DeepSeek-V3:理解并本地运行最佳开源 LLM_deepseek v3 int4

DeepSeek-V3 是最优秀的开源 LLMs 之一,在多项任务中表现优于大多数其他模型。尽管拥有 6710 亿参数,你可能会认为它需要多个 GPU 节点才能运行,即使在昂贵硬件上速度也会非常缓慢。然而实际上,DeepSeek-V3 的运行速度比 Llama 3.3(700 亿参数)和 Qwen2.5(720 亿参数)等小型模型快得多。
那么,DeepSeek-V3 如何在如此庞大的规模下仍能保持高效?
本文将解释 DeepSeek-AI 如何实现这一突破。他们在早期工作 DeepSeek 和 DeepSeek-V2 的基础上,采用了一种特殊的专家混合模型架构,包含多个小型专家模型、若干共享专家以及多头潜在注意力机制。同时通过训练模型使用 FP8 精度,使其内存效率远超同类规模模型。
我们还将探讨运行 DeepSeek-V3 所需的硬件配置。
DeepSeek-V3:庞大而高效的混合专家模型
DeepSeek-AI 发布了一份详尽的技术报告,阐述了模型训练过程及其架构设计:
DeepSeek-V3 Technical Report
DeepSeek-V3 的核心组件(如 DeepSeekMoE 和多头潜在注意力机制 MLA)最初在 DeepSeek-V2 中提出。这些设计旨在确保即便参数量巨大,推理过程仍能保持高速且内存高效。
这个架构最令我欣赏之处在于,它巧妙融合了前沿研究的诸多创新理念与精妙的工程技巧。这种既智能又实用的设计方案成效显著,下图对此作了完美诠释:
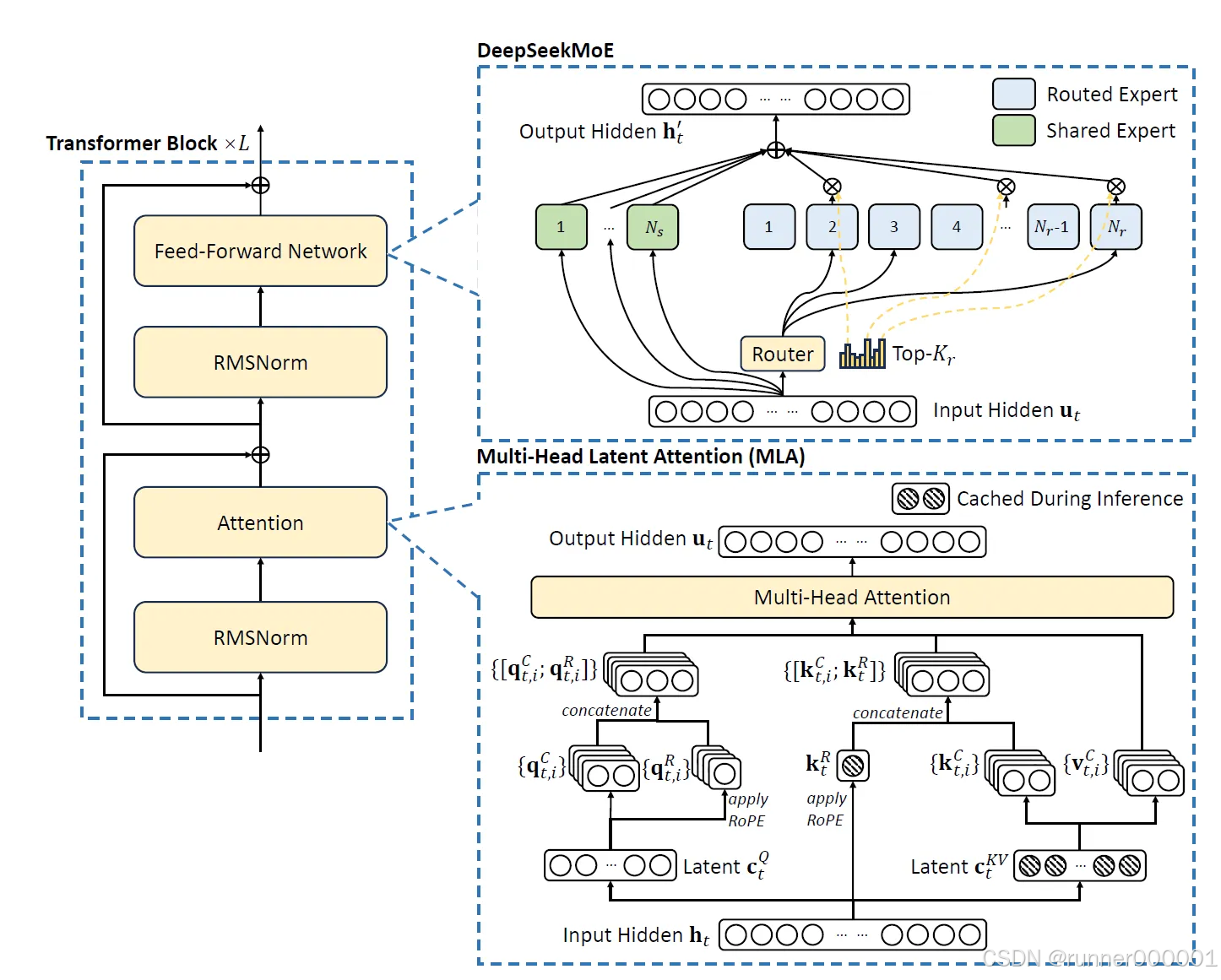
理解多头潜在注意力机制
多头潜在注意力是一种优化的注意力机制。它在保持与标准多头注意力(MHA)相当性能的同时,提升了内存效率。其主要优势之一是能显著降低推理过程中的内存消耗——这种消耗通常源于需要为序列中的每个标记存储所有键值对。
MLA 的核心思想是在生成键和值之前,将输入嵌入压缩到低维潜在空间。注:严格来说,这并非 KV 缓存的量化操作。
