Llama-Index调用外部大模型API_llamaindex 调用硅基流动
目录
1、调用embedding模型
2、调用LLM
3、调用重排模型
由于本地电脑上没有GPU,跑rag不方便,所以需要调用外部api的服务。但是网上关于llama-index如何调用外部embedding和llm以及rerank的方法找不到,所以搞明白之后记录一下方便以后使用
llama-index针对每个api服务商,都提供了一个专门的接口,这点与langchain不同。以硅基流动的api为例。
1、调用embedding模型
在使用硅基流动的模型之前,需要先去硅基流动官网(SiliconCloud)注册账号,新建一个api密钥。
在llama-index官网可以查看要调用的函数:Siliconflow - LlamaIndex。官网并没有提供调用的示例,但是在llama-index-embeddings-siliconflow · PyPI有调用的示例:
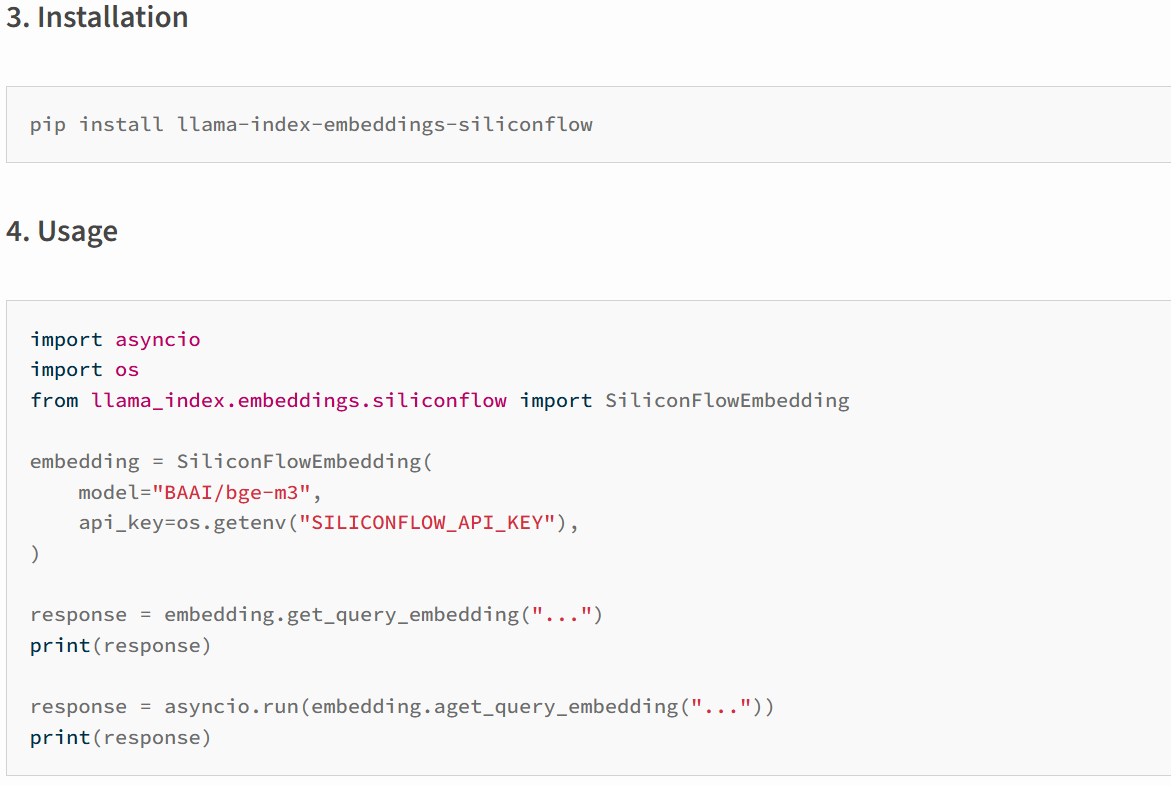
这里提醒我们需要先安装依赖包(官网是没有提醒的):
# llama-index更新频繁,默认下载最新版本的,这样的话有问题可以看官网文档pip install llama-index-embeddings-siliconflow下载完依赖包后,调用embedding模型的api:
from llama_index.embeddings.siliconflow import SiliconFlowEmbeddingimport osembed_model = SiliconFlowEmbedding( model_name=\"netease-youdao/bce-embedding-base_v1\", api_key=\"sk-你自己的硅基流动的api\", # api_key = os.getenv(\"SILICONFLOW_API_KEY\"), api_base=\"https://api.siliconflow.com/v1\")response = embed_model.get_query_embedding(\"一个星期有几天?\")print(len(response))2、调用LLM
调用LLM的官网文档:Siliconflow - LlamaIndex。llama-index的嵌入模型和llm调用的位置不一致,一个在embedding下面,一个在llm下面,查找官网文档的时候需要注意一下。在这里也可以找到接入其他厂商的api的文档:
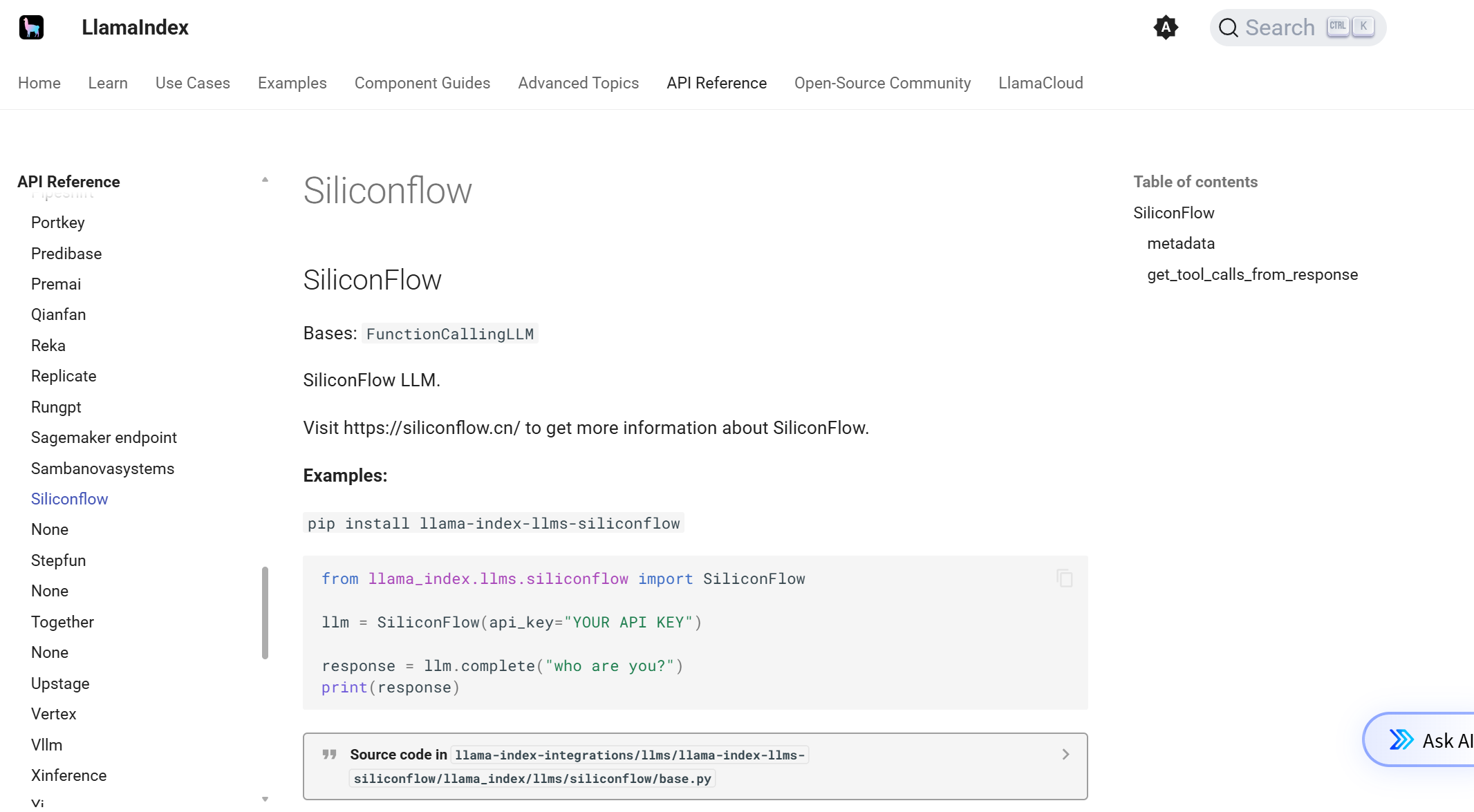
这里,关于llm的文档比embedding的文档要全。根据文档,需要先下载依赖包:
pip install llama-index-llms-siliconflow然后调用硅基流动的模型。
from llama_index.llms.siliconflow import SiliconFlowllm = SiliconFlow( model=\"Qwen/Qwen2.5-7B-Instruct\", api_key=\"sk-你自己的硅基流动api\", # api_key = os.getenv(\"SILICONFLOW_API_KEY\"), api_base=\"https://api.siliconflow.com/v1\")print(llm.complete(\"你好,请介绍一下你自己。\"))3、调用重排模型
