面试题:基础的sql命令
基础的 SQL 命令主要用于对数据库进行查询、新增、修改、删除等操作,可分为以下几类:
一、数据查询(SELECT)
用于从表中获取数据,是最常用的命令。
基本语法:
SELECT 列名1, 列名2... FROM 表名 WHERE 条件;- 示例:查询
students表中所有 18 岁以上的学生姓名和年龄SELECT name, age FROM students WHERE age > 18; - 常用扩展:
DISTINCT(去重)、ORDER BY(排序)、LIMIT(限制结果数量)等。
我来扩写这个 SQL 查询,加入 DISTINCT、ORDER BY 和 LIMIT 等常用扩展功能:
-- 查询18岁以上不重复的学生姓名和年龄,按年龄降序排列,年龄相同的按姓名升序排列,只返回前20条记录SELECT DISTINCT name, age FROM students WHERE age > 18 ORDER BY age DESC, name ASC LIMIT 20;这个扩展查询包含以下功能:
-
DISTINCT- 确保返回的结果中没有重复的行 -
WHERE age > 18- 筛选条件,只返回18岁以上的学生 -
ORDER BY age DESC, name ASC- 先按年龄降序排列,年龄相同的再按姓名升序排列 -
LIMIT 20- 只返回前20条记录
如果需要更复杂的查询,还可以考虑:
-
添加 GROUP BY 进行分组
-
使用 HAVING 对分组结果进行筛选
-
使用 JOIN 连接其他表
-
添加 OFFSET 实现分页功能
我将扩展这个 SQL 查询,加入 GROUP BY、HAVING、JOIN 和 OFFSET 分页功能,同时保持之前的 DISTINCT、ORDER BY 和 LIMIT 条件:
假设场景:
-
students表存储学生信息(id,name,age,class_id) -
classes表存储班级信息(id,class_name,teacher_id) -
exam_scores表存储考试成绩(student_id,score)
查询目标:
\"查询18岁以上、平均分≥60分的学生姓名、年龄和班级名称,按年龄降序排列,并实现分页(每页10条记录)\"
完整 SQL:
SELECT s.name, s.age, c.class_name, AVG(e.score) AS avg_scoreFROM students sLEFT JOIN classes c ON s.class_id = c.idLEFT JOIN exam_scores e ON s.id = e.student_idWHERE s.age > 18GROUP BY s.id, s.name, s.age, c.class_nameHAVING AVG(e.score) >= 60ORDER BY s.age DESC, s.name ASCLIMIT 10 OFFSET 0; -- 第一页(0-10条记录)关键功能说明:
-
JOIN(连接表):
-
连接
students和classes获取班级名称 -
连接
students和exam_scores计算平均分
-
-
GROUP BY(分组):
-
按学生ID、姓名、年龄和班级名称分组
-
确保聚合函数(如
AVG)正确计算每个学生的平均分
-
-
HAVING(筛选分组):
-
筛选出平均分≥60的学生(
WHERE不能用于聚合条件)
-
-
DISTINCT(去重):
-
由于
GROUP BY已经确保唯一性,这里可以省略DISTINCT
-
-
ORDER BY(排序):
-
优先按年龄降序(
DESC),其次按姓名升序(ASC)
-
-
LIMIT + OFFSET(分页):
-
LIMIT 10每页10条 -
OFFSET 0从第1条开始(第2页改为OFFSET 10)
-
进阶扩展:
-
如果需要计算总页数,可结合
COUNT(*) OVER()窗口函数:SELECT s.name, s.age, c.class_name, AVG(e.score) AS avg_score, COUNT(*) OVER() AS total_countFROM ...
