【Elasticsearch入门到落地】14、DSL复合查询_es复合查询
接上篇《13、DSL查询详解:分类、语法与实战场景》
上一篇我们讲解了ElasticSearch的DSL语法,并结合实际业务场景编写了一些简单的查询语句。本篇我们来学习DSL更加复杂的语法,进行复合查询,学习“相关性算分”、“FunctionScoreQuery”和“BooleanQuery”的相关内容。
一、复合查询概念
在Elasticsearch中,复合查询(Compound Query)是构建复杂搜索逻辑的核心工具。它允许将多个查询条件组合起来,灵活控制匹配逻辑和相关性算分。本篇博文将深入探讨BooleanQuery和FunctionScoreQuery的使用场景、原理及优化技巧,帮助大家解决实际业务中的搜索需求。
二、为什么需要复合查询?
Elasticsearch的查询分为两类:
1.简单查询(如match、term):直接匹配字段值。
2.复合查询(如bool、function_score):组合多个查询条件,支持逻辑运算和算分干预。
为什么需要复合查询?
●业务场景复杂:例如,电商搜索需要同时匹配关键词、过滤价格范围、按销量排序。
●算分需求:基础相关性(如TF-IDF)可能无法满足业务优先级(如推荐热门商品)。
三、相关性算分机制详解
(一)相关性算分的基本概念
相关性(Relevance)指的是搜索引擎对搜索请求与索引文档之间匹配程度的评估。当用户执行一个搜索查询时,Elasticsearch会根据其内部的相关性评分机制为返回的每个文档分配一个得分(_score),得分越高代表文档与搜索请求越相关。
相关性算分的核心目标是:精准的内容排序、个性化搜索结果和搜索体验优化。通过复杂的打分算法,Elasticsearch能够判断哪些文档更符合用户的搜索意图,并将这些文档排在结果列表的前面。
(二)相关性算分的核心算法
1. TF-IDF算法
在Elasticsearch5.0版本之前,系统主要采用TF-IDF(Term Frequency-Inverse Document Frequency)算法作为相关性计算的基础。
TF(词频Term Frequency):搜索文本中的各个词条在要搜索的field文本中出现的次数,次数越多就越相关。例如:
●搜索\"hello world\"
●doc1内容:\"hello world,I love you\"(匹配2次)
●doc2内容:\"hello,I love you,too\"(只匹配1次)
●结果:doc1的score更高,因为它匹配的次数更多
IDF(逆文档频率Inverse Document Frequency):搜索文本中的各个词条在整个index的所有document中出现的次数,出现的次数越多,越不相关。例如:
●搜索\"hello world\"
●假设index有10000条document
