详解(一)Python + Selenium 批量采集微信公众号_selenium微信文章
在上一篇文章中,我提供了批量采集公众号+coze工作流AI总结+飞书自动推送的方案实现了每日自动跟踪微信公众号进行AI总结简报,效果如下:由于微信公众号的文章篇幅有限,无法对整体实践的全过程完整表述,因此后续将对中间关键阶段进行详细展开,本文主要针对第一阶段:批量采集微信公众号文章列表
自研方案
-
方案一:影刀 RPA 通过微信公众平台后台接口进行页面抓取
优点:技术门槛较低,可视化页面编写采集程序
缺点:需要桌面化系统和浏览器配合,占用系统控制权,微信公众号平台需要扫码登录 -
方案二:python selenium库通过模拟浏览器访问微信公众号后台接口进行脚本抓取
优点:脚本环境依赖简单,只需要偶尔配合浏览器扫码登录
缺点:脚本编写有门槛,微信公众号平台2-3天会登陆过期,需要扫码登录 -
方案三:通过开源项目WeWe RSS采集公众号文章,通过RSS阅读器进行阅读
优点:整体比较优雅,无需了解微信机制,页面配置,展现友好
缺点:需要科学上网,云服务器+docker部署等资源技术,有接口不稳定帐号失效等问题 -
方案四:通过anyproxy客户端代理解析微信https接口信息进行数据抓取
优点:从协议层模拟实际访问,无风控风险,适合长期大规模方案
缺点:多端开发,协议插件代理复杂
综上方案优缺点和个人技术精力,我选择了方案一和方案二进行快速实践,技术难度都不高,利于大家实践
实践过程
Python脚本批量采集微信公众号
使用Python脚本selenium库可以驱动浏览器进行扫码登录自动获取cookie,有效期为2-3天,当获取cookie后需要先获取当前会话token,再通过cookie+token访问微信公众平台的后端接口搜索公众号fakeid,最后通过cookie+token+fakeid查询文章列表,最后通过文章链接直接获取文章内容
1.环境安装
-
需要安装python selenium模块包,需要使用selenium中的webdriver驱动浏览器进行登录获取Cookie;我安装selenium 版本发现无法调起浏览器,可能与插件不适配,降到主流版本4.5.0 OK
-
使用webdriver功能需要安装对应浏览器的驱动插件,我这里测试用的是谷歌浏览器:google chrome版本为137.0.7151.104 ;chromedriver版本为:138.0.7204.92 注意:谷歌浏览器版本和chromedriver需要对应,否则会导致启动时报错。
chromedriver的官方下载
2.脚本调起浏览器登录获取cookie
当前引入方式已更新至selenium.webdriver.chrome.service import Service as ChromeService,旧方式不可用
import time,random,re,json,requestsfrom selenium import webdriverfrom selenium.webdriver import Chromefrom selenium.webdriver.firefox.options import Optionsfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.service import Service as ChromeServiceimport requestsimport jsonimport datetimedef