二、数据插入(INSERT)
用于向表中新增记录。
基本语法:
INSERT INTO 表名 (列名1, 列名2...) VALUES (值1, 值2...);- 示例:向
students表插入一条新记录INSERT INTO students (name, age, gender) VALUES (\'张三\', 20, \'男\');
三、数据更新(UPDATE)
用于修改表中已有记录。
基本语法:
- 示例:将
students表中id=1的学生年龄改为 21UPDATE students SET age=21 WHERE id=1;注意:若省略
WHERE,会修改表中所有记录,需谨慎使用。
四、数据删除(DELETE)
用于删除表中的记录。
基本语法:
- 示例:删除
students表中age < 18的记录DELETE FROM students WHERE age < 18;注意:若省略
WHERE,会删除表中所有记录(表结构保留)。
五、表结构操作
1. 创建表(CREATE TABLE)
sql
CREATE TABLE 表名 ( 列名1 数据类型 约束, 列名2 数据类型 约束...);- 示例:创建
students表DROP TABLE IF EXISTS `sys_config`;CREATE TABLE `sys_config` ( `config_id` int NOT NULL AUTO_INCREMENT COMMENT \'参数主键\', `config_name` varchar(100) NOT NULL DEFAULT \'\' COMMENT \'参数名称\', `config_key` varchar(100) NOT NULL DEFAULT \'\' COMMENT \'参数键名\', `config_value` varchar(500) NOT NULL DEFAULT \'\' COMMENT \'参数键值\', `config_type` char(1) NOT NULL DEFAULT \'N\' COMMENT \'系统内置\', `create_by` varchar(64) NOT NULL DEFAULT \'\' COMMENT \'创建者\', `create_time` datetime(6) DEFAULT CURRENT_TIMESTAMP(6) COMMENT \'创建时间\', `update_by` varchar(64) NOT NULL DEFAULT \'\' COMMENT \'更新者\', `update_time` datetime(6) DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT \'更新时间\', `remark` varchar(500) DEFAULT NULL COMMENT \'备注\', `status` char(1) NOT NULL DEFAULT \'0\' COMMENT \'状态\', `del_flag` char(1) NOT NULL DEFAULT \'0\' COMMENT \'删除标志\', PRIMARY KEY (`config_id`)) ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT=\'参数配置表\';
2. 删除表(DROP TABLE)
DROP TABLE 表名; -- 彻底删除表(包括结构和数据)3. 修改表结构(ALTER TABLE)
- 新增列:
ALTER TABLE 表名 ADD 列名 数据类型; - 删除列:
ALTER TABLE 表名 DROP COLUMN 列名;
六、其他常用命令
DESCRIBE 表名;(或DESC 表名;):查看表结构。USE 数据库名;:切换到指定数据库。SHOW DATABASES;:查看所有数据库。SHOW TABLES;:查看当前数据库中的所有表。
这些命令覆盖了 SQL 的核心操作,掌握后可完成大部分基础数据库交互。
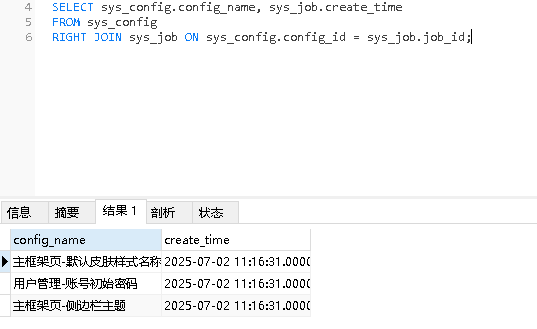
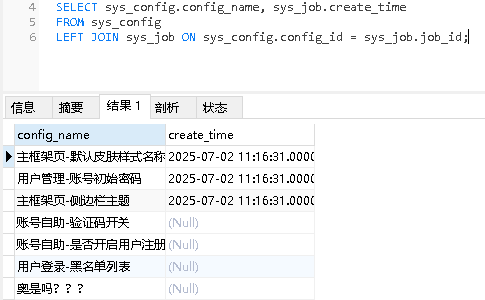
左链接,右链接的区别
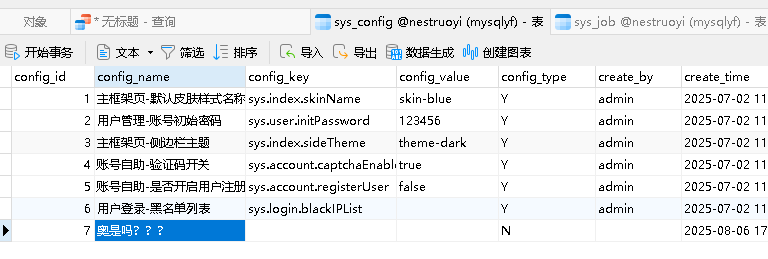
右链接:最大的条数取决于右边
左链接:最大的条数取决于左边
HAVING 是 SQL 中用于 对分组(GROUP BY)后的结果进行筛选 的关键字。它和 WHERE 的区别在于:
WHERE:在分组前对原始数据进行筛选。HAVING:在分组后对聚合结果进行筛选。
✅ 一、使用场景说明
