repmgr+vip实现对业务透明的高可用切换
本方案说明
- PostgreSQL + repmgr:实现主从自动故障检测与切换(Failover)。
- vip:作为应用连接地址,屏蔽后端数据库变动,提供透明连接。
- vip漂移:通过repmgr组件的
promote_command阶段触发脚本,将vip漂移到新主库。
节点规划
目录文件说明
1.集群准备
准备一套1主2从的repmgr集群,部署过程参考我的另一篇文章PostgreSQL高可用架构Repmgr部署流程
# 配置集群所有节点postgres用户的sudo权限[root@repmgr01 ~]# visudopostgres ALL=(ALL) NOPASSWD: ALL2.编辑repmgr触发脚本
#所有节点vim /data/repmgr/promte_standby_vip.sh#!/bin/bashset -o xtracePGCANDIDATES=(10.0.0.41 10.0.0.42 10.0.0.43)HOSTNAME=`hostname -i`VIP=10.0.0.44GW=10.0.0.254DEVICE=ens33PG_HOME=/usr/local/pgsqlPG_PORT=5432REPMGR_USER=repmgrREPMGR_PASSWD=repmgrREPMGR_CONF=/data/repmgr/repmgr.confSTEP1=\"Remove the VIP on all nodes\"STEP2=\"Check if vip still online\"STEP3=\"Promte primary DB\"STEP4=\"Add vip on new primary DB\"STEP5=\"Clear ARP Cache\"###step1. Remove the VIP on all nodesfor candidate in \"${PGCANDIDATES[@]}\"; do [ \"$HOSTNAME\" = \"$candidate\" ] && continue ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$candidate \" /usr/bin/sudo /sbin/ip addr del $VIP/24 dev $DEVICE \"done###step2.Check if vip still online/usr/bin/sudo /usr/bin/ping -c1 -w1 -t5 ${VIP}if [ $? -eq 0 ]; then echo repmgr_promote_command.sh: ${STEP2} : ${VIP} failed !!! exit 1fi###step3.Promte primary DB${PG_HOME}/bin/repmgr standby promote -f ${REPMGR_CONF} --log-to-fileif [ $? -ne 0 ]; then echo repmgr_promote_command.sh: ${STEP3} on ${HOSTNAME} failed !!! exit 1fistandby_flg=`${PG_HOME}/bin/psql -p ${PG_PORT} -U ${REPMGR_USER} -w ${REPMGR_PASSWD} -h localhost -At -c \"SELECT pg_is_in_recovery();\"`if [ ${standby_flg} == \'f\' ]; then echo repmgr_promote_command.sh: ${STEP3} on ${HOSTNAME} successfully !!!elif [ ${standby_flg} == \'t\' ]; then echo repmgr_promote_command.sh: ${STEP3} on ${HOSTNAME} failed !!! exit 1fi###step4.Add vip on new primary DB/usr/bin/sudo /sbin/ip addr add $VIP/24 dev $DEVICEif [ $? -ne 0 ]; then echo repmgr_promote_command.sh: ${STEP4} on ${HOSTNAME} failed !!! exit 1fi####step5.Clear arp cache/usr/bin/sudo /sbin/arping -I $DEVICE -s $VIP -b -c 3 $GWif [ $? -ne 0 ]; then echo repmgr_promote_command.sh: ${STEP5} on ${HOSTNAME} failed !!! exit 1fi# 授予脚本可执行权限chmod +x /data/repmgr/promte_standby_vip.sh3.修改repmgr配置文件
# 修改promote_command参数,执行我们新建的脚本vim /data/repmgr/repmgr.confpromote_command=\'/data/repmgr/promte_standby_vip.sh >> /data/repmgr/repmgrd.log\'4.将vip挂载到主节点
[postgres@repmgr01 ~]$ /usr/bin/sudo /sbin/ip addr add 10.0.0.44/24 dev ens335.重新启动repmgrd守护进程
kill $(pgrep -f repmgrd)repmgrd -f /data/repmgr/repmgr.conf --daemonize6.验证failover
查看当前集群状态
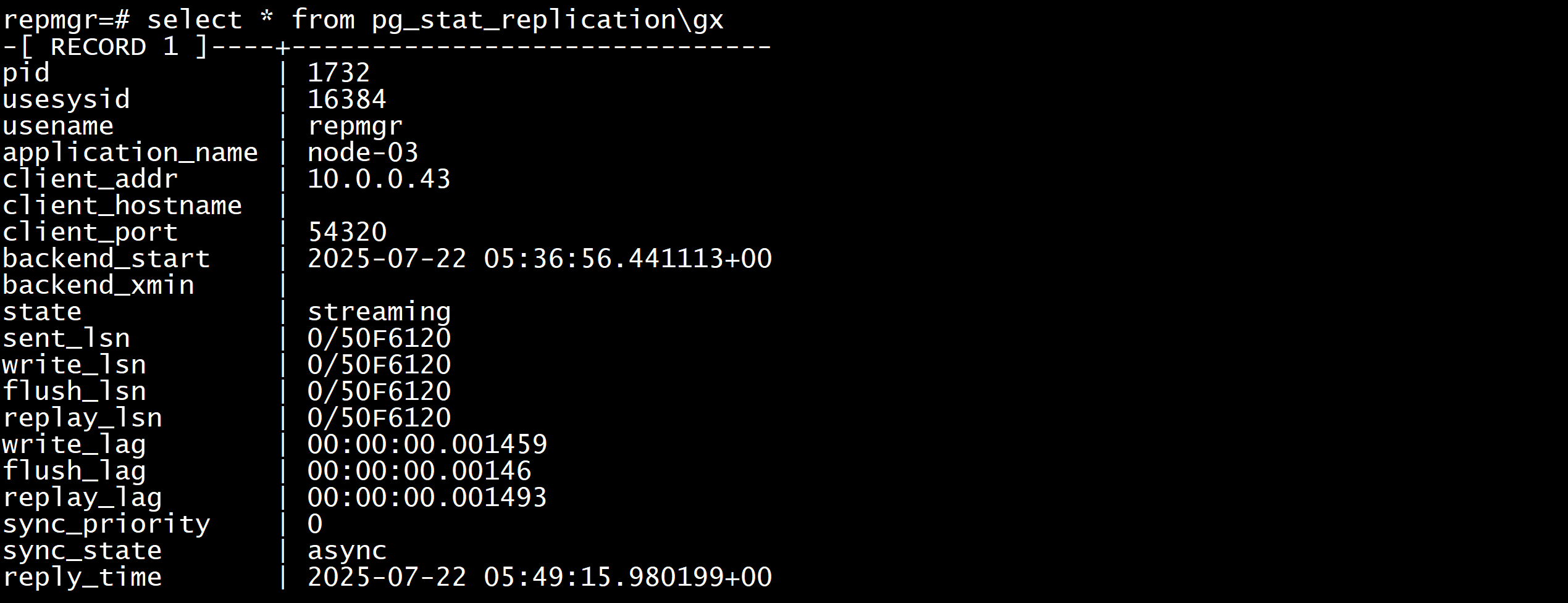
