Elasticsearch_kibana设置索引生命周期
初识ES

需要下载Kibana和Elasticsearch。 Kibana一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示。注意在下载的时候两者版本需要保持一致并且位于同一网络下才能使用容器名来访问。
倒排索引
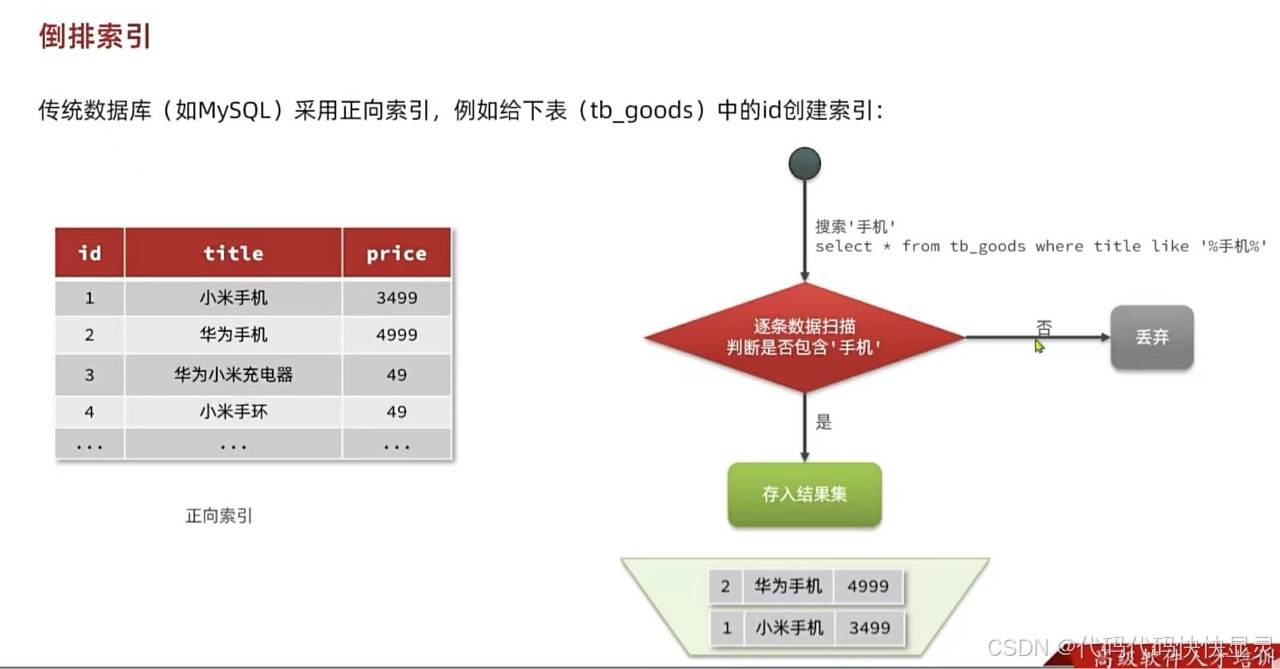
正向索引根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
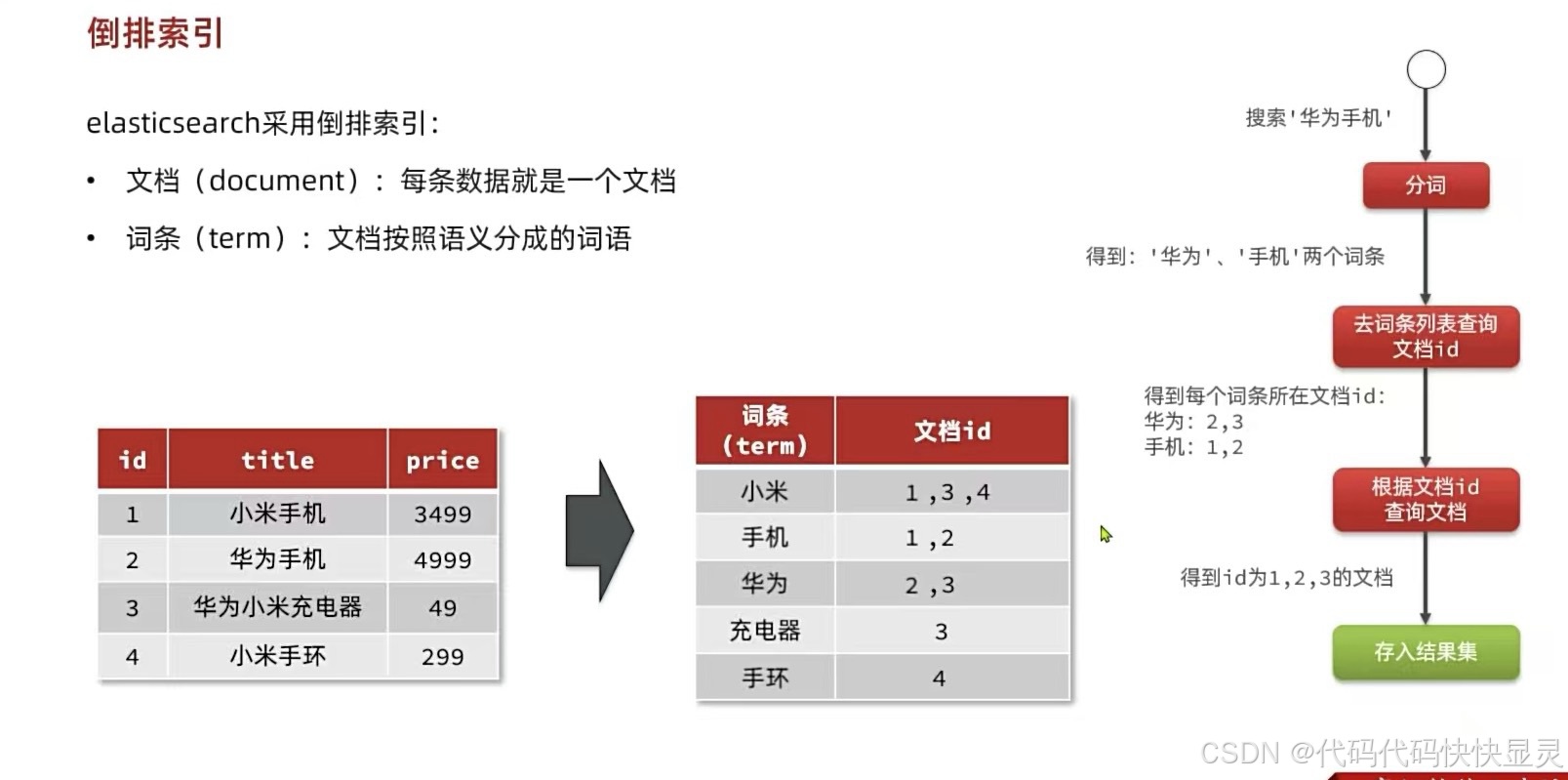
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法(例如IK分词器)分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
举例区别
正向索引(Forward Index)
假设我们有以下 3 篇文档:
- 文档 1(ID: 101):
今天天气很好 - 文档 2(ID: 102):
今天去公园玩 - 文档 3(ID: 103):
公园里有很多人
正向索引存储方式:
{ \"101\": [\"今天\", \"天气\", \"很好\"], \"102\": [\"今天\", \"去\", \"公园\", \"玩\"], \"103\": [\"公园\", \"里\", \"有\", \"很多\", \"人\"]}如果用户要搜索 “公园”,系统需要遍历所有文档,检查其中是否包含“公园”。
倒排索引(Inverted Index)
倒排索引的存储方式是 先将文档分成词条然后记录每个词在哪些文档中出现,比如:
{ \"今天\": [101, 102], \"天气\": [101], \"很好\": [101], \"去\": [102], \"公园\": [102, 103], \"玩\": [102], \"里\": [103], \"有\": [103], \"很多\": [103], \"人\": [103]}如果用户要搜索 “公园”,系统可以直接找到包含“公园”的文档 ID(102 和 103),然后快速获取对应的文档,而不需要遍历所有文档。
对比
倒排索引大大提高了搜索效率,因此现代搜索引擎(如 Elasticsearch、Lucene)都采用 倒排索引 来优化查询速度。
IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
