api-key: 49dadd9c9d504acbb60580f6d53cf30b.vlX0Fp67MTwxdZ5i # ZhiPu AI 的接口基础地址 base-url: https://open.bigmodel.cn/api/paas # ZhiPu AI 的聊天模型配置 chat: options: # 可选模型如 glm-4-air、glm-4、glm-3-turbo 等 model: glm-4-air # 文生图模型(如需启用,取消注释并设置模型名称,如 cogview-3) # image: # options: # model: cogview-3 # 嵌入模型(如需启用,取消注释并设置模型名称,如 embedding-2) # embedding: # options: # model: embedding-2当使用多个 AI 模型时,可以为每个模型定义单独的 ChatClient bean:
@Configurationpublic class ChatClientConfig { /** * 创建并配置一个ChatClient实例 * 该方法通过注入的DeepSeekChatModel对象初始化一个ChatClient * 主要作用是将聊天模型与客户端进行绑定,以便进行后续的聊天操作 * * @param chatModel 聊天模型,包含了聊天所需的配置和参数 * @return 返回配置好的ChatClient实例 */ @Bean public ChatClient deepSeekChatClient(DeepSeekChatModel chatModel) { return ChatClient.create(chatModel); } /** * 创建ChatClient实例的Bean定义 * 该方法将ZhiPuAiChatModel转换为ChatClient实例,供Spring框架管理 * * @param chatModel 聊天模型,包含了与聊天客户端相关的信息和配置 * @return ChatClient实例,用于与AI聊天服务进行交互 */ @Bean public ChatClient zhiPuAiChatClient(ZhiPuAiChatModel chatModel) { return ChatClient.create(chatModel); }}然后,可以使用 @Qualifier 注解将这些 bean 注入到应用程序组件中:
@Configurationpublic class ChatClientExample { @Bean CommandLineRunner cli( @Qualifier(\"deepSeekChatClient\") ChatClient deepSeekChatClient, @Qualifier(\"zhiPuAiChatClient\") ChatClient zhiPuAiChatClient) { return args -> { var scanner = new Scanner(System.in); ChatClient chat; // 模型选择 System.out.println(\"\\n选择您的 AI 模型:\"); System.out.println(\"1. DeepSeek\"); System.out.println(\"2. ZhiPuAi\"); System.out.print(\"输入您的选择(1 