编程语言Java——核心技术篇(四)集合类详解
言不信者行不果,行不敏者言多滞.
目录
4. 集合类
4.1 集合类概述
4.1.1 集合框架遵循原则
4.1.2 集合框架体系
4.2 核心接口和实现类解析
4.2.1 Collection 接口体系
4.2.1.1 Collection 接口核心定义
4.2.1.2 List接口详解
4.2.1.3 Set 接口详解
4.2.1.4 Queue/Deque接口详解
4.2.2 Map 接口体系详解
4.3 集合类选择
4.3.1 集合类选择指南
4.3.2 集合类选择决策树
4.4 性能优化建议
4.5 总结
续前篇:编程语言Java——核心技术篇(三)异常处理详解-CSDN博客
4. 集合类
Java集合框架(Java Collections Framework, JCF)是Java语言中用于存储和操作数据集合的一组接口和类。它提供了一套标准化的数据结构实现,使开发者能够高效地处理数据。
4.1 集合类概述
4.1.1 集合框架遵循原则
集合框架的设计遵循了几个重要原则:
-
接口与实现分离:所有具体集合类都实现自标准接口(如List、Set、Map),这使得程序可以灵活切换不同的实现而不影响业务逻辑。
-
算法复用:Collections工具类提供了大量通用算法(如排序、查找、反转等),这些算法可以应用于任何实现了相应接口的集合类。
-
性能优化:针对不同使用场景提供了多种实现,如需要快速随机访问选择ArrayList,需要频繁插入删除选择LinkedList。
-
扩展性:通过迭代器模式(Iterator)和比较器(Comparator)等设计,使集合框架易于扩展和定制。
-
类型安全:通过泛型机制在编译期检查类型一致性,避免了运行时的类型转换错误。
4.1.2 集合框架体系
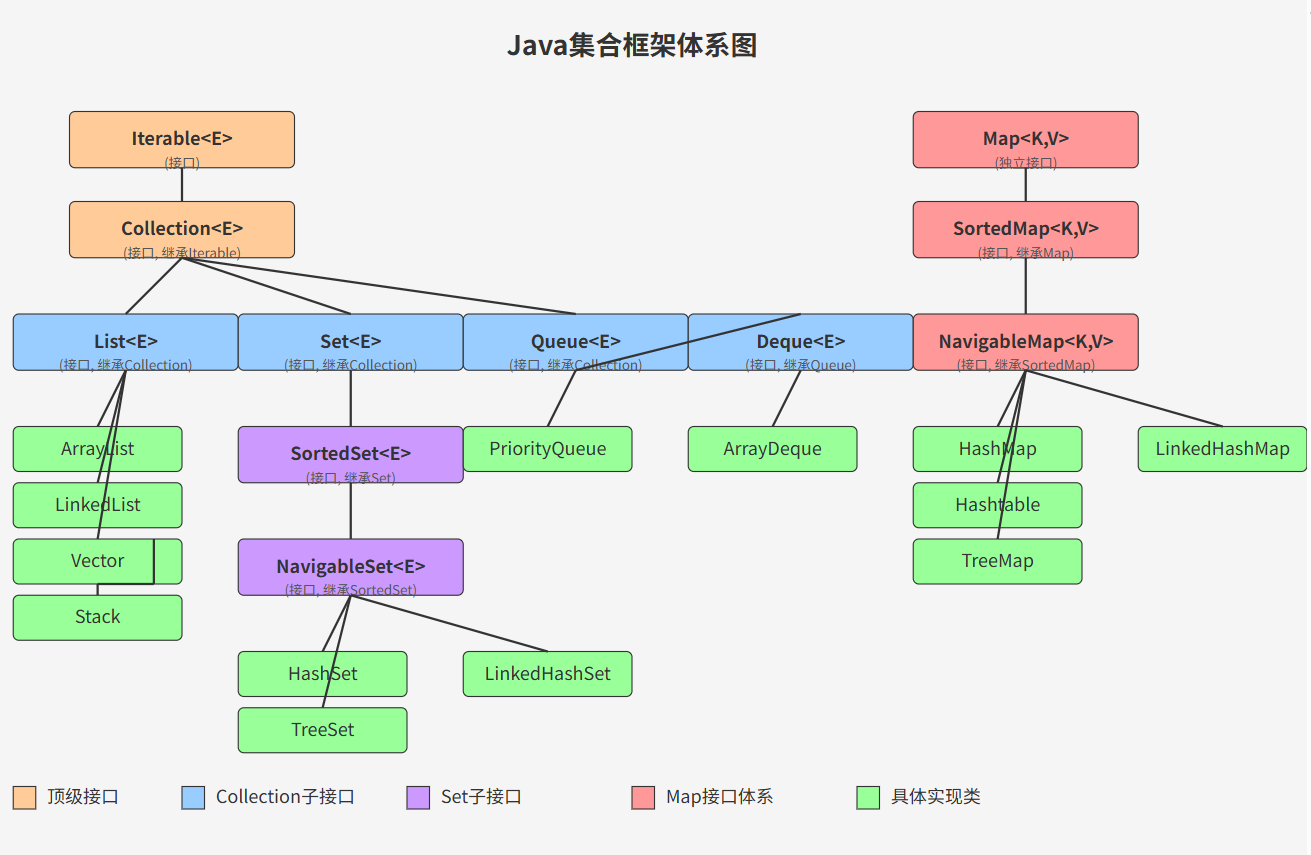
这张图很清楚了,两个顶级父类接口Iterable和Map,剩下的List,Set和Queue等都是两个接口的实现子接口,在下来才是各种实现类。如果只但看各个接口之间的继承关系还有下面这张图:
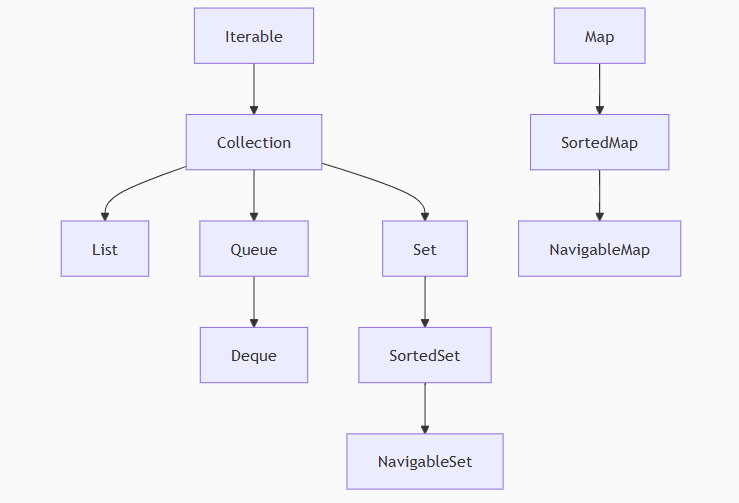
我感觉这两个图可以详细地记一下,因为适用性挺广的,存放数据和操作都会频繁地遇到集合类。
4.2 核心接口和实现类解析
4.2.1 Collection 接口体系
4.2.1.1 Collection 接口核心定义
Collection是单列集合的根接口,定义了集合的通用行为:
public interface Collection extends Iterable { // 基本操作 int size(); boolean isEmpty(); boolean contains(Object o); Iterator iterator(); Object[] toArray(); T[] toArray(T[] a); // 修改操作 boolean add(E e); boolean remove(Object o); // 批量操作 boolean containsAll(Collection c); boolean addAll(Collection c); boolean removeAll(Collection c); boolean retainAll(Collection c); void clear(); // Java 8新增 boolean removeIf(Predicate filter); Spliterator spliterator(); Stream stream(); Stream parallelStream();}4.2.1.2 List接口详解