weChat_login(): #定义一个空的字典,存放cookies内容 post={} #用webdriver启动谷歌浏览器 logging.info(\"启动浏览器,打开微信公众号登录界面\") options = Options() options.add_argument(\'-headless\') # 无头参数 service = ChromeService(executable_path=\"/opt/homebrew/bin/chromedriver\") driver = webdriver.Chrome(service=service) #打开微信公众号登录页面 driver.get(\'https://mp.weixin.qq.com/\') #等待5秒钟 time.sleep(2) logging.info(\"正在输入微信公众号登录账号和密码......\") #清空账号框中的内容 driver.find_element(By.XPATH, \"./*//a[@class=\'login__type__container__select-type\']\").click() driver.find_element(By.XPATH, \"./*//input[@name=\'account\']\").clear() #自动填入登录用户名 driver.find_element(By.XPATH, \"./*//input[@name=\'account\']\").send_keys(user) #清空密码框中的内容 driver.find_element(By.XPATH, \"./*//input[@name=\'password\']\").clear() #自动填入登录密码 driver.find_element(By.XPATH, \"./*//input[@name=\'password\']\").send_keys(password) time.sleep(1) #自动点击登录按钮进行登录 driver.find_element(By.XPATH, \"./*//a[@class=\'btn_login\']\").click() # 拿手机扫二维码! logging.info(\"请拿手机扫码二维码登录公众号\") time.sleep(20) #重新载入公众号登录页,登录之后会显示公众号后台首页,从这个返回内容中获取cookies信息 driver.get(\'https://mp.weixin.qq.com/\') #获取cookies cookie_items = driver.get_cookies() #获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中 for cookie_item in cookie_items: post[cookie_item[\'name\']] = cookie_item[\'value\'] if \"slave_sid\" not in post: logging.info(\"登录公众号失败,获取cookie失败\") return None cookie_str = json.dumps(post) return cookie_str3.使用cookie调用微信公众平台接口获取关注作者文章列表
该部分在上篇文章有详细说明,此处不再赘述
