Java List深度复制技术实现与应用
本文还有配套的精品资源,点击获取 
简介:在Java中,复制List时需区分浅复制与深复制。浅复制仅复制对象引用,而深复制递归复制所有引用的对象。本文探讨了如何利用Java的序列化机制及手动复制属性两种方法实现List的深复制,特别针对可变对象进行阐述,并提供了相应的实现示例。
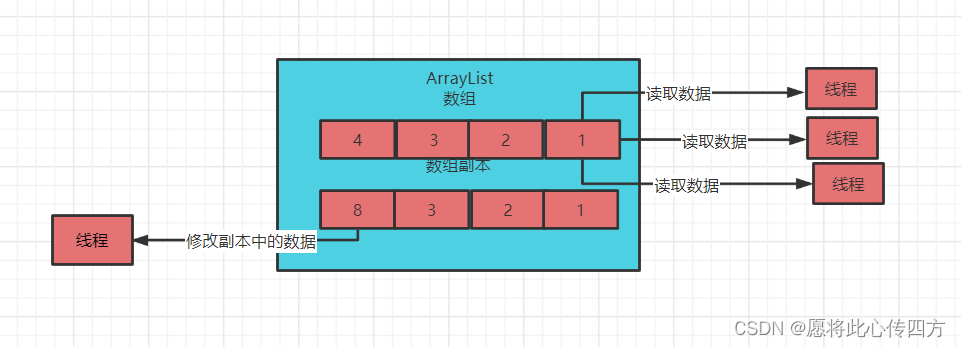
1. 浅复制与深复制的区别
在软件开发过程中,复制对象是一项常见的操作,但不是所有的复制都是平等的。理解浅复制与深复制之间的差异,对于有效地管理复杂数据结构至关重要。本章将介绍浅复制与深复制的基本概念,以及它们之间显著的区别。
1.1 浅复制与深复制的概念
浅复制(Shallow Copy)指的是创建一个新的集合或对象,但是其中包含的引用类型的元素仍然是原始元素的引用。这意味着,如果集合中的元素包含其他对象的引用,浅复制将不会复制这些内部对象。
1.2 浅复制的影响
由于浅复制并不复制内部对象,因此对原始对象的任何更改都会影响到复制对象。这在处理包含多个引用元素的集合时尤其危险,可能引起数据不一致或潜在的逻辑错误。
1.3 深复制的必要性
深复制(Deep Copy)则不同,它不仅复制集合本身,还会递归复制集合中的所有对象,直到最基本的元素。这样,复制的对象和原始对象在内存中完全独立,对其中一个的修改不会影响到另一个。
通过深入浅出地讲解浅复制和深复制的概念及区别,下一章我们将探讨在Java中如何实现List的浅复制,并讨论其中存在的潜在问题。
2. Java中List的浅复制方法
2.1 浅复制的基本概念及实现
2.1.1 浅复制定义及其影响
浅复制,也就是Shallow Copy,在Java中指的是复制对象本身,而不复制对象内部引用的其他对象。浅复制的对象和原始对象共用内部的引用对象,这就意味着如果内部的引用对象被修改,原始对象和复制对象都会受到影响。理解浅复制的关键在于理解对象引用与实际对象存储的差异。在Java中,对象是通过引用传递的,而非实际值的复制。
2.1.2 浅复制在List中的应用及问题
在Java的List集合中实现浅复制十分简单,通常使用List的构造函数或者 Collections.copy() 方法来达到复制的效果。但这种复制方法会引发一系列问题,尤其是在处理嵌套对象或包含引用类型元素的List时。当List中的元素是对象引用时,浅复制的List中的元素仍然指向同一个对象。如果修改了原List中某个元素指向的对象,复制出的List也会看到这一改变。
举个具体的例子,假设有一个包含自定义对象的List,自定义对象中又引用了其他对象,通过浅复制方法复制这个List后,如果更改了原List中自定义对象引用的内部对象,复制出来的List中对应的自定义对象也会受到影响,因为它们都指向同一个内部对象。
2.2 浅复制对不可变对象的影响
2.2.1 不可变对象与复制的关系
在Java中,不可变对象指的是对象的状态在其生命周期内无法更改的对象。对于这些对象,浅复制和深复制之间的区别就显得微乎其微,因为即使复制了引用,我们也不会改变对象本身的状态。不可变对象通常包括 String 类和所有包装类(如 Integer 、 Double 等)。它们在初始化后,其属性值不能再被修改。
2.2.2 不可变对象在List浅复制中的特性
由于不可变对象的特性,即使在List中使用浅复制,也不会遇到因对象状态改变导致的问题。在浅复制过程中,不可变对象会被复制其引用,但由于不可变性,复制出的List不会表现出与原List不同的行为。这简化了浅复制在不可变对象集合中的使用,但同时意味着浅复制并没有带来预期的分离效果。
以Java中的 String 类为例,当你创建一个新的字符串实例时,实际上并没有创建一个新的字符串,而是创建了一个指向已有字符串常量池中字符串的新引用。因此,即使进行List的浅复制,也不会有实质性的复制行为发生。例如:
String a = \"hello\";String b = a;List list1 = new ArrayList();list1.add(a);List list2 = new ArrayList(list1);System.out.println(list1.get(0) == list2.get(0)); // 输出 true 在这个例子中, list1 和 list2 中的字符串对象 a 都是对同一个字符串的引用。
接下来,我们将详细探讨如何通过Java序列化实现List的深复制,这将涉及到对象的完整状态复制,以及如何处理对象之间的依赖关系。