对于每个输入 token,它的 embedding(向量表示)首先会通过一个降维投影(down-projection)映射到一个低维潜在空间(compressed latent space)。这个过程相当于减少信息的维度,用更紧凑的向量来表示输入,从而减少内存开销。接着,模型会使用一个上投影(up-projection)操作,从这个低维的表示中“重建”出用于多头注意力机制的 Key 和 Value 向量。这样做的核心思想是:不用缓存全尺寸的 Key/Value,只缓存低维的 latent 表示,在用的时候再还原。Key 向量还会加入位置编码信息。具体做法是:再通过一个额外的 projection(投影)应用 RoPE(旋转位置编码),这是一种可与向量乘法兼容的位置编码方式,非常适合 transformer。
同样地,注意力机制中使用的 Query 向量 也会被压缩到潜在空间中。这种做法通过限制需要存储的激活值(即推理过程中产生的张量)的大小,从而在训练期间减少内存占用。之后,在执行注意力计算时,Query 会从压缩后的表示中重建出来。
在完成压缩后的查询、键和值的计算与重构后,它们将被用于计算注意力输出。查询与键用于生成注意力权重,该权重随后作用于值以生成每个注意力头的输出。这些输出经过拼接和投影处理,最终生成该词元的注意力输出结果。
MLA 实现了显著的内存节省,因为在推理过程中仅存储键和值的压缩潜在表示以及位置键。
相比标准的多头注意力机制(MHA)需要缓存所有 token 的键值对,这是一个重大改进。尽管进行了这些优化,MLA 仍能通过从压缩表示中精确重建必要信息,保持与标准注意力机制相当的性能。这使得它特别适合需要长序列处理或高效推理的应用场景。

共享与微型专家结合的 DeepSeekMoE
在 DeepSeek 模型中,前馈神经网络(FFN)采用了先进的 DeepSeekMoE 架构,该架构最初在 DeepSeek(V1)中提出。该架构通过更精细的专家划分,实现了更好的专业化能力和更高效的知识获取;同时还引入了共享专家机制,以减少路由专家之间的冗余。据 DeepSeek-AI 所说,这种架构提升了知识分布的合理性以及专家的利用率。从他们公布的结果来看,这一点似乎得到了验证。DeepSeekMoE 相较于传统的混合专家架构(MoE)实现了显著改进,但据我所知,自该架构提出以来尚未被应用于其他模型。