注意,在虚拟机当中直接更改没有效果(可能是因为保存不了) ,需要我们在Windows当中编辑之后传入其中。

在IKAnalyzer.cfg.xml当中进行扩展词汇,ext.dic是扩展词汇。
具体可以查看黑马 day08-Elasticsearch - 飞书云文档 (feishu.cn)1.4节
基本概念
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
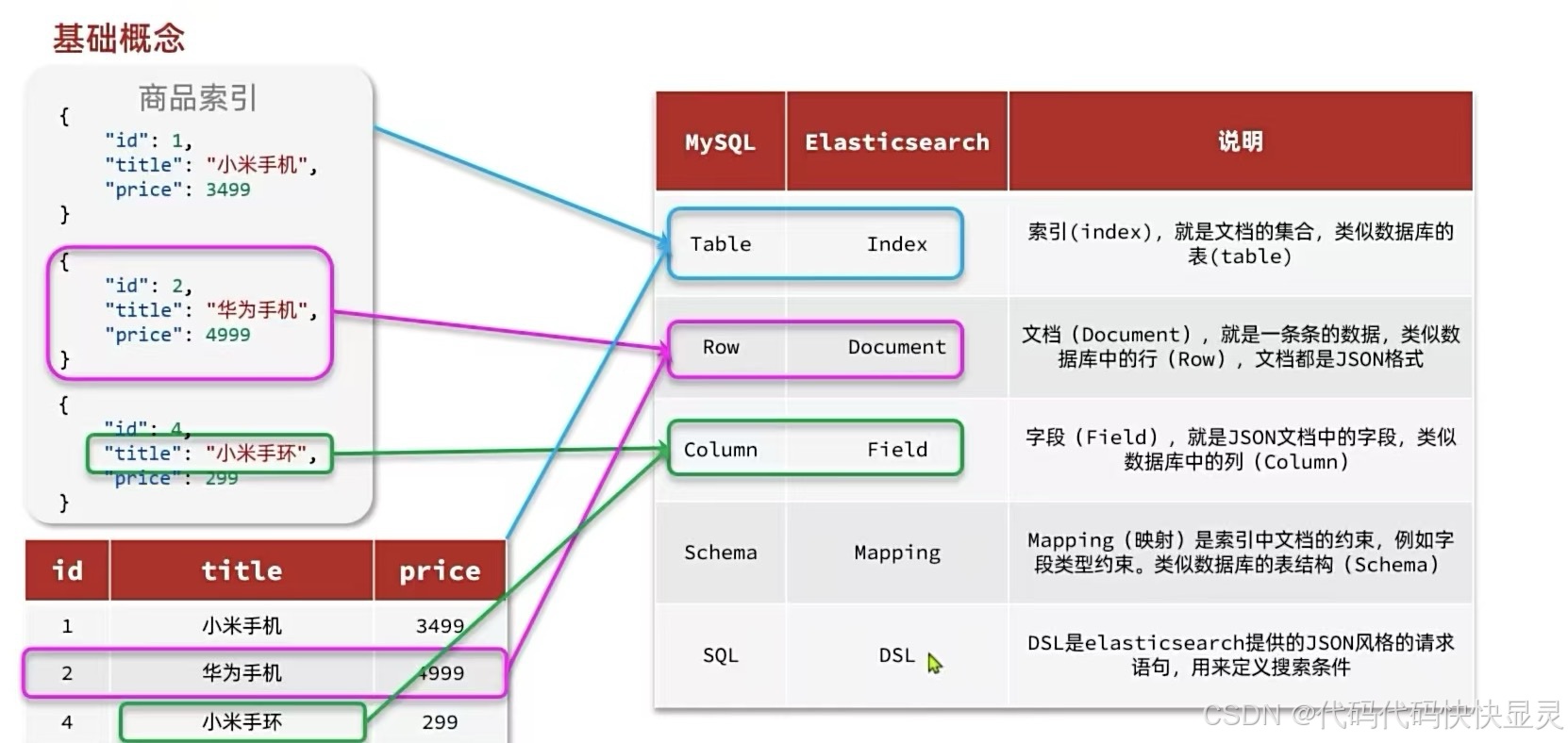
我们要将类型相同的文档集中在一起管理,称为索引(Index)。
索引库
mapping映射
Mapping 的作用
-
字段类型定义:指定每个字段的数据类型(如
text,keyword,integer,date等)。 -
分词控制:定义全文搜索字段的分词器(ik_smart)和搜索时的分词策略。
-
索引优化:控制字段是否被索引、是否存储原始值等。
-
数据格式验证:防止不符合格式的数据被写入索引。
核心字段属性
1. 常见数据类型
textkeywordlong, integer, short, bytedouble, float, half_floatbooleandateyyyy-MM-dd)。2. 关键参数
typetext, keyword)。indextrue/false),关闭后无法搜索。analyzerstandard, ik_smart)。search_analyzeranalyzer 一致)。fieldstext 字段添加 keyword 子字段)。formatyyyy-MM-dd HH:mm:ss)。查看索引的 Mapping
GET /my_index/_mapping更新 Mapping(只能添加新字段)
PUT /my_index/_mapping{ \"properties\": { \"new_field\": { \"type\": \"keyword\" } }}修改 Mapping 的限制
-
已有字段的类型不可修改(需重建索引)。
-
可新增字段,但需通过
PUT /index/_mapping更新映射。 -
若需修改现有字段,需通过
Reindex API迁移数据到新索引。
索引库操作
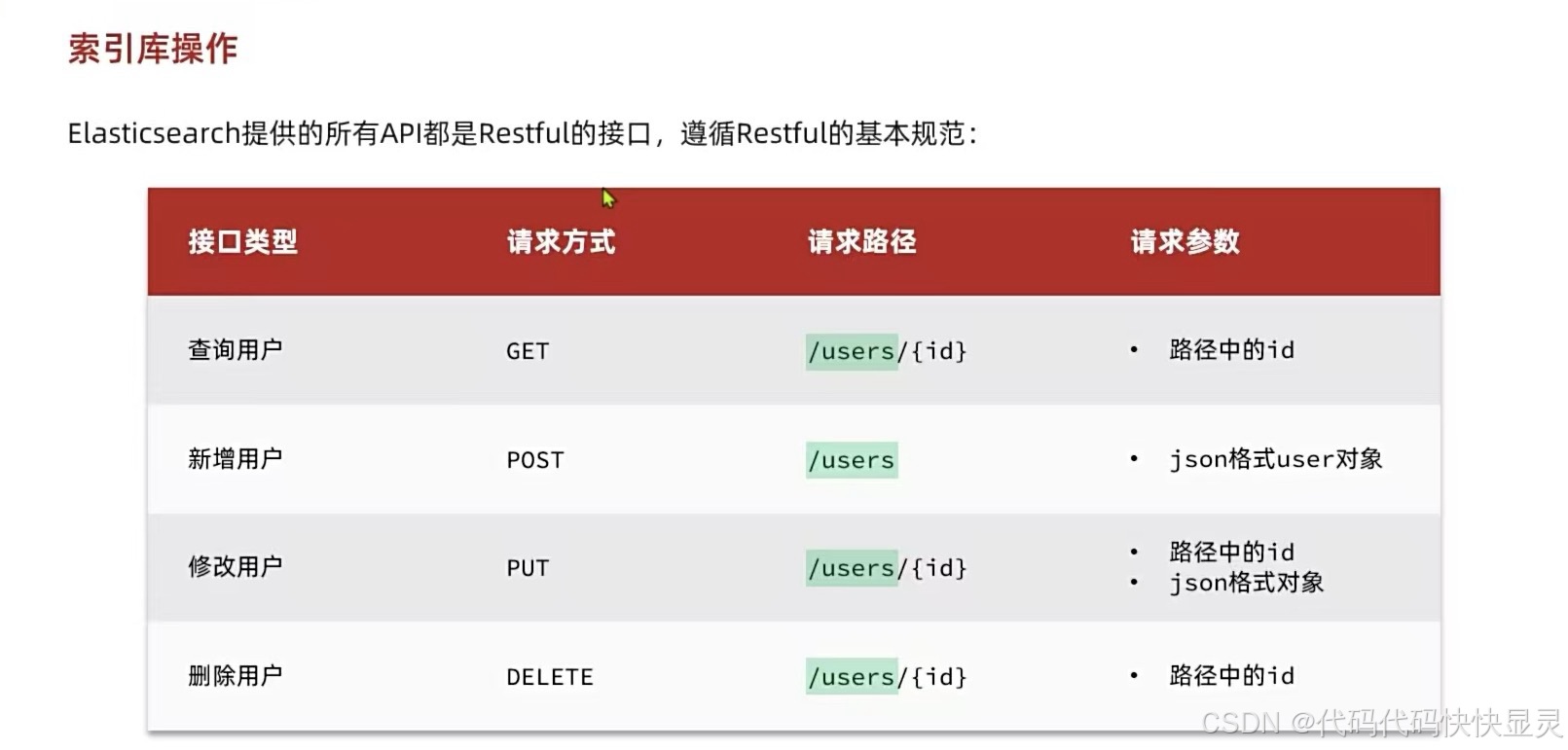



定义结构部分:
{ \"mappings\": { \"properties\": { \"id\": { \"type\": \"integer\" }, \"name\": { \"type\": \"keyword\" }, \"age\": { \"type\": \"integer\" }, \"bio\": { \"type\": \"text\" } } }}示例:
创建索引库:
PUT /orders{ \"mappings\": { \"properties\": { \"items\": { \"type\": \"nested\", // 保留数组内对象的独立性 \"properties\": { \"product\": { \"type\": \"keyword\" }, \"quantity\": { \"type\": \"integer\" } } } } }}嵌套类型
解决对象数组的独立性问题,保留子对象的关联性:
PUT /my_index{ \"mappings\": { \"properties\": { \"title\": { \"type\": \"text\", \"analyzer\": \"ik_max_word\", // 使用 IK 分词器 \"fields\": { \"keyword\": { \"type\": \"keyword\" } // 子字段用于精确匹配 } }, \"year\": { \"type\": \"integer\" }, \"published\": { \"type\": \"boolean\" } } }}查看索引信息
GET /my_index删除索引
DELETE /my_index文档操作

POST /my_index/_doc/1{ \"title\": \"Elasticsearch入门教程\", \"price\": 49.9, \"create_time\": \"2023-10-01 10:00:00\"} 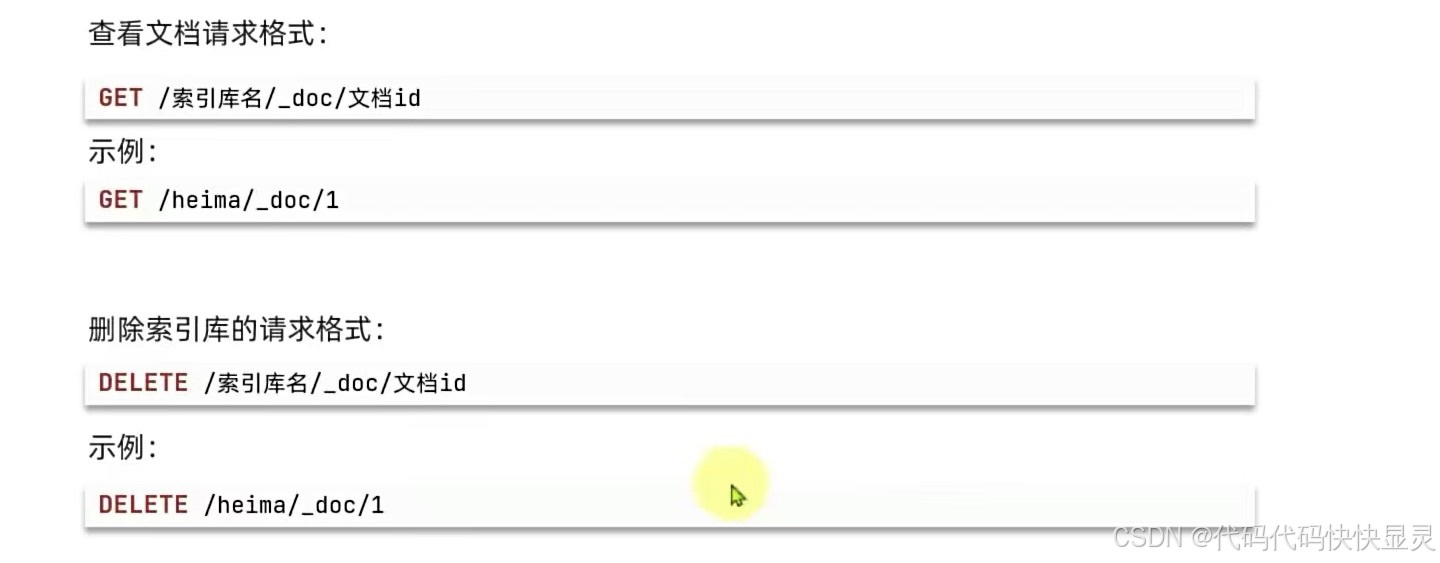
查询文档
GET /my_index/_doc/1删除文档
DELETE /my_index/_doc/1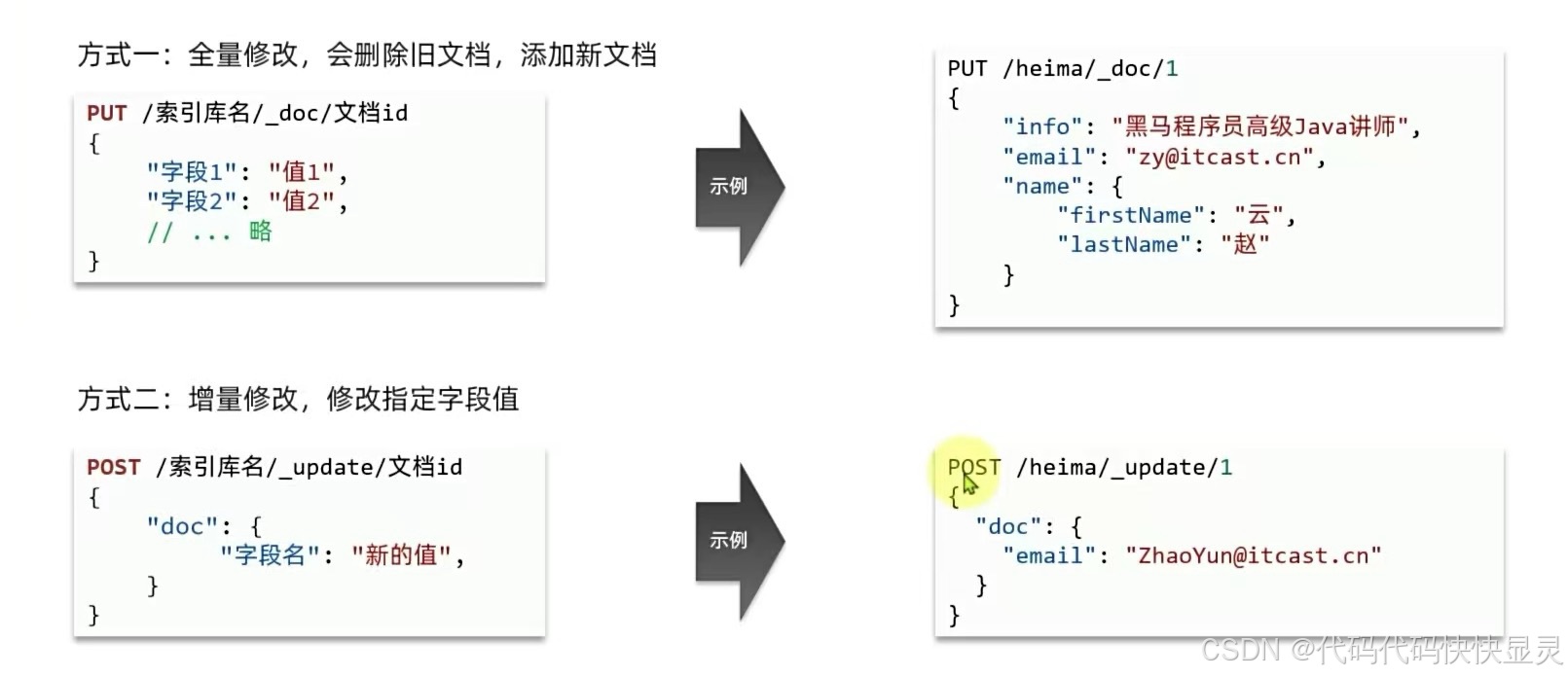
覆盖更新
PUT /my_index/_doc/1{ \"title\": \"Elasticsearch进阶教程\", \"price\": 59.9}局部更新(使用 _update)
POST /my_index/_update/1{ \"doc\": { \"price\": 69.9 }}
批量处理

批量写入文档
POST /my_index/_bulk{ \"index\": { \"_id\": 2 } }{ \"title\": \"Java编程思想\", \"price\": 89.9 }{ \"index\": { \"_id\": 3 } }{ \"title\": \"Python数据分析\", \"price\": 55.0 }批量删除
