毕业设计 基于大数据B站数据分析项目
文章目录
- 0 数据分析目标
- 1 B站整体视频数据分析
-
- 1.1 数据预处理
- 1.2 数据可视化
- 1.3 分析结果
- 2 单一视频分析
-
- 2.1 数据预处理
- 2.2 数据清洗
- 2.3 数据可视化
- 3 文本挖掘(NLP)
-
- 3.1 情感分析
0 数据分析目标
今天向大家介绍如何使用大数据技术,对B站的视频数据进行分析,得到可视化结果。
这里学长分为两个部分描述:
- 1 对B站整体视频进行数据分析
- 2 对B站的具体视频进行弹幕情感分析
🧿 选题指导, 项目分享:见文末
1 B站整体视频数据分析
分析方向:首先从总体情况进行分析,之后分析综合排名top100的视频类别。
总体情况部分包括:
- 各分区播放量情况。
- 各区三连(硬币、收藏、点赞)情况。
- 弹幕、评论、转发情况。
- 绘制综合词云图,查看关键词汇。
综合排名top100部分包括:
5. top100类别占比。
6. top100播放量情况。
7. 硬币、收藏、点赞平均人数分布。
8. 各分区平均评论、弹幕、转发量情况。
1.1 数据预处理
这里主要是进行查看数据信息、空值、重复值以及数据类型,但由于数据很完整这里不再做过多操作。
对数据进行拆分、聚合,方便之后各项分析,由于“区类别”列中的“全站”是各分类中排名靠前的视频,会出现重复数据,因此对其进行去除。
df.info()df.isnull().count()df.nunique().count()df.dtypes#剔除全区排名df_nall=df.loc[df[\'区类别\']!=\'全站\']df_nall[\'区类别\'].value_counts()#按分数进行排序ascdf_top100 = df_nall.sort_values(by=\'分数\',ascending=False)[:100]df_type = df_nall.drop([\'作者\',\'视频编号\',\'标签名称\',\'视频名称\',\'排名\'],axis=1)gp_type = df_type.groupby(\'区类别\').sum().astype(\'int\')type_all = gp_type.index.tolist()1.2 数据可视化
各分区播放情况
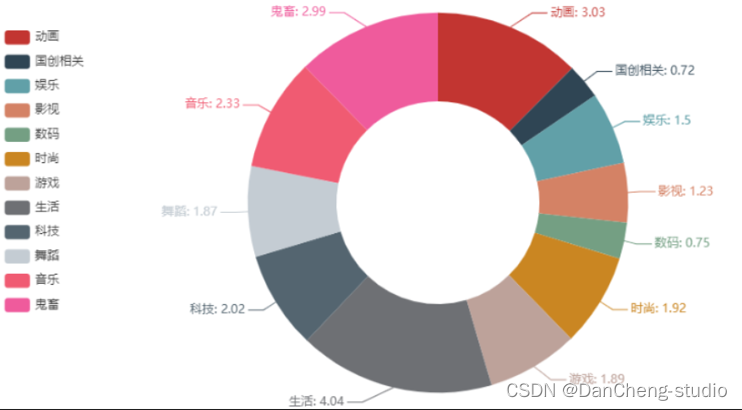
play = [round(i/100000000,2) for i in gp_type[\'播放次数\'].tolist()]# bar = (Bar()# .add_xaxis(type_all)# .add_yaxis(\"\", play)# .set_global_opts(# title_opts=opts.TitleOpts(title=\"各分区播放量情况\"),# yaxis_opts=opts.AxisOpts(name=\"次/亿\"),# xaxis_opts=opts.AxisOpts(name=\"分区\",axislabel_opts={\"rotate\":45})# )# )# bar.render_notebook()pie = ( Pie() .add( \"\", [list(z) for z in zip(type_all, play)], radius=[\"40%\", \"75%\"], ) .set_global_opts( title_opts=opts.TitleOpts(title=\"各分区播放量情况 单位:亿次\"), legend_opts=opts.LegendOpts( orient=\"vertical\", pos_top=\"15%\", pos_left=\"2%\" ), ) .set_series_opts(label_opts=opts.LabelOpts(formatter=\"{b}: {c}\")))pie.render_notebook()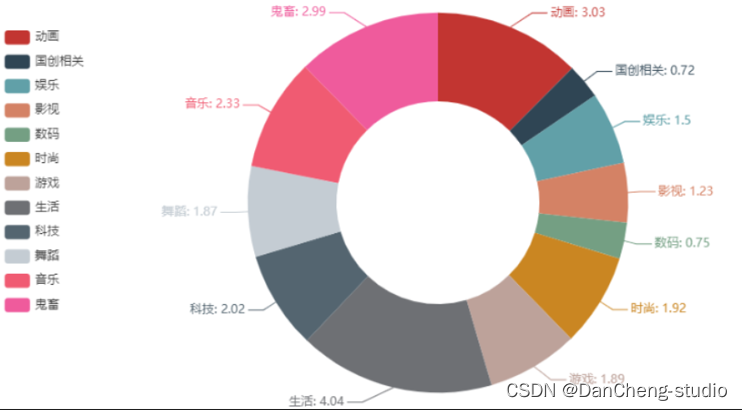