[postgres@repmgr01 ~]$ repmgr -f /data/repmgr/repmgr.conf cluster show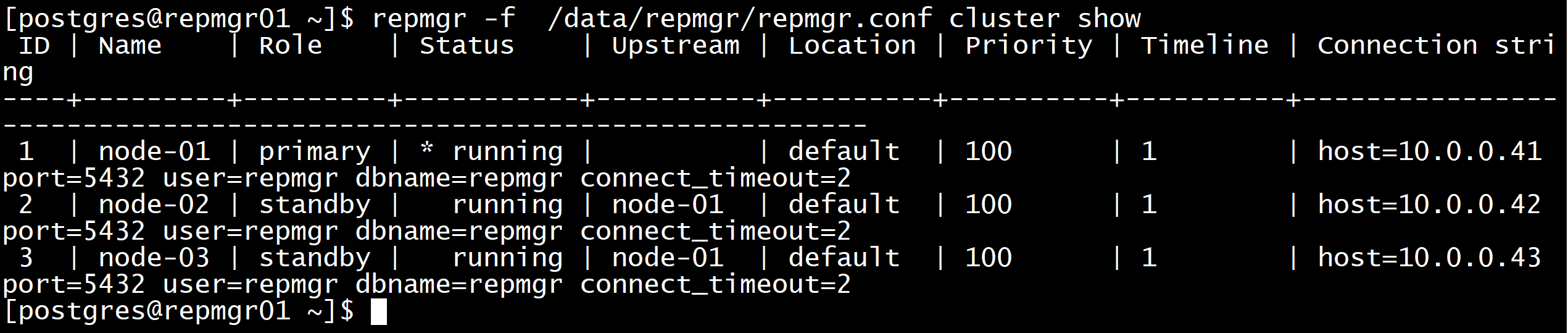
使用vip连接查看从库信息
[postgres@repmgr01 ~]$ PGPASSWORD=\"repmgr\" psql -p 5432 -U repmgr -h 10.0.0.44 -d repmgrrepmgr=# select * from pg_stat_replication;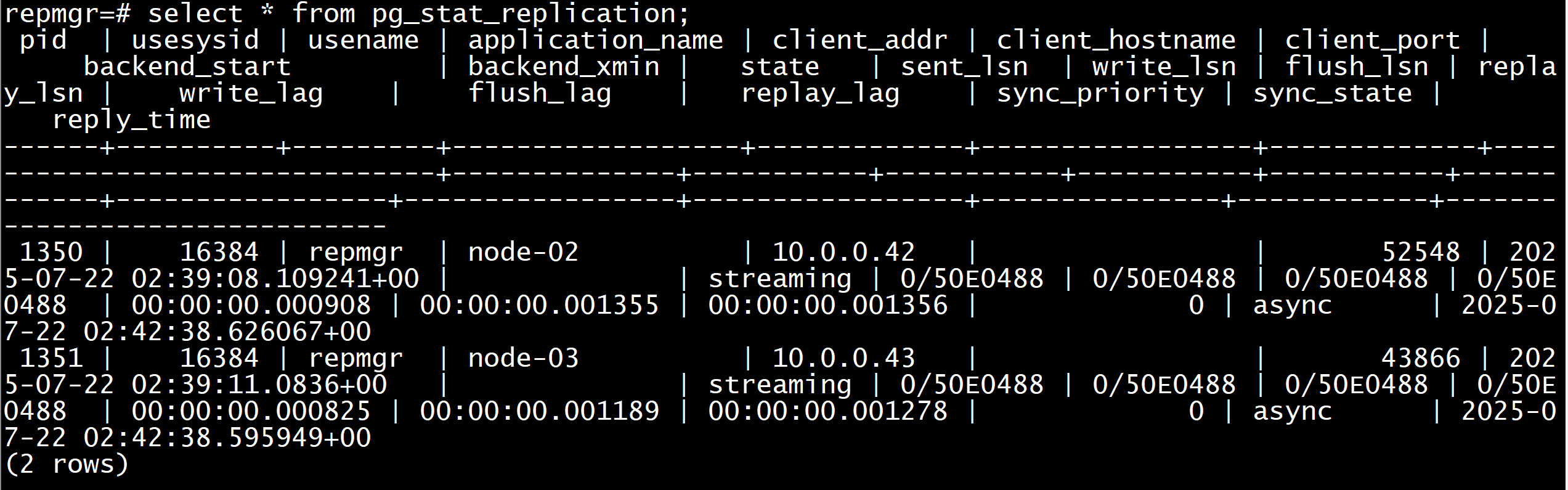
手动关闭主节点
[postgres@postgres-01 data]$ pg_ctl stop -D $PGDATAwaiting for server to shut down.... doneserver stopped查看日志
[postgres@repmgr02 ~]$ vim /data/repmgr/repmgrd.log 经过三次重试无法连接node-01
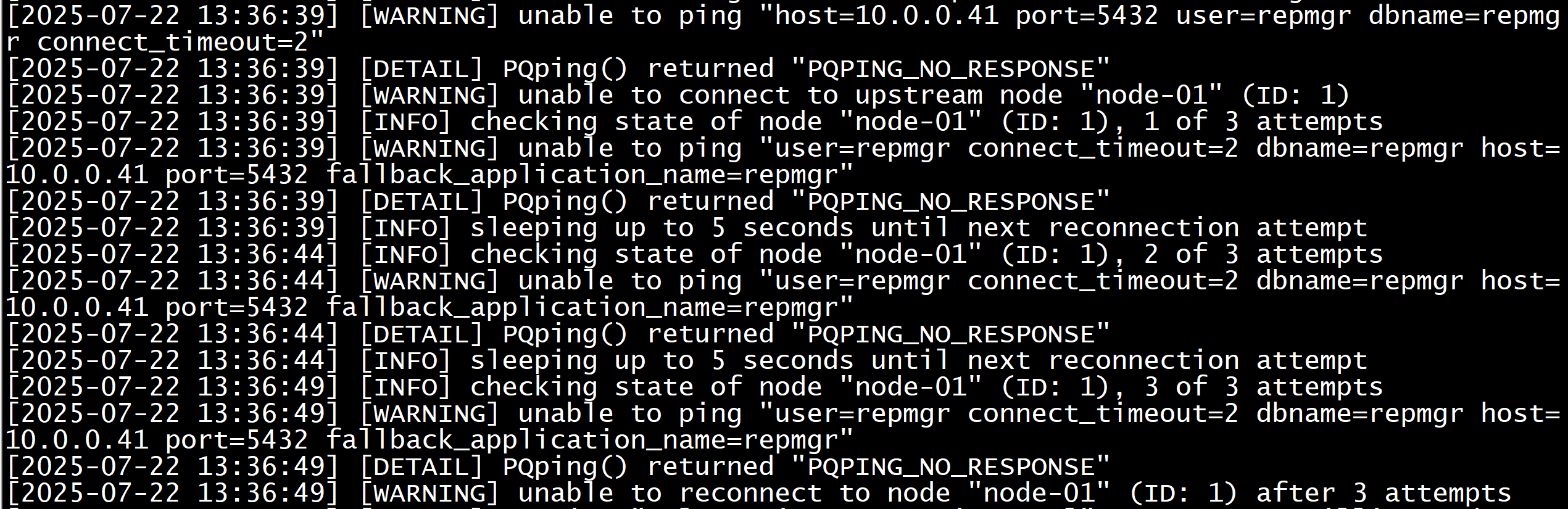
node-02作为主节点,在该节点上执行了触发脚本,成功被提升为主库,并且node-03节点作为从节点
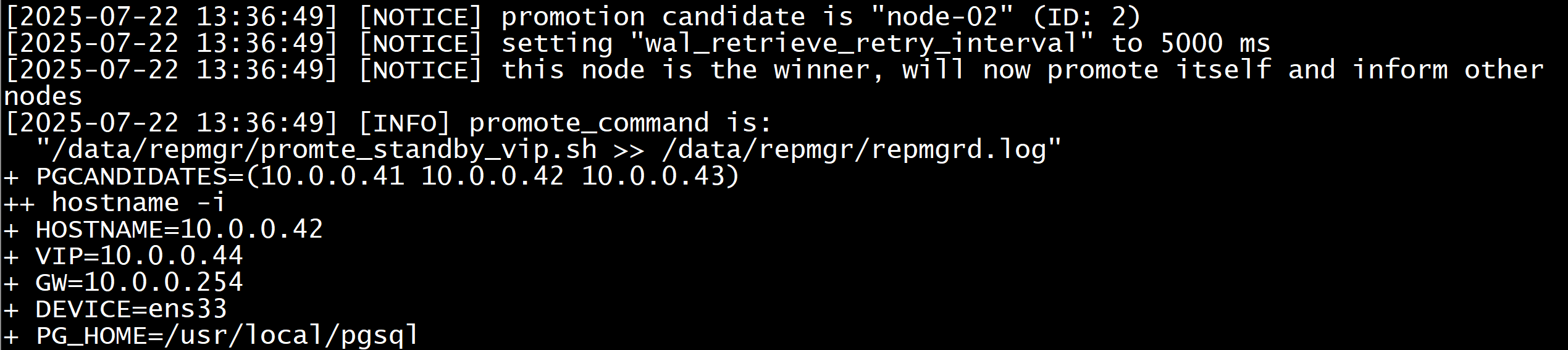


查看vip
vip漂移到了node-02节点
[postgres@repmgr02 ~]$ ip a| grep 10.0.0.44 inet 10.0.0.44/24 scope global secondary ens33通过vip连接主节点,查看从库信息
[postgres@repmgr02 ~]$ PGPASSWORD=\"repmgr\" psql -p 5432 -U repmgr -h 10.0.0.44 -d repmgrpsql (15.5)Type \"help\" for help.repmgr=# select * from pg_stat_replication\\gx