为解决混合专家模型(MoE)在多 GPU 硬件配置中的通信开销问题,DeepSeek 采用了设备受限的路由机制。在使用专家并行的场景下,被路由的专家会分布在多个设备上,每个令牌的通信成本取决于其目标专家跨越的设备数量。这种设计确保了在推理和训练过程中实现更高效的跨设备通信。由于 DeepSeek 模型规模庞大,其设计初衷就是在多 GPU 环境下运行,因此这一机制对其推理效率至关重要。
不同于传统 MoE(专家混合)架构中使用的简单 Top-K 选择机制,DeepSeek 的路由机制引入了一个额外的约束:每个 token 的目标专家最多只能分布在 M 个设备上。
具体流程是:首先,系统会选出在该 token 上亲和度(affinity score)最高的 前 M 个设备;
然后,仅在这 M 个设备内部,执行 Top-K 选择,以确定最终的专家分配。这种做法显著降低了通信开销,同时还能保持高性能表现。
为进一步提升效率,DeepSeek 整合了辅助损失函数来管理负载均衡并防止路由崩溃——这种状况会导致部分专家模块利用率不足,从而引发计算效率低下的问题。目前已实现三类辅助损失函数来实现这一目标:
1、专家级均衡损失(Expert-Level Balance Loss) 用于实现 token 在各个专家之间的公平分配。它通过计算 token 与专家之间的亲和度,并引入一个平衡因子,以促进负载的均匀分布。
2、设备级均衡损失(Device-Level Balance Loss) 用于平衡各个设备之间的计算负载。
它通过将专家划分为多个组,并将这些组分布在不同设备上,从而确保没有某一台设备成为性能瓶颈。
3、通信平衡损失(Communication Balance Loss) 通过均衡每个设备处理的 token 数量,解决入站通信中的不平衡问题,从而最大限度地减少通信延迟。
为了应对负载不均的问题,DeepSeek 在训练过程中引入了一种设备级的 token 丢弃策略。
该方法会为每个设备计算其计算预算,并优先丢弃亲和度最低的 token,直到满足预算限制为止。
为了保持训练与推理阶段的一致性,大约 10% 的训练序列会不进行 token 丢弃。这种策略提供了灵活性:在注重效率的推理场景中可以启用 token 丢弃;而在需要完整 token 处理以追求高性能的场景中,也能保持良好表现。
Multi-Token Prediction
