MySQL 数据操作全流程:创建、读取、更新与删除实战_mysql插入数据的过程
MySQL系列
文章目录
- MySQL系列
- 前言
- 一、Create(创建)并插入数据
-
- 1.1 单行数据 + 全列插入
- 1.2 多行数据 + 指定列插入
- 1.3 插入冲突时同步更新
- 1.4 冲突时替换
- 二、Retireve读取数据
-
- 2.1 全列查询
- 2.2 查询指定列
- 2.3 查询字段为表达式
- 2.4 结果去重 DISTINCT
- 2.5 where条件筛选
- 2.6 order by语句(结果排序)
- 2.6 limit的使用(筛选分页结果)
- 三、Update更新修改
- 四、Delete删除
- 五、插入查询结果
前言
本篇将介绍表的增删查改(CURD),在数据库技术与项目开发中,CURD 是对应 Create(创建)、Update(更新)、Read(读取)、Delete(删除)四类数据处理动作的核心操作缩写,也是贯穿各类项目开发全流程的基础数据交互原子操作。
本篇内容紧跟上篇,前半部分的操作比较基础,之前的文章中你已经见过了
一、Create(创建)并插入数据
创建一个用于测试的表结果:
CREATE TABLE students (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,sn INT NOT NULL UNIQUE COMMENT \'学号\',name VARCHAR(20) NOT NULL,qq VARCHAR(20));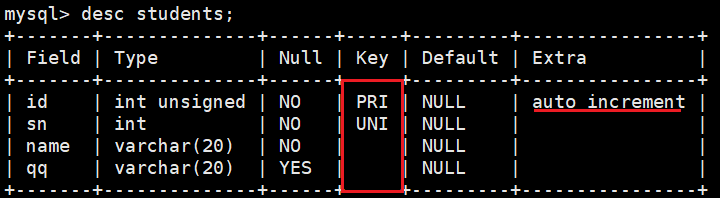
插入语法:
INSERT [INTO] table_name [(column1 [, column2, ...])]VALUES (value1 [, value2, ...]), [(value1 [, value2, ...]), ...];[]中的内容都是可自主选择的填写字段
-
核心结构:
INSERT [INTO] table_name [(列名列表)] VALUES (对应值列表)table_name:需插入数据的目标表名(列名列表):需插入的具体属性列(如id, name)VALUES (值列表):与列名列表一一对应的数据值
-
关键语法细节:
INSERT后可加INTO关键字,也可直接省略(如INSERT table_name ...)。- 全列插入场景:若不写
(列名列表),则默认需一次性插入表中所有属性列,此时VALUES后的值需按表定义的列顺序完整提供。
1.1 单行数据 + 全列插入