或 2):\"); String choice = scanner.nextLine().trim(); if (choice.equals(\"1\")) { chat = deepSeekChatClient; System.out.println(\"使用 OpenAI 模型\"); } else { chat = zhiPuAiChatClient; System.out.println(\"使用 Anthropic 模型\"); } // 使用选定的聊天客户端 System.out.print(\"\\n输入您的问题:\"); String input = scanner.nextLine(); String response = chat.prompt(input).call().content(); System.out.println(\"助手:\" + response); scanner.close(); }; }}DeepSeek执行结果:
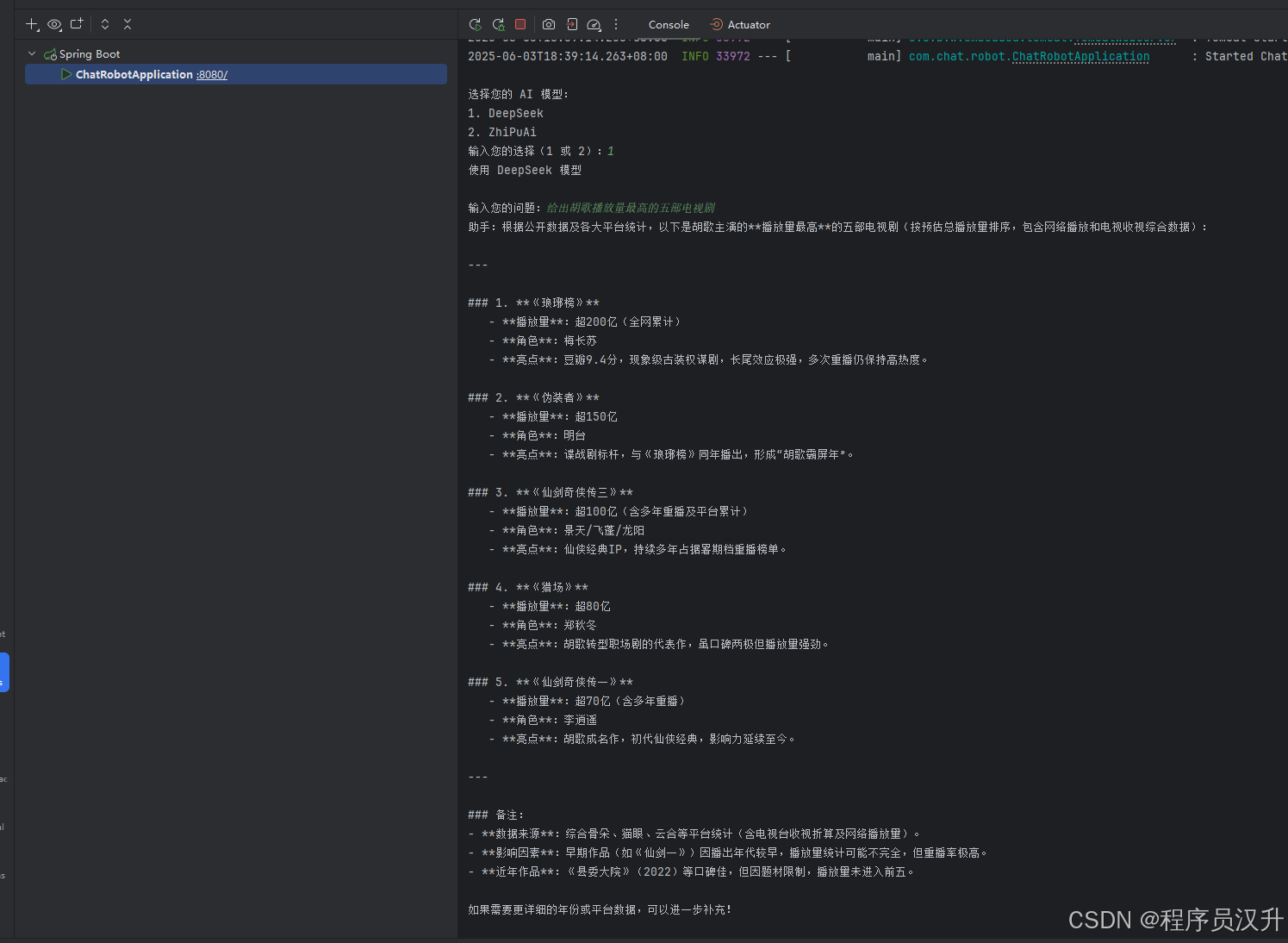
ZhiPu Ai执行结果:

3.4 ChatClient请求
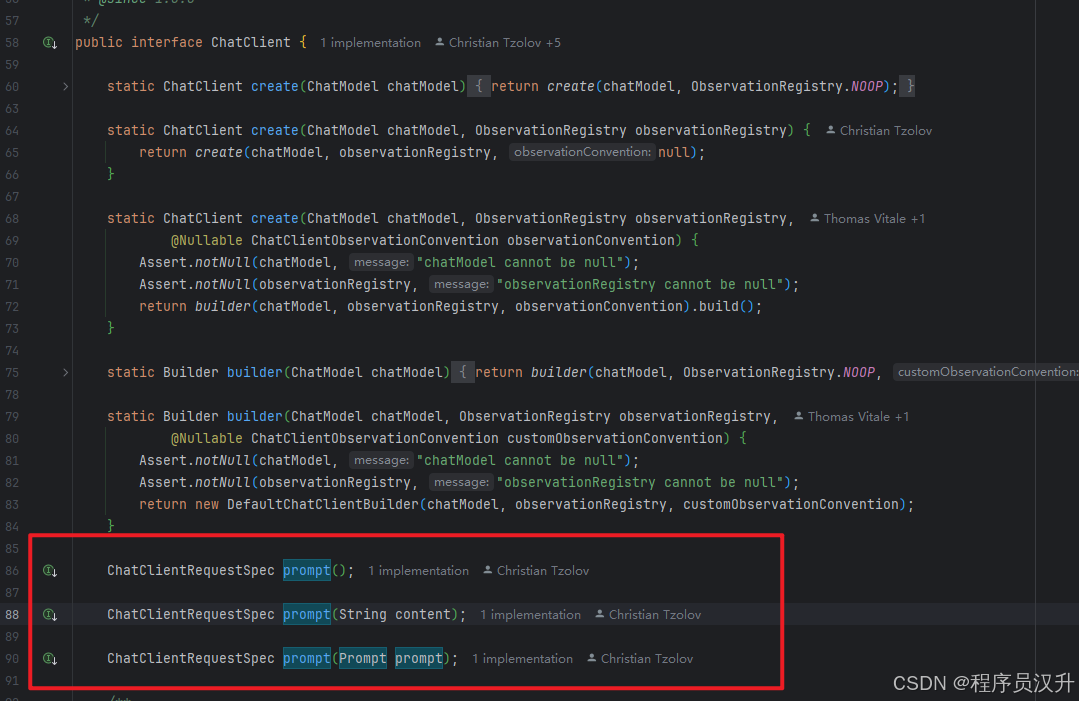
ChatClient 请求允许使用重载的 prompt 方法以三种不同的方式创建提示:
-
prompt():无参数方法。 -
prompt(Prompt prompt):这个方法接受一个Prompt参数,让传入使用Prompt创建Prompt实例。 -
prompt(String content):这是一个类似于前一个重载的便捷方法。它接受用户的文本内容。
关于提示词的内容,我们下一篇博客,详细讲解
3.5 ChatClient 响应
ChatClient API 提供了几种使用 AI 模型响应的方法。
3.5.1 返回 ChatResponse
AI 模型的响应是一个由 ChatResponse 类型定义的丰富结构。 它包括有关如何生成响应的元数据,还可以包含多个响应,称为 Generations,每个都有自己的元数据。 元数据包括用于创建响应的令牌数量(每个令牌大约是一个单词的 3/4)。 这些信息很重要,因为托管 AI 模型根据每个请求使用的令牌数量收费。
以下示例通过调用 call() 方法后的 chatResponse() 返回包含元数据的 ChatResponse 对象:
@RestControllerpublic class ChatClientResponseController { private final ChatClient deepSeekChatClient; @Autowired public ChatClientResponseController(@Qualifier(\"deepSeekChatClient\") ChatClient deepSeekChatClient) { this.deepSeekChatClient = deepSeekChatClient; } @GetMapping(\"/ai/chat-client-response\") ChatResponse generation() { return deepSeekChatClient.prompt() .user(\"给我讲个笑话\") .call() .chatResponse(); }}执行结果:
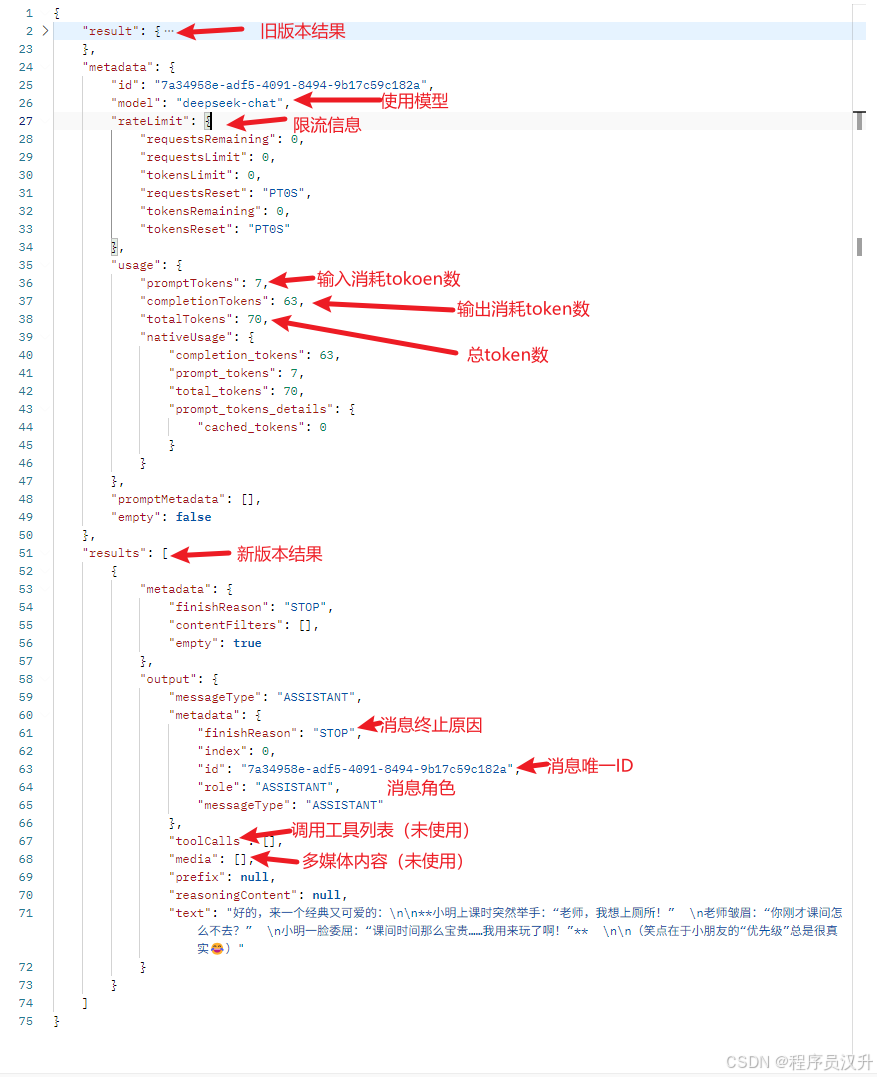
Token统计详情:
- 输入:“讲个笑话” -> 7 tokens
- 输出:笑话内容 -> 63 tokens
- 计费依据:总tokens = 7 + 63 -> 70
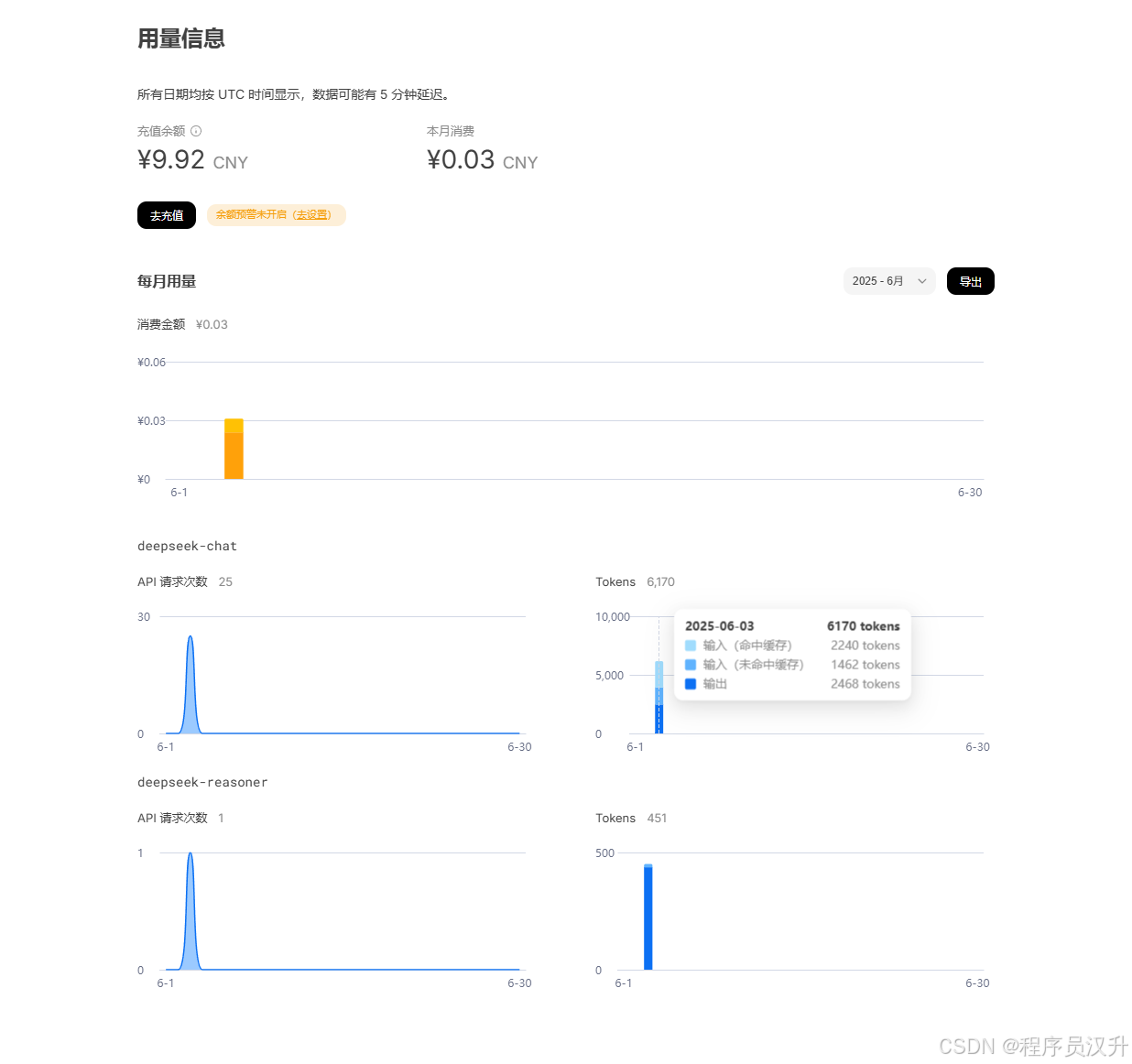
关键字段说明:
finishReason:- STOP:正常结束
- LENGTH:达到token限制
- CONTENT_FILTER:内容被过滤
- TOOL_CALLS:该模型为工具
- TOOL_CALL:仅用于与 Mistral AI API 兼容
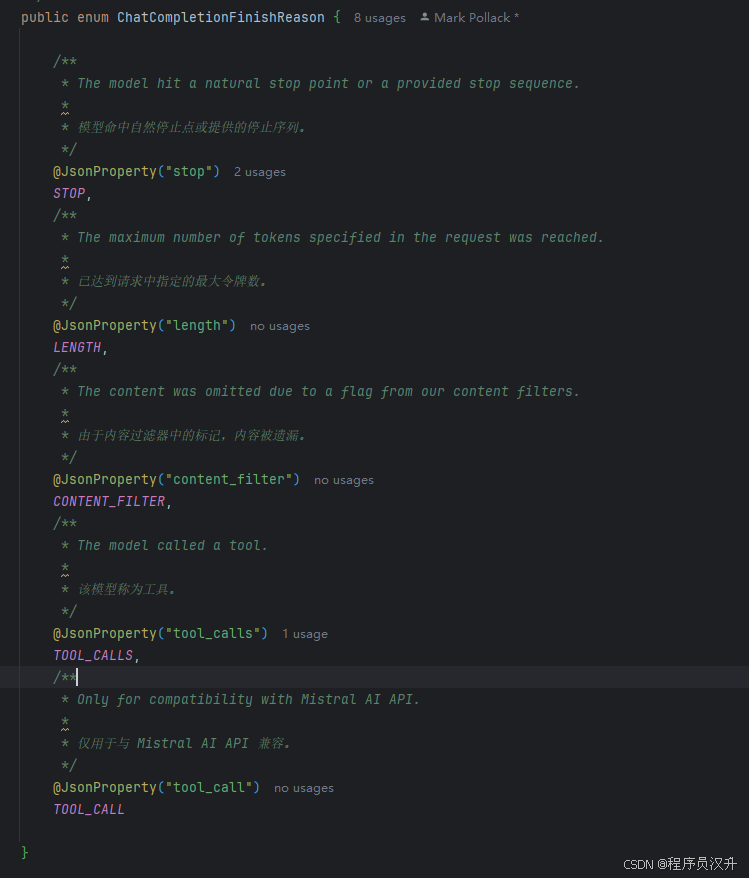
- role:标志消息来源
- SYSTEM
- USER
- ASSISTANT
- TOOL
3.5.2 返回实体
通常希望返回一个从返回的 String 映射的实体类。 entity() 方法提供了这个功能。
首先我们定义一个ActorFilms实体类:
public class ActorsFilms { private String actor; private List<String> movies; public ActorsFilms() { } public String getActor() { return this.actor; } public void setActor(String actor) { this.actor = actor; } public List<String> getMovies() { return this.movies; } public void setMovies(List<String> movies) { this.movies = movies; } @Override public String toString() { return \"ActorsFilms{\" + \"actor=\'\" + this.actor + \'\\\'\' + \", movies=\" + this.movies + \'}\'; }}我们可以使用 entity() 方法轻松地将 AI 模型的输出String字符串映射到这个 ActorsFilms实体,如下所示:
@GetMapping(\"/ai/chat-client-response-entity\")ActorsFilms generation_entity() { return deepSeekChatClient.prompt() .user(\"生成一个随机演员的电影作品。\") .call() .entity(ActorsFilms.class);}运行结果:
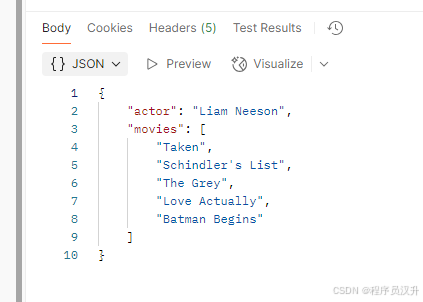
还有一个重载的 entity 方法,参数为 entity(ParameterizedTypeReference type),允许指定泛型列表等类型:
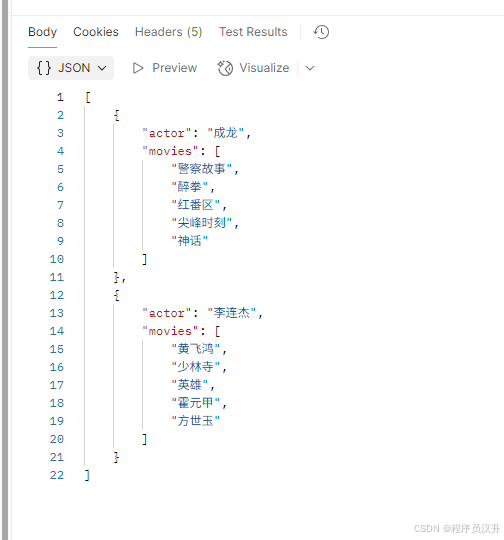
