一文读懂Python循环语句

🙋♀️ 个人主页:颜颜yan_
⭐ 本期精彩:一文读懂Python循环语句
🏆 热门专栏:零基础玩转Python爬虫:手把手教你成为数据猎人
🚀 专栏亮点:零基础友好 | 实战案例丰富 | 循序渐进教学 | 代码详细注释
💡 学习收获:掌握爬虫核心技术,成为数据采集高手,开启你的数据科学之旅!🔥 如果觉得文章有帮助,别忘了点赞👍 收藏⭐ 关注🚀,你的支持是我创作的最大动力!
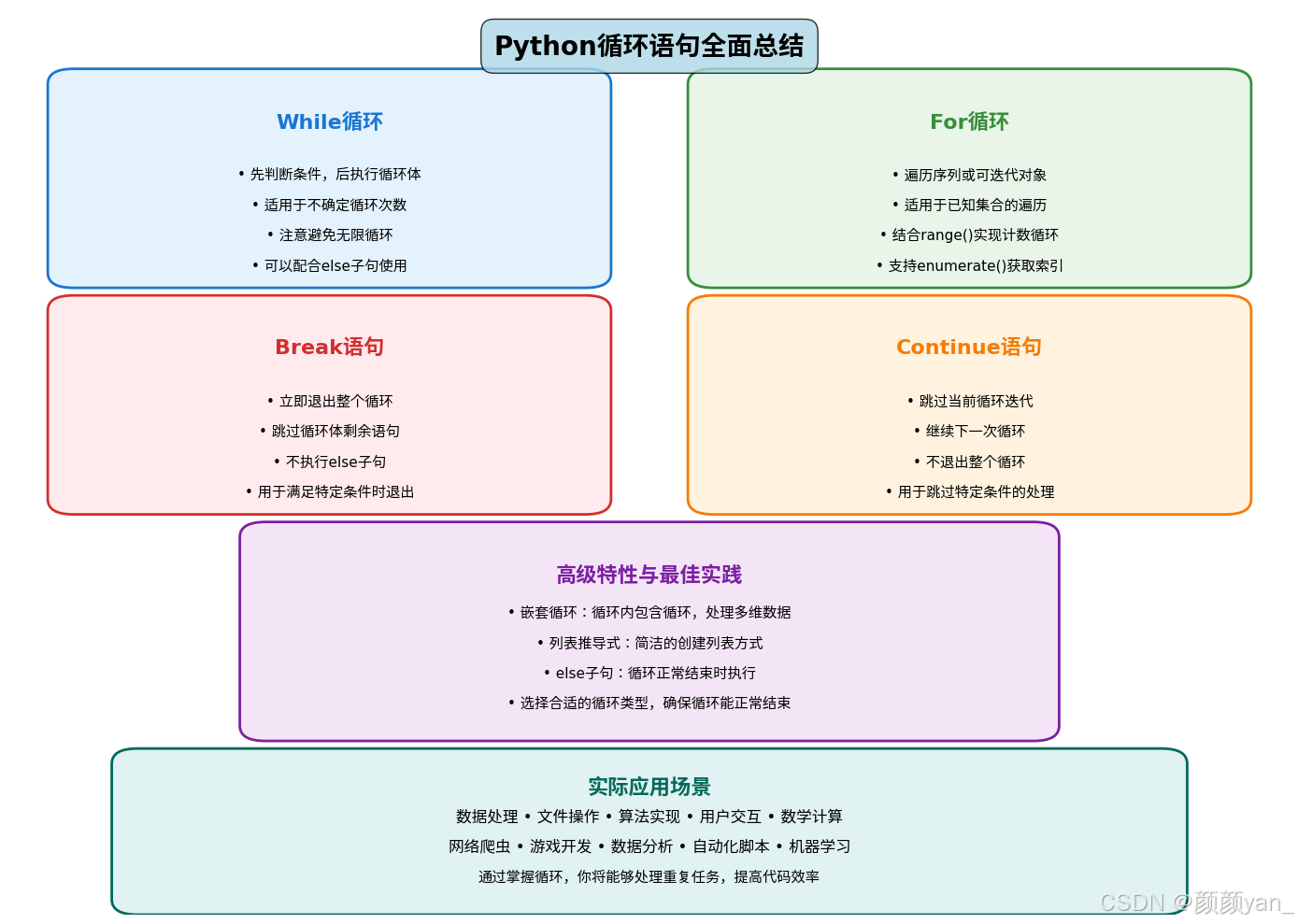
文章目录
- 前言
- while语句
-
- 基本语法
- 基本while循环
- 计算累加和
- 无限循环
- while-else语句
- for语句
-
- 基本语法
- 遍历列表
- 遍历字符串
- 使用range()函数
- 遍历字典
- 使用enumerate()函数
- for-else语句
- break和continue语句
-
- break语句
-
- 在while循环中使用break
- 在for循环中使用break
- continue语句
-
- 在while循环中使用continue
- 在for循环中使用continue
- 进阶应用
-
- 嵌套循环
- 列表推导式
-
- 传统方法 vs 列表推导式对比
- 实际应用案例
-
- 斐波那契数列计算
- 文本词频统计分析
- 🎯 与我一起学习成长
-
- 📚 专栏推荐
- 💬 期待与你交流
前言
循环是编程中最基本也是最强大的控制结构之一,它允许我们重复执行特定的代码块,直到满足某个条件为止。Python提供了两种主要的循环结构:while循环和for循环,以及用于控制循环执行的break和continue语句。本文将详细讲解这些循环结构的语法和使用方法,并通过实例展示其在实际编程中的应用。
while语句
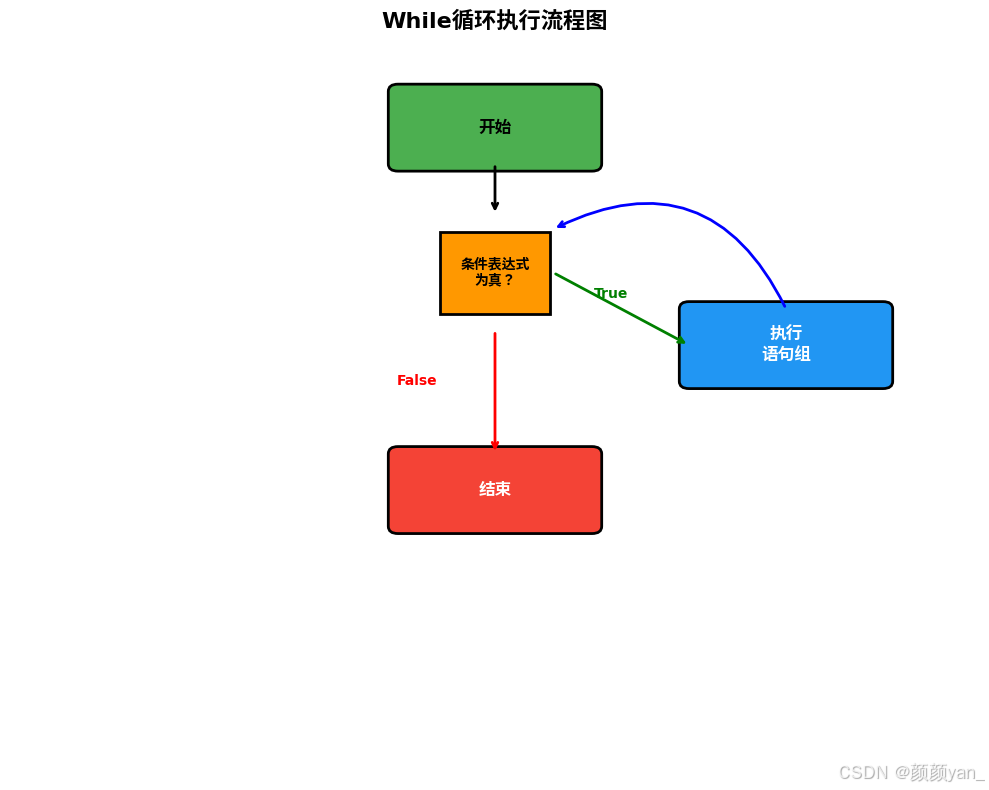
while语句是一种先判断的循环结构,首先测试条件表达式,如果值为true,则执行语句组,如果条件表达式为false,则忽略语句组,继续执行后面的语句。