1. 核心特性:
特有方法:
// 位置访问E get(int index);E set(int index, E element);void add(int index, E element);E remove(int index);// 搜索int indexOf(Object o);int lastIndexOf(Object o);// 范围操作List subList(int fromIndex, int toIndex);// Java 8新增default void replaceAll(UnaryOperator operator);default void sort(Comparator c);2. 实现类对比
3. ArrayList 示例
// 创建ArrayListList arrayList = new ArrayList();// 添加元素arrayList.add(\"Java\");arrayList.add(\"Python\");arrayList.add(1, \"C++\"); // 在指定位置插入// 访问元素String lang = arrayList.get(0); // \"Java\"// 遍历方式1:for循环for (int i = 0; i < arrayList.size(); i++) { System.out.println(arrayList.get(i));}// 遍历方式2:增强for循环for (String language : arrayList) { System.out.println(language);}// 遍历方式3:迭代器Iterator it = arrayList.iterator();while (it.hasNext()) { System.out.println(it.next());}// 删除元素arrayList.remove(\"Python\"); // 按对象删除arrayList.remove(0); // 按索引删除// 转换为数组String[] array = arrayList.toArray(new String[0]);// Java 8操作arrayList.removeIf(s -> s.length() < 3); // 删除长度小于3的元素arrayList.replaceAll(String::toUpperCase); // 全部转为大写ArrayList常用的方法都在这里了。我们可以把ArrayList就看成一个动态数组,实际上ArrayList比较适合查询数组内地各个元素,但在增删改上地性能较差。
4. LinkedList 示例
// 创建LinkedListLinkedList linkedList = new LinkedList();// 添加元素linkedList.add(\"Apple\");linkedList.addFirst(\"Banana\"); // 添加到头部linkedList.addLast(\"Orange\"); // 添加到尾部linkedList.add(1, \"Grape\"); // 在指定位置插入// 队列操作linkedList.offer(\"Pear\"); // 添加到队尾String head = linkedList.poll(); // 移除并返回队头// 栈操作linkedList.push(\"Cherry\"); // 压栈String top = linkedList.pop(); // 弹栈// 获取元素String first = linkedList.getFirst();String last = linkedList.getLast();// 遍历方式:降序迭代器Iterator descIt = linkedList.descendingIterator();while (descIt.hasNext()) { System.out.println(descIt.next());}这里刻意强调一下栈操作。