insert into students values (100, 10000, \'唐三藏\', null);insert students values (101, 10001, \'孙悟空\', \'11111\');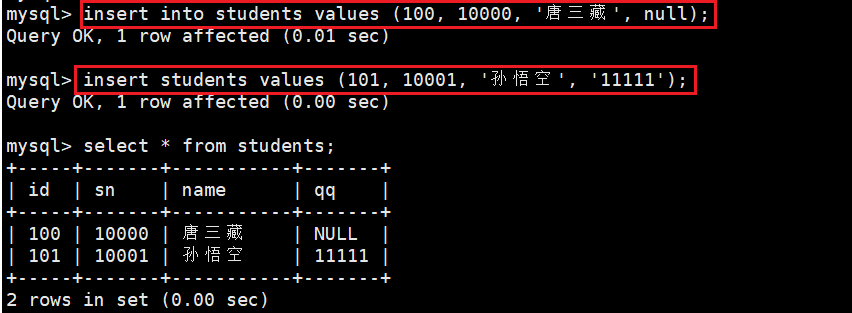
1.2 多行数据 + 指定列插入
插入数据时,使用,分割列名列表,多行数据使用,分割值列表:
insert into students (id, sn, name) values(102, 20001, \'曹孟德\'),(103, 20002, \'孙仲谋\');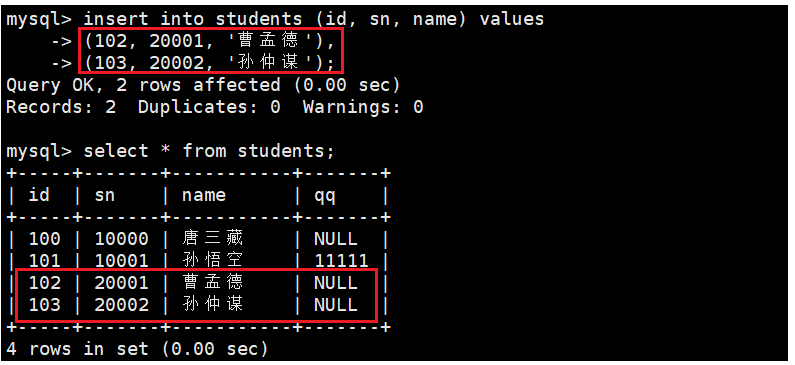
1.3 插入冲突时同步更新
在插入数据时,若遇到主键冲突或唯一键冲突,可通过在 INSERT 语句后添加特定子句(如 ON DUPLICATE KEY UPDATE)实现冲突处理逻辑,确保即使存在冲突也能正常执行操作,避免直接报错导致插入失败。
INSERT INTO table_name (column1, column2, ...)VALUES (value1, value2, ...)ON DUPLICATE KEY UPDATE column1 = value1, -- 冲突时更新的字段及值 column2 = value2; -- 可指定多个更新字段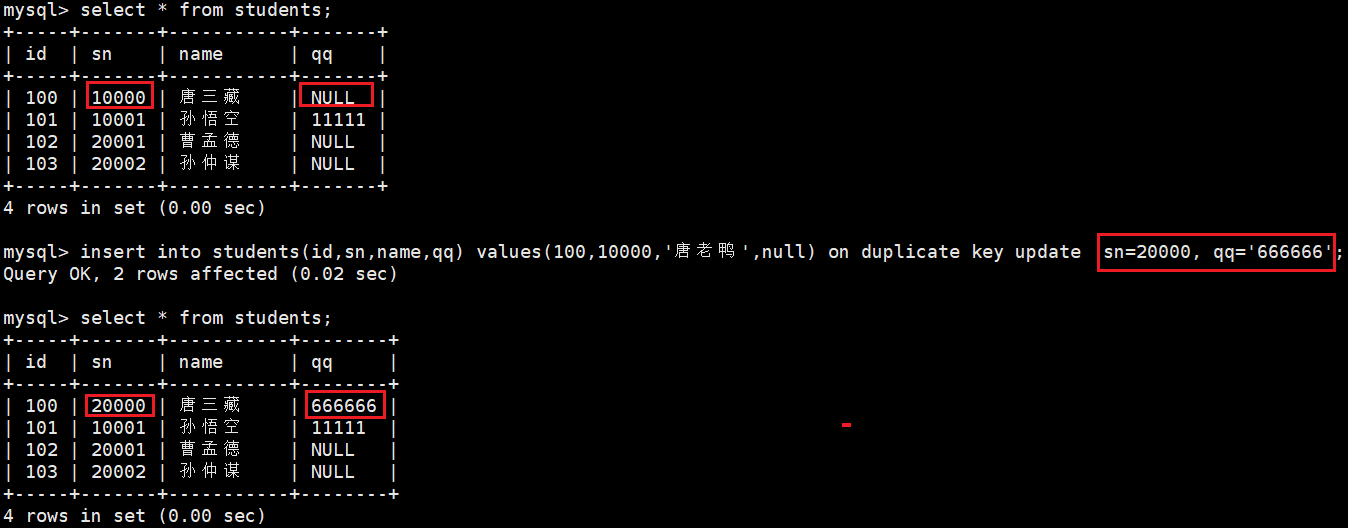
这里必须保障跟新后的逐渐和唯一键不能与表中已存在的产生冲突。
SELECT ROW_COUNT();该函数可以查看你在执行操作时,受到影响的行数。
1.4 冲突时替换
-- 主键 或者 唯一键 没有冲突,则直接插入;-- 主键 或者 唯一键 如果冲突,则删除后再插入replace into students (sn, name) values (20001, \'曹贼\');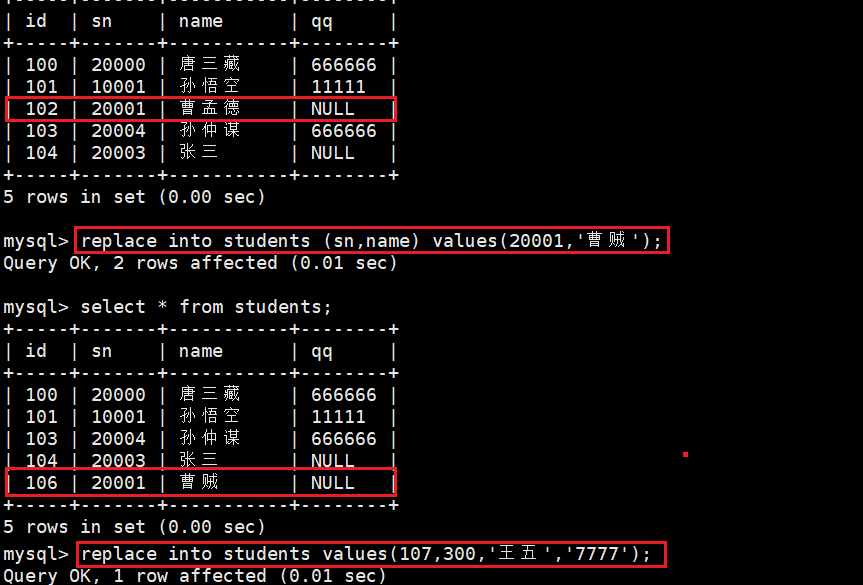
发生唯一键冲突时,将冲突行删除后重新插入(id自增长变化),不发生冲突则直接插入。
二、Retireve读取数据
SELECT [DISTINCT] {*, column1, column2, ...} -- 选择列(*表示所有列)FROM table_name[WHERE condition] -- 筛选条件[ORDER BY column1 [ASC|DESC], -- 排序规则 column2 [ASC|DESC]][LIMIT count]; -- 限制返回行数该sql语句可选项较多,接下我会根据实例来逐一介绍