@GetMapping(\"/ai/chat-client-response-entity/list\")List<ActorsFilms> generation_entity_list() { return deepSeekChatClient.prompt() .user(\"生成成龙和李连杰的 5 部电影作品。\") .call() .entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});}运行结果:
3.5.3 流式响应
stream() 方法让可以获得异步响应,如下所示:
@GetMapping(\"/ai/flux\")Flux<String> gen_flux() { return deepSeekChatClient.prompt() .user(\"给我讲个笑话\") .stream() .content();}运行结果:

还可以使用方法 Flux chatResponse() 流式传输 ChatResponse。道理同上
还可以通过结构化输出转换器显示的转换响应,其中结构化输出转换器在后面的文章中会详细讲解
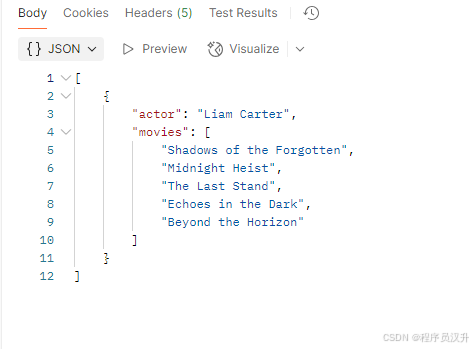
@GetMapping(\"/ai/struct/flux\")List<ActorsFilms> gen_struct_flux() { var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<List<ActorsFilms>>() { }); Flux<String> flux = deepSeekChatClient.prompt() .user(u -> u.text(\"\"\" 生成一个随机演员的电影作品。 {format} \"\"\") .param(\"format\", converter.getFormat())) .stream() .content(); String content = flux.collectList().block().stream().collect(Collectors.joining()); List<ActorsFilms> actorFilms = converter.convert(content); return actorFilms;}运行结果:
3.6 提示模板
ChatClient API 允许提供带有变量的用户和系统文本作为模板,这些变量在运行时被替换。
String answer = ChatClient.create(chatModel).prompt() .user(u -> u .text(\"告诉我 5 部由 {composer} 主演的电影\") .param(\"actor\", \"成龙\")) .call() .content();在内部,ChatClient 使用 PromptTemplate 类来处理用户和系统文本,并使用给定的 TemplateRenderer 实现替换变量。 默认情况下,Spring AI 使用 StTemplateRenderer 实现,它基于 Terence Parr 开发的开源 StringTemplate 引擎。
如果想使用不同的模板引擎,可以直接向 ChatClient 提供 TemplateRenderer 接口的自定义实现。也可以继续使用默认的 StTemplateRenderer,但使用自定义配置。
