第N8周:使用Word2vec实现文本分类
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、数据预处理
1.加载数据
import torchimport torch.nn as nnimport torchvisionfrom torchvision import transforms,datasetsimport os,PIL,pathlib,warningswarnings.filterwarnings(\"ignore\")#忽略警告信息# win10系统device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")devicedevice(type=\'cuda\')
import pandas as pd#加载自定义中文数据train_data = pd.read_csv(\'F:/jupyter lab/DL-100-days/datasets/N8/train.csv\', sep=\'\\t\', header=None, encoding=\'utf-8\')train_data.head()#构造数据集迭代器def coustom_data_iter(texts, labels): for x,y in zip(texts,labels): yield x,y x = train_data[0].values[:]#多类标签的one-hot展开y= train_data[1].values[:]2.构建词典
from gensim.models.word2vec import Word2Vecimport numpy as np#训练 Word2Vec 浅层神经网络模型w2v = Word2Vec(vector_size=100, #是指特征向量的维度,默认为100。 min_count=3) #可以对字典做截断,词频少于min_count次数的单词会被丢弃掉,默认值为5。w2v.build_vocab(x)w2v.train(x, total_examples=w2v.corpus_count, epochs=28)(3827441, 5128984)
#将文本转化为向量def average_vec(text): vec =np.zeros(100).reshape((1,100)) for word in text: try: vec += w2v.wv[word].reshape((1,100)) except KeyError: continue return vec #将词向量保存为 Ndarrayx_vec =np.concatenate([average_vec(z) for z in x])#保存 Word2Vec 模型及词向量w2v.save(\'F:/jupyter lab/DL-100-days/datasets/N8/w2v_model.pkl\')train_iter=coustom_data_iter(x_vec,y)len(x),len(x_vec)(12100, 12100)
label_name =list(set(train_data[1].values[:]))print(label_name)[\'Alarm-Update\', \'Radio-Listen\', \'Calendar-Query\', \'Weather-Query\', \'Travel-Query\', \'Audio-Play\', \'HomeAppliance-Control\', \'FilmTele-Play\', \'TVProgram-Play\', \'Other\', \'Video-Play\', \'Music-Play\']
3.生成数据批次和迭代器
text_pipeline=lambda x:average_vec(x)label_pipeline =lambda x: label_name.index(x)text_pipeline(\"你在干嘛\")array([[-1.47463497e-01, 5.53675264e-01, 2.32937965e+00, 8.27723369e-01, -2.40717939e+00, 1.44922793e-01, 1.05791057e+00, 1.80504337e-01, 8.77318978e-02, 8.46821085e-01, -2.18721238e+00, -6.19571346e+00, 1.54999074e+00, -1.53929926e+00, 9.02176678e-01, 7.66459696e-01, 3.52216189e+00, -2.71442854e+00, 4.83723553e+00, -2.00612454e-01, 2.65928553e+00, -6.85812015e-01, 2.92455360e-01, -7.59955257e-01, -7.11056605e-01, -5.00715058e-02, -7.25709766e-01, -3.49449252e+00, 2.05362378e+00, 1.65073585e-01, 1.53607135e+00, 1.60568693e+00, -1.50479630e+00, -1.01070085e+00, 1.61834336e-01, 3.67275476e-02, -5.12860328e-01, 3.95214066e+00, -2.57145926e+00, 1.36886638e+00, 1.65003492e+00, 1.67193332e+00, -8.31996325e-01, 1.19858028e+00, -1.21710787e+00, 3.41078362e-01, 1.32124563e+00, -5.43934271e-01, -3.71614812e+00, 2.69695812e+00, -6.01738691e-04, -2.58512072e+00, 2.85854936e-03, -5.94619996e-01, -9.07128885e-01, -3.32832735e-01, -3.54674160e-02, -8.85167986e-01, -1.04638404e+00, -3.19511371e-01, 2.18448932e+00, -1.14190475e+00, 2.76876066e+00, -1.30832776e+00, -5.46692092e-01, -1.63290769e-01, -1.80786880e+00, 9.39842269e-01, 1.08917363e+00, -2.15198517e-01, 8.01670000e-01, 4.68951598e-01, 1.16898914e+00, -4.52896714e-01, 3.86154914e-01, -4.23372328e-01, -2.95600758e+00, 1.00093703e+00, 5.18836200e-01, -1.25538594e+00, -1.34598680e+00, -1.03631393e+00, -2.25449917e+00, 2.21089753e+00, -2.21546982e+00, -1.69246741e-01, 1.50789835e+00, -2.10600454e+00, -8.36849727e-01, -2.62724876e-01, -6.43695414e-01, -2.41657940e+00, 1.28879721e+00, 9.73569101e-01, 1.37036532e-01, -2.54981112e+00, -1.28008410e-01, 1.05215633e+00, -2.58280669e+00, 1.66395550e+00]])
label_pipeline(\"Travel-Query\")4