create table exam_result (id int unsigned primary key auto_increment,name varchar(20) not null comment \'同学姓名\',chinese float default 0.0 comment \'语文成绩\',math float default 0.0 comment \'数学成绩\',english float default 0.0 comment \'英语成绩\');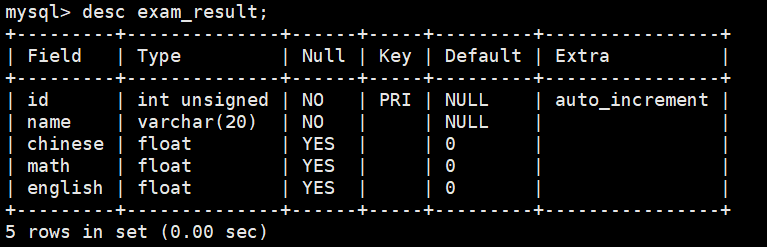
测试数据
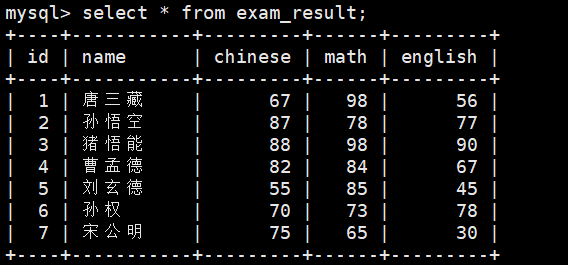
INSERT INTO exam_result (name, chinese, math, english) VALUES(\'唐三藏\', 67, 98, 56),(\'孙悟空\', 87, 78, 77),(\'猪悟能\', 88, 98, 90),(\'曹孟德\', 82, 84, 67),(\'刘玄德\', 55, 85, 45),(\'孙权\', 70, 73, 78),(\'宋公明\', 75, 65, 30);2.1 全列查询
SELECT * FROM exam_result;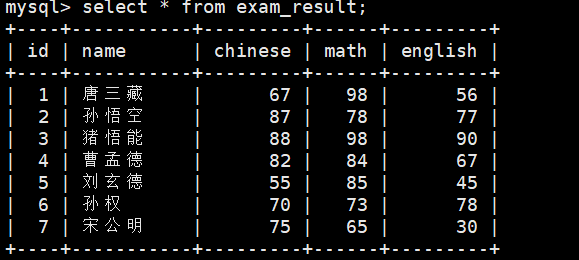
- 通常情况下不建议使用 * 进行全列查询,查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。
2.2 查询指定列
-- 指定列的顺序不需要按定义表的顺序来SELECT id, name, english FROM exam_result;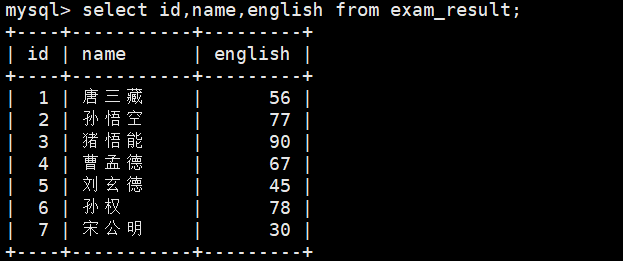
可以根据需要查找任意列
2.3 查询字段为表达式
select id,name,chinese+english,1 from exam_result;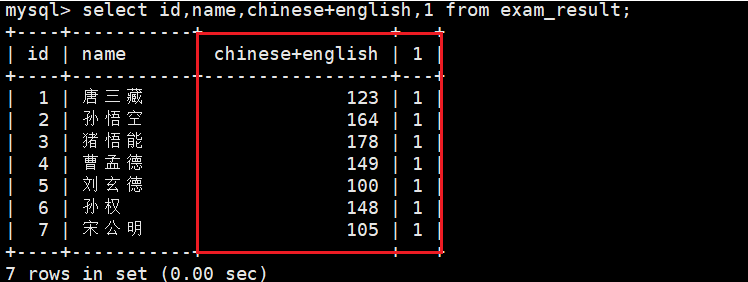
select可跟任意合法表达式,并返回表达式计算的结果,图中1就是表达式1计算的结果。
为查询结果指定别名
select id,name,chinese+english as \'语文+英语\' from exam_result;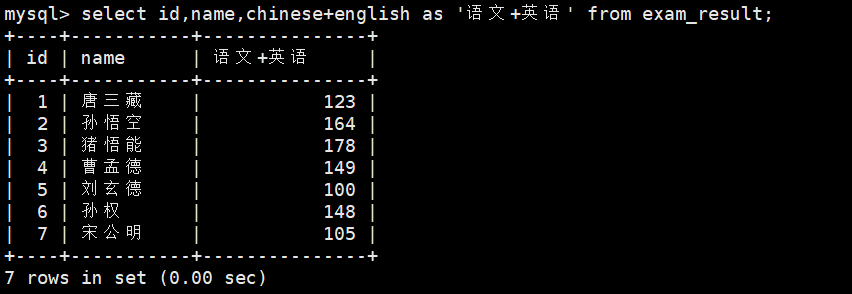
使用as可对表达式进行重命名,as可以省略
2.4 结果去重 DISTINCT
select distinct math from exam_result;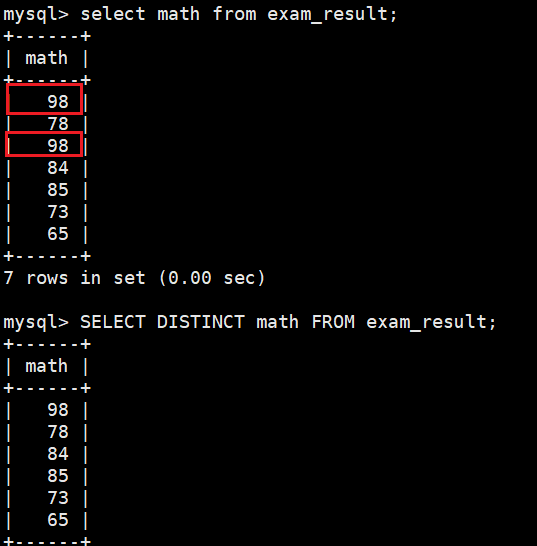
2.5 where条件筛选
比较运算符:
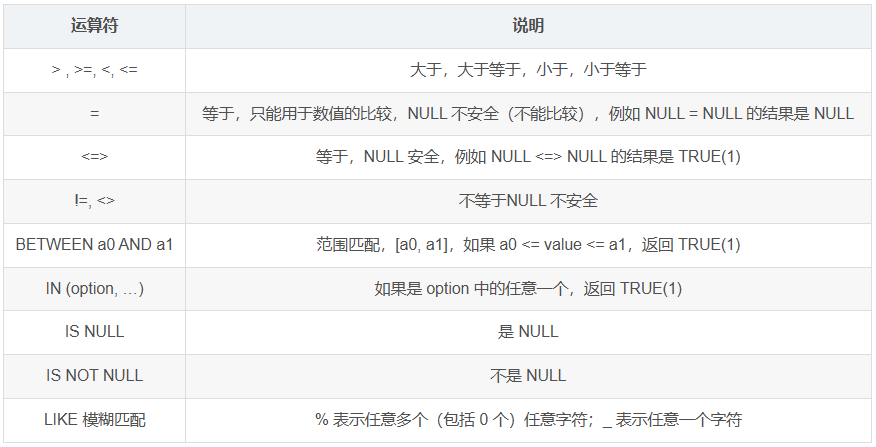
注意
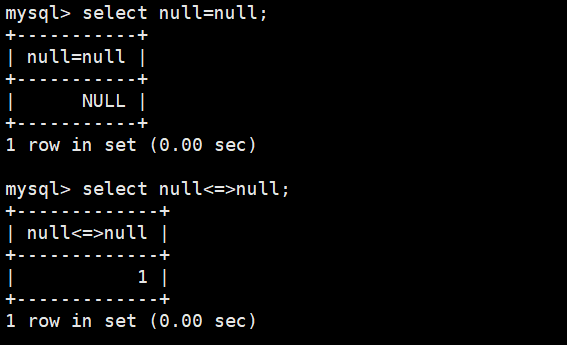
=不可直接用于NULL值比较,可以使用进行比较