例如,默认情况下,模板变量由 {} 语法标识。如果计划在提示中包含 JSON,可能想使用不同的语法以避免与 JSON 语法冲突。例如,可以使用 < 和 > 分隔符。
String answer = ChatClient.create(chatModel).prompt() .user(u -> u .text(\"告诉我 5 部由 主演的电影\") .param(\"actor\", \"成龙\")) .templateRenderer(StTemplateRenderer.builder().startDelimiterToken(\'<\').endDelimiterToken(\'>\').build()) .call() .content();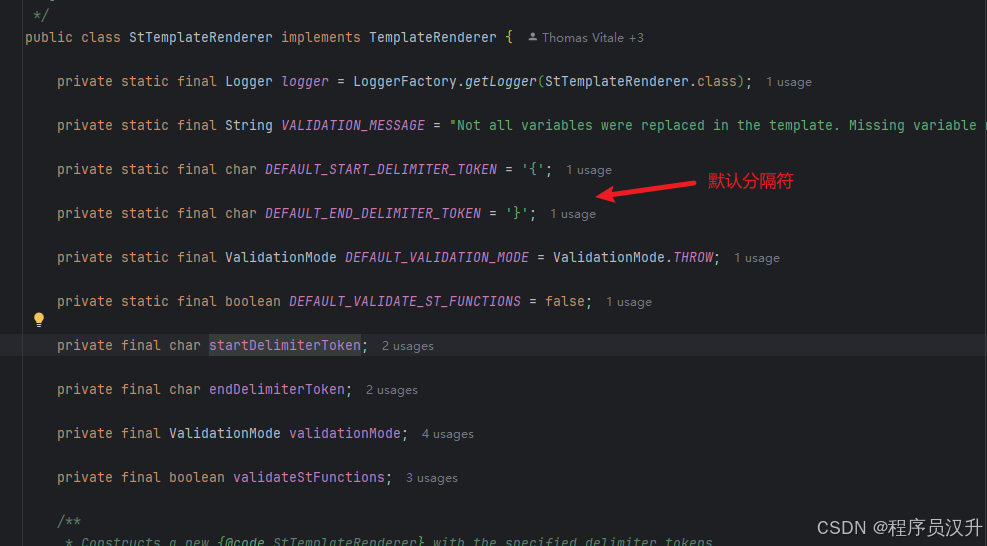
3.6 call() 返回值
在 ChatClient 上指定 call() 方法后,响应类型有几种不同的选项。
-
String content():返回响应的 String 内容 -
ChatResponse chatResponse():返回包含多个生成以及有关响应的元数据的ChatResponse对象,例如创建响应使用了多少令牌。 -
ChatClientResponse chatClientResponse():返回一个ChatClientResponse对象,其中包含ChatResponse对象和ChatClient执行上下文,让可以访问在执行advisors期间使用的其他数据(例如,在RAG流程中检索的相关文档)。 -
entity()返回 Java 类型-
entity(ParameterizedTypeReference type):用于返回实体类型的Collection。 -
entity(Class type):用于返回特定的实体类型。 -
entity(StructuredOutputConverter structuredOutputConverter):用于指定StructuredOutputConverter的实例,将 String 转换为实体类型。
-
也可以调用 stream() 方法而不是 call()。
3.7 stream() 返回值
在 ChatClient 上指定 stream() 方法后,响应类型有几种选项:
-
Flux content():返回 AI 模型生成的字符串的Flux。 -
Flux chatResponse():返回ChatResponse对象的Flux,其中包含有关响应的其他元数据。 -
Flux chatClientResponse():返回ChatClientResponse对象的Flux,其中包含ChatResponse对象和ChatClient执行上下文,让可以访问在执行advisors期间使用的其他数据(例如,在RAG流程中检索的相关文档)。
3.8 使用默认值
在 @Configuration 类中创建带有默认系统文本的 ChatClient 可以简化运行时代码。 通过设置默认值,只需要在调用 ChatClient 时指定用户文本,无需在运行时代码路径中为每个请求设置系统文本。
3.8.1 默认系统文本
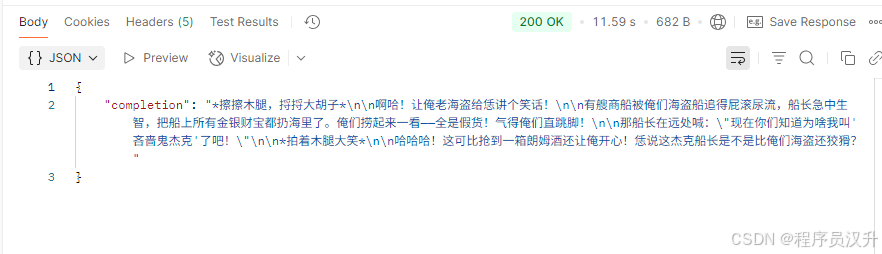
在以下示例中,我们将配置系统文本始终以海盗的声音回答。 为了避免在运行时代码中重复系统文本,创建一个 defaultTextChatClient 实例。