POST /my_index/_bulk{ \"delete\": { \"_id\": 2 } }{ \"delete\": { \"_id\": 3 } }综合使用
如果你希望控制字段类型、分词方式等,建议先创建索引,然后再添加文档。
示例:手动创建索引
PUT my_index{ \"mappings\": { \"properties\": { \"name\": { \"type\": \"keyword\" }, \"age\": { \"type\": \"integer\" }, \"bio\": { \"type\": \"text\", \"analyzer\": \"standard\" } } }}然后插入数据:
POST my_index/_doc/1{ \"name\": \"Alice\", \"age\": 25, \"bio\": \"Loves hiking and reading\"}JavaRestClient
索引库操作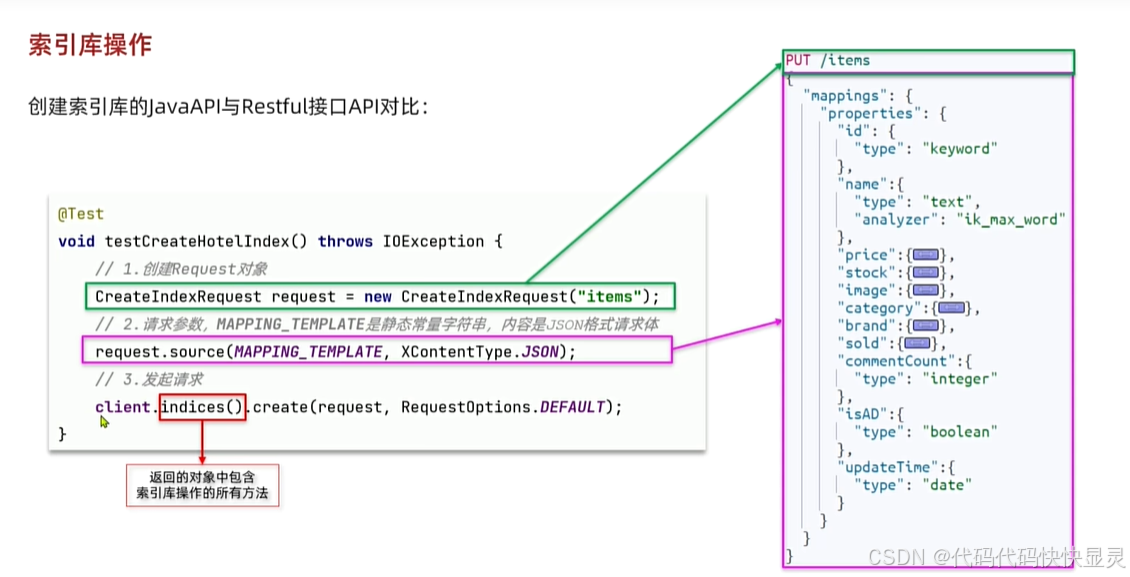

RestHighLevelClient
-
作用: Elasticsearch 官方提供的高级 REST 客户端,用于与 Elasticsearch 集群进行交互(注意:该客户端在 Elasticsearch 7.15 后已废弃,推荐改用新 Java API Client,但现有代码仍可运行)。
-
初始化: 在
setUp()方法中创建,连接到指定 Elasticsearch 节点的地址192.168.88.130:9200。
JUnit 生命周期方法
-
@BeforeEach void setUp(): 在每个测试方法执行前初始化客户端,确保测试独立性。 -
@AfterEach void tearDown(): 在每个测试方法执行后关闭客户端,释放资源,防止内存泄漏。
public class ElasticIndexTest { private RestHighLevelClient client; @BeforeEach void setUp() { client = new RestHighLevelClient(RestClient.builder( HttpHost.create(\"192.168.88.130:9200\") )); } @AfterEach void tearDown() throws