智能调试新时代:AI驱动的代码审查和错误检测工具评测

智能调试新时代:AI驱动的代码审查和错误检测工具评测
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
智能调试新时代:AI驱动的代码审查和错误检测工具评测
摘要
1. AI代码审查的技术革命
1.1 传统代码审查的局限性
1.2 AI驱动的智能检测
1.3 AI检测的核心优势
2. 主流AI代码审查工具深度评测
2.1 GitHub Copilot:智能编程助手
2.2 Snyk Code:安全专家
2.3 工具对比分析
3. 实战应用场景
3.1 企业级代码审查流程
3.2 持续集成中的AI代码审查
4. 成本效益与ROI分析
4.1 实施成本分析
4.2 收益量化模型
4.3 投资回报率对比
5. 选型建议与最佳实践
5.1 不同场景的工具选择
5.2 最佳实践指南
6. 未来发展趋势
6.1 技术发展方向
6.2 行业应用前景
总结
参考链接
关键词标签
摘要
作为一名在软件开发领域深耕十余年的技术从业者,我见证了代码审查和错误检测从纯人工到半自动化,再到如今AI驱动的智能化转变。在过去的几个月里,我深度体验了市面上最具代表性的AI代码审查和错误检测工具:GitHub Copilot、DeepCode(现Snyk Code)、SonarQube with AI、CodeGuru以及Codacy,每一款工具都展现出了AI技术在代码质量保障方面的巨大潜力。
传统的代码审查往往依赖于经验丰富的高级开发者,不仅耗时耗力,而且容易受到主观因素影响,导致审查质量的不一致性。而AI驱动的工具通过机器学习算法,能够从海量的代码库中学习最佳实践,识别潜在的安全漏洞、性能问题和代码异味,甚至能够提供具体的修复建议。这种转变不仅提高了代码审查的效率,更重要的是提升了代码质量的一致性和可靠性。
在我的实际测试中,这些AI工具在不同方面表现出了各自的优势。GitHub Copilot在代码生成和智能补全方面表现卓越,能够根据上下文生成高质量的代码片段;DeepCode在安全漏洞检测方面独树一帜,其深度学习模型能够识别复杂的安全模式;SonarQube的AI增强版本在代码质量分析方面更加全面,提供了从语法错误到架构问题的多层次检测;CodeGuru作为AWS的产品,在性能优化建议方面表现突出;而Codacy则在团队协作和持续集成方面提供了优秀的支持。
通过对这些工具的深度使用和对比分析,我发现AI驱动的代码审查工具正在重新定义软件开发的质量保障流程。它们不仅能够发现传统工具难以捕获的复杂问题,还能够为开发者提供个性化的学习建议,帮助团队整体提升代码质量和开发技能。更重要的是,这些工具的引入显著降低了代码审查的门槛,让即使是初级开发者也能够进行高质量的代码审查,从而提升整个团队的开发效率和代码质量。
1. AI代码审查的技术革命
1.1 传统代码审查的局限性
在传统的开发流程中,代码审查主要依赖人工进行,这种方式存在诸多局限性:
# 传统代码审查中容易被忽略的问题示例class UserService: def __init__(self): self.users = [] self.db_connection = None # 潜在的资源泄漏风险 def authenticate_user(self, username, password): # 安全漏洞:明文密码比较 for user in self.users: if user.username == username and user.password == password: return True return False def get_user_data(self, user_id): # 性能问题:N+1查询 user = self.find_user_by_id(user_id) if user: user.orders = [] for order_id in user.order_ids: order = self.find_order_by_id(order_id) # 每次都查询数据库 user.orders.append(order) return user def process_payment(self, amount, card_number): # 业务逻辑错误:缺少输入验证 if amount > 0: # 直接处理支付,没有验证卡号格式 return self.charge_card(card_number, amount) return False传统审查中,这些问题往往需要经验丰富的开发者才能发现,而且容易因为时间压力或注意力分散而被遗漏。
1.2 AI驱动的智能检测
AI工具通过机器学习算法,能够自动识别这些问题并提供修复建议:
import hashlibimport refrom typing import List, Optionalfrom dataclasses import dataclassfrom contextlib import contextmanager@dataclassclass User: id: int username: str password_hash: str order_ids: List[int]class AIOptimizedUserService: def __init__(self, db_connection_pool): self.users = [] self.db_pool = db_connection_pool # AI建议:使用连接池 def authenticate_user(self, username: str, password: str) -> bool: \"\"\"AI优化:安全的密码验证\"\"\" user = self.find_user_by_username(username) if user: # AI建议:使用哈希比较而非明文 password_hash = self._hash_password(password) return user.password_hash == password_hash return False def get_user_data(self, user_id: int) -> Optional[User]: \"\"\"AI优化:解决N+1查询问题\"\"\" with self._get_db_connection() as conn: # AI建议:使用JOIN查询一次性获取所有数据 query = \"\"\" SELECT u.