20250331期:YOLOv12算法深度解析(含结构图)
目录
一、核心架构升级与创新
二、性能表现与硬件适配
三、应用场景扩展
四、部署与优化建议
五、支持的任务和模式
六、应用
YOLOv12算法是YOLO算法的版本之一,它突破了传统CNN架构的局限,首次提出以注意力机制为核心的实时检测框架。该算法通过引入区域注意力模块(A²)、残差高效层聚合网络(R-ELAN)和FlashAttention等技术,显著提高了检测精度和推理速度。在COCO数据集上,YOLOv12不同规模的模型在精度和速度上均有显著提升,展现出优越的性能。同时,该算法支持多任务扩展,具有广泛的应用场景,包括自动驾驶、安防监控、工业检测和医疗影像分析等,展现出强大的应用潜力。
论文:[2502.12524] YOLOv12: Attention-Centric Real-Time Object Detectors
代码:https://github.com/sunsmarterjie/yolov12
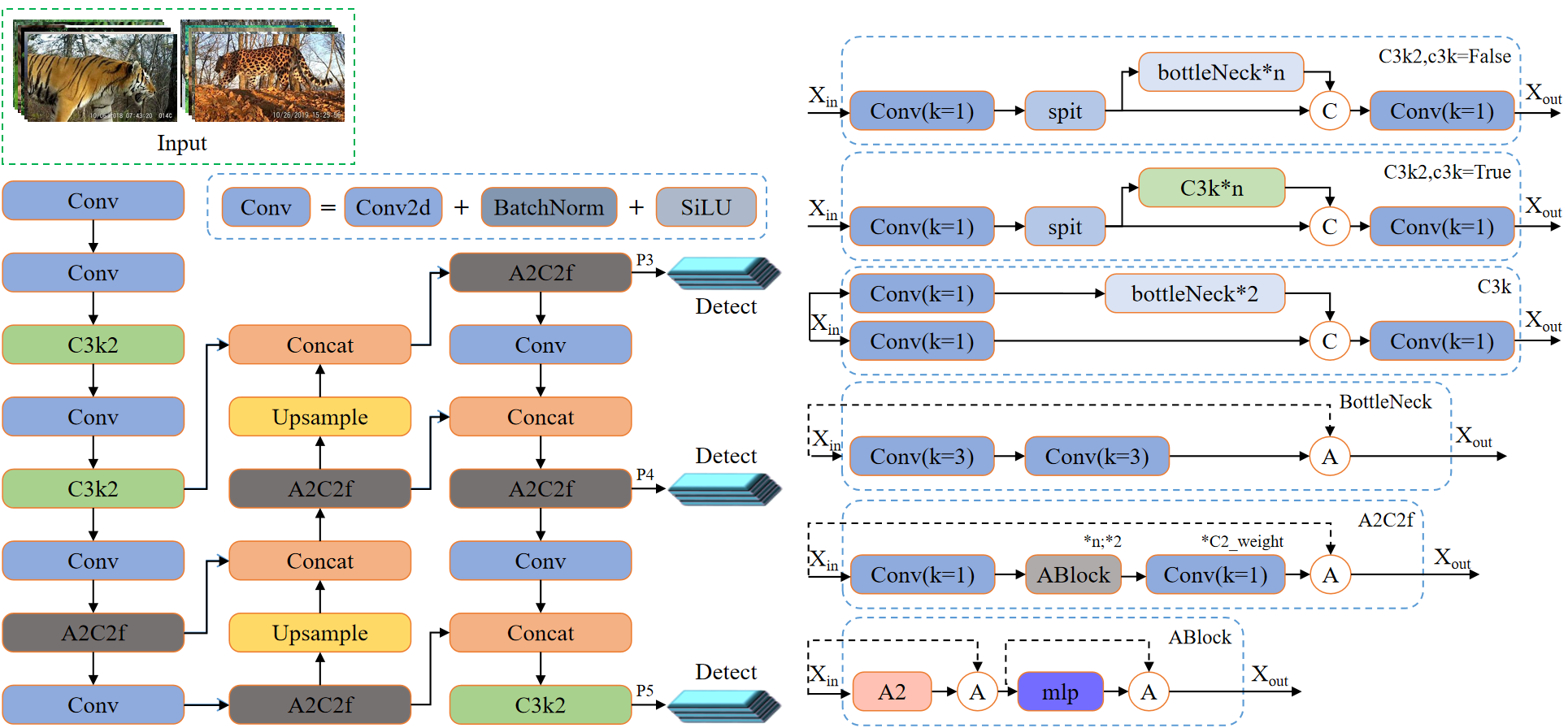
一、核心架构升级与创新
YOLOv12突破了传统CNN架构的局限,首次提出以注意力机制为核心的实时检测框架,通过三大关键改进实现性能跃升:
- 区域注意力模块(Area Attention, A²)
- 创新点:将特征图划分为垂直或水平区域(默认4个),仅在局部区域内计算注意力,避免全局注意力的高复杂度。
- 优势:计算成本从O(L²d)降至O(½n²hd),感受野保留率超75%,显著提升小目标检测精度(如交通监控中的车牌识别)。
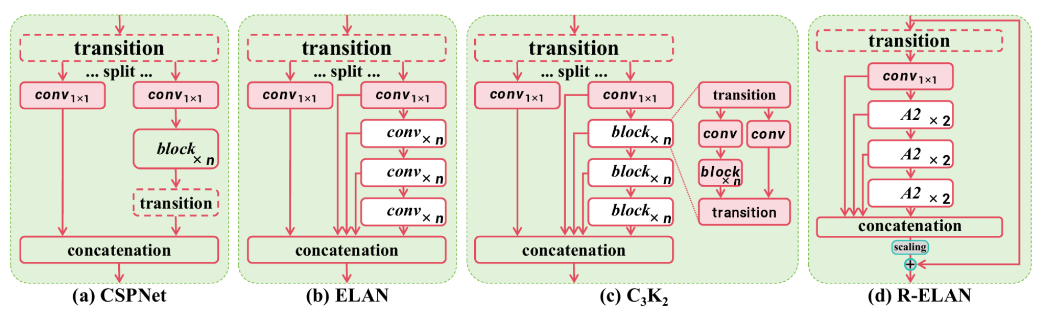
- 残差高效层聚合网络(R-ELAN)
- 改进点:在原始ELAN基础上引入:
- 块级残差设计:通过缩放技术(默认因子0.01)增强训练稳定性,尤其提升大模型(如YOLOv12-X)的收敛性。
- 特征聚合优化:采用“转换层→1×1卷积→区域注意力→残差连接”流程,降低参数量的同时保留特征整合能力。
- 改进点:在原始ELAN基础上引入:
- 计算效率优化
- FlashAttention加速:利用CUDA优化注意力计算,内存访问效率提升10倍以上,但需NVIDIA Turing及以上架构GPU支持。
- 架构精简:移除位置编码,引入7×7深度可分离卷积作为位置感知模块,调整MLP比例至1.2,平衡计算分布。
二、性能表现与硬件适配
YOLOv12在COCO数据集上实现显著突破,支持N/S/M/L/X五类模型,适配不同硬件场景:
(pixels)