●\"hello\"在10000个document中出现了2000次
●\"world\"在10000个document中出现了100次
●结果:包含\"world\"的文档更相关,因为这个词出现的次数更少
TF-IDF算法的计算公式为:
TF-IDF = TF(关键词1)*IDF(关键词1) + TF(关键词2)*IDF(关键词2)[8](@ref)然而,TF-IDF算法有一个明显的问题:随着TF无限增加时,相关度算法会无限增加,这在实际应用中可能导致不合理的结果。
2. BM25算法
从Elasticsearch5.0版本开始,系统采用了BM25(Best Match 25)算法作为默认的相关性评分算法,这是对TF-IDF算法的改进版本。
BM25算法的核心公式如下:
score(D,Q) = ∑ IDF(qi) * (f(qi,D) * (k1 + 1)) / (f(qi,D) + k1 * (1 - b + b * |D|/avgdl))其中:
●qi:查询项
●D:被评价的文档
●IDF(qi):第i个查询项的逆文档频率
●f(qi,D):查询项在文档内的出现次数
●|D|和avgdl:单篇文档字数及其所在集合的平均长度
●k1和b:可调参数,控制饱和程度与惩罚力度
BM25算法相比TF-IDF有以下改进:
1.引入了参数k1(默认1.2)控制词频饱和度,防止词频过高导致分数不合理增长
2.通过参数b(默认0.75)实现文档长度归一化,解决长文档和短文档的公平比较问题
3.对常见词和罕见词的处理更加合理,提高了搜索结果的准确性
BM25算法的优点包括:
1.能够对文档进行更准确的评分,得到更好的搜索结果
2.具有良好的可调节性,可以通过调整参数适应不同数据集和查询需求
3.计算速度较快,适用于大规模文本数据的处理
当然,除了核心算法外,Elasticsearch的相关性算分还受“字段长度归一化(Field-length Norm)”、“查询规范因子(Query Norm)”、“位置信息”等因素影响,这里不再进行赘述,感兴趣的同学可以自行检索学习。
Elasticsearch的相关性算分是一个复杂但高度可配置的系统,从早期的TF-IDF算法发展到现在的BM25算法,不断提高了搜索结果的准确性和合理性。了解这些算分机制的原理和影响因素,对于构建高效的搜索应用至关重要。通过合理配置和优化,可以显著提升用户体验,使搜索结果更加符合用户的真实需求。
四、相关性算分的核心算法
Elasticsearch提供了丰富的查询功能来满足复合查询需求。其中,BooleanQuery和FunctionScoreQuery是两种常用的查询类型,它们分别解决了不同的搜索场景问题。
(一)BooleanQuery详解
1.基本概念与使用场景
BooleanQuery(布尔查询)是Elasticsearch中最基础也是最重要的复合查询类型,它允许通过布尔逻辑将多个查询条件组合起来,构建复杂的查询逻辑。在实际应用中,BooleanQuery适用于以下典型场景:
(1)多条件组合搜索:例如电商平台中同时筛选品牌、价格区间、商品类型的场景
(2)精确过滤与全文搜索结合:如搜索某城市中名称包含特定关键词的酒店
(3)排除特定内容:如新闻搜索中排除某些敏感词汇的结果
(4)条件可选搜索:某些条件为可选而非必须满足的场景
2.核心子句与原理
BooleanQuery由四种类型的子句构成,每种子句有不同的逻辑语义和对相关性算分的影响:
(1)must子句:
●语义:必须满足的条件,相当于逻辑AND
●算分影响:文档必须匹配所有must子句,每个匹配的must子句都会贡献到最终的相关性得分(_score)中
●示例:\"must\": [{\"term\": {\"city\": \"上海\"}}] 查找城市为上海的文档
(2)should子句:
●语义:应该满足的条件,相当于逻辑OR
●算分影响:在没有must子句时,至少需要匹配一个should子句;有must子句时,匹配的should子句会增加额外分数
●特殊参数:可通过minimum_should_match指定最少需要匹配的should子句数量
●示例:\"should\": [{\"term\": {\"brand\": \"皇冠假日\"}}, {\"term\": {\"brand\": \"华美达\"}}] 查找品牌为皇冠假日或华美达的文档
(3)must_not子句:
●语义:必须不满足的条件,相当于逻辑NOT
●算分影响:不参与算分,在过滤上下文中执行,结果会被缓存
示例:\"must_not\": [{\"range\": {\"price\": {\"lte\": 500}}}] 排除价格低于500的文档
(4)filter子句:
●语义:必须满足的过滤条件
●算分影响:不参与算分,在过滤上下文中执行,结果会被缓存以提高性能
●与must的区别:不影响相关性评分,适合用于结构化数据的精确过滤
●示例:\"filter\": [{\"range\": {\"score\": {\"gte\": 45}}}] 筛选评分大于等于45的文档
BooleanQuery采用\"匹配越多越好\"的评分策略,来自每个匹配的must或should子句的分数会被累加,形成文档的最终_score。
3.DSL语法样例
示例1:多条件组合查询(城市+品牌+价格区间+评分)
(1)查询语法
{ \"query\": { \"bool\": { \"must\": [ {\"term\": {\"city\": \"北京\"}}, {\"term\": {\"brand\": \"皇冠假日\"}} ], \"filter\": [ {\"range\": {\"price\": {\"gte\": 400, \"lte\": 500}}}, {\"range\": {\"score\": {\"gte\": 45}}} ], \"should\": [ {\"term\": {\"starName\": \"五星级\"}}, {\"term\": {\"business\": \"国展中心\"}} ], \"minimum_should_match\": 1 } }}(2)语句作用