重排模型在官网中不好找,而且找到之后也没有使用示例。但是我在llama-index-postprocessor-siliconflow-rerank · PyPI找到了使用示例。

需要先下载相关的包,相关代码在llama-index-postprocessor-siliconflow-rerank · PyPI网页最上面,我没截下来:
pip install llama-index-postprocessor-siliconflow-rerank使用示例的代码:
from llama_index.postprocessor.siliconflow_rerank import SiliconFlowRerank# 不需要填写base_urlreranker = SiliconFlowRerank( model=\"BAAI/bge-reranker-v2-m3\", api_key=\"sk你自己的硅基流动api\", # api_key = os.getenv(\"SILICONFLOW_API_KEY\"), top_n=4,)from llama_index.core.schema import NodeWithScore, TextNode# 手动创建测试用的节点nodes = [ NodeWithScore( node=TextNode(text=\"Python是一种高级编程语言,以其简单性和可读性而闻名。\"), score=0.42 ), NodeWithScore( node=TextNode(text=\"Java是一种面向对象的编程语言,可在数十亿台设备上运行。\"), score=0.42 ), NodeWithScore( node=TextNode(text=\"JavaScript是一种支持交互式网页的编程语言。\"), score=0.33 ), NodeWithScore( node=TextNode(text=\"C++是一种用于系统/软件开发的强大编程语言。\"), score=0.52 ), NodeWithScore( node=TextNode(text=\"Ruby是一种动态的开源编程语言,注重简单性。\"), score=0.62 )]# 定义一个 queryquery = \"Python是一种什么语言?\"# 通过 reranker 处理节点reranked_nodes = reranker.postprocess_nodes(nodes=nodes, query_str=query)# 打印结果print(\"原始节点顺序:\")for i, node in enumerate(nodes): print(f\"{i+1}. Score: {node.score:.2f} - {node.node.text}\")print(\"\\n重新排序后的节点:\")for i, node in enumerate(reranked_nodes): print(f\"{i+1}. Score: {node.score:.2f} - {node.node.text}\")这里我把与问题最相关的内容的初始分数设置的比较低,但是经过重排后,可以看到“Python是一种高级编程语言,以其简单性和可读性而闻名。”仍具有最高的相似性分数。