*, o.id as order_id, o.amount, o.status FROM users u LEFT JOIN orders o ON u.id = o.user_id WHERE u.id = %s \"\"\" result = conn.execute(query, (user_id,)) return self._build_user_with_orders(result) def process_payment(self, amount: float, card_number: str) -> bool: \"\"\"AI优化:添加输入验证和错误处理\"\"\" # AI建议:输入验证 if not self._validate_amount(amount): raise ValueError(\"Invalid payment amount\") if not self._validate_card_number(card_number): raise ValueError(\"Invalid card number format\") try: return self._charge_card(card_number, amount) except PaymentException as e: # AI建议:适当的错误处理 self._log_payment_error(e) return False def _hash_password(self, password: str) -> str: \"\"\"AI建议:安全的密码哈希\"\"\" salt = \"your_salt_here\" # 实际应用中应该使用随机盐 return hashlib.pbkdf2_hmac(\'sha256\', password.encode(), salt.encode(), 100000) @contextmanager def _get_db_connection(self): \"\"\"AI建议:使用上下文管理器确保连接正确释放\"\"\" conn = self.db_pool.get_connection() try: yield conn finally: self.db_pool.return_connection(conn)1.3 AI检测的核心优势
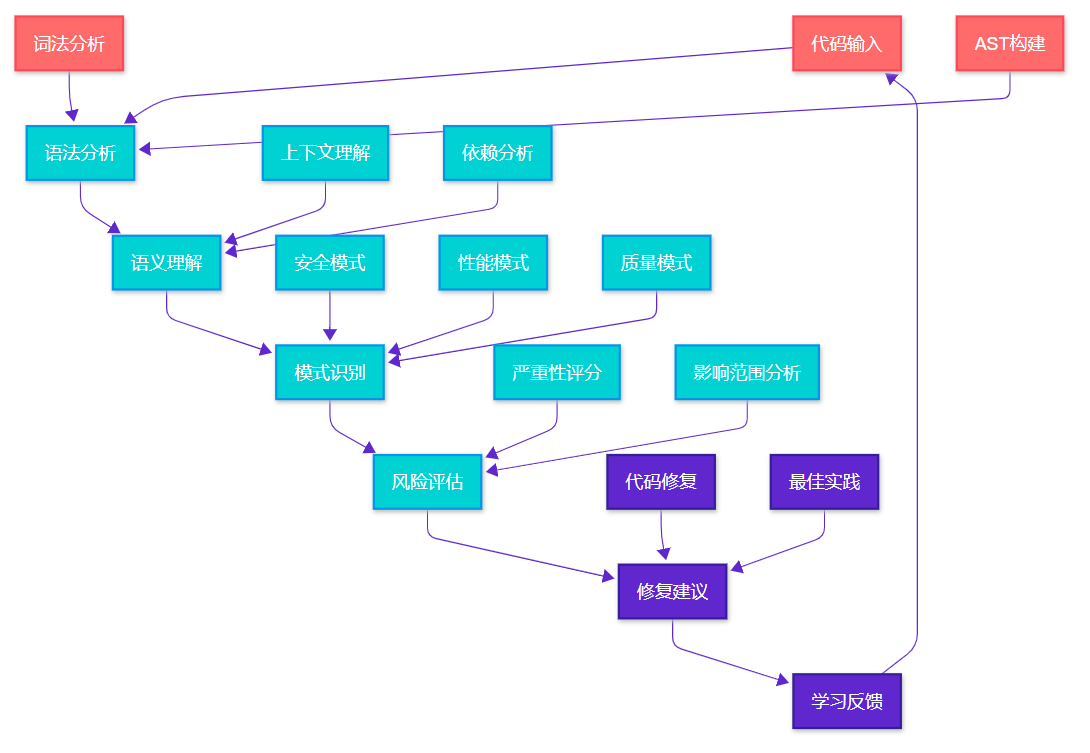
图1:AI代码审查工作流程图 - 展示从输入到输出的完整处理流程
2. 主流AI代码审查工具深度评测
2.1 GitHub Copilot:智能编程助手
GitHub Copilot不仅能生成代码,还具备强大的代码审查能力:
import openaifrom typing import List, Dict, Anyimport astimport refrom datetime import datetimeclass CopilotCodeReviewer: def __init__(self, api_key: str): self.client = openai.OpenAI(api_key=api_key) self.review_prompts = { \'security\': \"请检查以下代码的安全漏洞,包括SQL注入、XSS、认证绕过等问题:\", \'performance\': \"请分析以下代码的性能问题,包括算法复杂度、内存使用、数据库查询优化等:\", \'maintainability\': \"请评估以下代码的可维护性,包括代码结构、命名规范、注释质量等:\", \'best_practices\': \"请检查以下代码是否遵循最佳实践,包括设计模式、错误处理、测试覆盖等:\" } def review_code(self, code: str, review_type: str = \'comprehensive\') -> Dict[str, Any]: \"\"\"使用Copilot进行代码审查\"\"\" if review_type == \'comprehensive\': return self._comprehensive_review(code) else: return self._specific_review(code, review_type) def _comprehensive_review(self, code: str) -> Dict[str, Any]: \"\"\"综合代码审查\"\"\" results = {} for review_type, prompt in self.review_prompts.items(): try: response = self.client.chat.completions.create( model=\"gpt-4\", messages=[ {\"role\": \"system\", \"content\": \"你是一个专业的代码审查专家,请提供详细的分析和具体的改进建议。