null不参与运算(前篇介绍了)
逻辑运算符:
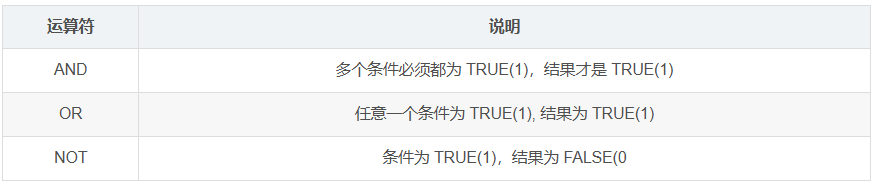
接下来结合实例,了解运算符的使用
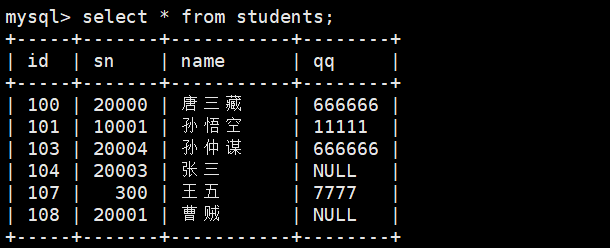
1、查找students表中qq为空的
select name,qq from students where qqnull;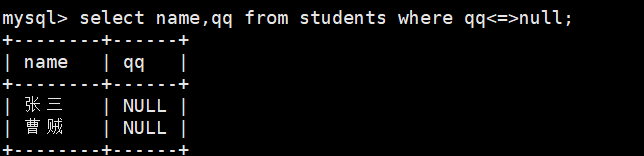
select name,qq from students where qq is null;
2、查找students表中qq不为空的
select name,qq from students where qq is not null;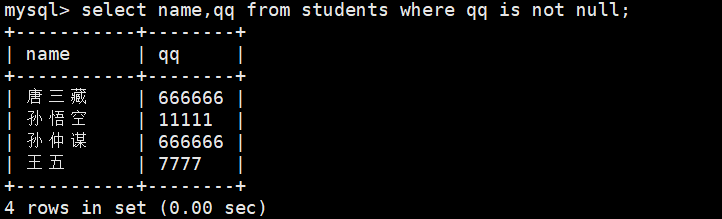
3、英语不及格的同学及英语成绩 ( < 60 )
select name,english from exam_result where english <60;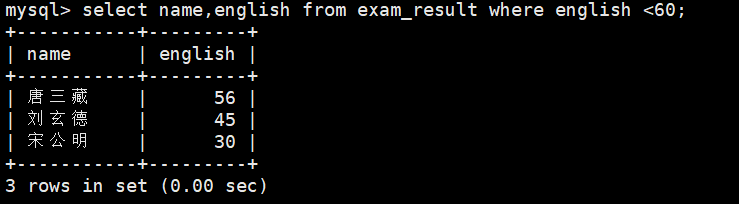
4、语文成绩在 [80, 90] 分的同学及语文成绩
select name,chinese from exam_result where chinese >= 80 and chinese < 90;
select name,chinese from exam_result where chinese between 80 and 90;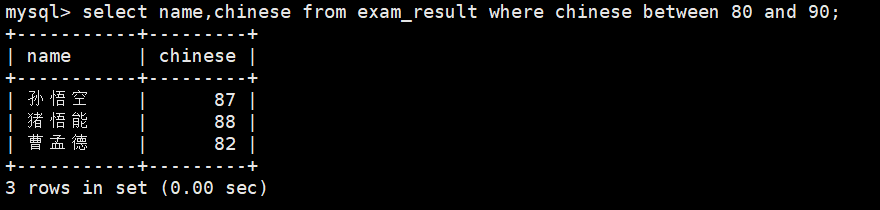
注意使用between...and...查找的区间为闭区间
5、数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
select name,math from exam_result where math=58 or math=59 or math=99 or math=98;
select name ,math from exam_result where math in(58,59,98,99);
6、姓孙的同学
LIKE 模糊匹配:% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符
select id,name from exam_result where name like \'孙%\';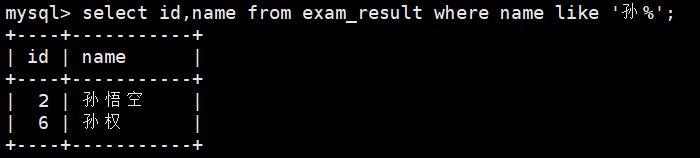
%表示可以匹配任意多字符。
7、孙某同学
select id,name from exam_result where name like \'孙_\';
_表示仅匹配一个字符。