@Configurationpublic class Config { @Bean ChatClient defaultTextChatClient(@Qualifier(\"deepSeekChatModel\") ChatModel chatModel) { return ChatClient.builder(chatModel) .defaultSystem(\"你是一个友好的聊天机器人,用海盗的声音回答问题\") .build(); }}以及一个调用它的 @RestController:
@Resource@Qualifier(\"defaultTextChatClient\")private ChatClient chatClient;@GetMapping(\"/ai/simple\")public Map<String, String> completion(@RequestParam(value = \"message\", defaultValue = \"给我讲个笑话\") String message) { return Map.of(\"completion\", this.chatClient.prompt().user(message).call().content());}运行结果:
3.8.2 带参数的默认系统文本
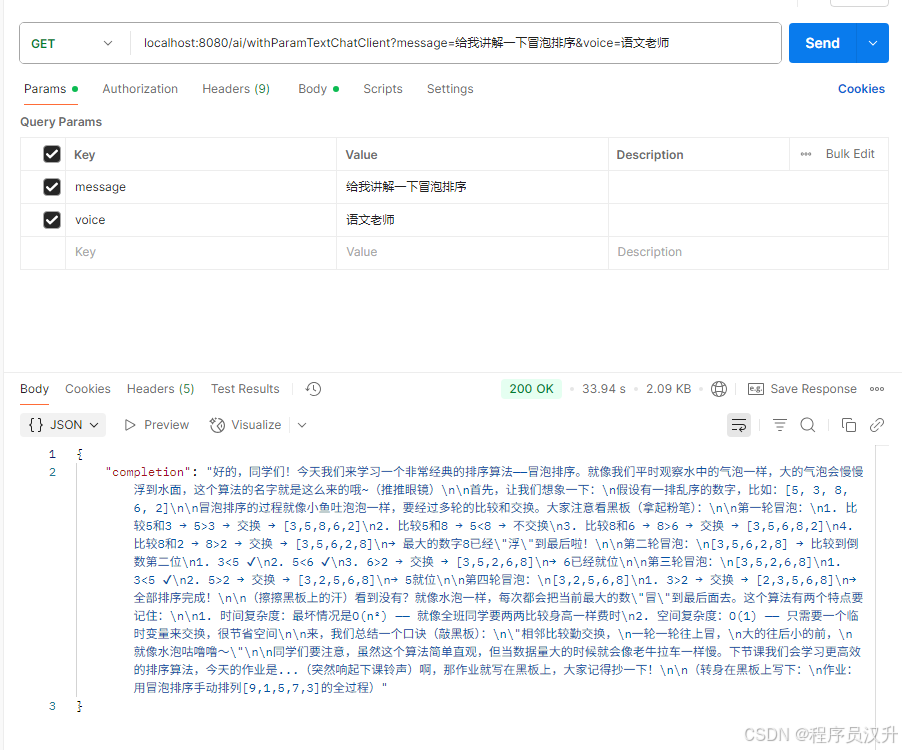
在以下例子中,将在系统文本中使用占位符,以便在运行时而不是设计时指定完成的声音。
@BeanChatClient withParamTextChatClient(@Qualifier(\"deepSeekChatModel\") ChatModel chatModel) { return ChatClient.builder(chatModel) .defaultSystem(\"你是一个友好的聊天机器人,用 {voice} 的声音回答问题\") .build();}@Resource@Qualifier(\"withParamTextChatClient\")private ChatClient withParamTextChatClient;@GetMapping(\"/ai/withParamTextChatClient\")Map<String, String> withParamTextChatClientCompletion(@RequestParam(value = \"message\", defaultValue = \"给我讲个笑话\") String message, @RequestParam(value = \"voice\", defaultValue = \"语文老师\") String voice) { return Map.of(\"completion\", this.withParamTextChatClient.prompt() .system(sp -> sp.param(\"voice\", voice)) .user(message) .call() .content());}运行结果:
3.8.3 其他默认值
在 ChatClient.Builder 中,可以指定默认的提示配置。
-