50-95
T4 TensorRT10
(M)
(G)
v1.0:
(pixels)
50-95
T4 TensorRT10
(M)
(G)
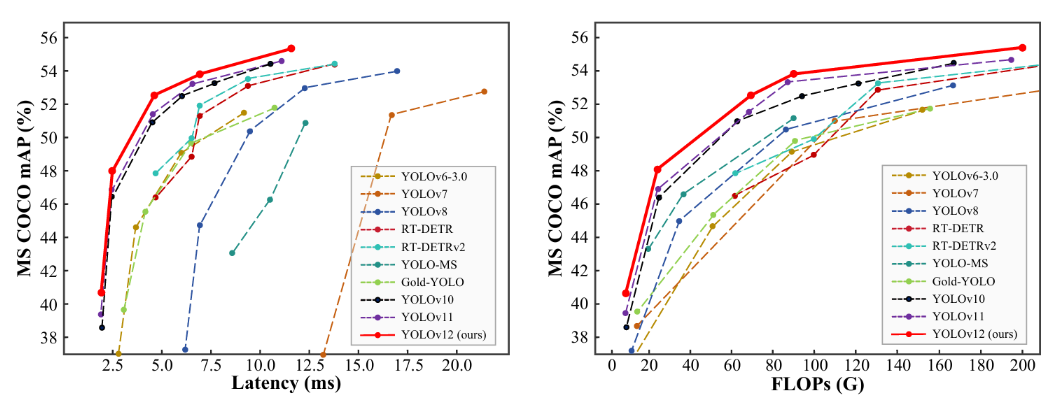
- 在NVIDIA T4GPU 上使用TensorRT FP16精度测量的推理速度。
- 比较显示了 mAP 的相对改进和速度变化的百分比(正值表示速度更快;负值表示速度更慢)。与已公布的 YOLOv10、YOLO11 和RT-DETR 结果(如有)进行了比较
硬件适配特性:
- NVIDIA GPU优化:在Turing(如T4)、Ampere(如RTX30系列)、Ada Lovelace(如RTX4090)架构上可启用FlashAttention,速度提升30%-50%。
- 非支持硬件限制:在无专用加速的CPU/GPU上,推理速度可能下降40%-60%,需手动配置CUDA环境。
三、应用场景扩展
YOLOv12的多任务支持能力显著扩展了其应用领域:
- 实时检测任务
- 自动驾驶:在KITTI数据集上实现车辆/行人检测AP达89.2%,延迟低于2ms。
- 安防监控:支持多目标跟踪(MOT)与异常行为检测,商场场景中误报率降低35%。
- 工业检测与医疗影像
- 缺陷检测:在PCB瑕疵检测中,微小裂纹(<0.5mm)识别率达92.3%,优于传统视觉算法20%。
- 医学影像:乳腺钼靶钙化点检测中,AUC达0.94,辅助诊断效率提升50%。
- 多任务扩展
- 实例分割:通过修改头部网络,在COCO分割任务上mAP达38.1%。
- 姿态估计:集成关键点检测模块后,人体姿态估计误差降低18%。
四、部署与优化建议
-
环境配置:
# 创建Anaconda环境(推荐Python 3.8+)conda create -n yolov12 python=3.8conda activate yolov12# 安装依赖(需PyTorch 1.12+)pip install torch torchvision torchaudio cudatoolkit=11.3pip install numpy opencv-python# 克隆官方仓库git clone https://github.com/sunsmarterjie/yolov12.git -
模型优化策略:
- 轻量化改进:可替换为VanillaNet或MobileViT骨干网络,参数量减少40%,精度损失<1%。
- 量化部署:使用TensorRT FP16量化后,YOLOv12-N在Jetson AGX Xavier上可达25 FPS。