IOException { if (client != null) { client.close(); } }}// 增加索引库 @Test void testCreateIndex() throws IOException { // 先创建Request对象 CreateIndexRequest request = new CreateIndexRequest(\"items\"); // 准备请求参数 request.source(MAPPING_TEMPLATE, XContentType.JSON); // 发送请求 client.indices().create(request, RequestOptions.DEFAULT); }// 获取索引库 @Test void testGetIndex() throws IOException { // 先创建Request对象 GetIndexRequest request = new GetIndexRequest(\"items\"); // 发送请求// client.indices().get(request,RequestOptions.DEFAULT); boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println(\"exists = \"+ exists); }// 删除索引库 @Test void testDelIndex() throws IOException { // 先创建Request对象 DeleteIndexRequest request = new DeleteIndexRequest(\"items\"); // 发送请求// client.indices().get(request,RequestOptions.DEFAULT); client.indices().delete(request,RequestOptions.DEFAULT); }8.0版本
RestHighLevelClient 已废弃,推荐使用新 Java API Client。
// 替换依赖(pom.xml) co.elastic.clients elasticsearch-java 8.12.0// 新客户端初始化RestClient restClient = RestClient.builder( HttpHost.create(\"192.168.88.130:9200\")).build();ElasticsearchClient client = new ElasticsearchClient( new