Redis高可用架构演进面试笔记
1. 主从复制架构
核心概念
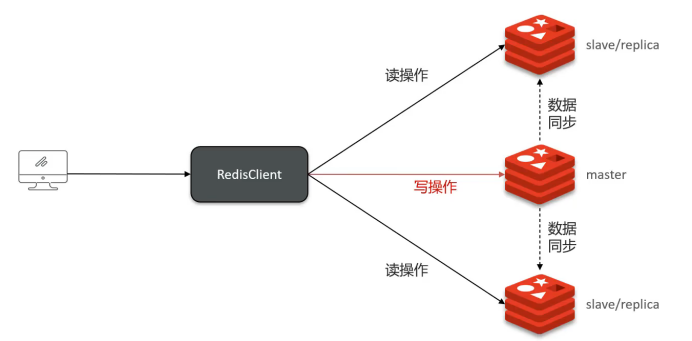
Redis单节点并发能力有限,通过主从集群实现读写分离提升性能:
- Master节点:负责写操作
- Slave节点:负责读操作,从主节点同步数据
主从同步流程
全量同步(首次同步)
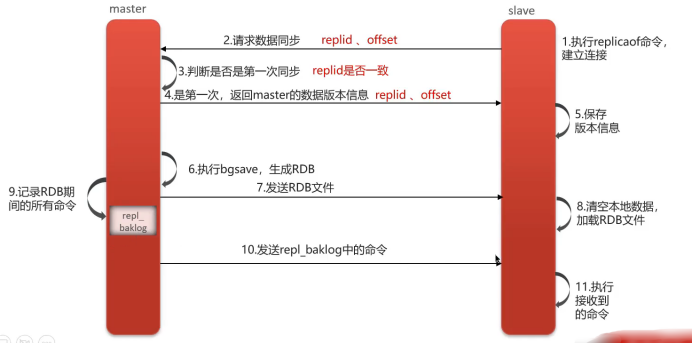
- 建立连接:从节点向主节点发送同步请求(携带replicationid、offset)
- 版本校验:主节点判断是首次请求,与从节点同步版本信息
- 生成快照:主节点执行bgsave生成RDB文件
- 数据传输:将RDB文件发送给从节点加载
- 增量补偿:同步期间新写入的命令记录到缓冲区(replication buffer),随后发送给从节点
增量同步(后续同步)
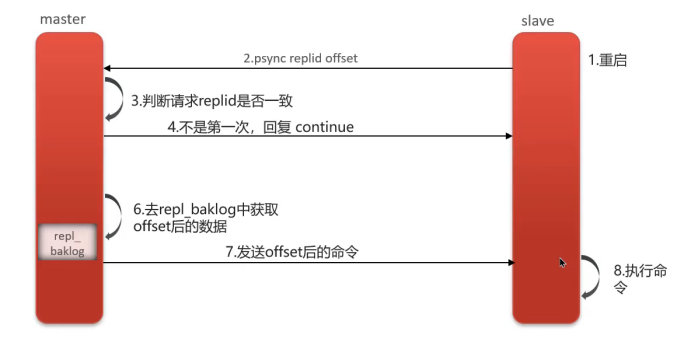
- 断线重连:从节点重启或网络恢复后请求同步
- 偏移量对比:主节点获取从节点的offset值
- 差异同步:从命令日志(replication backlog)中获取offset之后的数据发送给从节点
关键参数:
replicationid:标识数据集版本offset:复制偏移量,标识同步进度
2. 哨兵机制(Sentinel)
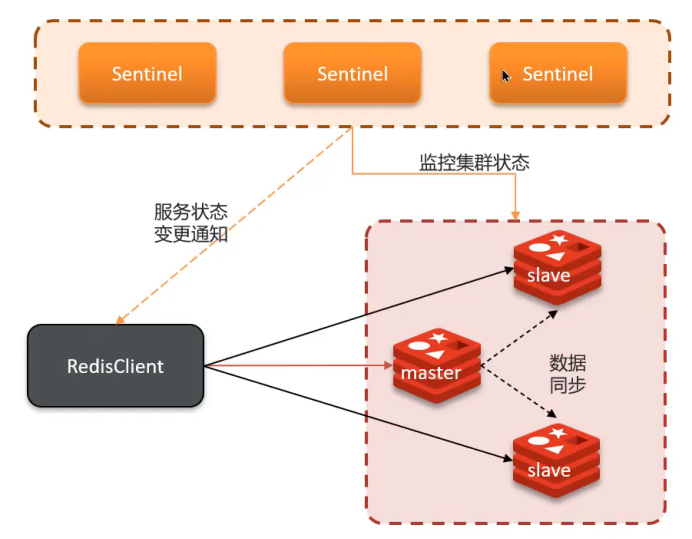
解决问题
主从架构无法自动故障转移,引入哨兵实现高可用。
工作原理
健康监测
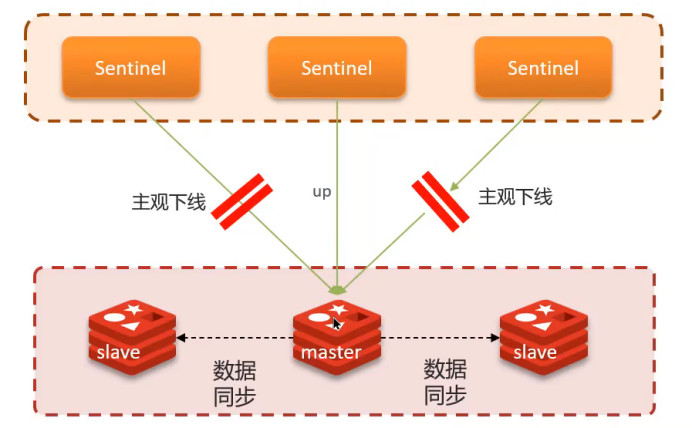
- 心跳检测:每隔1秒向集群实例发送PING命令
- 主观下线:单个哨兵认为实例无响应
- 客观下线:超过quorum数量的哨兵都认为实例下线(quorum > 哨兵数/2)
故障转移
自动选举新的主节点,选主规则按优先级:
- 网络连接:排除与主节点断开时间过长的从节点
- slave-priority:优先级配置,数值越小优先级越高