播放量排名前三的分别是生活类、动画类、鬼畜类。其中动画类和鬼畜类,这两个是B站的特色。
第三、四位是音乐类和科技类。
各区三连量情况可视化
coin_all = [round(i/1000000,2) for i in gp_type[\'硬币数\'].tolist()]like_all = [round(i/1000000,2) for i in gp_type[\'点赞数\'].tolist()]favourite_all = [round(i/1000000,2) for i in gp_type[\'喜欢人数\'].tolist()]def bar_base() -> Bar: c = ( Bar() .add_xaxis(type_all) .add_yaxis(\"硬币\", coin_all) .add_yaxis(\"点赞\", like_all) .add_yaxis(\"收藏\", favourite_all) .set_global_opts(title_opts=opts.TitleOpts(title=\"各分区三连情况\"), yaxis_opts=opts.AxisOpts(name=\"次/百万\"), xaxis_opts=opts.AxisOpts(name=\"分区\", axislabel_opts={\"rotate\":45})) ) return c bar_base().render_notebook()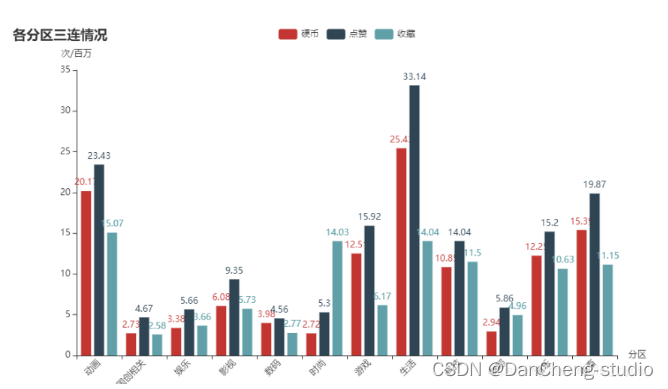
虽然生活类投币和点赞数依然是不可撼动的,但是收藏数却排在动画之后,科技类收藏升至第四位。
弹幕、评论、三联情况
danmaku_all = [round(i/100000,2) for i in gp_type[\'弹幕数\'].tolist()]reply_all = [round(i/100000,2) for i in gp_type[\'评论数\'].tolist()]share_all = [round(i/100000,2) for i in gp_type[\'转发数\'].tolist()]line = ( Line() .add_xaxis(type_all) .add_yaxis(\"弹幕\", danmaku_all,label_opts=opts.LabelOpts(is_show=False)) .add_yaxis(\"评论\", reply_all,label_opts=opts.LabelOpts(is_show=False)) .add_yaxis(\"转发\", share_all,label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( title_opts=opts.TitleOpts(title=\"弹幕、评论、转发情况\"), tooltip_opts=opts.TooltipOpts(trigger=\"axis\", axis_pointer_type=\"cross\"), yaxis_opts=opts.AxisOpts(name=\"人数 单位:十万\"), xaxis_opts=opts.AxisOpts(name=\"时间(日)\",axislabel_opts={\"rotate\":45}) ) )line.render_notebook()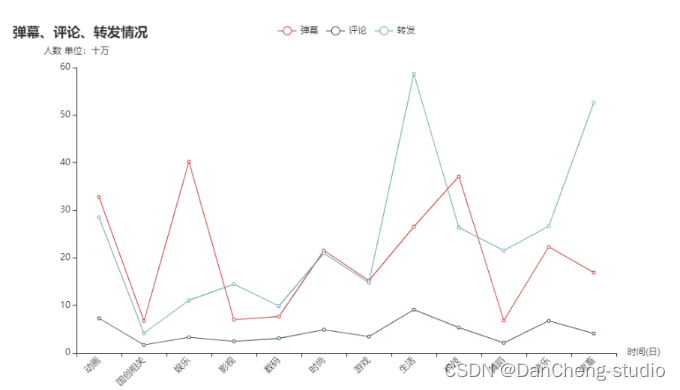
B站搜索词云图
tag_list=\',\'.join(df_nall[\'标签名称\']).split(\',\')tags_count=pd.Series(tag_list).value_counts()wordcloud = ( WordCloud() .add(\"\", [list(z) for z in zip(tags_count.index,tags_count)], word_size_range=[10, 100]) .set_global_opts(title_opts=opts.TitleOpts(title=\"热门标签\")))wordcloud.render_notebook()