LinkedList 实现了 Deque(双端队列)接口,因此可以作为栈(Stack)使用。栈是一种后进先出(LIFO)的数据结构,实际上就是数据接口的知识。
// 将元素推入栈顶(实际添加到链表头部)入栈LinkedList stack = new LinkedList();stack.push(\"A\"); // 栈底 ← \"A\" → 栈顶stack.push(\"B\"); // 栈底 ← \"A\" ← \"B\" → 栈顶stack.push(\"C\"); // 栈底 ← \"A\" ← \"B\" ← \"C\" → 栈顶String top = stack.pop(); // 移除并返回栈顶元素 \"C\" 出栈// 现在栈状态:栈底 ← \"A\" ← \"B\" → 栈顶String peek = stack.peek(); // 返回 \"B\"(栈顶元素)// 栈保持不变:栈底 ← \"A\" ← \"B\" → 栈顶4.2.1.3 Set 接口详解
1. 核心特性:
-
元素唯一性:不包含重复元素(依据equals()判断)
-
无序性:不保证维护插入顺序(TreeSet/LinkedHashSet除外)
-
数学集合:支持并集、交集、差集等操作
2. 实现类对比
3. HashSet 示例
// 创建HashSetSet hashSet = new HashSet();// 添加元素hashSet.add(\"Java\");hashSet.add(\"Python\");hashSet.add(\"Java\"); // 重复元素不会被添加// 判断包含boolean hasJava = hashSet.contains(\"Java\"); // true// 删除元素hashSet.remove(\"Python\");// 遍历for (String language : hashSet) { System.out.println(language);}// 集合运算Set otherSet = new HashSet(Arrays.asList(\"C++\", \"Java\", \"JavaScript\"));hashSet.retainAll(otherSet); // 交集hashSet.addAll(otherSet); // 并集hashSet.removeAll(otherSet); // 差集4. LinkedHashSet示例
// 创建LinkedHashSet(保持插入顺序)Set linkedHashSet = new LinkedHashSet();linkedHashSet.add(\"First\");linkedHashSet.add(\"Second\");linkedHashSet.add(\"Third\");// 遍历顺序与插入顺序一致for (String item : linkedHashSet) { System.out.println(item); // 输出顺序:First, Second, Third}// 移除并添加,顺序会变linkedHashSet.remove(\"Second\");linkedHashSet.add(\"Second\");// 现在顺序:First, Third, SecondLinkedHashSet能够保持插入顺序,即删除时后面元素会自动补位,增添元素时会自动退位;但HashSet不会,不管组内元素如何变化,其他元素均不变。