#爬取微信公众号文章,并存在本地文本中def get_wechat_upper_article_url(): #query为要爬取的公众号名称 #公众号主页 url = \'https://mp.weixin.qq.com\' #设置headers header = { \"HOST\": \"mp.weixin.qq.com\", \"User-Agent\": \"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0\" } #读取上一步获取到的cookies config_json = read_config_json() cookies_str = config_json.get(\'wechat\').get(\'cookie\') if not cookies_str: cookies = None else: cookies = json.loads(cookies_str) #登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,从这里获取token信息 response = requests.get(url=url, allow_redirects=False, cookies=cookies) if not response.headers.get(\"Location\"): logging.info(\"微信cookie已过期,重新登录刷新\") cookies = weChat_login() if not cookies: feishu_send_message(\"微信cookie过期,请重新登录刷新\") return cookies = json.loads(cookies) response = requests.get(url=url,allow_redirects=False,cookies=cookies) token = re.findall(r\'token=(\\d+)\', str(response.headers.get(\"Location\")))[0] logging.info(\"微信token:\"+ token) article_urls = [] for account_name, account_id in gzlist.items(): #搜索微信公众号的接口地址 search_url = \'https://mp.weixin.qq.com/cgi-bin/searchbiz?\' #搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字 query_id = { \'action\': \'search_biz\', \'token\' : token, \'lang\': \'zh_CN\', \'f\': \'json\', \'ajax\': \'1\', \'random\': random.random(), \'query\': account_name, \'begin\': \'0\', \'count\': \'5\' } #打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id) #取搜索结果中的第一个公众号 lists = search_response.json().get(\'list\')[0] #获取这个公众号的fakeid,后面爬取公众号文章需要此字段 fakeid = lists.get(\'fakeid\') logging.info(\"fakeid:\" + fakeid) #微信公众号文章接口地址 appmsg_url = \'https://mp.weixin.qq.com/cgi-bin/appmsg?