硬币、收藏、点赞平均人数分布
gp_triple_quality = df_top100.groupby(\'区类别\')[[\'硬币数\',\'喜欢人数\',\'点赞数\',]].mean().astype(\'int\')gp_index = gp_triple_quality.index.tolist()gp_coin = gp_triple_quality[\'硬币数\'].values.tolist()gp_favorite = gp_triple_quality[\'喜欢人数\'].values.tolist()gp_like = gp_triple_quality[\'点赞数\'].values.tolist()max_num = max(gp_triple_quality.values.reshape(-1))def radar_base() -> Radar: c = ( Radar() .add_schema( schema=[ opts.RadarIndicatorItem(name=gp_index[0], max_=600000), opts.RadarIndicatorItem(name=gp_index[1], max_=600000), opts.RadarIndicatorItem(name=gp_index[2], max_=600000), opts.RadarIndicatorItem(name=gp_index[3], max_=600000), opts.RadarIndicatorItem(name=gp_index[4], max_=600000), opts.RadarIndicatorItem(name=gp_index[5], max_=600000), opts.RadarIndicatorItem(name=gp_index[6], max_=600000), opts.RadarIndicatorItem(name=gp_index[7], max_=600000), opts.RadarIndicatorItem(name=gp_index[8], max_=600000),] ) .add(\"硬币数\", [gp_coin],color=\'#40e0d0\') .add(\"喜欢人数\", [gp_favorite],color=\'#1e90ff\') .add(\"点赞数\", [gp_like],color=\'#b8860b\') .set_series_opts(label_opts=opts.LabelOpts(is_show=False), linestyle_opts=opts.LineStyleOpts(width=3,type_=\'dotted\'),) .set_global_opts(title_opts=opts.TitleOpts(title=\"硬币、收藏、点赞平均人数分布\")) ) return cradar_base().render_notebook()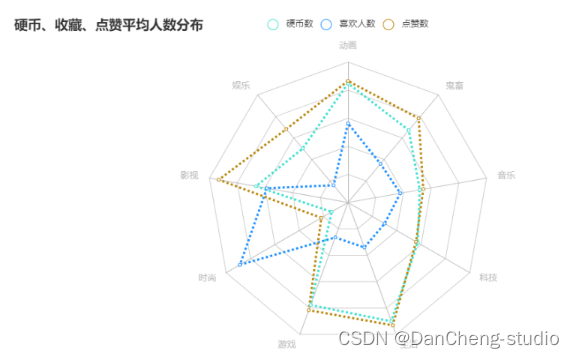
生活区的平均投币和点赞量依然高于动画区。投币、点赞、收藏最高的分区分别是:生活、影视、时尚。除了时尚区外,其他分区的收藏量均低于投币和点赞,且时尚区的收藏量是远高其点赞和投币量。
1.3 分析结果
从数据可视化中可以看到,播放量排名前三的分别是生活类、动画类、鬼畜类,让人诧异的是以动漫起家的B站,播放量最多的视频分类竟然是生活类节目。
对比总体各分类播放情况,top100各类占比基本保持不变。生活类的平均投币和点赞量依然高于动画类。投币、点赞、收藏最高的分区分别是:生活、影视、时尚。除了时尚区外,其他分区的收藏量均低于投币和点赞,且时尚区的收藏量是远高其点赞和投币量。
2 单一视频分析
2.1 数据预处理
B站爬虫代码Demo