8、语文成绩好于英语成绩的同学
select name,chinese,english from exam_result where chinese > english;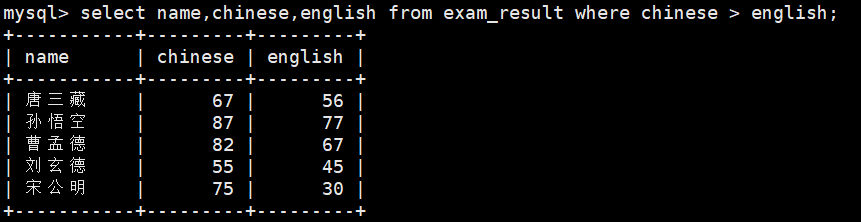
9、总分在 200 分以下的同学
select name,chinese+math+english from exam_result where chinese+math+english <200;
10、语文成绩 > 80 并且不姓孙的同学
select name,chinese from exam_result where chinese >80 and name not like \'孙%\';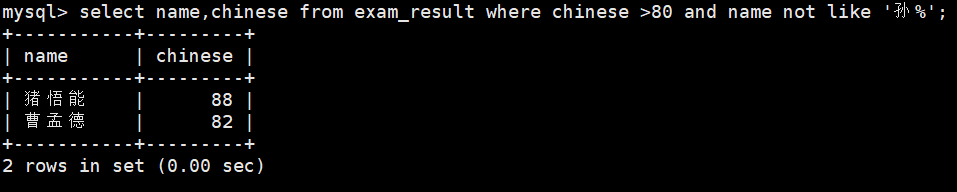
11、孙某同学,否则要求总成绩 > 200 并且 语文成绩 80
select name,chinese,math,english,chinese+math+english \'总分\' from exam_result where name like \'孙_\' or (chinese+math+english >200 and chinese <math and english > 80); 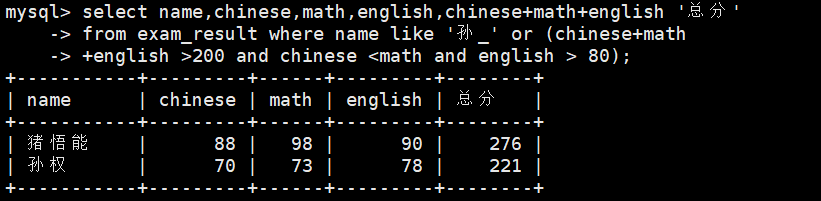
2.6 order by语句(结果排序)
- ASC 为升序(Ascending)(从小到大)
- DESC 为降序(Descending)(从大到小)
不做显示声明默认为 ASC方式排序并且没有order by子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
MySQL中认为NULL值是最小的
SELECT ... FROM table_name [WHERE ...]ORDER BY column [ASC|DESC], [...];、1、同学及数学成绩,按数学成绩升序显示
select name,math from exam_result order by math asc;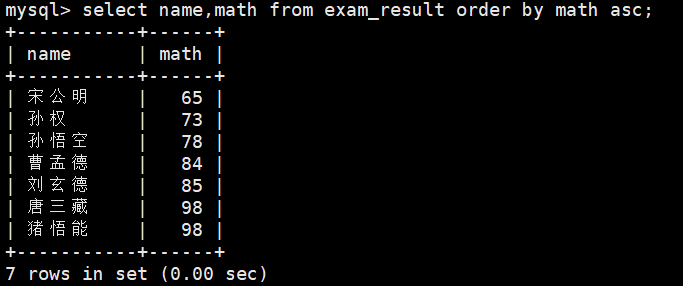
2、查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
SELECT name, math, english, chinese FROM exam_result ORDER BY math DESC, -- 数学降序 english ASC, -- 英语升序(默认可省略 ASC) chinese ASC; -- 语文升序(默认可省略 ASC)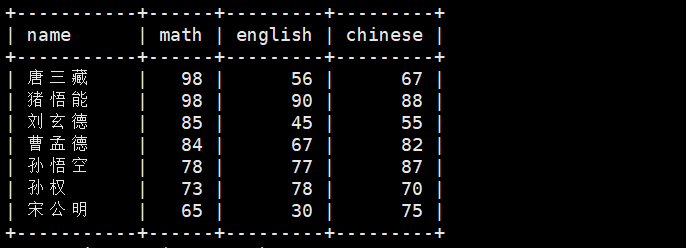