从流程图可以看出,while循环的执行过程是一个不断判断条件的循环过程:
- 首先判断条件表达式
- 如果条件为真,执行循环体,然后回到条件判断
- 如果条件为假,直接跳出循环
基本语法
while 条件表达式: 语句组基本while循环
# 打印1到5的数字count = 1while count <= 5: print(count) count += 1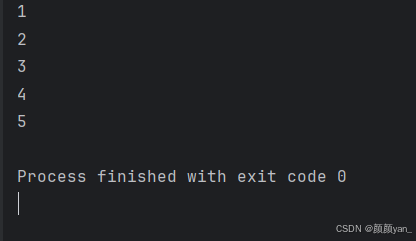
计算累加和
# 计算1到100的和total = 0num = 1while num <= 100: total += num num += 1 print(f\"1到100的和是: {total}\")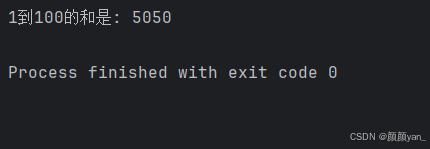
无限循环
有时我们需要创建无限循环,然后在循环体内部使用条件语句来跳出循环:
# 模拟简单的菜单系统while True: print(\"\\n===== 菜单 =====\") print(\"1. 查看信息\") print(\"2. 修改设置\") print(\"3. 退出程序\") choice = input(\"请输入选项 (1-3): \") if choice == \'1\': print(\"显示信息...\") elif choice == \'2\': print(\"修改设置...\") elif choice == \'3\': print(\"程序已退出\") break else: print(\"无效的选项,请重试\")
while-else语句
Python的while循环可以包含else子句,当循环条件变为False时,else子句将被执行。
# 查找列表中的元素numbers = [1, 3, 5, 7, 9]target = 6index = 0while index < len(numbers): if numbers[index] == target: print(f\"找到目标数字{target},位置是{index}\") break index += 1else: print(f\"列表中不存在数字{target}\")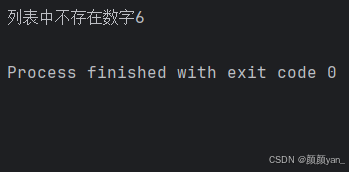
for语句