RestClientTransport(restClient, new JacksonJsonpMapper()));RestClient restClient = RestClient.builder( HttpHost.create(\"localhost:9200\")).build();ElasticsearchClient client = new ElasticsearchClient( new RestClientTransport(restClient, new JacksonJsonpMapper()));IndexRequest request = IndexRequest.of(b -> b .index(\"test_index\") .id(\"1\") .document(Map.of(\"field\", \"value\")));IndexResponse response = client.index(request);文档操作
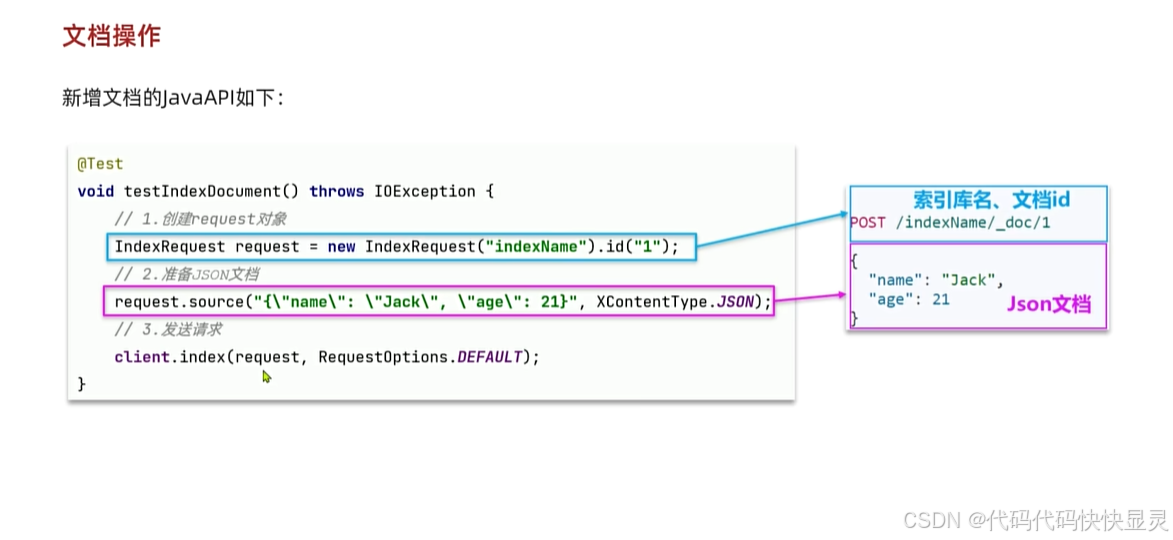
/** * 新增操作 当id存在时就是修改 * @throws IOException */ @Test void testIndexDoc() throws IOException { // 准备文档数据 // 从数据库查询 Item item = itemService.getById(1013324L);// item.setPrice(29900); // 进行转化 ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class); // 准备Request IndexRequest request = new IndexRequest(\"items\").id(item.getId().toString()); // 准备请求参数 request.source(JSONUtil.toJsonStr(itemDoc),XContentType.JSON); // 发送请求 client.index(request,RequestOptions.DEFAULT); }
/** * 获取 * @throws IOException */ @Test void testGetDoc() throws IOException { // 准备Request GetRequest request = new GetRequest(\"items\").id(\"1013324\"); // 发送请求 GetResponse response = client.get(request, RequestOptions.DEFAULT); String json = response.getSourceAsString(); ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class); System.out.println(\"doc = \" + doc); }删除:
/** * 删除 * @throws IOException */ @Test void testDelDoc() throws IOException { // 准备Request DeleteRequest request = new DeleteRequest(\"items\").id(\"1013324\"); // 发送请求 client.delete(request,RequestOptions.DEFAULT); }
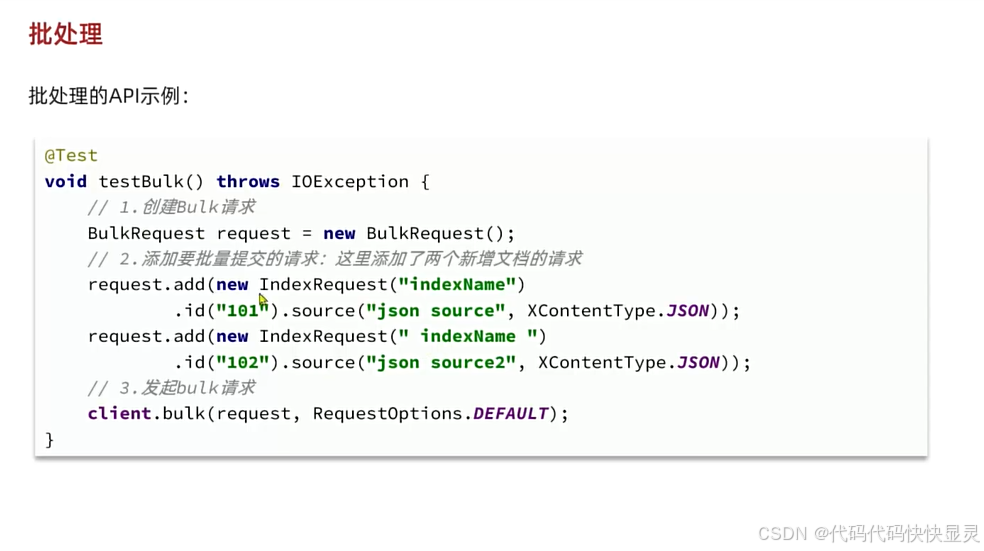
@Test void testUpdateDoc() throws IOException { // 准备Request UpdateRequest request = new UpdateRequest(\"items\",\"1013324\"); // 参数 request.doc( \"price\",29900 ); // 发送请求 client.update(request,RequestOptions.DEFAULT); } @Test void testBulkDoc() throws IOException { // 准备文档数据 // 从数据库查询 int pageNo = 1; int pageSize = 500; while(true) { Page page = itemService.lambdaQuery() .eq(Item::getStatus, 1) .page(Page.of(pageNo, pageSize)); List records = page.getRecords(); // 未查到 if (records == null || records.isEmpty()) { return; } // 准备Request BulkRequest request = new BulkRequest(); // 准备请求参数 for (Item item : records) { // 进行转化 ItemDoc doc = BeanUtil.copyProperties(item, ItemDoc.class); request.add(new