Pandas query() 方法详解
Pandas query() 方法详解
query() 是 Pandas 中一个非常强大的方法,它允许你使用字符串表达式来筛选数据行。这种方法比传统的布尔索引更简洁、更易读。
基本语法
df.query(expr, inplace=False, **kwargs)expr: 查询字符串表达式inplace: 是否原地修改 DataFrame (默认为 False)**kwargs: 其他关键字参数
- 对于大型 DataFrame,
query()通常比布尔索引快,因为它在底层使用了 numexpr 库- 但对于小型 DataFrame,传统布尔索引可能更快
基本用法
1. 简单条件查询
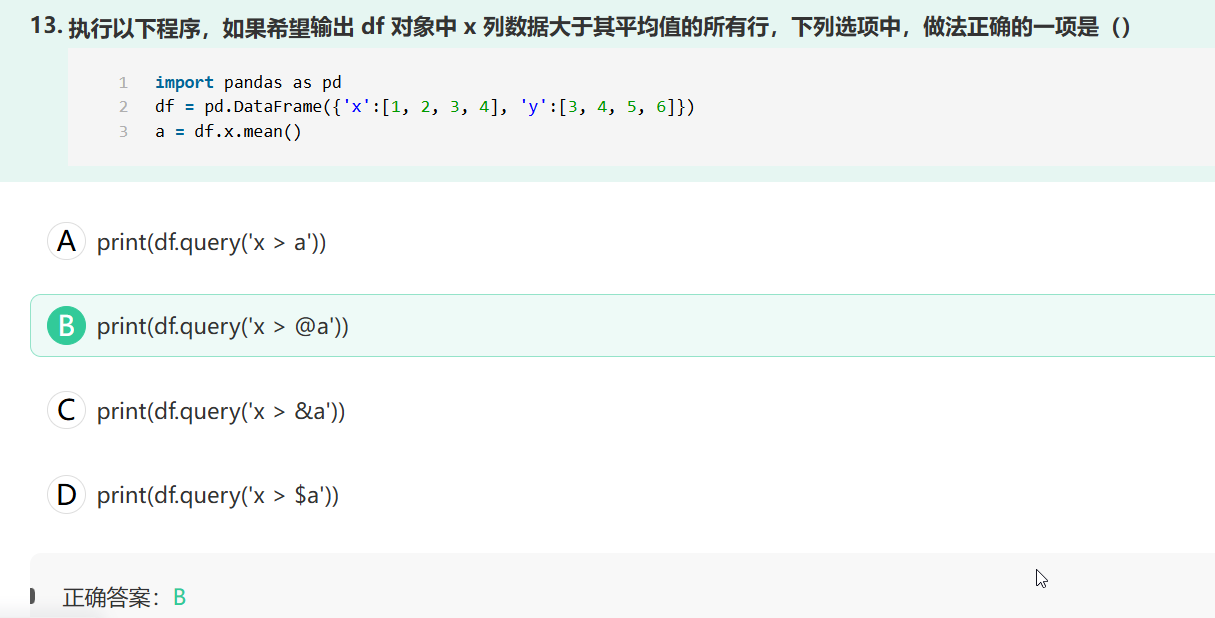
import pandas as pddf = pd.DataFrame({ \'A\': range(1, 6), \'B\': range(10, 60, 10), \'C\': [\'a\', \'b\', \'c\', \'d\', \'e\']})# 查询 A 列大于 2 的行result = df.query(\'A > 2\')2. 多条件查询
# AND 条件df.query(\'A > 2 & B 4 | B == 20\')# 使用括号明确优先级df.query(\'(A > 2) & (B < 50)\')3. 字符串条件查询
# 等于df.query(\'C == \"a\"\')# 不等于df.query(\'C != \"a\"\')# 包含在列表中df.query(\'C in [\"a\", \"b\", \"c\"]\')# 不包含在列表中df.query(\'C not in [\"a\", \"b\"]\')高级用法
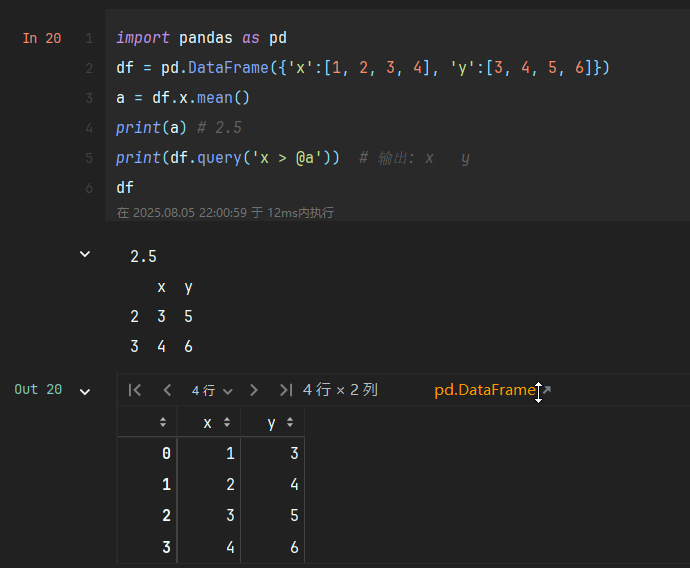
1. 使用变量 (@符号)
min_val = 3max_val = 5df.query(\'A >= @min_val & A <= @max_val\')2. 列名包含空格或特殊字符