- 复制偏移量:offset越大(数据越新)优先级越高
- 运行ID:ID越小优先级越高
3. 脑裂问题
问题描述
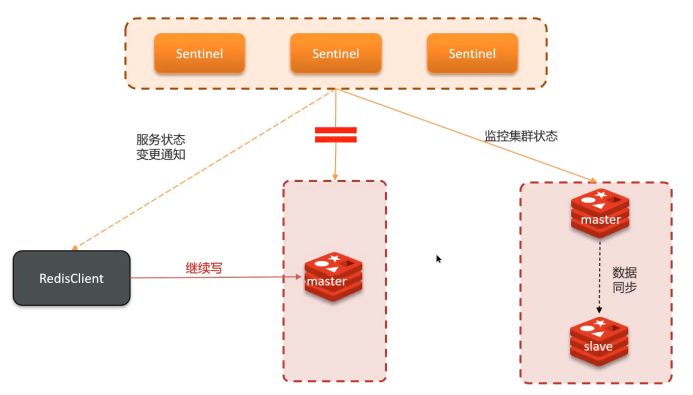
网络分区导致集群出现两个Master节点,类似\"大脑分裂\"。
产生原因
主节点与哨兵、从节点网络隔离,哨兵误判主节点下线并选举新主节点。
危害
- 客户端向旧主节点写入数据
- 新主节点无法同步这些数据
- 网络恢复后数据丢失
解决方案
配置参数限制写入条件:
min-replicas-to-write 1 # 至少1个从节点在线min-replicas-max-lag 5 # 主从同步延迟不超过5秒4. 分片集群(Cluster)
解决问题
主从+哨兵仍存在两个核心问题:
- 海量数据存储:单主节点内存限制
- 高并发写入:单主节点写入瓶颈
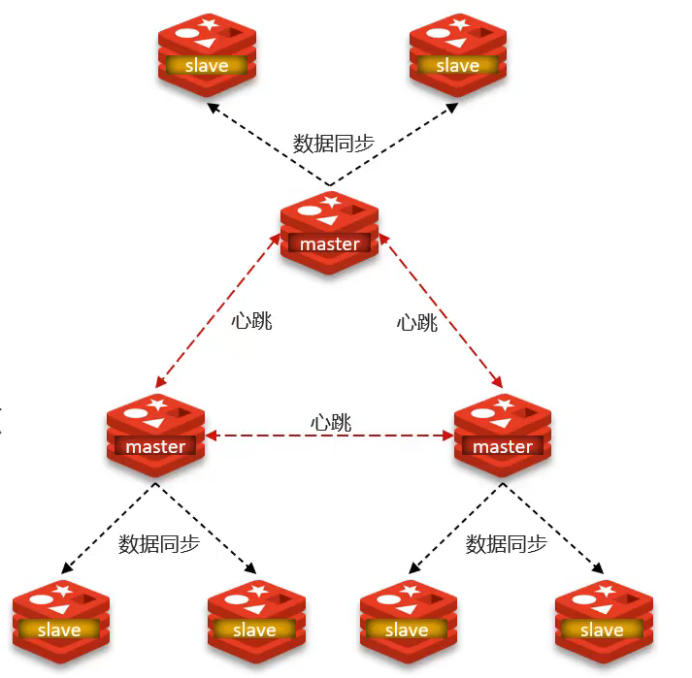
集群特征
- 多个Master节点,每个存储不同数据
- 每个Master可配置多个Slave节点
- Master间通过PING监测健康状态
- 客户端可访问任意节点,自动路由到正确节点
数据分片机制
哈希槽(Hash Slot)
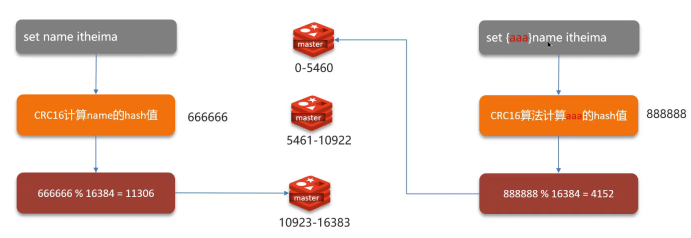
- 槽位总数:16384个哈希槽
- 分配算法:CRC16(key) % 16384
- 槽位分配:每个Master节点负责一部分槽位
数据路由流程
- 客户端对key进行CRC16校验
- 对16384取模确定槽位
- 根据槽位映射找到对应节点
- 如果访问错误节点,返回MOVED重定向
面试要点总结
架构演进路径
单机 → 主从复制 → 哨兵集群 → 分片集群
各架构解决的问题
- 主从复制:读写分离,提升并发读能力
- 哨兵机制:自动故障转移,实现高可用
- 分片集群:水平扩展,解决存储和写入瓶颈
核心技术点
- 数据同步:全量同步 + 增量同步
- 故障检测:心跳机制 + 主客观下线
- 数据分片:一致性哈希槽算法
- 脑裂预防:最小从节点数 + 同步延迟限制