python语言中for语句用于遍历序列类型,序列包括字符串、列表和元组。
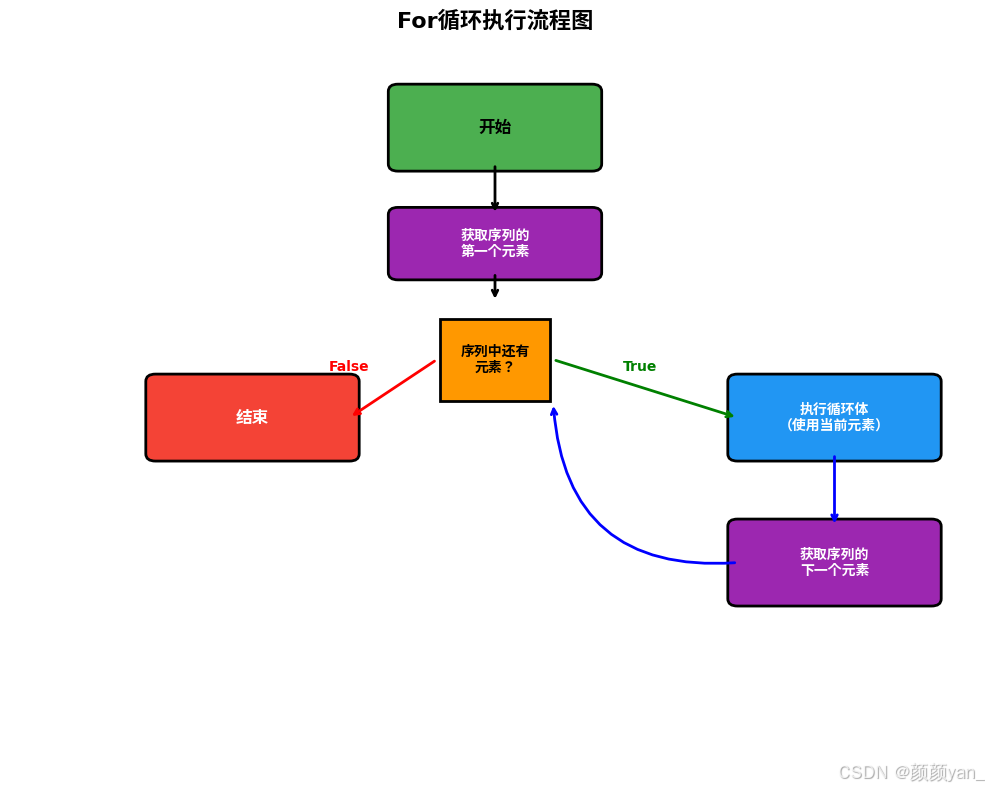
for循环的执行流程更加直观:
- 获取序列的第一个元素
- 判断序列中是否还有元素
- 如果有,执行循环体,然后获取下一个元素
- 如果没有,结束循环
基本语法
for 迭代变量 in 序列: 语句组序列表示所有的实现序列的类型都可以使用for循环。迭代变量是从序列中迭代取出的元素。
遍历列表
# 遍历水果列表fruits = [\"苹果\", \"香蕉\", \"橙子\", \"草莓\", \"葡萄\"]for fruit in fruits: print(f\"我喜欢吃{fruit}\")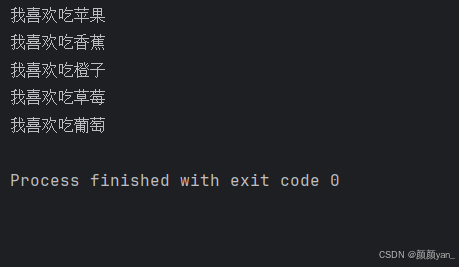
遍历字符串
# 遍历字符串中的字符message = \"Python\"for char in message: print(char)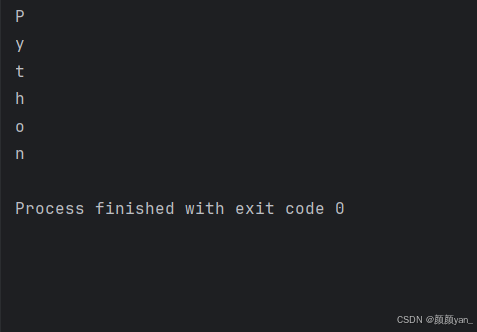
使用range()函数
range()函数可以生成一个数字序列,常用于for循环中:
# 打印平方数for i in range(1, 6): # 生成1到5的序列 square = i ** 2 print(f\"{i}的平方是{square}\")
遍历字典
# 遍历字典的键值对student = { \"name\": \"李明\", \"age\": 18, \"grade\": \"高三\", \"score\": 95}for key, value in student.items(): print(f\"{key}: {value}\")
使用enumerate()函数
enumerate()函数可以同时获取索引和元素:
# 使用enumerate()获取索引和元素colors = [\"红\", \"橙\", \"黄\", \"绿\", \"蓝\", \"紫\"]for index, color in enumerate(colors): print(f\"第{index+1}个颜色是{color}色\")
for-else语句
与while循环类似,for循环也可以带有else子句,当for循环正常结束时(不是通过break跳出)执行else子句:
# 检查列表中的奇数numbers = [2, 4, 6, 8, 10]for num in numbers: if num % 2 != 0: print(f\"找到奇数: {num}\") breakelse: print(\"列表中没有奇数\")
break和continue语句
break和continue语句是控制循环执行流程的重要工具,它们的执行流程如下图所示:
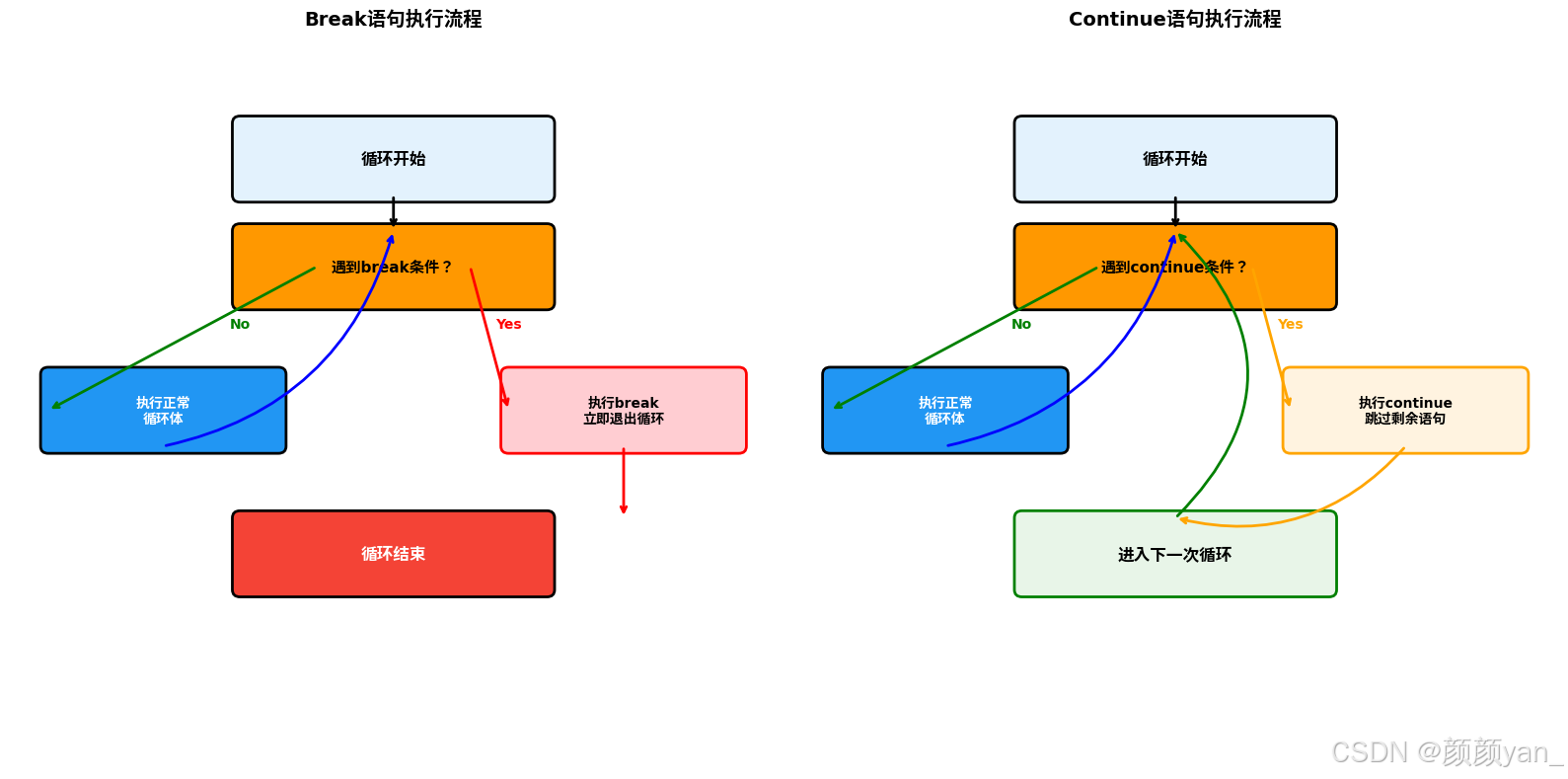
break语句
break语句可用于while或for循环,它的作用是强行退出循环体,不再执行循环体中剩余的语句。
在while循环中使用break
# 查找第一个能被7整除的数i = 1while i <= 100: if i % 7 == 0: print(f\"找到了第一个能被7整除的数: {i}\") break i += 1
在for循环中使用break
# 查找特定元素并停止names = [\"张三\", \"李四\", \"王五\", \"赵六\", \"钱七\"]search_name = \"王五\"for name in names: if name == search_name: print(f\"找到了{search_name}!\") break print(f\"检查: {name}\")
continue语句
continue语句用来结束本次循环,跳过循环体中尚未执行的语句,接着进行终止条件的判断,以决定是否继续循环。
在while循环中使用continue