5. TreeSet示例
// 创建TreeSet(自然排序)Set treeSet = new TreeSet();treeSet.add(\"Orange\");treeSet.add(\"Apple\");treeSet.add(\"Banana\");// 自动排序输出for (String fruit : treeSet) { System.out.println(fruit); // Apple, Banana, Orange}// 定制排序Set customSort = new TreeSet((a, b) -> b - a); // 降序customSort.addAll(Arrays.asList(5, 3, 9, 1));// 输出:9, 5, 3, 1// 导航方法TreeSet nums = new TreeSet(Arrays.asList(1, 3, 5, 7, 9));Integer lower = nums.lower(5); // 3 (小于5的最大元素)Integer higher = nums.higher(5); // 7 (大于5的最小元素)Integer floor = nums.floor(4); // 3 (小于等于4的最大元素)Integer ceiling = nums.ceiling(6); // 7 (大于等于6的最小元素)// 范围视图Set subSet = nums.subSet(3, true, 7, false); // [3, 5]4.2.1.4 Queue/Deque接口详解
1. Queue核心方法:
2. 实现类对比
3. PriorityQueue示例
// 创建优先级队列(自然排序)PriorityQueue pq = new PriorityQueue();pq.add(30);pq.add(10);pq.add(20);// 取出时会按顺序while (!pq.isEmpty()) { System.out.println(pq.poll()); // 10, 20, 30}// 定制排序PriorityQueue customPq = new PriorityQueue( (s1, s2) -> s2.length() - s1.length()); // 按长度降序customPq.add(\"Apple\");customPq.add(\"Banana\");customPq.add(\"Pear\");// 输出:Banana, Apple, Pear2. ArrayDeque示例
// 创建ArrayDequeDeque deque = new ArrayDeque();// 作为栈使用deque.push(\"First\");deque.push(\"Second\");String top = deque.pop(); // \"Second\"// 作为队列使用deque.offer(\"Third\");deque.offer(\"Fourth\");String head = deque.poll(); // \"First\"// 双端操作deque.addFirst(\"Front\");deque.addLast(\"End\");String first = deque.getFirst(); // \"Front\"String last = deque.getLast(); // \"End\"4.2.2 Map 接口体系详解