df = pd.DataFrame({\'A value\': [1, 2, 3], \'B@value\': [4, 5, 6]})# 使用反引号包裹列名df.query(\'`A value` > 1 & `B@value` < 6\')3. 使用 DataFrame 属性
# 查询索引df.query(\'index > 2\')# 查询列长度df.query(\'A.str.len() > 1\') # 如果A是字符串列4. 使用函数
# 使用内置函数df.query(\'A.abs() > 2\') # 绝对值# 使用自定义函数def my_func(x): return x * 2df.query(\'A > @my_func(2)\')性能考虑
- 对于大型 DataFrame,
query()通常比布尔索引快,因为它在底层使用了 numexpr 库 - 但对于小型 DataFrame,传统布尔索引可能更快
与传统布尔索引的比较
# 传统布尔索引df[(df[\'A\'] > 2) & (df[\'B\'] 2 & B < 50\')query() 的优势在于:
- 语法更简洁
- 不需要重复写 DataFrame 名称
- 对于复杂条件更易读
注意事项
- 表达式必须返回布尔值
- 列名中的特殊字符需要用反引号包裹
- 使用变量时需要用 @ 符号
- 表达式中的字符串需要用双引号包裹
实际应用示例
# 创建示例数据data = { \'name\': [\'Alice\', \'Bob\', \'Charlie\', \'David\', \'Eve\'], \'age\': [25, 30, 35, 40, 45], \'salary\': [50000, 60000, 70000, 80000, 90000], \'department\': [\'HR\', \'IT\', \'IT\', \'Finance\', \'HR\']}df = pd.DataFrame(data)# 查询年龄在30-40之间且部门为IT或HR的员工result = df.query(\'(age >= 30 & age @avg_salary\')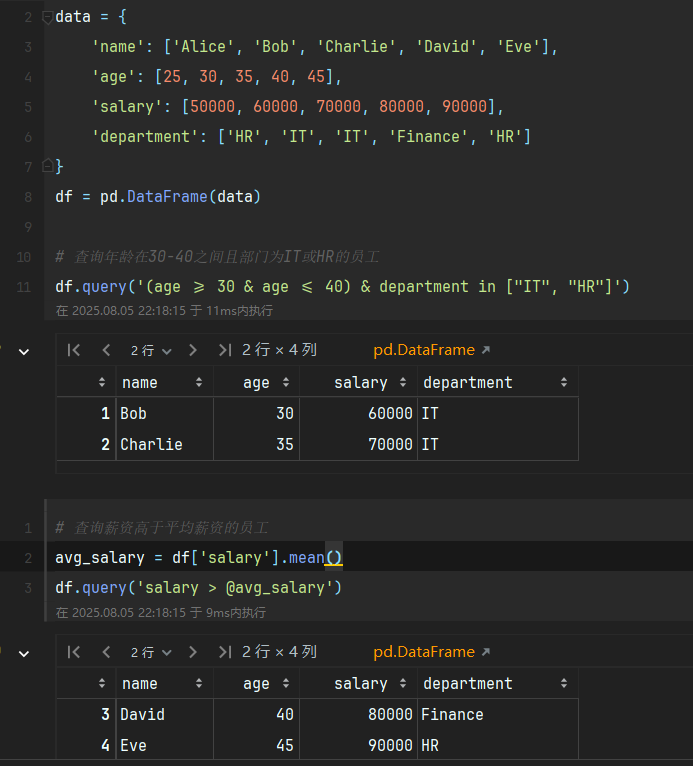
query() 方法是 Pandas 中非常实用的功能,特别适合需要编写复杂筛选条件的场景,能够显著提高代码的可读性和简洁性。
例题