# 打印1到10中除了5以外的所有数字num = 0while num < 10: num += 1 if num == 5: continue print(f\"当前数字: {num}\")
在for循环中使用continue
# 打印所有不包含\'e\'的单词words = [\"apple\", \"banana\", \"orange\", \"grape\", \"kiwi\"]for word in words: if \'e\' in word: continue print(f\"{word} 不包含字母\'e\'\")
进阶应用
嵌套循环
循环可以嵌套使用,即在一个循环内部包含另一个循环。下面通过九九乘法表来演示嵌套循环的应用:
- 外层循环控制行数(i从1到9)
- 内层循环控制每行的列数(j从1到i)
- 每个内层循环完成后,外层循环进入下一次迭代
- 形成阶梯状的乘法表结构
# 打印乘法表for i in range(1, 10): for j in range(1, i+1): print(f\"{j}×{i}={i*j}\", end=\"\\t\") print() # 换行
列表推导式
列表推导式是Python的一个强大特性,可以用简洁的语法创建列表。
传统方法 vs 列表推导式对比
1. 创建平方数列表的对比:
传统方法:
squares_traditional = []for x in range(1, 11): squares_traditional.append(x**2)# 结果: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]列表推导式:
squares_comprehension = [x**2 for x in range(1, 11)]# 结果: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]2. 过滤偶数的对比:
传统方法:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]even_traditional = []for x in numbers: if x % 2 == 0: even_traditional.append(x)# 结果: [2, 4, 6, 8, 10]列表推导式:
even_comprehension = [x for x in numbers if x % 2 == 0]# 结果: [2, 4, 6, 8, 10]3. 复杂的列表推导式:
# 创建一个包含平方数的字典square_dict = {x: x**2 for x in range(1, 6)}print(square_dict)# 从字符串列表中提取长度大于4的单词并转换为大写words = [\"python\", \"java\", \"c\", \"javascript\", \"go\", \"rust\"]long_words = [word.upper() for word in words if len(word) > 4]print(long_words)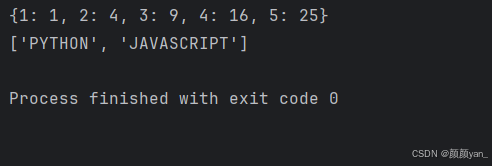
实际应用案例
斐波那契数列计算
斐波那契数列是一个经典的数学序列,每个数都是前两个数的和。通过for循环,我们可以高效地计算这个数列:
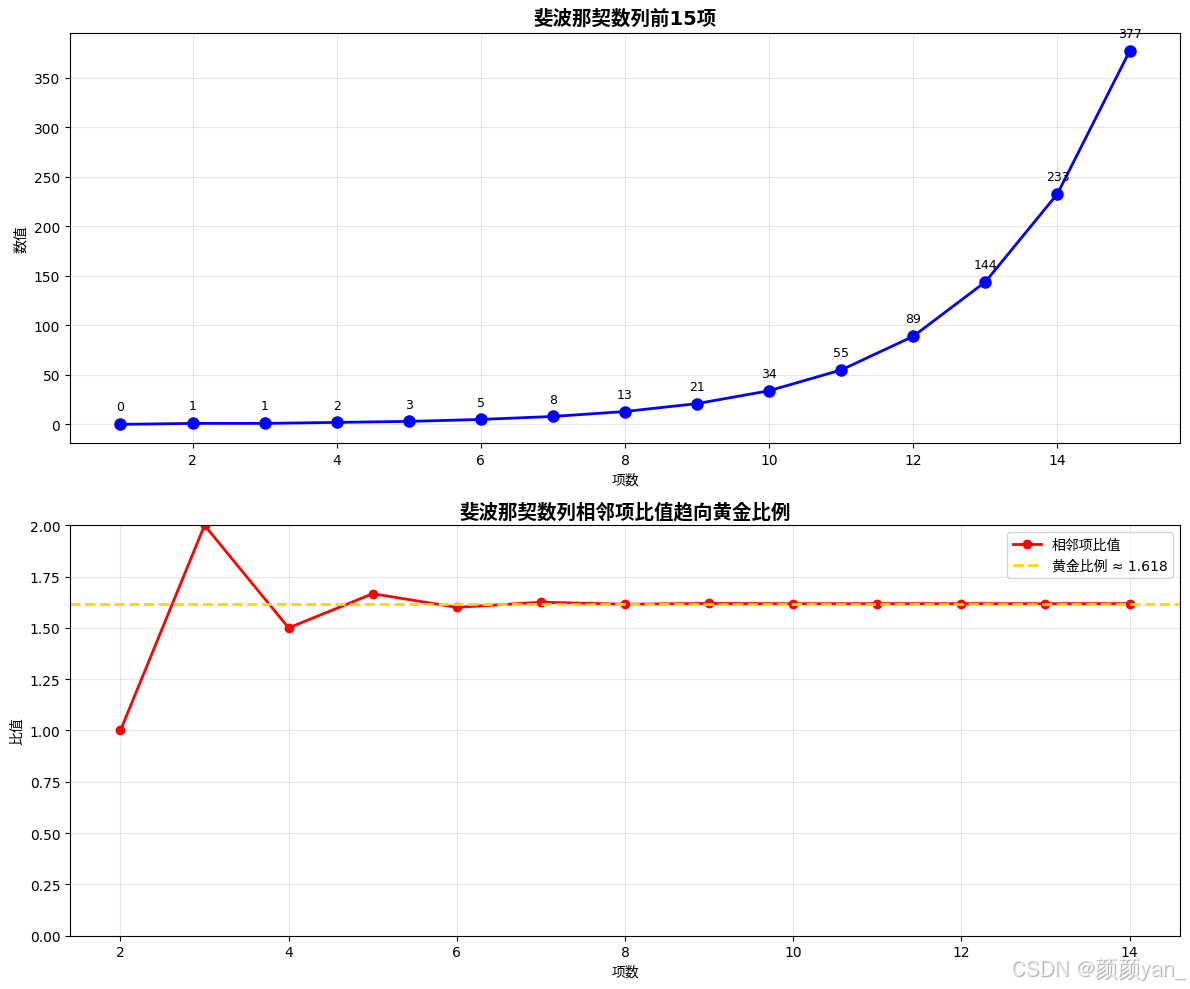
def fibonacci(n): \"\"\"生成斐波那契数列的前n个数\"\"\" if n <= 0: return [] elif n == 1: return [0] elif n == 2: return [0, 1] fib_series = [0, 1] # 初始化前两个数 # 从第3个数开始计算 for i in range(2, n): next_number = fib_series[i-1] + fib_series[i-2] fib_series.append(next_number) return fib_series# 计算并显示斐波那契数列fib_15 = fibonacci(15)print(f\"斐波那契数列的前15个数: {fib_15}\")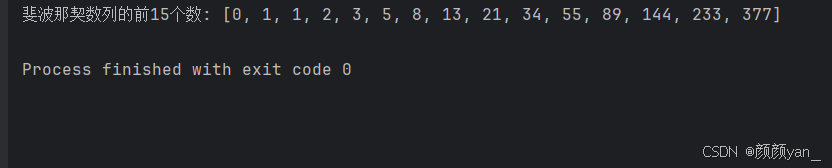