1. 核心定义
public interface Map { // 基本操作 int size(); boolean isEmpty(); boolean containsKey(Object key); boolean containsValue(Object value); V get(Object key); V put(K key, V value); V remove(Object key); // 批量操作 void putAll(Map m); void clear(); // 集合视图 Set keySet(); Collection values(); Set<Map.Entry> entrySet(); // 内部Entry接口 interface Entry { K getKey(); V getValue(); V setValue(V value); // Java 8新增 boolean equals(Object o); int hashCode(); public static <K extends Comparable, V> Comparator<Map.Entry> comparingByKey() // ... } // Java 8新增方法 default V getOrDefault(Object key, V defaultValue) default void forEach(BiConsumer action) default V putIfAbsent(K key, V value) default boolean remove(Object key, Object value) default boolean replace(K key, V oldValue, V newValue) default V replace(K key, V value) default void replaceAll(BiFunction function) default V computeIfAbsent(K key, Function mappingFunction) // ...}这里是Java的源码,可以看到Map实际上放的是一对K-V键值对。
2. 实现类对比
3. HashMap示例
// 创建HashMapMap hashMap = new HashMap();// 添加键值对hashMap.put(\"Apple\", 10);hashMap.put(\"Banana\", 20);hashMap.put(\"Orange\", 15);// 获取值int apples = hashMap.get(\"Apple\"); // 10int defaultValue = hashMap.getOrDefault(\"Pear\", 0); // 0// 遍历方式1:entrySetfor (Map.Entry entry : hashMap.entrySet()) { System.out.println(entry.getKey() + \": \" + entry.getValue());}// 遍历方式2:keySetfor (String key : hashMap.keySet()) { System.out.println(key);}// 遍历方式3:valuesfor (int value : hashMap.values()) { System.out.println(value);}// Java 8操作hashMap.forEach((k, v) -> System.out.println(k + \" => \" + v));hashMap.computeIfAbsent(\"Pear\", k -> 5); // 如果不存在则添加hashMap.merge(\"Apple\", 5, Integer::sum); // Apple数量增加54. LinkedHashMap示例