3. 利用序列化实现List的深复制
3.1 序列化与反序列化的基本原理
3.1.1 Java序列化的定义及机制
在Java中,序列化(Serialization)是指将对象状态转换为可以保存或传输的形式的过程。在序列化过程中,一个对象被转换成一系列的字节,而这些字节可以存储在文件中,或通过网络传输到另一个网络节点,当需要时,这些字节可以反序列化成对象。
序列化机制是通过实现 Serializable 接口来启用的。当一个类实现了这个接口,它就能够被转换成字节流,并且能够从字节流中恢复回来。序列化过程不仅保存了对象的 public 、 protected 和包级 private 字段的状态,还保存了对象的超类和子对象的类类型信息。
import java.io.Serializable;public class MyObject implements Serializable { private static final long serialVersionUID = 1L; // Other fields...} 在上述代码中, MyObject 类通过实现 Serializable 接口启用了序列化机制。序列化ID( serialVersionUID )是一个版本控制字段,有助于确保序列化的兼容性。
3.1.2 序列化与对象状态的关系
对象的状态通常包括其字段的值。在序列化时,这些状态信息被保存,使得对象可以被完整地重建。序列化是对象持久化的一种形式,允许将对象的状态持久化存储在文件系统中或通过网络传输到其他地方。
反序列化是序列化的逆过程,它将字节流重新构建成原始对象。序列化和反序列化机制对于实现对象的深复制至关重要,因为它们能够确保对象中的所有字段,包括那些引用其他对象的字段,都能够被复制并保持其状态。
3.2 序列化实现List深复制的步骤
3.2.1 利用ObjectOutputStream进行序列化
ObjectOutputStream 是Java序列化机制的关键类之一,它可以将Java对象写入到输出流中。为了实现List的深复制,首先需要创建一个 ObjectOutputStream 实例,然后将其与输出流相关联。接着,可以利用 writeObject() 方法将List对象序列化到输出流中。
下面的示例展示了如何通过 ObjectOutputStream 序列化一个List对象:
import java.io.FileOutputStream;import java.io.ObjectOutputStream;import java.util.ArrayList;import java.util.List;public class DeepCopySerialized { public static void main(String[] args) throws Exception { List listToSerialize = new ArrayList(); // Add elements to the list // ... try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(\"list.ser\"))) { oos.writeObject(listToSerialize); } }} 在上述代码中,首先创建了一个 ArrayList ,填充了需要序列化的对象。然后,使用 FileOutputStream 创建了一个文件输出流,将要写入的对象序列化到名为”list.ser”的文件中。
3.2.2 利用ObjectInputStream进行反序列化
反序列化过程利用 ObjectInputStream 类,它负责从输入流中读取字节流,并重构对象。为了完成List的深复制,需要创建一个 ObjectInputStream 实例,并使用 readObject() 方法从之前序列化得到的文件中读取对象。
下面的示例展示了如何通过 ObjectInputStream 反序列化之前保存的List对象:
import java.io.FileInputStream;import java.io.ObjectInputStream;import java.util.ArrayList;import java.util.List;public class DeepCopySerialized { public static void main(String[] args) throws Exception { try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(\"list.ser\"))) { List listDeserialized = (List) ois.readObject(); // Now listDeserialized is the deep-copied list of original listToSerialize } }} 在这个例子中,通过 FileInputStream 读取之前保存为文件”list.ser”的对象,并通过 ObjectInputStream 反序列化。反序列化得到的对象现在存储在 listDeserialized 变量中,这个变量是一个与原始列表完全独立的深复制版本。
至此,利用Java序列化机制实现List深复制的完整步骤已经演示完毕。需要注意的是,使用序列化实现深复制虽然简单,但是序列化与反序列化的过程可能会比较慢,并且可能带来安全风险,特别是当序列化流不能被完全信任时。因此,这种机制更加适合于对象不是很大,且对性能要求不是特别高的场景。
4. ```
第四章:手动复制List元素实现深复制
手动复制List元素来实现深复制是处理复杂对象复制的一种方法。它允许开发者完全控制复制过程,适用于简单的数据结构或者当标准的复制机制(如clone()方法)不满足需求时。本章节将详细探讨手动复制的方法、操作流程以及在深复制中处理循环引用时所面临的挑战。
4.1 手动复制的基本思路
4.1.1 手动复制的定义与必要性
手动复制是指开发者编写代码逐个复制对象的字段,创建一个新的对象实例。与浅复制不同,手动复制确保了新创建的对象与原始对象在内存中的地址完全不同,即深复制。在深复制中,任何对原始对象的修改都不会影响到复制后的对象。
在某些情况下,类中包含了不可克隆的字段或者需要特殊的复制逻辑,使用clone()方法或者序列化/反序列化手段可能会遇到限制。此时,手动复制提供了一种灵活的方式,尽管它可能会比其他方法更加繁琐。
4.1.2 手动复制在List中的操作流程
手动复制List元素的流程可以分为以下步骤:
1. 遍历原始List中的所有元素。
2. 对于每个元素,检查它的类型,并确定复制逻辑。
3. 创建与原对象相同类型的对象实例。
4. 将原对象中的每个字段复制到新创建的对象中。
5. 将新对象添加到新的List中。
下面是一个简单的手动复制List的Java代码示例:
public List deepCopyList(List originalList) { List newList = new ArrayList(); for (MyObject obj : originalList) { MyObject newObj = new MyObject(); newObj.setField1(obj.getField1()); newObj.setField2(obj.getField2()); // ... newList.add(newObj); } return newList;} 在这个例子中, MyObject 是需要复制的类,它有多个字段。方法 deepCopyList 接受一个原始的List,并返回一个新的包含深复制对象的List。
4.2 深复制中的循环引用问题
4.2.1 循环引用的定义及危害
在对象图中,循环引用是指两个或多个对象相互引用,形成闭环。在深复制过程中,如果不适当处理循环引用,可能会导致无限递归,最终导致 StackOverflowError 。
循环引用的危害不仅限于复制过程中的错误,它还可能影响对象的序列化和反序列化。在没有正确处理循环引用的情况下,序列化可能会陷入无限循环,导致资源耗尽。
4.2.2 如何避免循环引用导致的错误
为了避免循环引用带来的问题,可以采用以下策略:
- 使用一个HashMap来存储已经复制的对象和它们的新实例。当复制一个对象时,首先检查它是否已经存在于HashMap中。
- 如果已存在,则直接使用已复制的对象引用;如果不存在,则创建一个新实例并保存到HashMap中。
- 在复制完所有对象之后,清除HashMap中的内容,以便垃圾回收器可以回收不再需要的数据。
下面是一个处理循环引用的手动复制示例代码:
public List deepCopyListWithCyclicReferences(List originalList) { Map copiedObjects = new HashMap(); List newList = new ArrayList(); for (MyObject obj : originalList) { if (copiedObjects.containsKey(obj)) { newList.add(copiedObjects.get(obj)); continue; } MyObject newObj = new MyObject(); // ...(复制字段) copiedObjects.put(obj, newObj); newList.add(newObj); } // 清除用于循环引用处理的HashMap copiedObjects.clear(); return newList;}通过使用HashMap来跟踪复制的对象,我们可以确保即使存在循环引用,深复制操作也能正确执行并避免无限递归。这个方法不仅适用于List,也可以扩展到其他类型的集合或数据结构。
结论
手动复制List元素以实现深复制在某些特定场景下是一个非常有用的工具。它提供了对复制过程的完全控制,并允许开发者在复制逻辑中引入任意复杂的操作。处理循环引用是手动复制过程中特别需要关注的部分。通过合理的数据结构来跟踪已复制的对象,可以有效避免复制过程中出现的无限递归错误。
在实际应用中,手动复制方法虽然灵活,但需要开发者编写更多的代码,并对对象的结构有清晰的理解。因此,它主要用于其他复制机制不适用或者不足够的复杂对象复制场景。
```
5. 可变对象的深复制重要性
5.1 可变对象在深复制中的角色
5.1.1 可变对象与不可变对象的区分
可变对象(Mutable Objects)和不可变对象(Immutable Objects)是面向对象编程中两种常见的对象类型。它们的主要区别在于对象状态是否可以在创建后被改变。
- 可变对象 指的是可以修改其状态的对象。例如,在Java中的
ArrayList,你可以添加、删除元素或修改现有元素。 - 不可变对象 一旦创建,其状态就无法改变。例如,Java中的
String对象,你不能更改字符串中的单个字符,所有的修改操作都会产生一个新的字符串对象。
理解这两种对象的区别对于实现深复制是非常重要的,因为它们在复制过程中表现出来的行为完全不同。
5.1.2 深复制对可变对象的影响
深复制操作的一个核心目的是确保复制得到的对象是独立于原对象的。对于可变对象来说,深复制能够确保在复制后,对新对象的任何修改都不会影响到原对象。
例如,假设有一个 Person 类,其中包含一个可变对象 Address 作为其属性。当你对一个 Person 对象进行深复制时,不仅 Person 对象本身被复制了,其内部的 Address 对象也应该被复制。这样,当你更改复制得到的 Person 对象的 Address 时,原 Person 对象的 Address 不会受到影响。
如果深复制没有正确执行,两个 Person 对象将共享同一个 Address 对象。这将导致不可预见的错误,特别是在多线程环境中,可能引起数据的不一致。
5.2 深复制与系统设计
5.2.1 深复制在系统设计中的应用场景
在系统设计中,深复制常用于以下场景:
- 状态管理 :在多线程编程中,深复制可以防止线程间共享对象状态时出现的竞争条件。
- 撤销/重做功能 :在文本编辑器或图形设计软件中,深复制用于保存对象的前一个状态,以便实现撤销操作。
- 持久化操作 :当需要将对象的状态保存到数据库或文件中,并且需要保留对象更改历史时,深复制可以保存当前对象状态的快照。
5.2.2 深复制优化与性能考虑
在实现深复制时,开发者必须权衡复制操作的复杂性和对系统性能的影响。通常,深复制比浅复制要消耗更多的资源,因为它需要复制对象的所有内部结构。
为了优化深复制的性能,可以考虑以下策略:
- 延迟复制(Lazy Copying) :当对象的某些部分在程序运行时实际上不会被修改时,可以推迟这部分的复制操作,直到实际需要时才进行。
- 增量复制(Incremental Copying) :如果对象很大,可以考虑分批次复制对象的各个部分,而不是一次性复制整个对象。
- 共享不可变对象 :在深复制对象时,可以共享那些不可变的部分,以此减少不必要的内存占用和复制开销。
通过这些策略,可以有效地减少深复制操作的开销,从而在保证功能正确的前提下提高系统的性能。
本文还有配套的精品资源,点击获取
简介:在Java中,复制List时需区分浅复制与深复制。浅复制仅复制对象引用,而深复制递归复制所有引用的对象。本文探讨了如何利用Java的序列化机制及手动复制属性两种方法实现List的深复制,特别针对可变对象进行阐述,并提供了相应的实现示例。
本文还有配套的精品资源,点击获取


