LinkedList的模拟实现+LinkedList和ArrayList的区别
目录
LinkedList的模拟实现
什么是双向链表
增加数据
头插法:
尾插法:
指定的下标插入:
删除数据
删除双向链表中出现的第一个key
置空所有数据
LinkedList和ArrayList的区别
顺序表对应的集合类是ArrayList;链表对应的集合类是LinkedList,在Java集合框架中,它们是两种最基础也是最常用的数据结构实现,它们的底层实现原理和性能差异是怎么样的呢?这里我们先来模拟实现LinkedList;
LinkedList的模拟实现
什么是双向链表
首先,我们要知道的是LinkedList的底层使用了双向链表,那么什么是双链表呢?我们前面学过单链表是由一个个节点组成,节点中包括数据域和指针域的一个链表其中指针域存放着下一个节点的地址值:
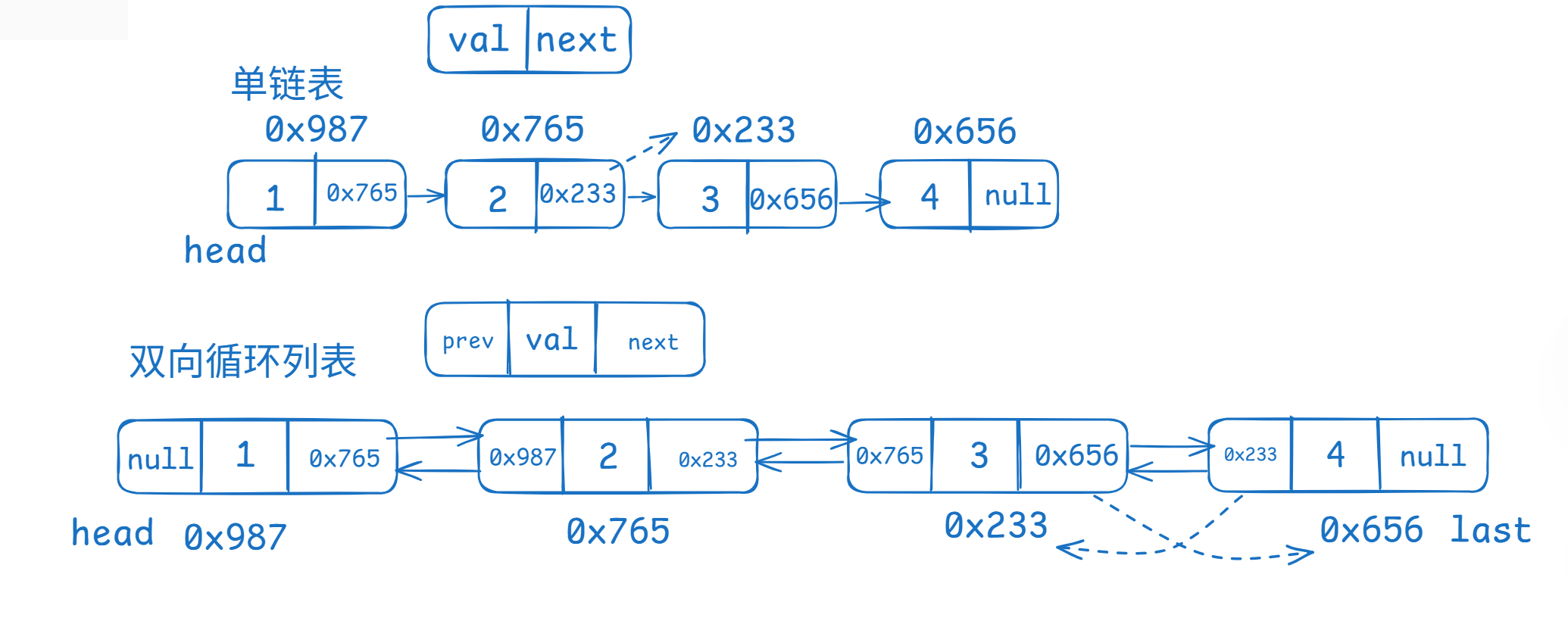
双向链表同样也是由一个个节点组成,多了个prev指针,指向前驱节点的地址,和一个last指针指向最后一个节点;那么我们如何构建一个双向链表呢?基于单链表的学习,双向链表我们模仿单链表的样式去写就简单很多了:
//1.想构成链表的是?->节点由什么组成?定义变量 一个节点为一个对象定义成内部类 static class ListNode{ public int val; public ListNode next; public ListNode prev; //构造一个节点,只需要实例化 public ListNode(int val) { this.val = val; } } //指向节点的一些指针 public ListNode head; public ListNode last;//始终指向最后一个节点这样写好一个链表的基本结构我们就可以为这个链表写一些操作方法了;双向链表有一些操作时不太涉及prev指针域的,这些操作是跟前面学习的单链表一致的,比如:链表打印display、表长size、查找链表的元素contains、这里就不重复记录了;具体看单链表的手动实现+相关习题,这里主要介绍与单链表有点区别的操作。
增加数据
头插法:
public void addFirst(int data) { //1.实例化一个节点 ListNode node = new ListNode(data); //2.链表尾空 if (head == null){ head = node; last = node; }else { node.next = head;//先绑定后面 head.prev = node; head = node; } return; }双向链表中有两个指针域,操作节点是要尤其注意操作指针域的顺序,要避免数据丢失的情况。
尾插法:
public void addLast(int data) { ListNode node = new ListNode(data); if (head == null){ head = node; last = node; }else { last.next = node; node.prev = last; last = node;//注意要更新last节点,保证last是最后一个节点 } }指定的下标插入:
在指定下标位置进行插入时,我们重点要关注的是中间插入元素是的操作顺序
public void addIndex(int index, int data) { ListNode node = new ListNode(data); //1.判断index合法性 if (index size()){ throw new IndexException(\"index非法\" + index); } //2.index为0时,头插 if (index == 0){ addFirst(data); return; } //index为size时,尾插 if (index == size()){ addLast(data); return; } //3.