from torch.utils.data import DataLoaderdef collate_batch(batch): label_list, text_list = [], [] for _text, _label in batch: # 标签转为 index label_list.append(label_pipeline(_label)) # 每条文本转为词向量表示 processed_text = torch.tensor(text_pipeline(_text), dtype=torch.float32) text_list.append(processed_text) # 拼接成 [batch_size, 100] 的张量 text_tensor = torch.cat(text_list, dim=0).view(len(label_list), -1) # [B, 100] label_tensor = torch.tensor(label_list, dtype=torch.int64) # [B] # 确保全部送到 model 所在设备 return text_tensor.to(device), label_tensor.to(device) #数据加载器,调用示例dataloader =DataLoader(train_iter, batch_size=8, shuffle =False, collate_fn=collate_batch)二、模型构建
1.模型搭建
from torch import nnclass TextClassificationModel(nn.Module): def __init__(self, num_class): super(TextClassificationModel, self).__init__() self.fc1 = nn.Linear(100, 128) self.bn1 = nn.BatchNorm1d(128) self.act1 = nn.LeakyReLU() self.dropout1 = nn.Dropout(0.3) self.fc2 = nn.Linear(128, 64) self.bn2 = nn.BatchNorm1d(64) self.act2 = nn.LeakyReLU() self.dropout2 = nn.Dropout(0.2) self.fc3 = nn.Linear(64, num_class) def forward(self, x): x = self.fc1(x) x = self.bn1(x) x = self.act1(x) x = self.dropout1(x) x = self.fc2(x) x = self.bn2(x) x = self.act2(x) x = self.dropout2(x) x = self.fc3(x) return x2.初始化模型
num_class= len(label_name)vocab_size = 100000em_size = 12model=TextClassificationModel(num_class).to(device)3.定义训练和评估函数
import timedef train(dataloader): model.train() total_acc, total_loss, total_count = 0, 0, 0 for idx, (text, label) in enumerate(dataloader): optimizer.zero_grad() predicted_label = model(text) loss = criterion(predicted_label, label) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) optimizer.step() total_acc += (predicted_label.argmax(1) == label).sum().item() total_loss += loss.item() total_count += label.size(0) return total_acc / total_count, total_loss / total_countdef evaluate(dataloader): model.eval() total_acc, total_loss, total_count = 0, 0, 0 with torch.no_grad(): for text, label in dataloader: predicted_label = model(text) loss = criterion(predicted_label, label) total_acc += (predicted_label.argmax(1) == label).sum().item() total_loss += loss.item() total_count += label.size(0) return total_acc / total_count, total_loss / total_count三、训练模型
1.拆分数据集并运行模型
from torch.utils.data.dataset import random_splitfrom torchtext.data.functional import to_map_style_datasetEPOCHS = 10LR = 5BATCH_SIZE = 64criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=LR)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)total_accu = None# 构建数据集train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])train_dataset = to_map_style_dataset(train_iter)split_train, split_valid = random_split(train_dataset, [ int(len(train_dataset) * 0.8), int(len(train_dataset) * 0.2)])train_dataloader = DataLoader(split_train, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)train_acc = []train_loss = []test_acc = []test_loss = []for epoch in range(1, EPOCHS + 1): epoch_start_time = time.time() train_epoch_acc, train_epoch_loss = train(train_dataloader) val_acc, val_loss = evaluate(valid_dataloader) train_acc.append(train_epoch_acc) train_loss.append(train_epoch_loss) test_acc.append(val_acc) test_loss.append(val_loss) lr = optimizer.state_dict()[\'param_groups\'][0][\'lr\'] if total_accu is not None and total_accu > val_acc: scheduler.step() else: total_accu = val_acc print(\"_\" * 69) print(\'| Epoch {:2d} | Time: {:4.2f}s | Train Acc: {:4.3f}, Loss: {:4.3f} | \' \'Val Acc: {:4.3f}, Loss: {:4.3f} | LR: {:4.6f}\'.format( epoch, time.time() - epoch_start_time, train_epoch_acc, train_epoch_loss, val_acc, val_loss, lr )) print(\"-\" * 69)_____________________________________________________________________| Epoch 1 | Time: 2.55s | Train Acc: 0.882, Loss: 0.006 | Val Acc: 0.909, Loss: 0.004 | LR: 5.000000---------------------------------------------------------------------_____________________________________________________________________| Epoch 