\' #搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random query_id_data = { \'token\': token, \'lang\': \'zh_CN\', \'f\': \'json\', \'ajax\': \'1\', \'random\': random.random(), \'action\': \'list_ex\', \'begin\': \'0\',#不同页,此参数变化,变化规则为每页加5 \'count\': \'5\', \'query\': \'\', \'fakeid\': fakeid, \'type\': \'9\' } #打开搜索的微信公众号文章列表页 query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data) fakeid_list = query_fakeid_response.json().get(\'app_msg_list\') item = fakeid_list[0] # 采集item示例 new_article = { \'title\': item.get(\'title\'), \'article_url\': item.get(\'link\'), \'account_id\': account_id, \'account_name\': account_name, \'publish_time\': datetime.datetime.fromtimestamp(int(item.get(\"update_time\"))).strftime(\'%Y-%m-%d %H:%M:%S\'), \'collection_time\': datetime.datetime.now().strftime(\'%Y-%m-%d %H:%M:%S\') } logging.info(\"new_article:\", new_article) article_urls.append(item.get(\'link\')) time.sleep(2) return article_urls影刀 RPA 批量采集微信公众号
RPA主流程使用了飞书多维表格进行输出记录,主要步骤流程为:建立多维表格连接-->打开微信公众平台-->点击文章、超链接按钮-->循环搜索关注账号列表-->依次分页抓取所有文章链接-->保存链接至飞书多维表格记录,此过程需要浏览器提前进行微信公众平台登录,保存有效cookie,采集流程为全自动,我测试批量采集了150+公众号,共2W+文章,共耗时4—5小时
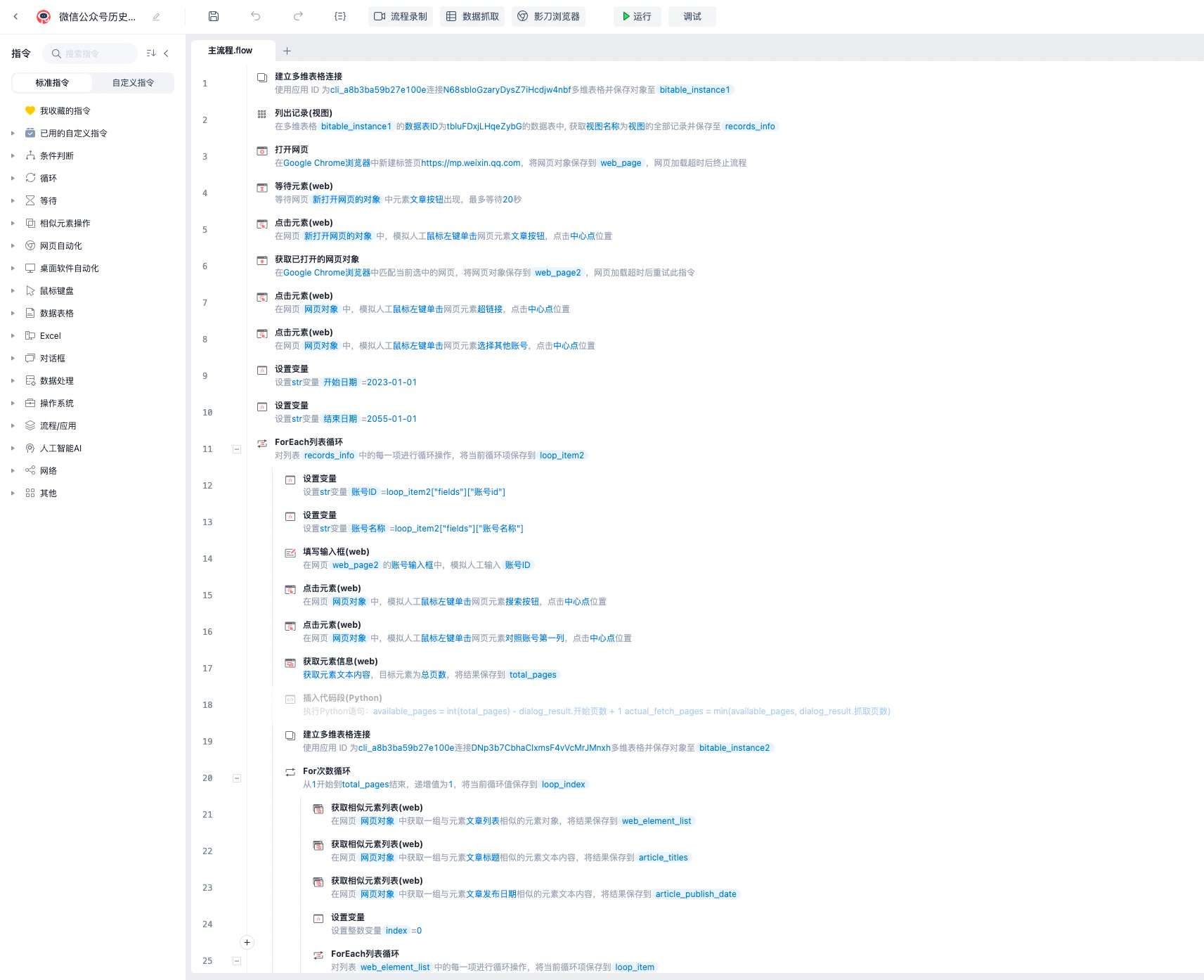
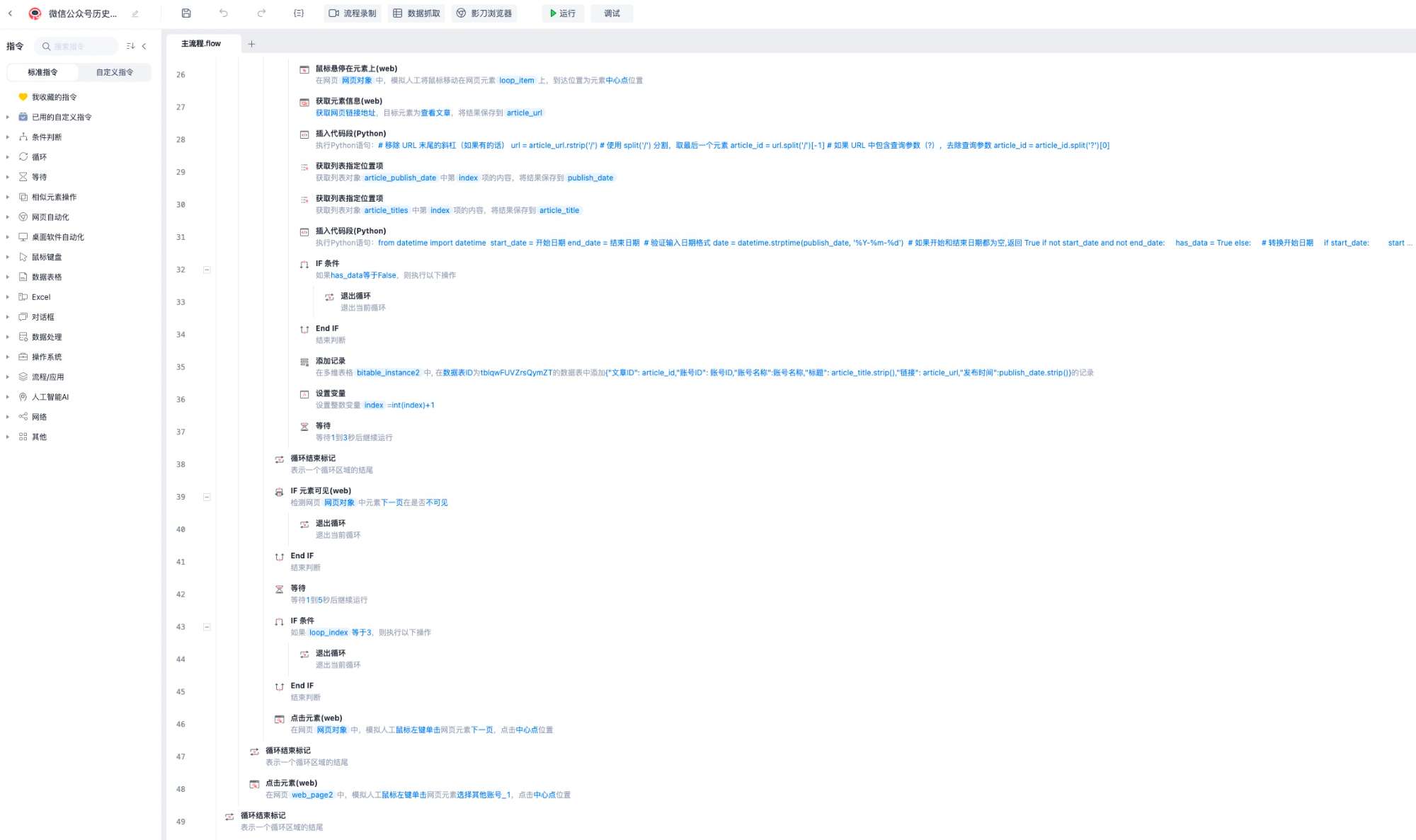
总结
不管用什么方式获取cookie,有效期都为2-3天,而RPA是需要接管独占浏览器,每日都需要登录,RPA程序本身也是模拟程序过程,因此不如Python脚本直接,脚本也利于与其他组件API进行集成,更加利于自动化,因此最后机器人过程采用了Python脚本进行。由于RPA程序节点较多,如若展开说明篇幅太大,因此仅截图说明思路,如需完整程序可加好友联系。