DeepSeek-V3 中的多令牌预测(MTP)是一种受前人工作启发的训练目标,它能同时预测多个未来令牌,而非每次仅聚焦单个令牌。这种方法通过让模型在单次前向传播中处理并学习多个未来令牌预测,从而增强了训练信号的密度并提升了数据利用效率。
MTP 机制按顺序而非并行预测额外的未来令牌。与早期使用独立输出头同时预测多个令牌的方法不同,DeepSeek-V3 在每次预测深度时都保持完整的因果链。每个额外令牌的预测都依赖于前序步骤的令牌及预测结果,从而保持输出的因果结构。
MTP 的实现包含一系列模块,每个模块设计用于在特定深度预测一个额外标记。每个模块包含共享的嵌入层、共享的输出头、深度特定的 Transformer 块以及投影矩阵。在每一深度,来自前一深度的当前标记表示会与序列中下一个标记的嵌入相结合。这些表示被拼接并投影为新的表示,作为该深度 Transformer 块的输入。随后,Transformer 块处理该输入以生成当前深度的输出表示。该输出被共享输出头用于计算此深度预测标记的概率分布。
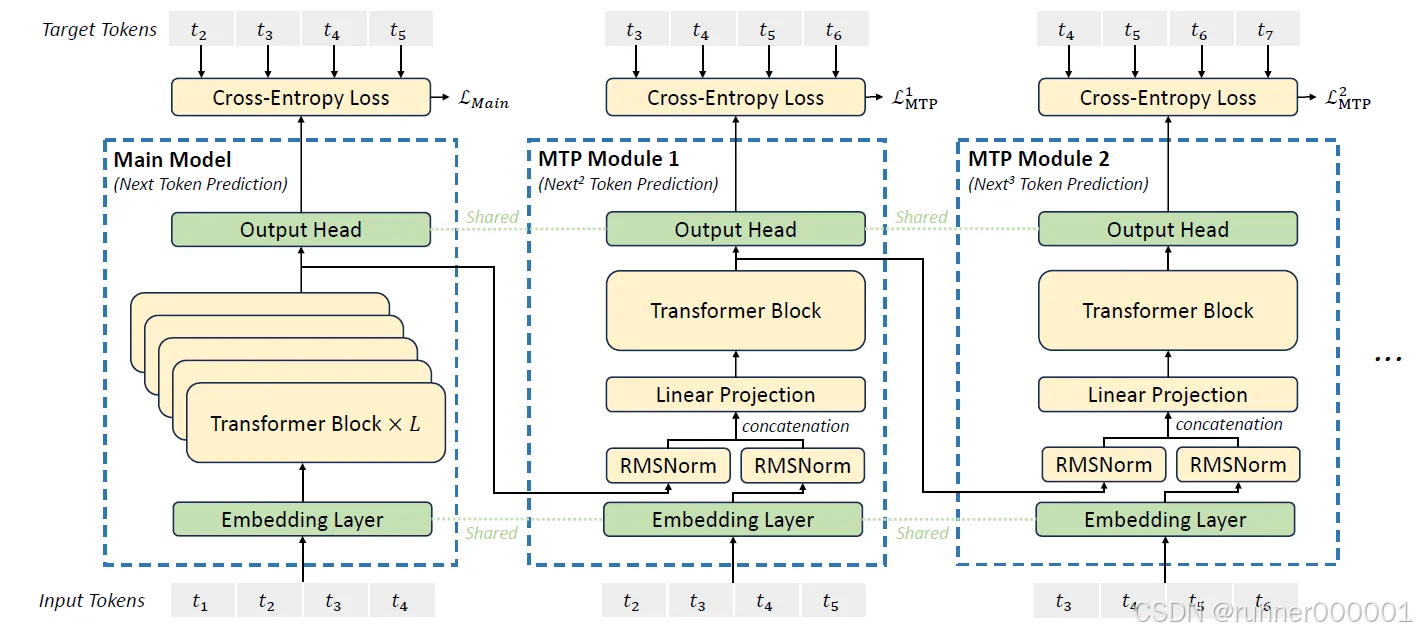
MTP 训练目标采用交叉熵损失函数评估每一深度的预测结果。针对每个深度,模型会将下一标记的预测概率与序列中的真实标记进行比对,并计算损失值。最终 MTP 总损失通过加权平均所有预测深度的损失值获得,其中应用了特定的权重系数。该损失函数作为训练过程中的附加目标,对主模型的核心训练目标形成补充。
在推理过程中,MTP 模块并非正常运行所必需,可以移除。不过,这些 MTP 模块也可重新用于推测性解码,通过利用早期深度的预测结果来预计算后续步骤,从而提高生成速度。
DeepSeek V3 的 GPU 需求
根据 DeepSeek-AI 官方信息,该模型拥有 6710 亿参数。但 Hugging Face 上的模型卡片显示其参数规模略大,达到 6850 亿:
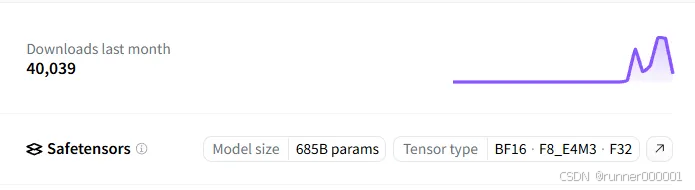
这并没有太大区别。无论如何,该模型都需要消耗大量内存。但由于模型原生支持 FP8 格式,意味着每 10 亿参数仅占用 1GB 内存。因此我们需要 671GB 内存来加载模型,例如配置 4 块 AMD MI300X、9 块 H100 GPU 或 5 块 H200。