2 | Time: 2.56s | Train Acc: 0.892, Loss: 0.005 | Val Acc: 0.912, Loss: 0.004 | LR: 5.000000---------------------------------------------------------------------_____________________________________________________________________| Epoch 3 | Time: 2.86s | Train Acc: 0.890, Loss: 0.005 | Val Acc: 0.916, Loss: 0.004 | LR: 5.000000---------------------------------------------------------------------_____________________________________________________________________| Epoch 4 | Time: 2.78s | Train Acc: 0.892, Loss: 0.005 | Val Acc: 0.914, Loss: 0.004 | LR: 5.000000---------------------------------------------------------------------_____________________________________________________________________| Epoch 5 | Time: 2.76s | Train Acc: 0.904, Loss: 0.005 | Val Acc: 0.921, Loss: 0.004 | LR: 0.500000---------------------------------------------------------------------_____________________________________________________________________| Epoch 6 | Time: 2.78s | Train Acc: 0.910, Loss: 0.004 | Val Acc: 0.920, Loss: 0.004 | LR: 0.500000---------------------------------------------------------------------_____________________________________________________________________| Epoch 7 | Time: 2.53s | Train Acc: 0.912, Loss: 0.004 | Val Acc: 0.921, Loss: 0.004 | LR: 0.050000---------------------------------------------------------------------_____________________________________________________________________| Epoch 8 | Time: 2.63s | Train Acc: 0.910, Loss: 0.004 | Val Acc: 0.917, Loss: 0.004 | LR: 0.005000---------------------------------------------------------------------_____________________________________________________________________| Epoch 9 | Time: 2.54s | Train Acc: 0.909, Loss: 0.004 | Val Acc: 0.921, Loss: 0.004 | LR: 0.000500---------------------------------------------------------------------_____________________________________________________________________| Epoch 10 | Time: 2.40s | Train Acc: 0.912, Loss: 0.004 | Val Acc: 0.920, Loss: 0.004 | LR: 0.000500---------------------------------------------------------------------
2.Acc与Loss图
import matplotlib.pyplot as pltimport warningsfrom datetime import datetimewarnings.filterwarnings(\"ignore\")plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 显示中文plt.rcParams[\'axes.unicode_minus\'] = Falseplt.rcParams[\'figure.dpi\'] = 100# 当前时间(用于标题)current_time = datetime.now().strftime(\"%Y-%m-%d %H:%M\")# 横轴:epoch 范围epochs_range = range(len(train_acc))plt.figure(figsize=(12, 3))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label=\'Training Accuracy\')plt.plot(epochs_range, test_acc, label=\'Validation Accuracy\')plt.xlabel(\"Epochs\")plt.ylabel(\"Accuracy\")plt.title(f\'准确率变化({current_time})\')plt.legend(loc=\'lower right\')# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs_range, train_loss, label=\'Training Loss\')plt.plot(epochs_range, test_loss, label=\'Validation Loss\')plt.xlabel(\"Epochs\")plt.ylabel(\"Loss\")plt.title(\'损失变化\')plt.legend(loc=\'upper right\')plt.tight_layout()plt.show()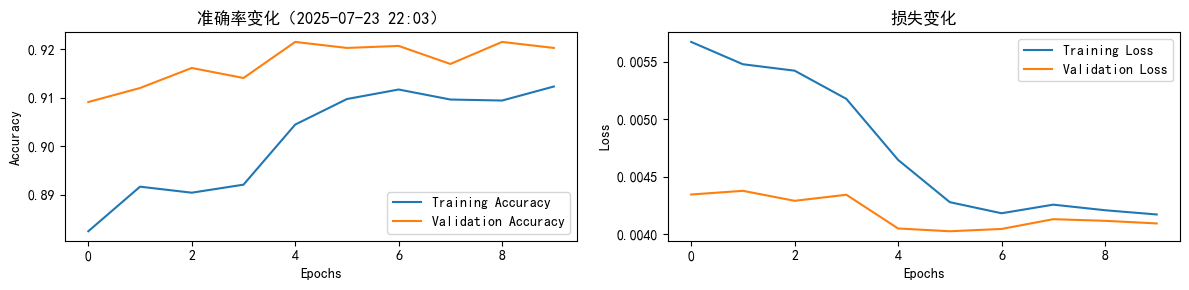
test_acc,test_loss =evaluate(valid_dataloader)print(\'模型准确率为:{:5.4f}\'.format(test_acc))模型准确率为:0.9202
3.测试指定数据
def predict(text,text_pipeline): with torch.no_grad(): text = torch.tensor(text_pipeline(text),dtype=torch.float32) print(text.shape) output = model(text) return output.argmax(1).item()#ex_text_str =\"随便播放一首专辑阁楼里的佛里的歌\"ex_text_str =\"还有双鸭山到淮阴的汽车票吗13号的\"model = model.to(\"cpu\")print(\"该文本的类别是:%s\"% label_name[predict(ex_text_str,text_pipeline)])torch.Size([1, 100])该文本的类别是:Travel-Query
四、学习心得
Word2Vec 模型能够实现中文文本分类任务中的词向量表示,是一种经典的词嵌入方法,通过对大规模文本数据进行训练,将词语映射为连续的向量空间表示。这些词向量能够有效捕捉词与词之间的语义和句法关联,为后续的文本分类模型提供更具表达力的输入特征。