查找北京地区\"皇冠假日\"品牌的酒店,价格在400-500元之间,评分≥45分,并且满足以下条件之一:是五星级酒店或位于国展中心。
(3)详细解释
must子句(必须满足):
{\"term\": {\"city\": \"北京\"}}:精确匹配城市为北京
{\"term\": {\"brand\": \"皇冠假日\"}}:精确匹配品牌为皇冠假日
filter子句(过滤条件,不参与算分):
{\"range\": {\"price\": {\"gte\": 400, \"lte\": 500}}}:价格在400到500元之间
{\"range\": {\"score\": {\"gte\": 45}}}:评分≥45分
should子句(应该满足,至少匹配一个):
{\"term\": {\"star_name\": \"五星级\"}}:星级为五星级
{\"term\": {\"business\": \"国展中心\"}}:位于国展中心
\"minimum_should_match\": 1:至少满足一个should条件
(4)查询结果
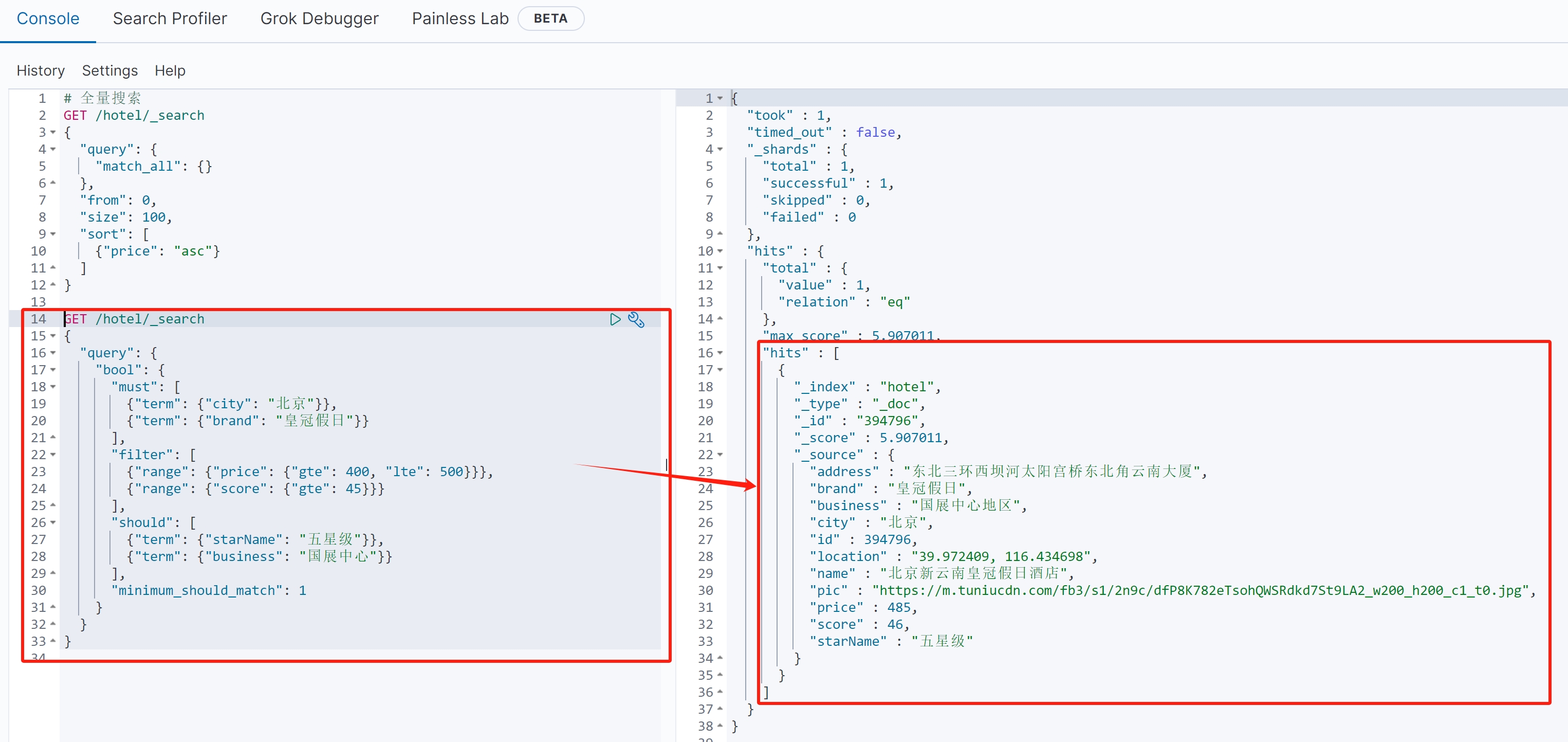
示例2:排除特定条件的查询
(1)查询语法
{ \"query\": { \"bool\": { \"must\": [ {\"match\": {\"name\": \"酒店\"}} ], \"must_not\": [ {\"term\": {\"brand\": \"7天酒店\"}}, {\"range\": {\"price\": {\"lt\": 300}}} ], \"should\": [ {\"term\": {\"starName\": \"五钻\"}}, {\"term\": {\"starName\": \"五星级\"}} ], \"minimum_should_match\": 1 } }}(2)语句作用
查找名称包含\"酒店\"的文档,排除7天品牌和价格低于300元的酒店,优先展示五钻或五星级酒店。
(3)详细解释
must子句:
{\"match\": {\"name\": \"酒店\"}}:在name字段中匹配\"酒店\"关键词
must_not子句(必须不满足):
{\"term\": {\"brand\": \"7天酒店\"}}:排除7天酒店品牌
{\"range\": {\"price\": {\"lt\": 300}}}:排除价格低于300元的酒店
should子句:
{\"term\": {\"star_name\": \"五钻\"}}:星级为五钻
{\"term\": {\"star_name\": \"五星级\"}}:星级为五星级