最新款 GPU(如 H100 和 H200)已针对 FP8 快速处理进行了专门优化。
模型加载完成后,推理过程需要额外内存支持
要实现高效运行模型,可选的配置方案包括:
-
6 块 MI300X:最具性价比但依赖 AMD 软件支持,可能与某些框架兼容性欠佳
-
12 至 16 块 H100:这是较优替代方案,但多数配置需要多个 GPU 节点(目前尚未见到单机搭载超过 8 块 H100 的设备,如有相关案例欢迎在评论区补充)。多节点部署会因机器间同步需求而增加推理耗时
-
8 张 H200 显卡:这是最昂贵但也最快速且实用的选择。仅需一个配备 8 张 H200 的节点即可运行该模型。
我会选择配备 8 块 H200 的配置。
本地运行 DeepSeek-V3 是否可行?
关于 FP8 版本
虽然技术上可行,但需配备 GPU 节点。考虑到当前单台配备 8 块 H200 显卡的节点售价高达 26 万美元(且供货紧张),云服务显然是更具性价比的选择。
SGLang 和 vLLM 均支持 FP8 模型。
我对 SGLang 的经验较少(但它是个不错的框架)。使用 vLLM 时,我们必须向引擎传递以下参数以实现分布式推理:
-
tensor_parallel_size = 8(如果你有 8 块 GPU)
-
pipeline_parallel_size = 2(如果你有两个节点)
若单个节点具有足够内存(例如使用 8 块 H200),你可以用这个引擎配置运行模型:
llm = LLM(model=\"deepseek-ai/DeepSeek-V3\", tensor_parallel_size=8)如果你有多个 GPU 节点,例如 2 个节点,每个节点配备 8 块 H100 显卡,你可以在张量并行之外实现流水线并行:
llm = LLM(model=\"deepseek-ai/DeepSeek-V3\", tensor_parallel_size=8, pipeline_parallel_size=2)对于 INT4 版本,采用 AutoRound 进行量化
企业 AI 开放平台(OPEA)发布了采用 AutoRound 技术制作的 4 比特量化版本模型,该模型采用 GPTQ 格式封装,可与 vLLM 框架兼容使用。值得注意的是,此次量化工作由 AutoRound 原团队操刀完成。有趣的是,他们选择通过 OPEA 而非英特尔渠道发布,推测可能是为了规避英特尔内部繁琐的新模型发布审批流程。(个人推测)