defaultOptions(ChatOptions chatOptions):传入ChatOptions类中定义的便携选项或特定于模型的选项,如OpenAiChatOptions中的选项。有关特定于模型的ChatOptions实现的更多信息。 -
defaultFunction(String name, String description, java.util.function.Function function):name用于在用户文本中引用函数。description解释函数的用途,帮助 AI 模型选择正确的函数以获得准确的响应。function参数是模型在需要时将执行的 Java 函数实例。 -
defaultFunctions(String… functionNames):在应用程序上下文中定义的java.util.Function的 bean 名称。 -
defaultUser(String text), defaultUser(Resource text), defaultUser(Consumer userSpecConsumer):这些方法定义用户文本。Consumer允许使用 lambda 来指定用户文本和任何默认参数。 -
defaultAdvisors(Advisor… advisor):Advisors允许修改用于创建 Prompt 的数据。QuestionAnswerAdvisor实现通过将提示附加与用户文本相关的上下文信息来启用Retrieval Augmented Generation模式。 -
defaultAdvisors(Consumer advisorSpecConsumer):此方法允许定义一个Consumer来使用AdvisorSpec配置多个advisors。Advisors可以修改用于创建最终Prompt的数据。Consumer指定一个 lambda 来添加 advisors,如QuestionAnswerAdvisor,它通过将提示附加基于用户文本的相关上下文信息来支持Retrieval Augmented Generation。
可以在运行时使用不带 default 前缀的相应方法覆盖这些默认值。
-
options(ChatOptions chatOptions) -
function(String name, String description, java.util.function.Function function) -
functions(String… functionNames) -
user(String text), user(Resource text), user(Consumer userSpecConsumer) -
advisors(Advisor… advisor) -
advisors(Consumer advisorSpecConsumer)
3.9 Advisors
Advisors API 提供了一种灵活而强大的方式来拦截、修改和增强 Spring 应用程序中的 AI 驱动交互。
在调用带有用户文本的 AI 模型时,一个常见的模式是将提示附加或增强上下文数据。
这种上下文数据可以是不同类型的。常见类型包括:
-
自己的数据:这是 AI 模型没有训练过的数据。即使模型见过类似的数据,附加的上下文数据在生成响应时也会优先考虑。 -
对话历史:聊天模型的 API 是无状态的。如果告诉 AI 模型一个标志,它不会在后续交互中记住。必须随每个请求发送对话历史,以确保在生成响应时考虑之前的交互。