找index ListNode cur = findIndex(index); //注意顺序 node.next = cur; cur.prev.next = node; node.prev = cur.prev; cur.prev = node; } private ListNode findIndex(int index){ ListNode cur = head; int count = 0; while (count != index){//因为是双向链表,可以访问到节点的前驱和后继,所以不用跟单链表一样找index-1 cur = cur.next; count++; } return cur; }删除数据
删除双向链表中出现的第一个key
注意:删除时要考虑到所有特殊的情况,比如删除头结点、尾结点、链表只有一个节点的情况:
public void remove(int key) { //遍历找key ListNode cur = head; while (cur != null){ if (cur.val == key ){ //1.要删的节点是头结点 if (cur == head){ head = head.next; if (head != null){ head.prev = null; }else { //链表只有一个节点且是需要删除的节点,也得置空 last = null; } return; }else { if (cur.next == null){ //删除尾结点 cur.prev.next = null; last = last.prev; }else { //删除中间节点 cur.prev.next = cur.next; cur.next.prev = cur.prev; } } return; } cur = cur.next; } }删除第一个key值得代码我们写出来了,那么删除所有key值也非常得简单了,把return去掉让他继续往下遍历往下删除即可;
置空所有数据
我们可以直接简单粗暴的分别把head和last置空,导致整个表置空;也可以把每个节点的指针域依次置空 ,本质上两种方法时一样的:
public void clear() { //循环把节点依次置空 ListNode cur = head; while (cur != null){ //定义一个指针指向即将被删除的节点,记录下下一个要被删除的节点 ListNode curNext = cur.next; cur.prev = null; cur.next = null; cur = curNext; } this.head = null; this.last = null; }LinkedList和ArrayList的区别
存储空间方面:
-
ArrayList:物理存储和逻辑顺序都是连续的(基于动态数组实现)。
-
LinkedList:逻辑上是连续的,但物理存储不一定连续(基于双向链表实现)。
查找修改效率:
-
ArrayList是数组结构,支持随机访问,可以直接通过索引定位元素,效率极高O(1);修改的第一步也是要访问,所以修改的时间复杂度也为O(1)
-
LinkedList不支持随机存取,必须从头或尾遍历链表,访问效率较低O(n)
插入和删除元素效率:
-
ArrayList 插入或删除除了头节点和尾结点元素时,需要移动后续所有元素,效率较低O(n)
-
LinkedList只需调整相邻节点的指针,无需移动数据,效率更高O(1)
扩容机制:
-
ArrayList:采用静态分配,初始容量固定,扩容时需要重新分配更大的数组并复制数据,时间复杂度 O(n)。可能导致空间浪费或频繁扩容。
-
LinkedList:动态分配,每次插入新元素时才分配内存,无需扩容。没有容量限制,但每个节点需要额外存储指针,占用更多内存。
适用场景:
-
ArrayList:适合读多写少的场景,。
-
LinkedList:适合增删频繁的场景。
感谢大家阅读📚点赞👍收藏⭐评论✍关注❤
博客主页: 【长毛女士-CSDN博客】