IndexRequest(\"items\").id(doc.getId()).source(JSONUtil.toJsonStr(doc), XContentType.JSON)); }// request.add(new DeleteRequest(\"items\").id(\"1\")); // 发送请求 client.bulk(request, RequestOptions.DEFAULT); // 翻页 pageNo++; } } 批量处理
批量处理
Elasticsearch Java API 查询操作 请求方式总结
QueryBuilders.matchAllQuery()request.source().query(QueryBuilders.matchAllQuery());SearchResponseQueryBuilders.termQuery()request.source().query(QueryBuilders.termQuery(\"field\", \"value\"));SearchResponseQueryBuilders.rangeQuery()request.source().query(QueryBuilders.rangeQuery(\"field\").gte(10).lte(100));SearchResponseQueryBuilders.boolQuery()request.source().query(QueryBuilders.boolQuery().must(...).filter(...));SearchResponse.from(...).size(...)request.source().query(...).from(0).size(10);SearchResponse.sort(...)request.source().query(...).sort(\"field\", SortOrder.ASC);SearchResponseHighlightBuilderrequest.source().query(...).highlighter(new HighlightBuilder().field(\"field\"));SearchResponseAggregationBuilders.terms()request.source().aggregation(AggregationBuilders.terms(\"aggName\").field(\"field\"));SearchResponse