小知识:斐波那契数列中,相邻两项的比值会逐渐趋向于黄金比例 φ ≈ 1.618,这是一个非常有趣的数学现象。
文本词频统计分析
在自然语言处理和数据分析中,词频统计是一个常见的任务。通过循环,我们可以高效地统计文本中各个词汇的出现频率。
- 遍历文本中的每个字符和单词
- 统计每个词汇的出现次数
- 过滤和排序高频词汇
- 生成可视化数据
def chinese_word_frequency(text): \"\"\"统计中文文本中各词语出现的频率\"\"\" import re # 定义常见的中文词汇模式 chinese_words = re.findall(r\'[\\u4e00-\\u9fff]+\', text) english_words = re.findall(r\'[a-zA-Z]+\', text) # 进一步分析中文词汇(简单的2-3字词分割) analyzed_words = [] for word in chinese_words: if len(word) >= 2: # 提取常见词汇 for i in range(len(word) - 1): if i + 2 <= len(word): analyzed_words.append(word[i:i+2]) if i + 3 <= len(word): analyzed_words.append(word[i:i+3]) # 添加英文单词 for word in english_words: analyzed_words.append(word.lower()) # 统计频率 frequency = {} for word in analyzed_words: if len(word) >= 2: # 只考虑长度>=2的词 frequency[word] = frequency.get(word, 0) + 1 return frequency# 测试文本sample_text = \"\"\"Python是一种广泛使用的高级编程语言,Python的设计具有很强的可读性。