// 创建LinkedHashMap(保持插入顺序)Map linkedHashMap = new LinkedHashMap();linkedHashMap.put(\"First\", 1);linkedHashMap.put(\"Second\", 2);linkedHashMap.put(\"Third\", 3);// 遍历顺序与插入顺序一致linkedHashMap.forEach((k, v) -> System.out.println(k)); // First, Second, Third// 按访问顺序排序的LinkedHashMap(可用于LRU缓存)Map accessOrderMap = new LinkedHashMap(16, 0.75f, true);accessOrderMap.put(\"One\", 1);accessOrderMap.put(\"Two\", 2);accessOrderMap.put(\"Three\", 3);accessOrderMap.get(\"Two\"); // 访问Two会使它移动到末尾// 现在顺序:One, Three, Two5. TreeMap示例
// 创建TreeMap(按键自然排序)Map treeMap = new TreeMap();treeMap.put(\"Orange\", 5);treeMap.put(\"Apple\", 10);treeMap.put(\"Banana\", 8);// 按键排序输出treeMap.forEach((k, v) -> System.out.println(k)); // Apple, Banana, Orange// 定制排序Map reverseMap = new TreeMap(Comparator.reverseOrder());reverseMap.putAll(treeMap);// 输出顺序:Orange, Banana, Apple// 导航方法TreeMap employeeMap = new TreeMap();employeeMap.put(1001, \"Alice\");employeeMap.put(1002, \"Bob\");employeeMap.put(1003, \"Charlie\");Map.Entry entry = employeeMap.floorEntry(1002); // 1002=BobInteger higherKey = employeeMap.higherKey(1001); // 1002// 范围视图Map subMap = employeeMap.subMap(1001, true, 1003, false); // 1001-1002红黑树特性:
-
每个节点是红色或黑色
-
根节点是黑色
-
所有叶子节点(NIL)是黑色
-
红色节点的子节点必须是黑色
-
从任一节点到其每个叶子的路径包含相同数目的黑色节点
主要是TreeMap的底层结构就是红黑树,这里建议恶补一下数据结构的知识——红黑树、链表、二叉堆和二叉树等,方便理解。这里放两个链接:
二叉树和堆详解(通俗易懂)_堆和二叉树的区别-CSDN博客
【数据结构】红黑树超详解 ---一篇通关红黑树原理(含源码解析+动态构建红黑树)_红黑树的原理-CSDN博客
4.3 集合类选择
4.3.1 集合类选择指南