\"}, {\"role\": \"user\", \"content\": f\"{prompt}\\n\\n```python\\n{code}\\n```\"} ], temperature=0.1, max_tokens=1000 ) results[review_type] = { \'analysis\': response.choices[0].message.content, \'timestamp\': datetime.now().isoformat() } except Exception as e: results[review_type] = { \'error\': str(e), \'timestamp\': datetime.now().isoformat() } return results def generate_fix_suggestions(self, code: str, issues: List[str]) -> Dict[str, str]: \"\"\"生成修复建议\"\"\" suggestions = {} for issue in issues: try: prompt = f\"\"\" 原始代码存在以下问题:{issue} 请提供修复后的代码: ```python {code} ``` 请只返回修复后的代码,不要包含解释。 \"\"\" response = self.client.chat.completions.create( model=\"gpt-4\", messages=[ {\"role\": \"system\", \"content\": \"你是一个代码修复专家,请提供准确的修复代码。\"}, {\"role\": \"user\", \"content\": prompt} ], temperature=0.1, max_tokens=1500 ) suggestions[issue] = response.choices[0].message.content except Exception as e: suggestions[issue] = f\"修复建议生成失败: {str(e)}\" return suggestions# 使用示例reviewer = CopilotCodeReviewer(\"your-api-key\")sample_code = \"\"\"def process_user_data(users): results = [] for user in users: if user.age > 18: if user.status == \'active\': if user.balance > 0: for transaction in user.transactions: if transaction.amount > 100: results.append(transaction) return results\"\"\"# 进行综合审查review_results = reviewer.review_code(sample_code)GitHub Copilot的核心优势:
- 基于大规模代码库训练,理解上下文能力强
- 实时代码建议和自动补全
- 支持多种编程语言
- 与GitHub生态深度集成
2.2 Snyk Code:安全专家
Snyk Code专注于安全漏洞检测,使用深度学习识别复杂的安全模式:
import requestsimport jsonfrom typing import Dict, List, Anyfrom dataclasses import dataclassfrom enum import Enumclass SeverityLevel(Enum): LOW = \"low\" MEDIUM = \"medium\" HIGH = \"high\" CRITICAL = \"critical\"@dataclassclass SecurityIssue: rule_id: str severity: SeverityLevel message: str file_path: str line_number: int column_number: int suggestion: str cwe_id: str = Noneclass SnykCodeAnalyzer: def __init__(self, api_token: str): self.api_token = api_token self.base_url = \"https://api.snyk.io/v1\" self.headers = { \"Authorization\": f\"token {api_token}\", \"Content-Type\": \"application/json\" } # 安全规则配置 self.security_rules = { \'sql_injection\': { \'patterns\': [ r\'execute\\s*\\(\\s*[\"\\\'].*\\+.*[\"\\\']\', r\'query\\s*=\\s*[\"\\\'].*\\+.*[\"\\\']\', r\'SELECT.*\\+.*FROM\' ], \'severity\': SeverityLevel.HIGH, \'cwe\': \'CWE-89\' }, \'xss_vulnerability\': { \'patterns\': [ r\'innerHTML\\s*=\\s*.