\"minimum_should_match\": 1:至少满足一个should条件(提升相关度)
(4)查询结果
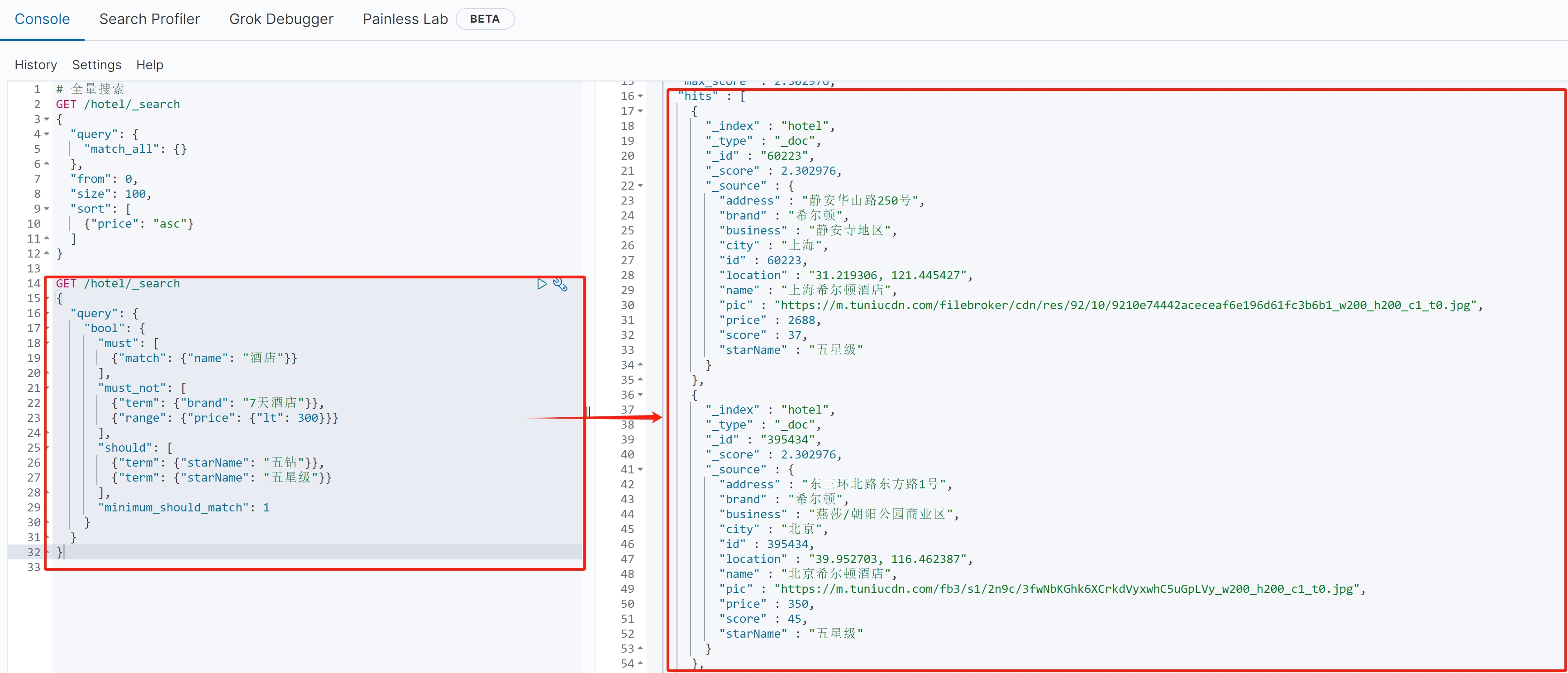
(二)FunctionScoreQuery详解
1.基本概念与使用场景
FunctionScoreQuery(函数评分查询)是Elasticsearch中用于自定义相关性算分的高级查询类型,它允许修改或完全替换默认的相关性评分。典型使用场景包括:
(1)业务加权:提升特定业务属性(如品牌、推荐级别)的文档排名
●示例:提升\"如家\"品牌酒店的排名
(2)时间衰减:让新近内容获得更高排名,如新闻、博客文章
(3)地理位置排序:基于距离远近调整结果排名
(4)个性化推荐:结合用户画像和行为数据定制排序
(5)随机展示:需要随机抽样或打散结果的场景
(6)热门内容:结合点击率、销量等指标提升热门内容排名
2.核心组成与原理
FunctionScoreQuery由四个核心部分组成:
(1)原始查询(query):
●基础查询条件,使用BM25算法计算原始得分(query score)
●示例:\"query\": {\"term\": {\"brand\": {\"value\": \"如家\"}}}
(2)过滤条件(filter):
●决定哪些文档需要重新算分
●只有匹配filter的文档才会应用算分函数
●示例:\"filter\": {\"term\": {\"brand\": \"如家\"}}
(3)算分函数(functions):
定义如何计算新分数,支持多种函数类型:
●weight:恒定权重,如\"weight\": 2
●field_value_factor:基于字段值计算,如\"field_value_factor\": {\"field\": \"likes\"}
●random_score:随机分数,如\"random_score\": {}
●decay functions:衰减函数(线性、高斯、指数),如地理位置衰减
●script_score:自定义脚本计算,最灵活但性能较差
(4)运算模式:
●boost_mode:定义function score与query score的合并方式:
multiply(默认):相乘,new_score = query_score * function_score
replace:替换,new_score = function_score
sum/avg/max/min:求和/平均/最大/最小
●score_mode:多个函数时的分数合并方式:
multiply/sum/avg/max/min/first
3.DSL语法样例
示例1:基于评分和价格的加权
(1)查询语法