3、查询同学及总分,由高到低
select name,chinese+math+english total from exam_result order by chinese+math+english desc;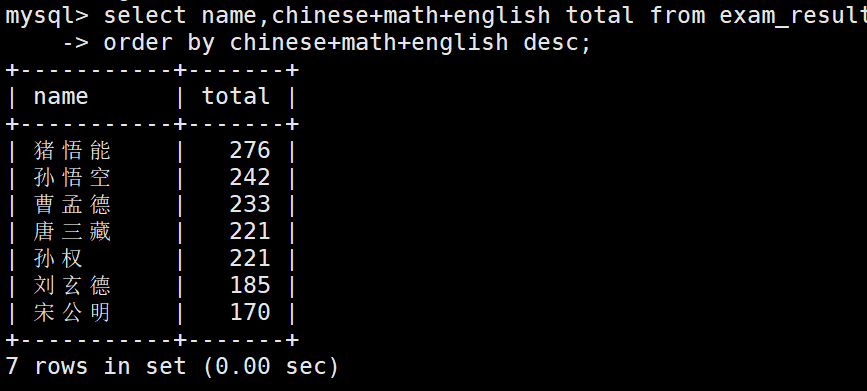
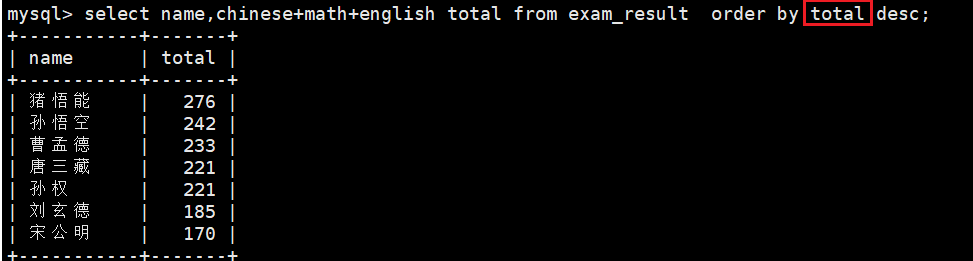
这种写法在标准sql中是不支持的,这里可以直接使用chinese+math+english的别名total进行排序操作,是因为该版本做了特殊处理,而在where的操作下则不被允许:

出现这种差异是因为sql语句的执行顺序造成的,where 子句在 select之前执行,此时 total 别名尚未生成,因此无法引用。
标准 SQL 执行顺序(理论上会报错)
- FROM exam_result
读取表数据。- WHERE(隐式)
无过滤条件,保留所有行。- 计算表达式
计算chinese + math + english,但此时未命名为total。- ORDER BY total DESC
报错:total是SELECT中定义的别名,此时尚未生效。
MySQL 的实际执行流程(允许
ORDER BY引用别名)
- FROM + 计算表达式
读取表数据,并计算chinese + math + english,暂存结果(未命名)。- ORDER BY total DESC
MySQL 允许ORDER BY引用尚未正式定义的别名,实际使用步骤 1 中暂存的计算结果进行排序。- SELECT name, … AS total
将排序后的结果命名为total,返回最终结果集。
可以对执行顺序理解为:1、from:先确定操作表 2、where:确定执行条件 3、根据执行条件去表中筛选
2.6 limit的使用(筛选分页结果)
select * from exam_result limit N;//N表示行数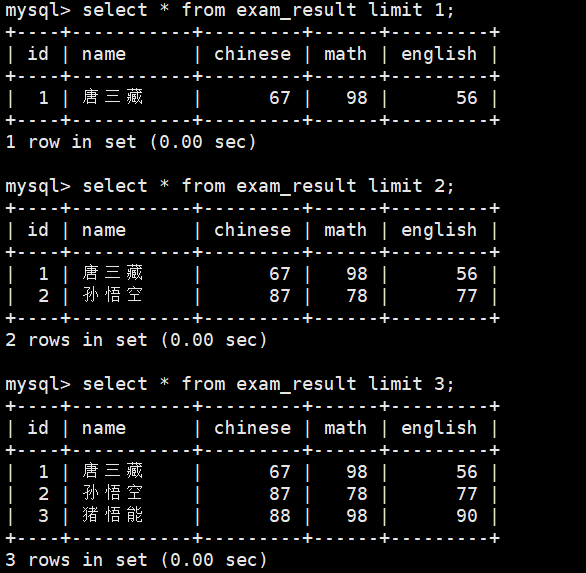
select * from exam_result limit pos,len;//从pos行开始,筛选len行数据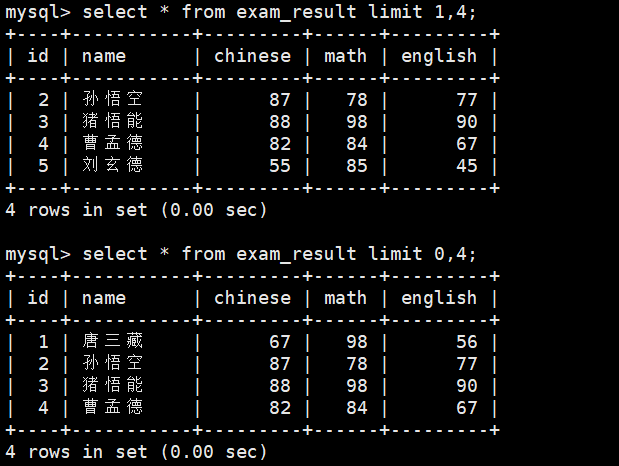
可以看出表中起始行的下标是从0位置开始的。
select * from exam_result limit len offset pos;//从pos位置开始获取len行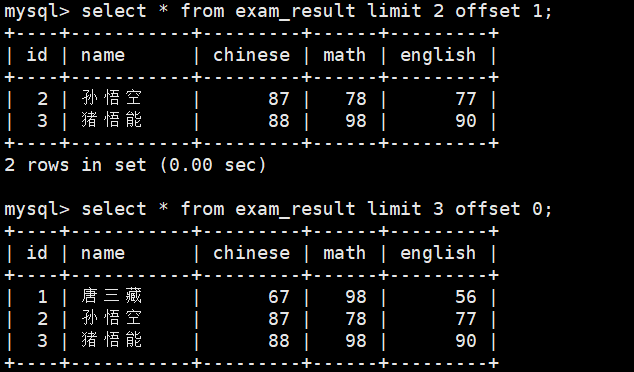
三、Update更新修改