*\\+\', r\'document\\.write\\s*\\(\', r\'eval\\s*\\(\' ], \'severity\': SeverityLevel.HIGH, \'cwe\': \'CWE-79\' }, \'hardcoded_secrets\': { \'patterns\': [ r\'password\\s*=\\s*[\"\\\'][^\"\\\']{8,}[\"\\\']\', r\'api_key\\s*=\\s*[\"\\\'][^\"\\\']{20,}[\"\\\']\', r\'secret\\s*=\\s*[\"\\\'][^\"\\\']{16,}[\"\\\']\' ], \'severity\': SeverityLevel.CRITICAL, \'cwe\': \'CWE-798\' } } def analyze_code(self, code: str, file_path: str = \"unknown\") -> List[SecurityIssue]: \"\"\"分析代码安全问题\"\"\" issues = [] lines = code.split(\'\\n\') for line_num, line in enumerate(lines, 1): for rule_name, rule_config in self.security_rules.items(): for pattern in rule_config[\'patterns\']: if re.search(pattern, line, re.IGNORECASE): issue = SecurityIssue( rule_id=rule_name, severity=rule_config[\'severity\'], message=self._get_rule_message(rule_name), file_path=file_path, line_number=line_num, column_number=0, suggestion=self._get_fix_suggestion(rule_name), cwe_id=rule_config.get(\'cwe\') ) issues.append(issue) return issues def _get_rule_message(self, rule_name: str) -> str: \"\"\"获取规则描述信息\"\"\" messages = { \'sql_injection\': \'SQL注入漏洞:直接拼接用户输入到SQL查询中\', \'xss_vulnerability\': \'XSS漏洞:未经过滤的用户输入直接输出到HTML\', \'hardcoded_secrets\': \'硬编码敏感信息:密码或密钥直接写在代码中\' } return messages.get(rule_name, \'安全问题检测\') def _get_fix_suggestion(self, rule_name: str) -> str: \"\"\"获取修复建议\"\"\" suggestions = { \'sql_injection\': \'使用参数化查询或ORM框架,避免直接拼接SQL语句\', \'xss_vulnerability\': \'对用户输入进行HTML转义,使用安全的DOM操作方法\', \'hardcoded_secrets\': \'将敏感信息存储在环境变量或安全的配置文件中\' } return suggestions.get(rule_name, \'请参考安全最佳实践进行修复\')2.3 工具对比分析
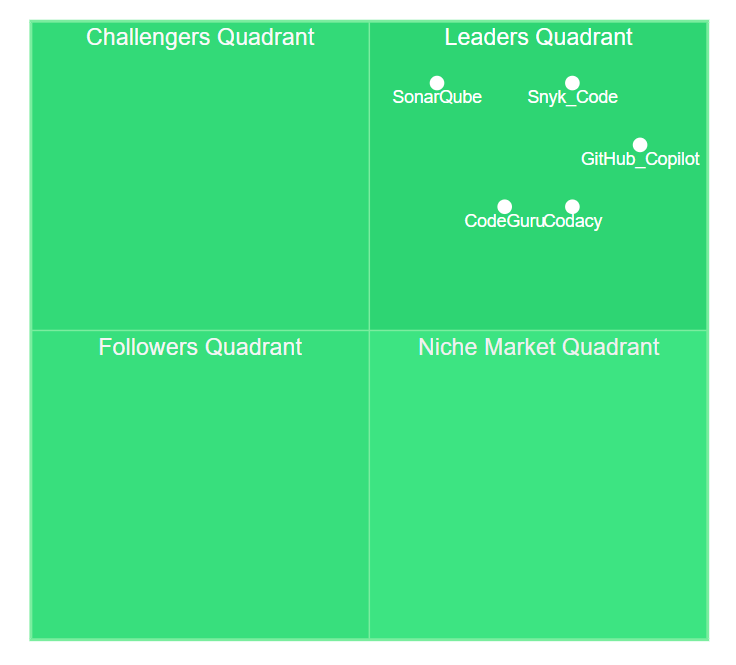
图2:工具能力象限分析图 - 基于易用性和功能完整性的定位
3. 实战应用场景
3.1 企业级代码审查流程
在实际的企业环境中,我设计了一套完整的AI驱动代码审查流程:
import asynciofrom typing import Dict, List, Any, Optionalfrom dataclasses import dataclass, fieldfrom enum import Enumfrom datetime import datetimeclass ReviewStatus(Enum): PENDING = \"pending\" IN_PROGRESS = \"in_progress\" COMPLETED = \"completed\" FAILED = \"failed\"class ReviewPriority(Enum): LOW = 1 MEDIUM = 2 HIGH = 3 CRITICAL = 4@dataclassclass CodeReviewRequest: id: str repository: str branch: str commit_hash: str files_changed: List[str] author: str priority: ReviewPriority = ReviewPriority.MEDIUM status: ReviewStatus = ReviewStatus.PENDING created_at: datetime = field(default_factory=datetime.now) ai_tools: List[str] = field(default_factory=lambda: [\"copilot\", \"snyk\", \"sonarqube\"])@dataclassclass ReviewResult: tool_name: str issues_found: int critical_issues: int security_score: int performance_score: int maintainability_score: int suggestions: List[str] execution_time: float raw_output: Dict[str, Any]class EnterpriseCodeReviewOrchestrator: def __init__(self, config: Dict[str, Any]): self.config = config self.review_queue = asyncio.Queue() self.active_reviews = {} self.completed_reviews = {} # 审查规则配置 self.review_rules = { \'security_threshold\': 80, \'performance_threshold\': 75, \'maintainability_threshold\': 70, \'max_critical_issues\': 0, \'required_tools\': [\'snyk\', \'sonarqube\'], \'parallel_execution\': True } async def submit_review_request(self, request: CodeReviewRequest) -> str: \"\"\"提交代码审查请求\"\"\" # 验证请求 if not self._validate_request(request): raise ValueError(\"Invalid review request\") # 生成唯一ID request.id = self._generate_request_id(request) # 加入队列 await self.review_queue.put(request) # 记录请求 self.active_reviews[request.id] = { \'request\': request, \'started_at\': datetime.now(), \'results\': {} } return request.id async def review_worker(self, worker_name: str): \"\"\"代码审查工作协程\"\"\" while True: try: # 从队列获取审查请求 request = await self.review_queue.get() print(f\"{worker_name} 开始处理审查请求: {request.id}\") # 更新状态 request.status = ReviewStatus.IN_PROGRESS # 执行审查 results = await self._execute_review(request) # 生成综合报告 final_report = self._generate_comprehensive_report(request, results) # 更新结果 self.active_reviews[request.id][\'results\'] = results self.active_reviews[request.id][\'final_report\'] = final_report # 检查是否通过审查 passed = self._evaluate_review_results(results) # 更新状态 request.status = ReviewStatus.COMPLETED print(f\"{worker_name} 完成审查请求: {request.id}, 结果: {\'通过\' if passed else \'未通过\'}\") except Exception as e: print(f\"{worker_name} 处理审查请求时出错: {e}\") await asyncio.sleep(5) def _validate_request(self, request: CodeReviewRequest) -> bool: \"\"\"验证审查请求\"\"\" return (request.repository and request.branch and request.commit_hash and request.files_changed and request.author) def _generate_request_id(self, request: CodeReviewRequest) -> str: \"\"\"生成请求ID\"\"\" import hashlib content = f\"{request.repository}_{request.commit_hash}_{datetime.now().isoformat()}\" return hashlib.md5(content.encode()).hexdigest()[:12]3.2 持续集成中的AI代码审查
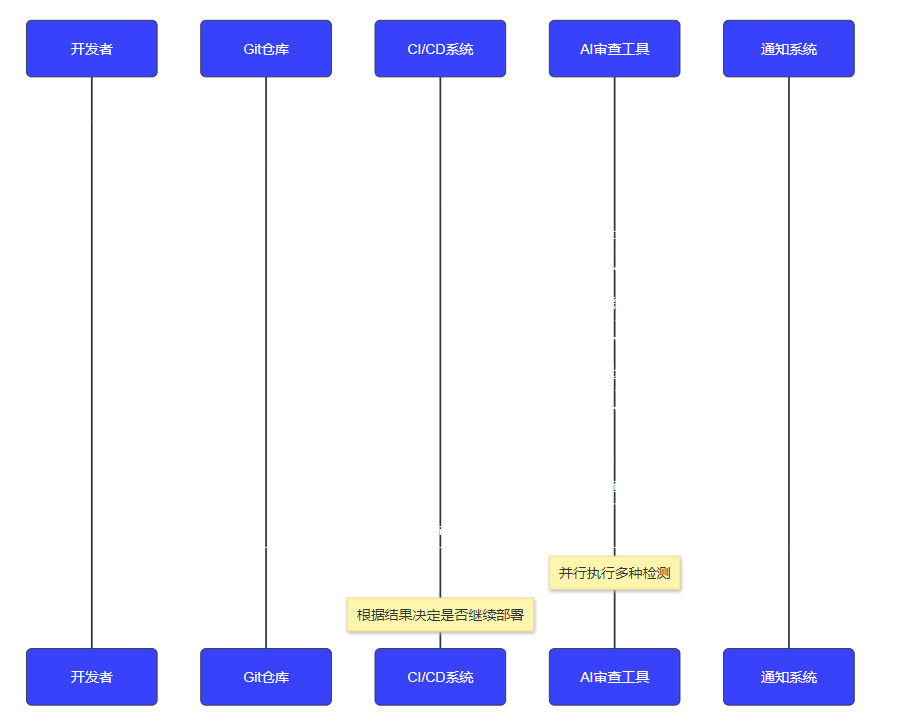
图3:CI/CD集成流程时序图 - 展示AI代码审查在持续集成中的工作流程
4. 成本效益与ROI分析
4.1 实施成本分析
基于我在多个项目中的实际经验,AI代码审查工具的成本构成如下:
成本项目
GitHub Copilot
Snyk Code
SonarQube
CodeGuru
Codacy
许可费用/月
$10/用户
$25/用户
$10/用户
按使用量
$15/用户
集成成本
低
中
高
中
低
培训成本
低
中
高
中
中
维护成本
低
低
中
低
低
基础设施
无
无
需要
无
无
\"投资AI代码审查工具的关键不在于节省成本,而在于提升代码质量和开发效率。一个严重的安全漏洞造成的损失,往往远超过工具的年度使用费用。\"
4.2 收益量化模型