相比其他语言经常使用英文关键字,其他语言的一些标点符号,Python具有相对简单的语法。相对其他动态类型语言,Python拥有相对较少的关键字。Python的核心哲学总结起来就是:优美胜于丑陋,明了胜于晦涩,简洁胜于复杂。Python开发者的哲学是用一种方法,最好是只有一种方法来做一件事。Python是一种解释型语言,Python可以应用于多个领域。\"\"\"# 统计单词频率word_count = chinese_word_frequency(sample_text)# 过滤高频词并排序frequent_words = {word: count for word, count in word_count.items() if count >= 2}sorted_words = sorted(frequent_words.items(), key=lambda x: x[1], reverse=True)print(\"高频词汇统计结果(出现次数 ≥ 2):\")for word, count in sorted_words: print(f\"\'{word}\' 出现了 {count} 次\")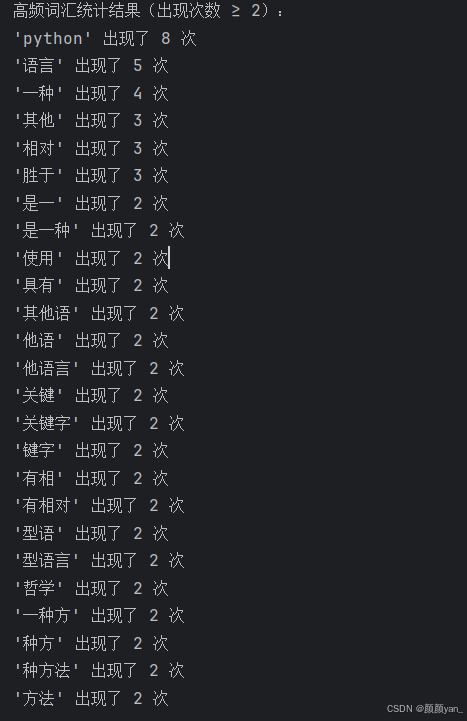
🎯 与我一起学习成长
掌握循环结构是编程的基础,它们使得我们能够高效地处理重复任务和数据集合。通过本文的示例和案例,希望您对Python的循环结构有了更深入的了解,并能在实际开发中灵活运用这些知识。循环不仅是编程的基础工具,更是解决复杂问题的强大武器!🐍✨
我是颜颜yan_,一名专注于技术分享的博主。如果这篇文章对你有帮助,欢迎关注我的更多精彩内容!
📚 专栏推荐
- 零基础玩转Python爬虫:手把手教你成为数据猎人
- 鸿蒙HarmonyOS:探索未来智能生态新纪元
💬 期待与你交流
- 有疑问?欢迎在评论区留言讨论
- 想深入学习?关注我获取更多优质教程
- 觉得有用?别忘了点赞👍 收藏⭐ 关注🚀