假设我们有一个销售记录表 sales:
-- 表:sales+----+---------+--------+-------+| id | name | region | sales |+----+---------+--------+-------+| 1 | Alice | North | 100 || 2 | Bob | South | 150 || 3 | Charlie | North | 200 || 4 | David | South | 50 || 5 | Eve | North | 300 || 6 | Frank | South | 100 |+----+---------+--------+-------+我们想查询:每个地区的总销售额,并只显示总销售额大于 250 的地区。
✅ 二、SQL 操作过程
第一步:创建表并插入数据
CREATE TABLE sales ( id INT PRIMARY KEY, name VARCHAR(50), region VARCHAR(50), sales INT);INSERT INTO sales (id, name, region, sales) VALUES(1, \'Alice\', \'North\', 100),(2, \'Bob\', \'South\', 150),(3, \'Charlie\', \'North\', 200),(4, \'David\', \'South\', 50),(5, \'Eve\', \'North\', 300),(6, \'Frank\', \'South\', 100);第二步:使用 GROUP BY 和 HAVING 查询
SELECT region, SUM(sales) AS total_salesFROM salesGROUP BY regionHAVING SUM(sales) > 250;✅ 三、执行过程详解
GROUP BY regionNorth: [100, 200, 300] → 总和 600
South: [150, 50, 100] → 总和 300
SUM(sales) 计算每组总销售额HAVING SUM(sales) > 250 筛选✅ 注意:如果
HAVING条件是> 350,则只有North会被返回。
✅ 四、预期输出
+--------+-------------+| region | total_sales |+--------+-------------+| North | 600 || South | 300 |+--------+-------------+如果改为:
HAVING SUM(sales) > 350;则输出:
+--------+-------------+| region | total_sales |+--------+-------------+| North | 600 |+--------+-------------+✅ 五、对比:WHERE vs HAVING
WHEREWHERE sales > 100 → 先过滤出 sales>100 的记录,再分组HAVINGHAVING SUM(sales) > 250 → 分组后筛选总销售额示例:先过滤再分组
SELECT region, SUM(sales) AS total_salesFROM salesWHERE sales > 100 -- 先过滤掉 sales 200;WHERE sales > 100后剩下:Alice(100❌), Bob(150✅), Charlie(200✅), David(50❌), Eve(300✅), Frank(100❌)- 实际参与分组的数据:Bob, Charlie, Eve, Frank → North: 200+300=500, South: 150+100=250
HAVING SUM(sales) > 200→ 两组都保留
✅ 六、HAVING 常见用法
-- 1. 筛选聚合值HAVING COUNT(*) > 1 -- 分组内记录数大于1HAVING AVG(sales) > 100 -- 平均销售额大于100HAVING MAX(sales) 250 AND COUNT(*) >= 2-- 3. 结合 ORDER BYORDER BY total_sales DESC✅ 总结
HAVING 必须和 GROUP BY 一起使用HAVING 后可跟聚合函数SUM, COUNT, AVG 等WHERE 先于 GROUP BY,HAVING 在其后WHERE → GROUP BY → HAVING✅ 记住口诀:
“先 where,再分组,后 having”
WHERE筛原始数据,HAVING筛分组结果。