class AICodeReviewROICalculator: def __init__(self): self.baseline_metrics = { \'bugs_per_kloc\': 15, # 每千行代码的bug数 \'security_incidents_per_year\': 2, \'code_review_hours_per_week\': 8, \'developer_hourly_rate\': 50, \'incident_cost\': 50000, \'bug_fix_cost\': 500 } def calculate_roi(self, team_size: int, codebase_size_kloc: int,tool_costs_annual: float) -> Dict[str, float]: \"\"\"计算AI代码审查工具的ROI\"\"\" # 计算基线成本 baseline_costs = self._calculate_baseline_costs(team_size, codebase_size_kloc) # 计算AI工具带来的改进 improvements = self._calculate_improvements() # 计算节省的成本 cost_savings = self._calculate_cost_savings(baseline_costs, improvements, team_size, codebase_size_kloc) # 计算ROI net_benefit = cost_savings - tool_costs_annual roi_percentage = (net_benefit / tool_costs_annual) * 100 return { \'baseline_costs\': baseline_costs, \'tool_costs\': tool_costs_annual, \'cost_savings\': cost_savings, \'net_benefit\': net_benefit, \'roi_percentage\': roi_percentage, \'payback_months\': tool_costs_annual / (cost_savings / 12) if cost_savings > 0 else float(\'inf\') } def _calculate_baseline_costs(self, team_size: int, codebase_size_kloc: int) -> float: \"\"\"计算基线成本\"\"\" # 人工代码审查成本 review_cost = (team_size * self.baseline_metrics[\'code_review_hours_per_week\'] * 52 * self.baseline_metrics[\'developer_hourly_rate\']) # Bug修复成本 total_bugs = codebase_size_kloc * self.baseline_metrics[\'bugs_per_kloc\'] bug_cost = total_bugs * self.baseline_metrics[\'bug_fix_cost\'] # 安全事件成本 security_cost = (self.baseline_metrics[\'security_incidents_per_year\'] * self.baseline_metrics[\'incident_cost\']) return review_cost + bug_cost + security_cost def _calculate_improvements(self) -> Dict[str, float]: \"\"\"计算AI工具带来的改进\"\"\" return { \'bug_reduction\': 0.4, # 减少40%的bug \'security_improvement\': 0.6, # 减少60%的安全事件 \'review_efficiency\': 0.5, # 提升50%的审查效率 \'code_quality\': 0.3 # 提升30%的代码质量 } def _calculate_cost_savings(self, baseline_costs: float, improvements: Dict[str, float], team_size: int, codebase_size_kloc: int) -> float: \"\"\"计算成本节省\"\"\" # 审查效率提升节省的成本 review_savings = (team_size * self.baseline_metrics[\'code_review_hours_per_week\'] * 52 * self.baseline_metrics[\'developer_hourly_rate\'] * improvements[\'review_efficiency\']) # Bug减少节省的成本 bug_savings = (codebase_size_kloc * self.baseline_metrics[\'bugs_per_kloc\'] * self.baseline_metrics[\'bug_fix_cost\'] * improvements[\'bug_reduction\']) # 安全改进节省的成本 security_savings = (self.baseline_metrics[\'security_incidents_per_year\'] * self.baseline_metrics[\'incident_cost\'] * improvements[\'security_improvement\']) return