import requests,csv,timeimport sysfrom bs4 import BeautifulSoup as BS\'\'\'获取网页内容\'\'\'def request_get_comment(url): headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)\', \'Cookie\': \'LIVE_BUVID=AUTO7215383727315695; stardustvideo=1; rpdid=kwxwwoiokwdoskqkmlspw; \' \'fts=1540348439; sid=alz55zmj; CURRENT_FNVAL=16; _uuid=08E6859E-EB68-A6B3-5394-65272461BC6E49706infoc; \' \'im_notify_type_64915445=0; UM_distinctid=1673553ca94c37-0491294d1a7e36-36664c08-144000-1673553ca956ac; \' \'DedeUserID=64915445; DedeUserID__ckMd5=cc0f686b911c9f2d; SESSDATA=7af19f78%2C1545711896%2Cb812f4b1; \' \'bili_jct=dc9a675a0d53e8761351d4fb763922d5; BANGUMI_SS_5852_REC=103088; \' \'buvid3=AE1D37C0-553C-445A-9979-70927B6C493785514infoc; finger=edc6ecda; CURRENT_QUALITY=80; \' \'bp_t_offset_64915445=199482032395569793; _dfcaptcha=44f6fd1eadc58f99515d2981faadba86\'} response = requests.get(url=url,headers=headers) soup = BS(response.text.encode(response.encoding).decode(\'utf8\'),\'lxml\') result = soup.find_all(\'d\') if len(result) == 0: return result all_list = [] for item in result: barrage_list = item.get(\'p\').split(\",\") barrage_list.append(item.string) barrage_list[4] = time.ctime(eval(barrage_list[4])) all_list.append(barrage_list) return all_list\'\'\'将秒转化为固定格式:\"时:分:秒\"\'\'\'def sec_to_str(second): second = eval(second) m,s = divmod(second,60) h,m = divmod(m,60) dtEventTime = \"%02d:%02d:%02d\" % (h,m,s) return dtEventTime\'\'\'主函数\'\'\'def main(): sys.setrecursionlimit(1000000) url_list = [] cid_list = [16980576,16980597,16548432,16483358,16740879,17031320, 17599975,18226264,17894824,18231028,18491877,18780374] tableheader = [\'弹幕出现时间\', \'弹幕格式\', \'弹幕字体\', \'弹幕颜色\', \'弹幕时间戳\', \'弹幕池\',\'用户ID\',\'rowID\',\'弹幕信息\'] \'\'\'最新弹幕文件\'\'\' for i in range(12): url = \"https://comment.bilibili.com/%d.xml\" % cid_list[i] url_list.append(url) file_name = \"now{}.csv\".format(i + 1) with open(file_name,\'w\',newline=\'\',errors=\'ignore\') as fd: comment = request_get_comment(url) writer = csv.writer(fd) # writer.writerow(tableheader) if comment: for row in comment: print(row) #writer.writerow(row) del comment \'\'\'按照集数,取出弹幕链接,进行爬虫,获取弹幕记录,并保存到csv文件\'\'\' for i in range(12): file_name = \"d{}.csv\".format(i+1) for j in range(1,13): for date in range(2): barrage_url = first_barrage_url.format(cid_list[i],\"%02d\" % j,\"%02d\" % (1 + date * 14)) with open(file_name,\'a\',newline=\'\',errors=\'ignore\') as fd : writer = csv.writer(fd) writer.writerow(tableheader) final_list = request_get_comment(barrage_url) if final_list: for row in final_list: writer.writerow(row) del (final_list)if __name__ == \"__main__\": main()2.2 数据清洗
导入数据分析库
#数据处理库import numpy as npimport pandas as pdimport globimport reimport jieba#可视化库import stylecloudimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlinefrom pyecharts.charts import *from pyecharts import options as optsfrom pyecharts.globals import ThemeType from IPython.display import Image#文本挖掘库from snownlp import SnowNLPfrom gensim import corpora,models合并弹幕数据
csv_list = glob.glob(\'/danmu/*.csv\')print(\'共发现%s个CSV文件\'% len(csv_list))print(\'正在处理............\')for i in csv_list: fr = open(i,\'r\').read() with open(\'danmu_all.csv\',\'a\') as f: f.write(fr)print(\'合并完毕!\')重复值、缺失值等处理
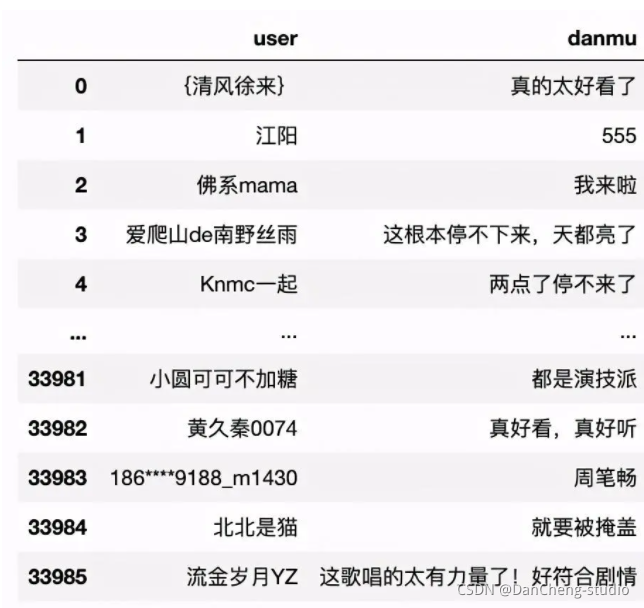
#error_bad_lines参数可忽略异常行df = pd.read_csv(\"./danmu_all.csv\",header=None,error_bad_lines=False)df = df.iloc[:,[1,2]] #选择用户名和弹幕内容列df = df.drop_duplicates() #删除重复行df = df.dropna() #删除存在缺失值的行df.columns = [\"user\",\"danmu\"] #对字段进行命名清洗后数据如下所示:
数据去重
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如\"啊啊啊啊啊\"这种数据,而实际做情感分析时,只需要一个“啊”即可。