-
OPEA/DeepSeek-V3-int4-sym-inc-cpu (MIT license)
该模型可在配备 8 张 H100 加速卡的单一节点上运行。
由于资金不足,OPEA 未能对该模型进行评估(根据模型卡所述;这在我看来不合逻辑,因为量化本身的成本远高于评估)。我估计使用标准的非生成式基准测试(如 MMLU、GPQA 和 MuSR)进行评估只需花费几百美元。
考虑到模型规模庞大,且 4 位量化通常对大型模型具有较高精度,这个 4 位量化版本的表现很可能与原版相当。但这一假设需要充分验证,因为某些层可能无法通过 AutoRound 正确量化,从而导致模型生成无意义的输出内容。
我也认为 2 比特版本可能会非常精确。希望 OPEA 能发布一个这样的版本。
结论
从基准测试结果来看,DeepSeek-V3 是目前最优秀的开源 LLM(代码采用 MIT 许可证,模型采用 DeepSeek 许可证)。
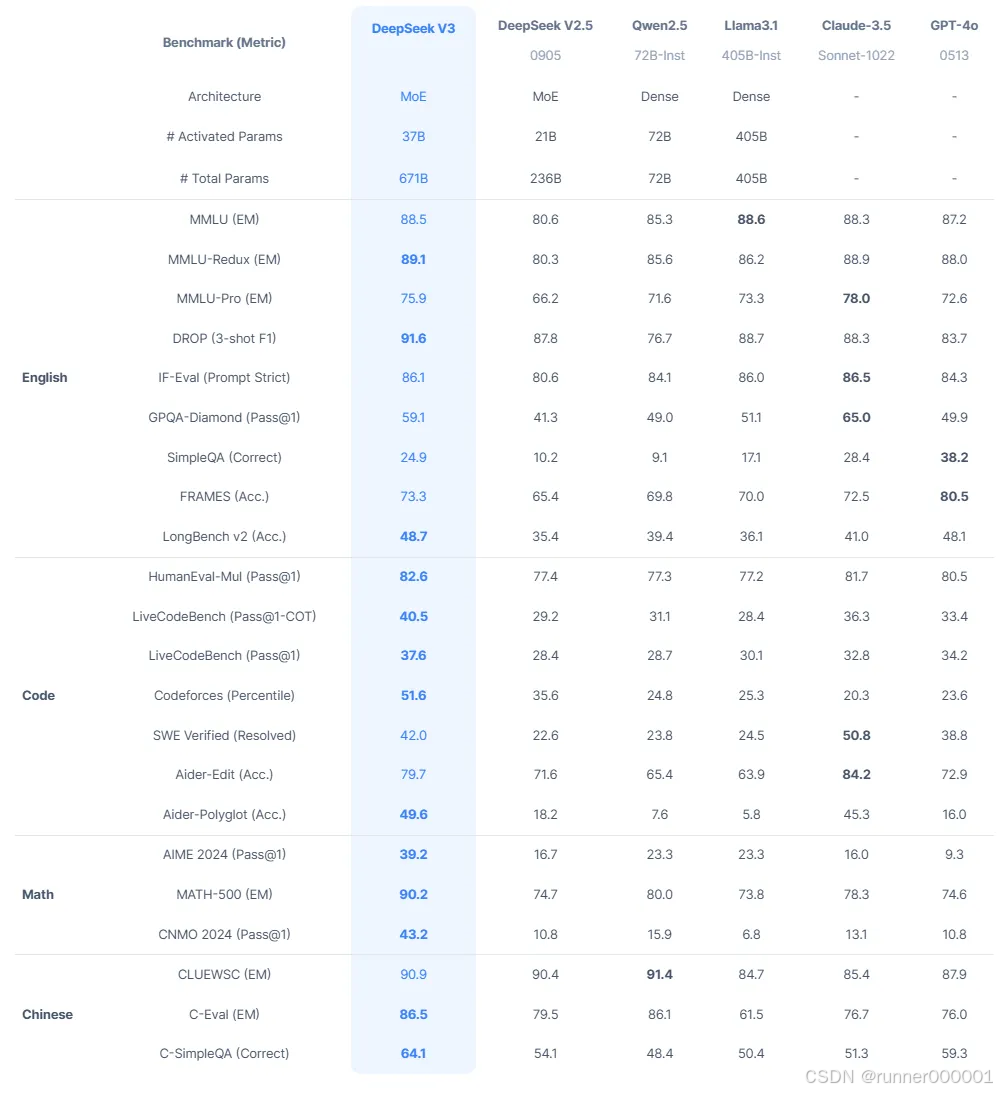
虽然目前将其用于日常任务尚不切实际——或者说至少不够经济实惠——但我预计未来几个月将发布更小、更高效的模型,这些模型很可能是通过师生框架(也称为知识蒸馏)利用 DeepSeek-V3 训练而成。
我甚至还没提到,但在我看来,这项工作最令人印象深刻的部分是对训练的极致优化。采用标准训练流程预训练一个 6710 亿参数的模型成本极其高昂(远超 1000 万美元)。
DeepSeek-AI 详细披露了他们如何极致优化训练流程以完美匹配硬件配置。DeepSeek-V3 的训练具有极高经济性:在一万亿 token 上的预训练仅消耗 18 万 H800 GPU 小时,相当于使用 2048 块 H800 GPU 集群运行 3.7 天。完整预训练阶段在两个月内完成,总计使用 266.4 万 GPU 小时。加上 11.9 万 GPU 小时用于上下文长度扩展以及 5000 小时用于训练后处理,总训练时长达到 278.8 万 GPU 小时。按每小时 2 美元的租赁费率计算,总训练成本为 557.6 万美元。令人惊叹!