-
性能调优:
- 输入分辨率:640×640时速度与精度平衡最佳,416×416可提升FPS至45(牺牲5% mAP)。
- 批处理优化:启用多流推理(CUDA Streams)可提升吞吐量30%。
五、支持的任务和模式
YOLO12 支持多种计算机视觉任务。下表列出了任务支持和每种任务启用的运行模式(推理、验证、训练和输出):
六、应用
训练:
from ultralytics import YOLOmodel = YOLO(\'yolov12n.yaml\')# Train the modelresults = model.train( data=\'coco.yaml\', epochs=600, batch=256, imgsz=640, scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9 mosaic=1.0, mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2 copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6 device=\"0,1,2,3\",)# Evaluate model performance on the validation setmetrics = model.val()# Perform object detection on an imageresults = model(\"path/to/image.jpg\")results[0].show()预测:
from ultralytics import YOLOmodel = YOLO(\'yolov12{n/s/m/l/x}.pt\')model.predict()导出:
from ultralytics import YOLOmodel = YOLO(\'yolov12{n/s/m/l/x}.pt\')model.export(format=\"engine\", half=True) # or format=\"onnx\"YOLOv12通过区域注意力机制和残差聚合网络实现了精度与速度的双重突破,成为首个高效融合注意力机制的实时检测框架。其多尺度模型设计和硬件适配能力,使其在自动驾驶、工业质检、医疗辅助等地方展现出广泛应用潜力。对于开发者而言,需在硬件选型(优先NVIDIA新架构GPU)和模型轻量化之间权衡,以充分发挥算法优势。
喜欢本篇文章请多多关注,您的鼓励是我最大的动力。欢迎大家互相分享交流。(aaanimals)