#定义机械压缩去重函数def yasuo(st): for i in range(1,int(len(st)/2)+1): for j in range(len(st)): if st[j:j+i] == st[j+i:j+2*i]: k = j + i while st[k:k+i] == st[k+i:k+2*i] and k<len(st): k = k + i st = st[:j] + st[k:] return styasuo(st=\"啊啊啊啊啊啊啊\")应用以上函数,对弹幕内容进行句内去重。
df[\"danmu\"] = df[\"danmu\"].apply(yasuo)特殊字符过滤
另外,我们还发现有些弹幕内容包含表情包、特殊符号等,这些脏数据也会对情感分析产生一定影响。

特殊字符直接通过正则表达式过滤,匹配出中文内容即可。
df[\'danmu\'] = df[\'danmu\'].str.extract(r\"([\\u4e00-\\u9fa5]+)\")df = df.dropna() #纯表情直接删除另外,过短的弹幕内容一般很难看出情感倾向,可以将其一并过滤。
df = df[df[\"danmu\"].apply(len)>=4]df = df.dropna()2.3 数据可视化
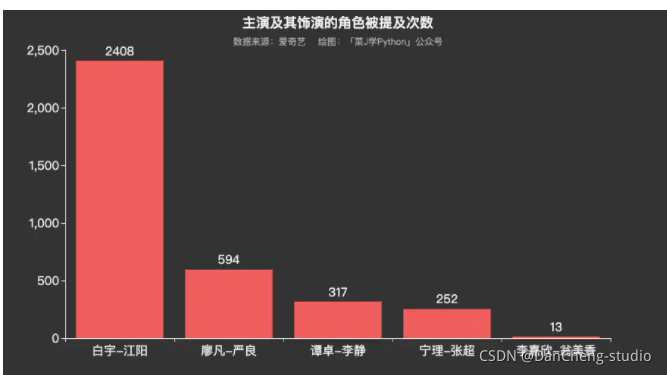
数据可视化分析部分代码本公众号往期原创文章已多次提及,本文不做赘述。从可视化图表来看,网友对《沉默的真相》还是相当认可的,尤其对白宇塑造的正义形象江阳,提及频率远高于其他角色。
整体弹幕词云

主演提及
3 文本挖掘(NLP)
3.1 情感分析
情感分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。
df[\'score\'] = df[\"danmu\"].apply(lambda x:SnowNLP(x).sentiments)df.sample(10) #随机筛选10个弹幕样本数据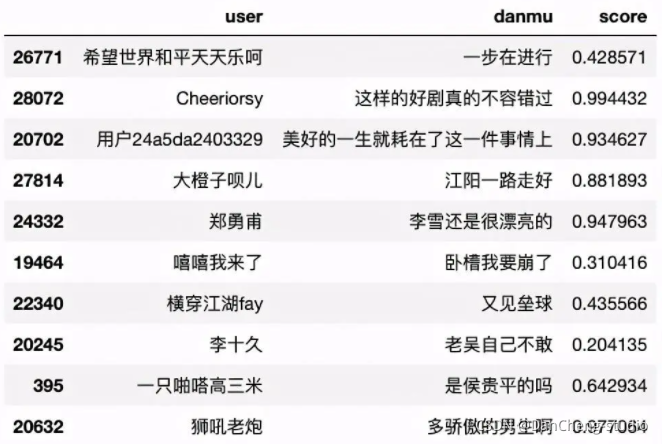
整体情感倾向
plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 设置加载的字体名plt.rcParams[\'axes.unicode_minus\'] = False # 解决保存图像是负号\'-\'显示为方块的问题plt.figure(figsize=(12, 6)) #设置画布大小rate = df[\'score\']ax = sns.distplot(rate, hist_kws={\'color\':\'green\',\'label\':\'直方图\'}, kde_kws={\'color\':\'red\',\'label\':\'密度曲线\'}, bins=20) #参数color样式为salmon,bins参数设定数据片段的数量ax.set_title(\"弹幕整体情感倾向 绘图:「菜J学Python」公众号\")plt.show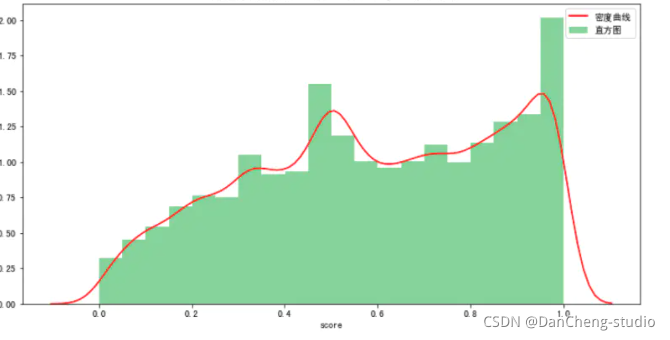
观众对主演的情感倾向
mapping = {\'jiangyang\':\'白宇|江阳\', \'yanliang\':\'廖凡|严良\', \'zhangchao\':\'宁理|张超\',\'lijing\':\'谭卓|李静\', \'wengmeixiang\':\'李嘉欣|翁美香\'}for key, value in mapping.items(): df[key] = df[\'danmu\'].str.contains(value)average_value = pd.Series({key: df.loc[df[key], \'score\'].mean() for key in mapping.keys()})print(average_value.sort_values())由各主要角色情感得分均值可知,观众对他们都表现出积极的情感。翁美香和李静的情感得分均值相对高一些,难道是男性观众偏多?江阳的情感倾向相对较低,可能是观众对作为正义化身的他惨遭各种不公而鸣不平吧。

