使用国内大模型复现langchain官方RAG Tutorials part1
langchain官方RAG demo文档:https://python.langchain.com/docs/tutorials/rag/
总览
一个典型的RAG应用由两部分组成:索引(Indexing)和检索生成(Retrieval and generation)。索引是一条从数据源摄取数据并对其进行索引的管道,索引工作通常离线完成。检索生成就是实际的RAG调用,它在运行时使用用户输入检索相关数据,并将其传入模型。
从原始数据到得出答案最常见的完整流程如下:
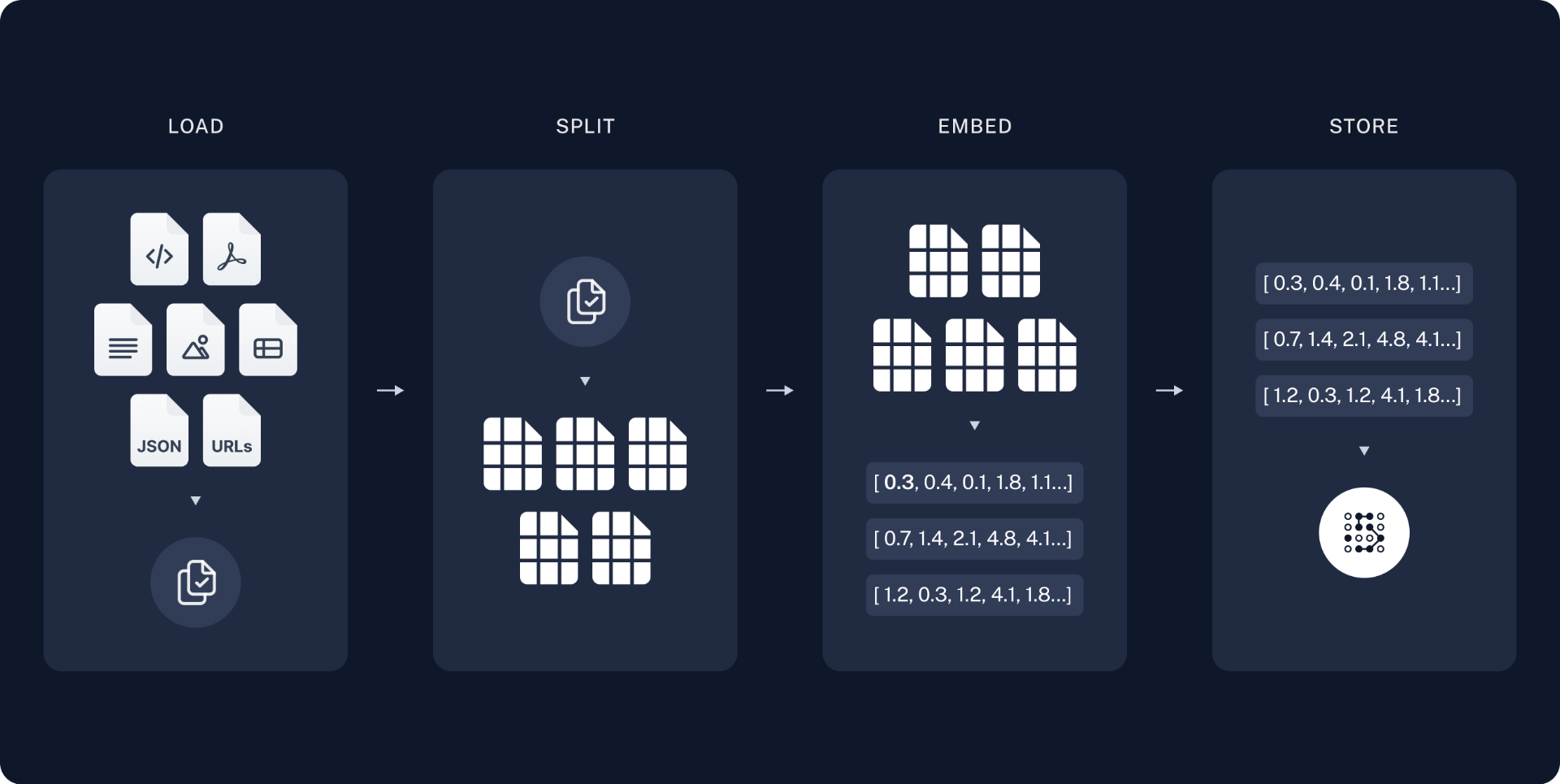
索引:
- 加载(load):首先需要加载数据,使用Document Loaders完成。
- 分割(split):文本分割器将大型文档拆分成较小的部分。这对于索引数据和将其输入模型都非常有用,因为较大的部分更难搜索,而且无法适应模型有限的上下文窗口。
- 存储(store):我们需要一个地方来存储和索引我们的分割内容,以便日后能够对其进行搜索。这通常通过向量存储库和嵌入模型来实现。
检索生成
- 检索(Retrieve):给定一个用户输入,使用检索器检索出相关的分割内容。
- 生成(Generate):问题和检索数据组成的提示词被送入大模型来生成答案。
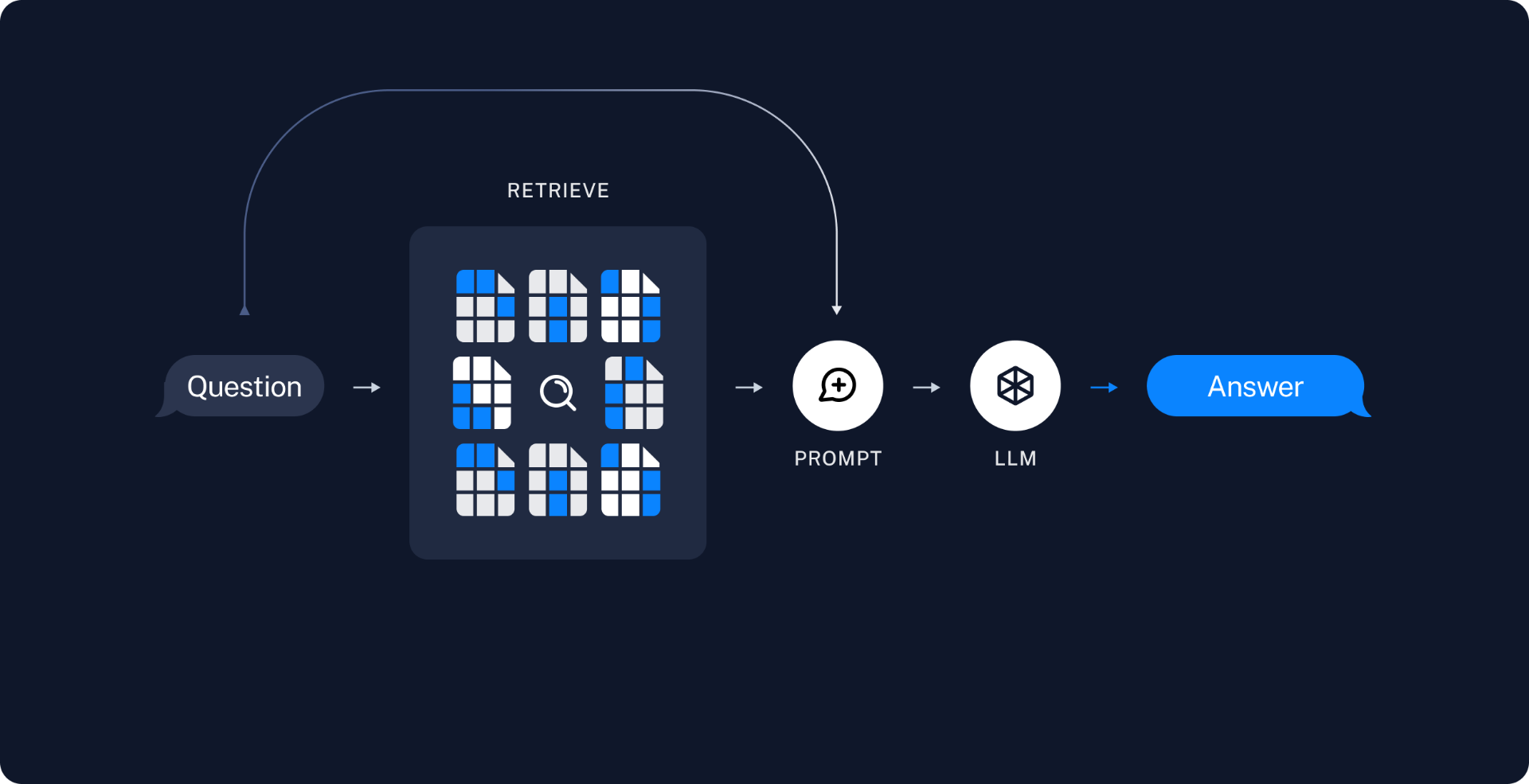
为数据建立索引之后,我们将使用LangGraph作为编排框架来实现检索和生成步骤。
实现
官方文档使用Jupyter Notebook来运行实现RAG的代码,便于观察每一步的结果。首先需要安装依赖:
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraphLangSmith是一个监控工具,当应用变的越来越复杂时,使用它可以方便的观察内部的LLM调用,它可以一键式配置:
import getpassimport osos.environ[\"LANGSMITH_TRACING\"] = \"true\"os.environ[\"LANGSMITH_API_KEY\"] = getpass.getpass()组件
我们需要从LangChain的集成套件中选择三个组件。
对话模型(chat model)
对话模型就是最终输入的模型,因为网络原因,使用国外大模型可能非常麻烦,甚至还存在地区限制,这里选择我们的国产大模型DeepSeek:
%pip install -qU langchain-deepseekimport getpassimport osif not os.getenv(\"DEEPSEEK_API_KEY\"): os.environ[\"DEEPSEEK_API_KEY\"] = getpass.getpass(\"Enter your DeepSeek API key: \")from langchain_deepseek import ChatDeepSeekllm = ChatDeepSeek( model=\"deepseek-chat\", temperature=0, max_tokens=None, timeout=None, max_retries=2, # other params...)可以使用如下代码测试调用一下:
messages = [ ( \"system\", \"You are a helpful assistant that translates English to French. Translate the user sentence.\", ), (\"human\", \"I love programming.\"),]ai_msg = llm.invoke(messages)ai_msg.content嵌入模型(embeddings model)