添加作者个人微信:wintersweet0flower(验证消息请注明CSDN)
分享LORA微调、QLoRA微调、RLHF以及RAG的代码实例
还可以就技术问题进行咨询。
代码
This code shows how to run DeepSeek-V3 with vLLM. Examples of configurations that can run DeepSeek-V3:8 H200s2 nodes of 8 H100sInstall
pip install --upgrade vllm tritonWith 1 node of 8 GPUs
from vllm import LLM, SamplingParamsprompts = [{\"role\": \"system\", \"content\": \"You are a helpful and harmless assistant. You should think step-by-step.\"}, {\"role\":\"user\", \"content\":\"Please add a pair of parentheses to the incorrect equation: 1 + 2 * 3 + 4 * 5 + 6 * 7 + 8 * 9 = 479, to make the equation true.\"}]sampling_params = SamplingParams(temperature=0.7, top_p=0.8, max_tokens=5000)llm = LLM(model=\"deepseek-ai/DeepSeek-V3\", max_model_len=8192, tensor_parallel_size=8)outputs = llm.chat(prompts, sampling_params)for output in outputs: generated_text = output.outputs[0].text print(generated_text)With 2 nodes of 8 GPUs
from vllm import LLM, SamplingParamsprompts = [{\"role\": \"system\", \"content\": \"You are a helpful and harmless assistant. You should think step-by-step.\"}, {\"role\":\"user\", \"content\":\"Please add a pair of parentheses to the incorrect equation: 1 + 2 * 3 + 4 * 5 + 6 * 7 + 8 * 9 = 479, to make the equation true.\"}]sampling_params = SamplingParams(temperature=0.7, top_p=0.8, max_tokens=5000)llm = LLM(model=\"deepseek-ai/DeepSeek-V3\", max_model_len=8192, tensor_parallel_size=8, pipeline_parallel_size=2)outputs = llm.chat(prompts, sampling_params)for output in outputs: generated_text = output.outputs[0].text print(generated_text)Running the Quantized Version
from vllm import LLM, SamplingParamsprompts = [{\"role\": \"system\", \"content\": \"You are a helpful and harmless assistant. You should think step-by-step.\"}, {\"role\":\"user\", \"content\":\"Please add a pair of parentheses to the incorrect equation: 1 + 2 * 3 + 4 * 5 + 6 * 7 + 8 * 9 = 479, to make the equation true.\"}]sampling_params = SamplingParams(temperature=0.7, top_p=0.8, max_tokens=5000)llm = LLM(model=\"OPEA/DeepSeek-V3-int4-sym-gptq-inc\", max_model_len=8192, tensor_parallel_size=8)outputs = llm.chat(prompts, sampling_params)for output in outputs: generated_text = output.outputs[0].text print(generated_text)