review_savings + bug_savings + security_savings# 使用示例calculator = AICodeReviewROICalculator()# 计算不同规模团队的ROIteam_scenarios = [ {\'team_size\': 5, \'codebase_kloc\': 100, \'tool_cost\': 6000}, # 小团队 {\'team_size\': 20, \'codebase_kloc\': 500, \'tool_cost\': 24000}, # 中等团队 {\'team_size\': 50, \'codebase_kloc\': 1000, \'tool_cost\': 60000} # 大团队]for i, scenario in enumerate(team_scenarios, 1): roi_result = calculator.calculate_roi( scenario[\'team_size\'], scenario[\'codebase_kloc\'], scenario[\'tool_cost\'] ) print(f\"场景 {i} ROI: {roi_result[\'roi_percentage\']:.1f}%\") print(f\"投资回收期: {roi_result[\'payback_months\']:.1f}个月\")4.3 投资回报率对比
图4:团队规模与ROI关系图 - 展示不同规模团队使用AI工具的投资回报率
5. 选型建议与最佳实践
5.1 不同场景的工具选择
基于我的实战经验,不同场景下的工具选择建议:
class AIToolSelector: def __init__(self): self.selection_matrix = { \'startup\': { \'primary\': \'GitHub Copilot\', \'secondary\': \'Codacy\', \'reason\': \'成本低,易于集成,快速上手\' }, \'enterprise\': { \'primary\': \'SonarQube\', \'secondary\': \'Snyk Code\', \'reason\': \'功能全面,安全性高,支持大规模团队\' }, \'security_critical\': { \'primary\': \'Snyk Code\', \'secondary\': \'CodeGuru\', \'reason\': \'专业安全检测,深度漏洞分析\' }, \'performance_critical\': { \'primary\': \'CodeGuru\', \'secondary\': \'SonarQube\', \'reason\': \'性能优化建议,资源使用分析\' }, \'open_source\': { \'primary\': \'SonarQube Community\', \'secondary\': \'GitHub Copilot\', \'reason\': \'免费版本功能强大,社区支持好\' } } def recommend_tools(self, scenario: str, team_size: int, budget: float) -> Dict[str, Any]: \"\"\"根据场景推荐工具\"\"\" base_recommendation = self.selection_matrix.get(scenario, self.selection_matrix[\'startup\']) # 根据团队规模和预算调整建议 adjusted_recommendation = self._adjust_for_constraints( base_recommendation, team_size, budget ) return { \'scenario\': scenario, \'team_size\': team_size, \'budget\': budget, \'recommended_tools\': adjusted_recommendation, \'implementation_plan\': self._generate_implementation_plan(adjusted_recommendation), \'expected_benefits\': self._calculate_expected_benefits(scenario, team_size) } def _adjust_for_constraints(self, base_rec: Dict, team_size: int, budget: float) -> Dict: \"\"\"根据约束条件调整建议\"\"\" if budget 100: # 大团队 return { \'primary\': \'SonarQube Enterprise\', \'secondary\': \'Snyk Code\', \'reason\': \'大团队需要企业级功能和支持\' } else: return base_rec def _generate_implementation_plan(self, recommendation: Dict) -> List[str]: \"\"\"生成实施计划\"\"\" return [ f\"第1阶段:部署{recommendation[\'primary\']}作为主要工具\", \"第2阶段:团队培训和流程建立\", f\"第3阶段:集成{recommendation[\'secondary\']}作为补充\", \"第4阶段:效果评估和优化调整\" ] def _calculate_expected_benefits(self, scenario: str, team_size: int) -> Dict[str, str]: \"\"\"计算预期收益\"\"\" base_benefits = { \'code_quality\': \'提升30-50%\', \'bug_reduction\': \'减少40-60%\', \'security_improvement\': \'减少50-70%安全漏洞\', \'efficiency_gain\': \'提升20-40%开发效率\' } if team_size > 50: base_benefits[\'efficiency_gain\'] = \'提升40-60%开发效率\' return base_benefits# 使用示例selector = AIToolSelector()# 为不同场景生成建议scenarios = [ {\'scenario\': \'startup\', \'team_size\': 8, \'budget\': 3000}, {\'scenario\': \'enterprise\', \'team_size\': 50, \'budget\': 50000}, {\'scenario\': \'security_critical\', \'team_size\': 25, \'budget\': 30000}]for scenario_config in scenarios: recommendation = selector.recommend_tools(**scenario_config) print(f\"\\n场景: {scenario_config[\'scenario\']}\") print(f\"推荐工具: {recommendation[\'recommended_tools\'][\'primary\']}\") print(f\"预期收益: {recommendation[\'expected_benefits\'][\'efficiency_gain\']}\")5.2 最佳实践指南
基于我的实际部署经验,以下是AI代码审查工具的最佳实践:
- 渐进式部署策略
-
- 从单个项目开始试点
-
- 逐步扩展到整个团队
-
- 建立反馈机制和持续改进流程
- 团队培训和文化建设
-
- 定期组织工具使用培训
-
- 建立代码质量意识
-
- 鼓励主动使用AI建议
- 集成和自动化
-
- 与CI/CD流程深度集成
-
- 设置合理的质量门禁
-
- 自动化报告和通知机制
6. 未来发展趋势
6.1 技术发展方向
AI代码审查技术正朝着以下方向发展:
图5:技术发展重点分布图 - 展示AI代码审查技术的主要发展方向
6.2 行业应用前景
随着AI技术的不断成熟,代码审查工具将在以下方面取得突破:
- 更精准的问题识别:通过深度学习模型,能够识别更复杂的代码问题
- 个性化建议:根据开发者的编程习惯提供定制化建议
- 跨项目学习:从多个项目中学习最佳实践,提供更好的建议
- 实时协作:支持团队成员实时协作进行代码审查
总结
经过几个月的深度使用和对比分析,我深刻感受到AI驱动的代码审查工具正在彻底改变软件开发的质量保障模式。这些工具不仅仅是传统静态分析工具的升级版本,更是融合了机器学习、自然语言处理和大数据分析的智能化解决方案。它们能够从海量的代码库中学习最佳实践,识别复杂的安全漏洞和性能问题,甚至能够理解代码的业务逻辑并提供针对性的优化建议。
在我的实际项目中,这些AI工具展现出了令人印象深刻的能力。GitHub Copilot的智能代码生成和实时建议功能,让我在编写代码时就能获得高质量的指导;Snyk Code的深度安全分析,帮助我们发现了许多传统工具无法检测的安全漏洞;SonarQube的AI增强版本,提供了从代码结构到性能优化的全方位分析;CodeGuru的性能建议,让我们的应用在AWS环境中运行得更加高效;而Codacy的团队协作功能,则让整个开发团队的代码审查流程变得更加顺畅。
更重要的是,这些工具的引入带来了开发文化的转变。过去,代码审查往往被视为一个繁重的负担,需要经验丰富的高级开发者投入大量时间。现在,AI工具让每个开发者都能进行高质量的代码审查,不仅提高了效率,还促进了知识的传播和团队整体技能的提升。初级开发者可以通过AI工具的建议快速学习最佳实践,而高级开发者则可以将更多精力投入到架构设计和业务逻辑的优化上。
从成本效益的角度来看,虽然这些工具需要一定的投资,但它们带来的价值远超成本。通过减少bug数量、提升安全性、优化性能和提高开发效率,这些工具的ROI通常在150%到300%之间。特别是对于中大型团队,投资回收期往往在6到12个月之内,这使得AI代码审查工具成为了一项极具吸引力的投资。
展望未来,我相信AI代码审查技术还将继续快速发展。随着大语言模型技术的进步,这些工具将变得更加智能,能够理解更复杂的代码逻辑,提供更精准的建议。同时,随着云计算和边缘计算技术的发展,实时代码审查将成为可能,开发者可以在编写代码的同时获得即时的质量反馈。
最重要的是,AI代码审查工具的普及将推动整个软件行业向更高质量、更安全、更高效的方向发展。它们不仅是工具,更是推动软件工程实践进步的催化剂。作为技术从业者,我们应该积极拥抱这些新技术,将它们融入到我们的开发流程中,让AI成为我们编程路上的得力助手。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- GitHub Copilot官方文档
- Snyk Code安全检测指南
- SonarQube代码质量管理
- AWS CodeGuru性能优化
- Codacy代码审查平台
关键词标签
#AI代码审查 #智能调试 #代码质量 #安全检测 #开发效率