UPDATE table_nameSET column1 = expr1, -- 要更新的列及值 column2 = expr2 -- 可同时更新多列[WHERE condition] -- 过滤条件(必加!避免全量更新)[ORDER BY column ASC/DESC] -- 可选:指定更新顺序[LIMIT row_count]; -- 可选:限制更新行数1、将孙悟空同学的数学成绩变更为 80 分
update exam_result set math=80 where name=\'孙悟空\';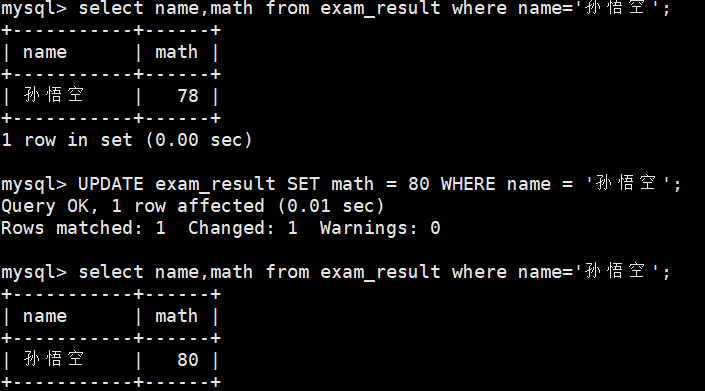
2、将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
update exam_result set math=60,chinese=70 where name=\'曹孟德\';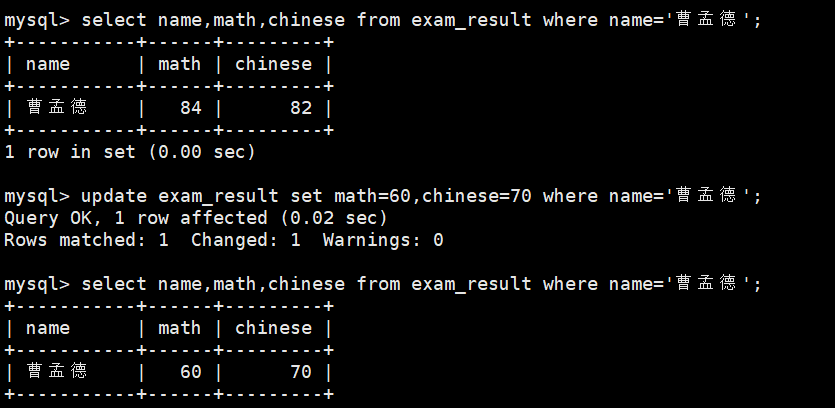
3、将所有同学的数学成绩+30分
update exam_result set math=math+30;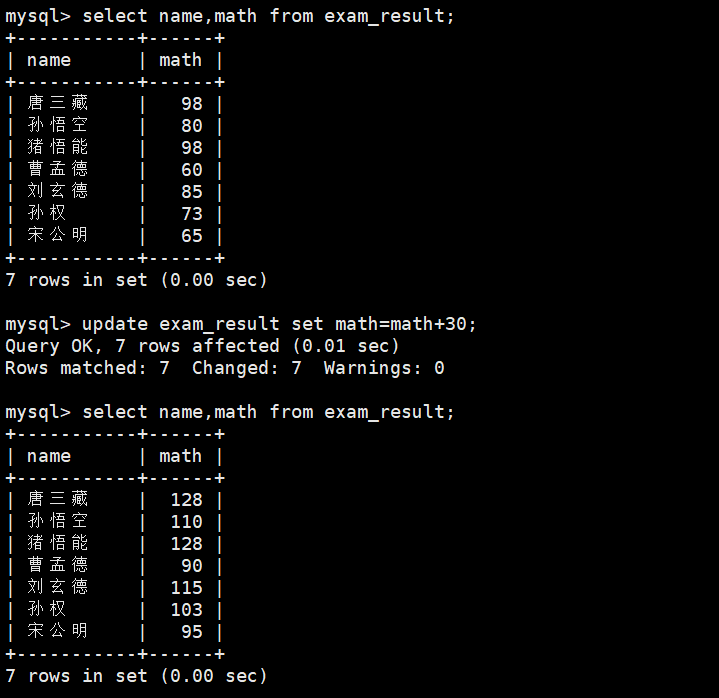
这里可以配合上面介绍的各种方法来完成操作,大家自己尝试吧
四、Delete删除
DELETE FROM table_name[WHERE condition] -- 过滤条件(必加!避免全量删除)[ORDER BY column ASC/DESC] -- 可选:指定删除顺序[LIMIT row_count]; -- 可选:限制删除行数1、删除孙悟空同学的考试成绩
delete from exam_result where name=\'孙悟空\';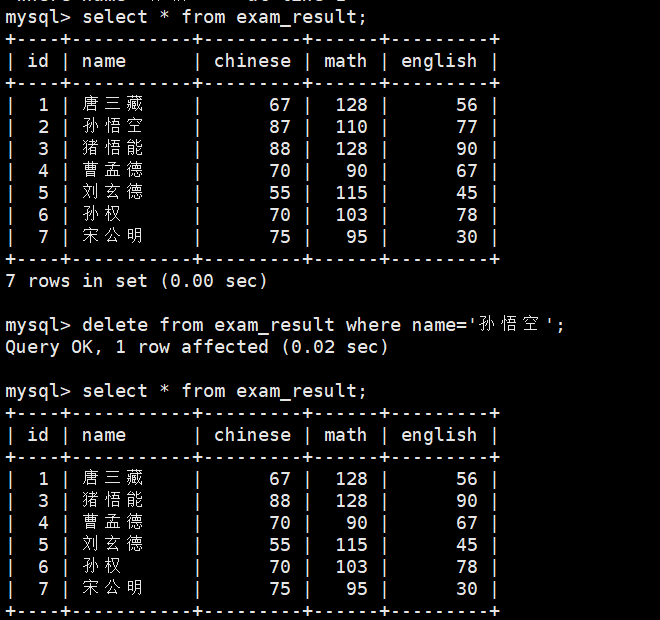
2、 删除整张表数据
准备测试表:
CREATE TABLE for_delete (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(20));INSERT INTO for_delete (name) VALUES (\'A\'), (\'B\'), (\'C\');delete from for_delete;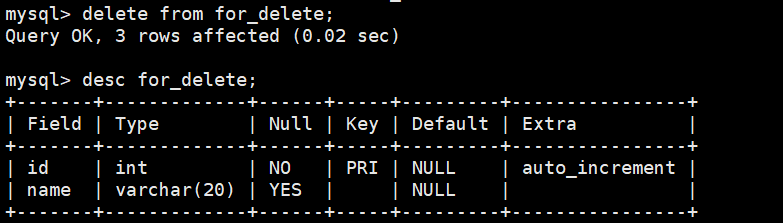
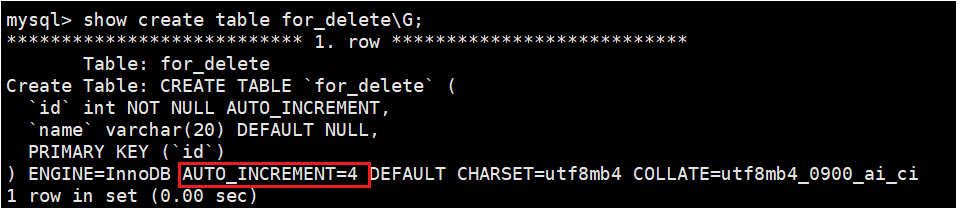
可以看到,当我们删除整张表达数据后,递增关键字并不会被重置。
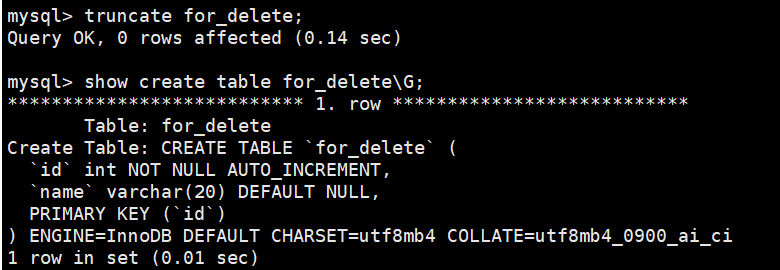
补充:截断表TRUNCATE
TRUNCATE [TABLE] table_name功能:彻底清空表中所有数据,保留表结构(列定义、索引、约束等)。
不同直接delete的是:
- 只能对整表操作,不能像 DELETE 一样可以针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE删除数据的时候,并不经过真正的事务,所以无法回滚。
- 会重置 AUTO_INCREMENT 项
- 并且不会记录日志 bin log
五、插入查询结果
在执行此类操作时我们需要保证,整个操作过程要么完全成功并生效,要么完全失败且不留下任何修改痕迹,绝对不允许出现 “部分完成” 的中间状,即原子性。
为什么需要保证原子性?
想象一个去重场景:假设表中有 1000 条重复数据,计划删除 900 条重复项。如果操作中途因停电、网络中断或 SQL 错误终止:
- 没有原子性保障: 可能只删除了 500 条,剩下 500 条重复数据未处理,导致数据处于 “半去重” 的混乱状态,后续难以恢复;
- 有原子性保障: 无论中途发生什么,数据库会自动回滚到操作前的状态,数据仍保持 1000 条重复数据,不会留下中间痕迹。
原子性的本质是 避免数据因意外中断而损坏,确保数据始终处于安全且可预期的状态。
INSERT INTO table_name [(column [, column ...])] SELECT ...示例:删除表中的的重复复记录,重复的数据只能有一份
如果在原表中直接操作,当碰到特殊情况(如:操作执行一般,断网、断电导致操作不完整,所有直接在原表中操作是不安全的)。
准备测试表CREATE TABLE duplicate_table (id int, name varchar(20));INSERT INTO duplicate_table VALUES(100, \'aaa\'),(100, \'aaa\'),(200, \'bbb\'),(200, \'bbb\'),(200, \'bbb\'),(300, \'ccc\');思路:
1、 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
CREATE TABLE no_duplicate_table LIKE duplicate_table;2、 将 duplicate_table 的去重数据插入到 no_duplicate_table
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;3、通过重命名表,实现原子的去重操作
RENAME TABLE duplicate_table TO old_duplicate_table,no_duplicate_table TO duplicate_table;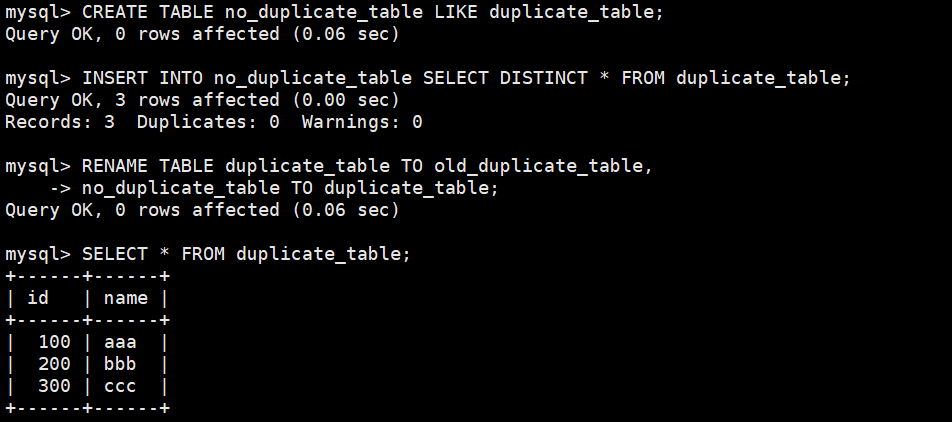
本篇文章就到这里了,余下内容放在下篇介绍,我会将文章链接补充在结尾处,肝文不易,三连回血!!!!!!
MySQL约束