主题分析
这里的主题分析主要是将弹幕情感得分划分为两类,分别为积极类(得分在0.8以上)和消极类(得分在0.3以下),然后再在各类里分别细分出5个主题,有助于挖掘出观众情感产生的原因。
首先,筛选出两大类分别进行分词。
#分词data1 = df[\'danmu\'][df[\"score\"]>=0.8]data2 = df[\'danmu\'][df[\"score\"]<0.3]word_cut = lambda x:\' \'.join(jieba.cut(x)) #以空格隔开data1 = data1.apply(word_cut)data2 = data2.apply(word_cut)print(data1)print(\'----------------------\')print(data2)123456789首先,筛选出两大类分别进行分词。#去除停用词stop = pd.read_csv(\"/菜J学Python/stop_words.txt\",encoding=\'utf-8\',header=None,sep=\'tipdm\')stop = [\' \',\'\'] + list(stop[0])#print(stop)pos = pd.DataFrame(data1)neg = pd.DataFrame(data2)pos[\"danmu_1\"] = pos[\"danmu\"].apply(lambda s:s.split(\' \'))pos[\"danmu_pos\"] = pos[\"danmu_1\"].apply(lambda x:[i for i in x if i.encode(\'utf-8\') not in stop])#print(pos[\"danmu_pos\"])neg[\"danmu_1\"] = neg[\"danmu\"].apply(lambda s:s.split(\' \'))neg[\"danmu_neg\"] = neg[\"danmu_1\"].apply(lambda x:[i for i in x if i.encode(\'utf-8\') not in stop])其次,对积极类弹幕进行主题分析。
#正面主题分析pos_dict = corpora.Dictionary(pos[\"danmu_pos\"]) #建立词典#print(pos_dict)pos_corpus = [pos_dict.doc2bow(i) for i in pos[\"danmu_pos\"]] #建立语料库pos_lda = models.LdaModel(pos_corpus,num_topics=5,id2word=pos_dict) #LDA模型训练print(\"正面主题分析:\")for i in range(5): print(\'topic\',i+1) print(pos_lda.print_topic(i)) #输出每个主题 print(\'-\'*50)结果如下:

最后,对消极类弹幕进行主题分析。
#负面主题分析neg_dict = corpora.Dictionary(neg[\"danmu_neg\"]) #建立词典#print(neg_dict)neg_corpus = [neg_dict.doc2bow(i) for i in neg[\"danmu_neg\"]] #建立语料库neg_lda = models.LdaModel(neg_corpus,num_topics=5,id2word=neg_dict) #LDA模型训练print(\"负面面主题分析:\")for j in range(5): print(\'topic\',j+1) print(neg_lda.print_topic(j)) #输出每个主题 print(\'-\'*50)结果如下:

🧿 项目分享:大家可自取用于参考学习,获取方式见文末!