嵌入模型用来将分割文本转为向量,这里选择智谱的大模型:
%pip install -qU zhipuaifrom langchain_community.embeddings import ZhipuAIEmbeddingsembeddings = ZhipuAIEmbeddings( model=\"embedding-3\", # With the `embedding-3` class # of models, you can specify the size # of the embeddings you want returned. # dimensions=1024)可以使用如下代码测试调用是否成功:
# Create a vector store with a sample textfrom langchain_core.vectorstores import InMemoryVectorStoretext = \"LangChain is the framework for building context-aware reasoning applications\"vectorstore = InMemoryVectorStore.from_texts( [text], embedding=embeddings,)# Use the vectorstore as a retrieverretriever = vectorstore.as_retriever()# Retrieve the most similar textretrieved_documents = retriever.invoke(\"What is LangChain?\")# show the retrieved document\'s contentretrieved_documents[0].page_content向量存储(vector store)
分割文本转为向量后还需要找个地方将它存储起来,这里就选择简单的内存向量存储:
pip install -qU langchain-corefrom langchain_core.vectorstores import InMemoryVectorStorevector_store = InMemoryVectorStore(embeddings)预览
官方Tutorial构建了一个关于网页内容问答的应用,网页使用的是一个称为大模型驱动自主代理博客,这个应用允许我们询问关于这个网页内容的问题。
通过50行代码就可以构建一个简单的索引管道和RAG调用链来实现这个应用:
import bs4from langchain import hubfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_core.documents import Documentfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langgraph.graph import START, StateGraphfrom typing_extensions import List, TypedDict# Load and chunk contents of the blogloader = WebBaseLoader( web_paths=(\"https://lilianweng.github.io/posts/2023-06-23-agent/\",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=(\"post-content\", \"post-title\", \"post-header\") ) ),)docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)all_splits = text_splitter.split_documents(docs)# Index chunks_ = vector_store.add_documents(documents=all_splits)# Define prompt for question-answering# N.B. for non-US LangSmith endpoints, you may need to specify# api_url=\"https://api.smith.langchain.com\" in hub.pull.prompt = hub.pull(\"rlm/rag-prompt\")# Define state for applicationclass State(TypedDict): question: str context: List[Document] answer: str# Define application stepsdef retrieve(state: State): retrieved_docs = vector_store.similarity_search(state[\"question\"]) return {\"context\": retrieved_docs}def generate(state: State): docs_content = \"\\n\\n\".join(doc.page_content for doc in state[\"context\"]) messages = prompt.invoke({\"question\": state[\"question\"], \"context\": docs_content}) response = llm.invoke(messages) return {\"answer\": response.content}# Compile application and testgraph_builder = StateGraph(State).add_sequence([retrieve, generate])graph_builder.add_edge(START, \"retrieve\")graph = graph_builder.compile()测试调用如下:
response = graph.invoke({\"question\": \"What is Task Decomposition?\"})print(response[\"answer\"])输出:
Task decomposition is the process of breaking down a complex task into smaller, manageable subtasks. It can be done using methods like simple prompting with LLMs, task-specific instructions, or human inputs. Alternatively, approaches like LLM+P or techniques such as Chain of Thought and Tree of Thoughts further enhance decomposition by leveraging external planners or exploring multiple reasoning paths.更换了对话模型之后发现输出结果和官方的结果是不太一样的,但是语义是相同的。当然使用DeepSeek和智谱大模型都需要充值才可以调用API,不然会提示余额不足。简单的Turtotial调用一次也就几分钱,充个10块钱就够学习用了。