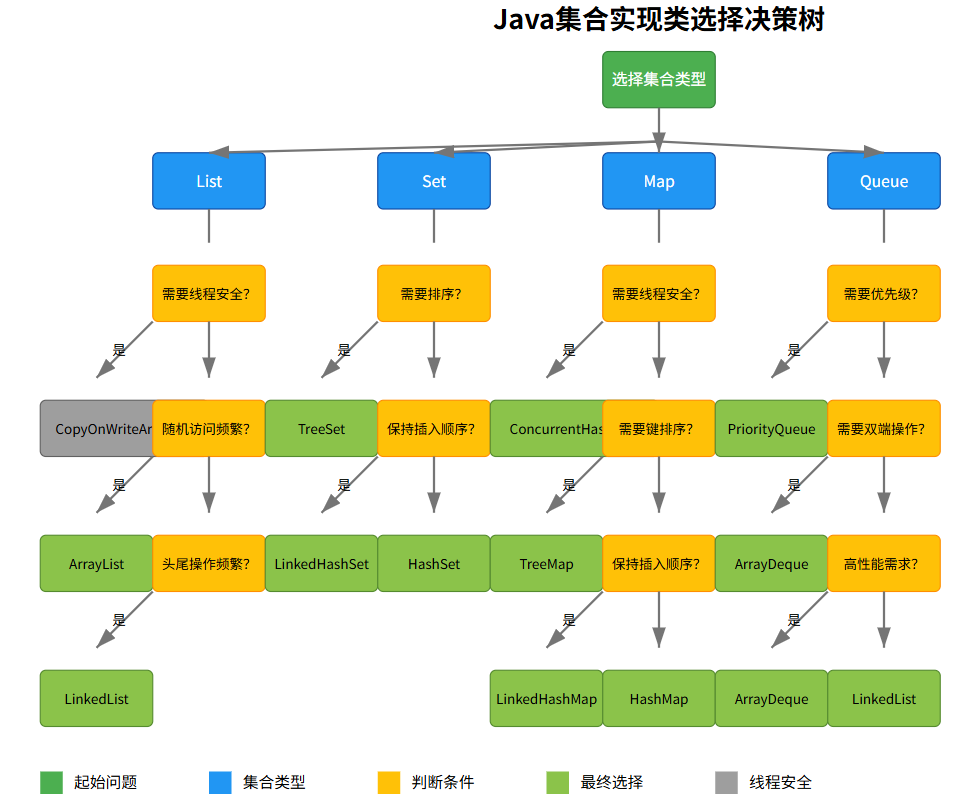
-
需要存储键值对时:
-
不需要排序:HashMap
-
需要保持插入/访问顺序:LinkedHashMap
-
需要按键排序:TreeMap
-
需要线程安全:ConcurrentHashMap
-
-
只需要存储元素时:
-
允许重复、需要索引:ArrayList/LinkedList
-
不允许重复、不关心顺序:HashSet
-
不允许重复、需要保持插入顺序:LinkedHashSet
-
不允许重复、需要排序:TreeSet
-
-
需要队列功能时:
-
普通队列:ArrayDeque
-
优先级队列:PriorityQueue
-
线程安全队列:LinkedBlockingQueue
-
-
需要线程安全时:
-
List:CopyOnWriteArrayList
-
Set:CopyOnWriteArraySet
-
Map:ConcurrentHashMap
-
Queue:LinkedBlockingQueue
-
4.3.2 集合类选择决策树
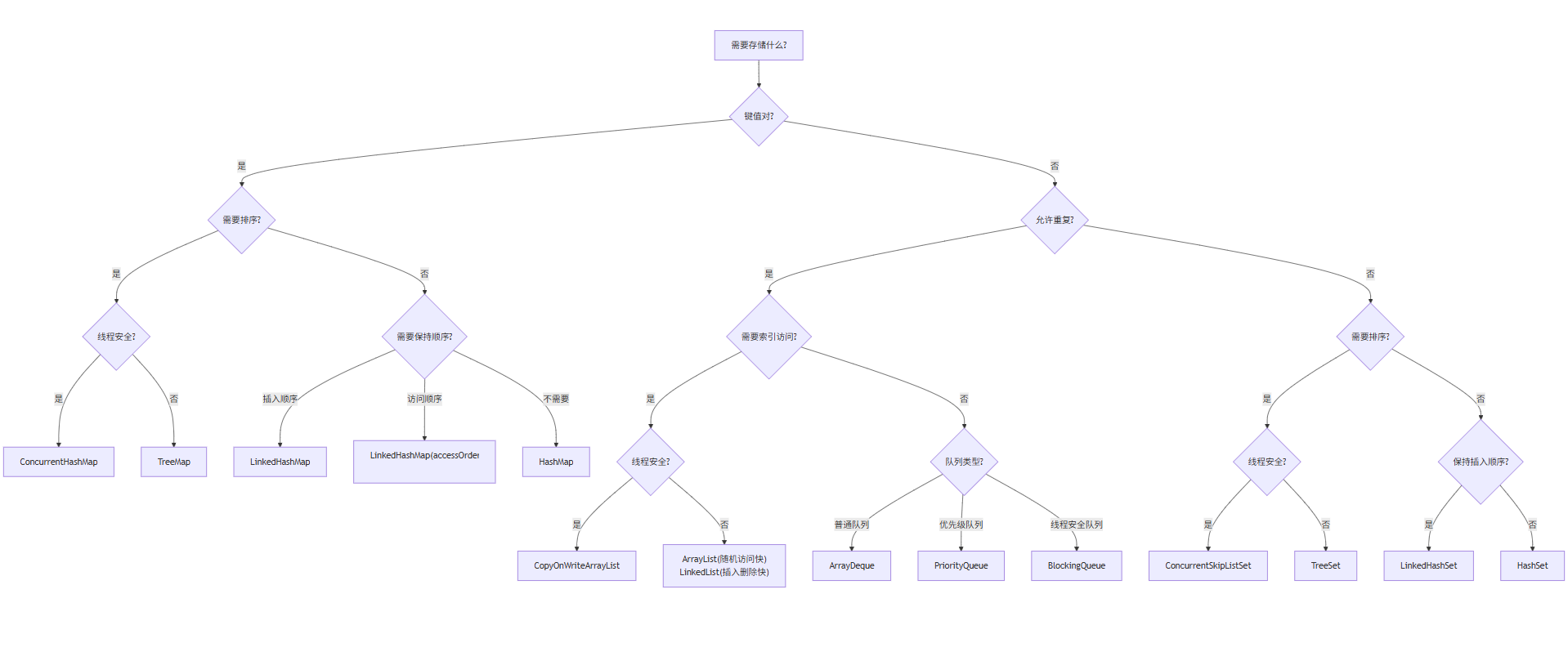
字有点小,建议点开了以后放大看 !!
决策树文字说明:
-
第一层决策:存储类型
-
键值对 → 进入Map分支
-
单元素 → 进入Collection分支
-
-
Map分支选择逻辑:
-
需要排序?→
TreeMap(自然排序)或ConcurrentSkipListMap(线程安全排序) -
不需要排序但需要顺序?→
LinkedHashMap(可配置插入顺序或访问顺序) -
都不需要 →
HashMap(最高性能)或ConcurrentHashMap(线程安全)
-
-
Collection分支选择逻辑:
-
允许重复(List/Queue):
-
需要索引 →
ArrayList(随机访问快)或LinkedList(插入删除快) -
需要队列 →
ArrayDeque(标准队列)或PriorityQueue(优先级队列) -
线程安全 →
CopyOnWriteArrayList或BlockingQueue实现类
-
-
不允许重复(Set):
-
需要排序 →
TreeSet或ConcurrentSkipListSet -
需要插入顺序 →
LinkedHashSet -
只需要去重 →
HashSet
-
-
4.4 性能优化建议
-
合理设置初始容量:对于ArrayList、HashMap等基于数组的集合,预先设置合理的初始容量可以减少扩容带来的性能损耗。
-
选择合适的负载因子:HashMap的负载因子(默认0.75)决定了哈希表在多少满时扩容。更高的值节省内存但增加哈希冲突。
-
实现高质量的hashCode():对于作为HashMap键或HashSet元素的类,要确保hashCode()方法能产生均匀分布的哈希值。
-
考虑使用视图:keySet()、values()等方法返回的是视图而非新集合,可以节省内存。
-
注意自动装箱开销:对于大量基本类型数据,考虑使用专门的集合库如Trove,避免自动装箱带来的性能损耗。
-
谨慎使用同步集合:只有在确实需要线程安全时才使用同步包装器,否则会带来不必要的性能损失。
-
利用不可变集合:对于不会修改的集合,使用Collections.unmodifiableXXX()创建不可变视图,既安全又明确表达设计意图。
4.5 总结
我在第一次接触集合类的时候其实有点被搞得眼花缭乱的,因为实现类太多了我也不是特别能分得清各个核心类之间的区别;后来代码量逐渐上来以后才能分辨请他们之间的差异。比较核心底层的东西还是得看源码。