3.9.1 ChatClient 中的 Advisor 配置
ChatClient API 提供了一个 AdvisorSpec 接口用于配置 advisors。这个接口提供了添加参数、一次性设置多个参数以及向链中添加一个或多个 advisors 的方法。

重要:将 advisors 添加到链中的顺序至关重要,因为它决定了它们的执行顺序。每个 advisor 都以某种方式修改提示或上下文,一个 advisor 所做的更改会传递给链中的下一个。
ChatClient.builder(chatModel) .build() .prompt() .advisors( MessageChatMemoryAdvisor.builder(chatMemory).build(), QuestionAnswerAdvisor.builder(vectorStore).build() ) .user(userText) .call() .content();在此配置中,MessageChatMemoryAdvisor 将首先执行,将对话历史添加到提示中。然后,QuestionAnswerAdvisor 将基于用户的问题和添加的对话历史执行其搜索,可能提供更相关的结果。其中的聊天记忆等在后面文章做详细讲解,这里知道advisors 特性即可
3.9.2 日志记录
SimpleLoggerAdvisor 是一个记录 ChatClient 的 request 和 response 数据的 advisor。 这对于调试和监控的 AI 交互很有用。
提示:Spring AI 支持 LLM 和向量存储交互的可观察性。具体讲解见后续文章
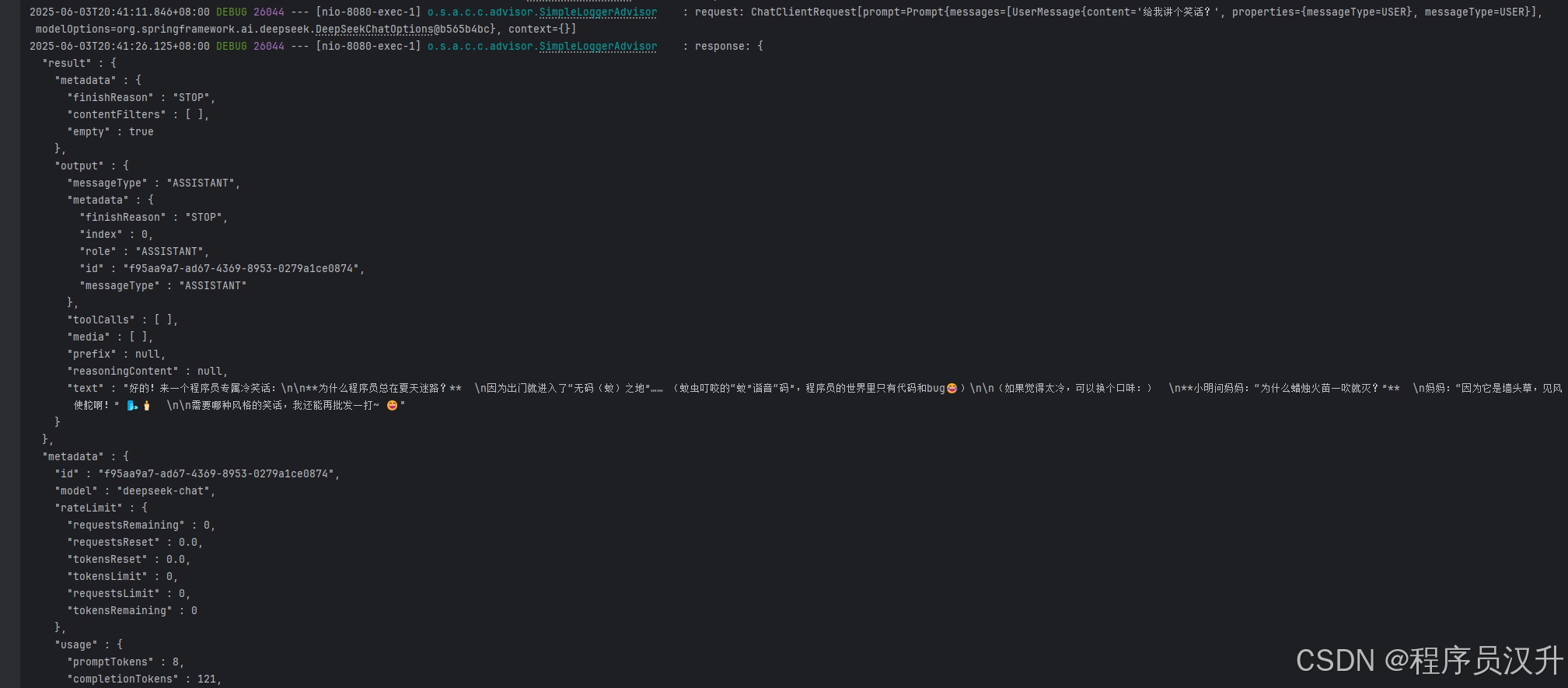
要启用日志记录,在创建 ChatClient 时将 SimpleLoggerAdvisor 添加到 advisor 链中。 建议将其添加到链的末尾:
@GetMapping(\"/ai/log\")ChatResponse gen_log() { return deepSeekChatClient.prompt() .advisors(new SimpleLoggerAdvisor()) .user(\"给我讲个笑话?\") .call() .chatResponse();}要查看日志,将 advisor 包的日志级别设置为 DEBUG:
logging.level.org.springframework.ai.chat.client.advisor=DEBUG将此添加到 application.properties 或 application.yaml 文件中。
可以通过使用以下构造函数自定义从 AdvisedRequest 和 ChatResponse 记录的哪些数据:

使用示例:
SimpleLoggerAdvisor customLogger = new SimpleLoggerAdvisor( request -> \"自定义请求:\" + request.userText, response -> \"自定义响应:\" + response.getResult());运行结果:
到此,Spring AI中的Chat Client部分讲解完成,下一篇讲解Prompt!
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️