{ \"query\": { \"function_score\": { \"query\": { \"match_all\": {} }, \"functions\": [ { \"field_value_factor\": { \"field\": \"score\", \"factor\": 0.1, \"modifier\": \"sqrt\" } }, { \"field_value_factor\": { \"field\": \"price\", \"factor\": 0.01, \"modifier\": \"reciprocal\" } } ], \"boost_mode\": \"sum\" } }}(2)语句作用
对所有酒店进行重新评分,评分规则是:酒店原始评分加上基于score和price字段的加权值,最终按新评分排序。
(3)详细解释
●基础查询:\"match_all\": {} 匹配所有文档
●评分函数1:
\"field\": \"score\":基于score字段计算
\"factor\": 0.1:权重因子为0.1
\"modifier\": \"sqrt\":使用平方根函数平滑处理(√score)
效果:评分越高,加分越多,但增幅递减
●评分函数2:
\"field\": \"price\":基于price字段计算
\"factor\": 0.01:权重因子
\"modifier\": \"reciprocal\":使用倒数函数实现价格越高值越小
效果:价格越高,减分越多,但减幅递减
●\"boost_mode\": \"sum\":将原始评分与函数评分相加作为最终评分
(4)查询结果
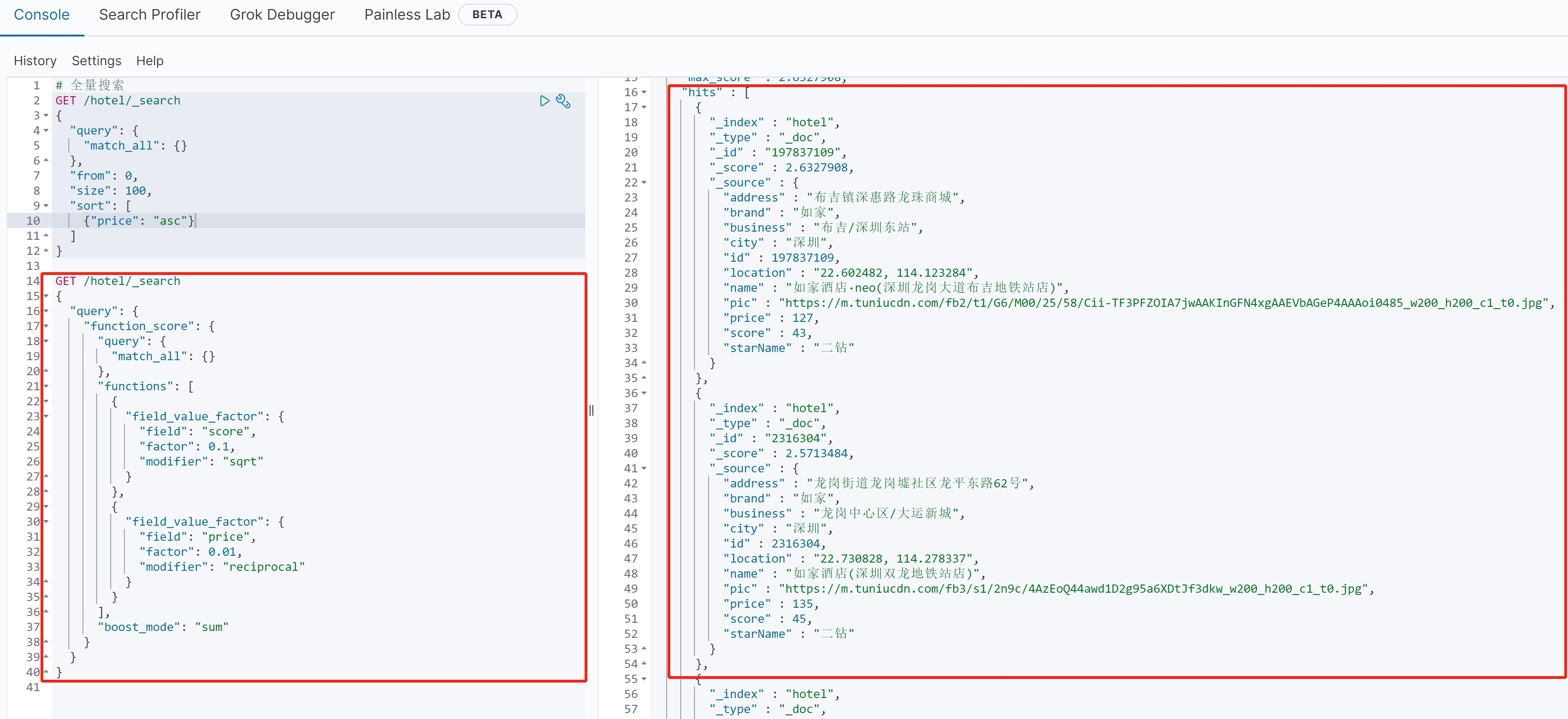
示例2:地理位置衰减函数
(1)查询语法
{ \"query\": { \"function_score\": { \"query\": { \"match_all\": {} }, \"functions\": [ { \"gauss\": { \"location\": { \"origin\": \"31.235152,121.506082\", \"scale\": \"2km\", \"offset\": \"500m\", \"decay\": 0.5 } } } ], \"boost_mode\": \"multiply\" } }}(2)语句作用
基于高斯衰减函数,使距离陆家嘴(31.235152,121.506082)越近的酒店得分越高。
(3)详细解释
\"origin\": \"31.235152,121.506082\":中心点坐标(上海金茂君悦大酒店)
\"scale\": \"2km\":衰减范围半径2公里
\"offset\": \"500m\":500米内不衰减,保持最高分
\"decay\": 0.5:衰减率为0.5
\"boost_mode\": \"multiply\":将衰减系数与原始评分相乘
效果:距离中心点越近,得分越高,2公里外得分显著降低
(4)查询结果
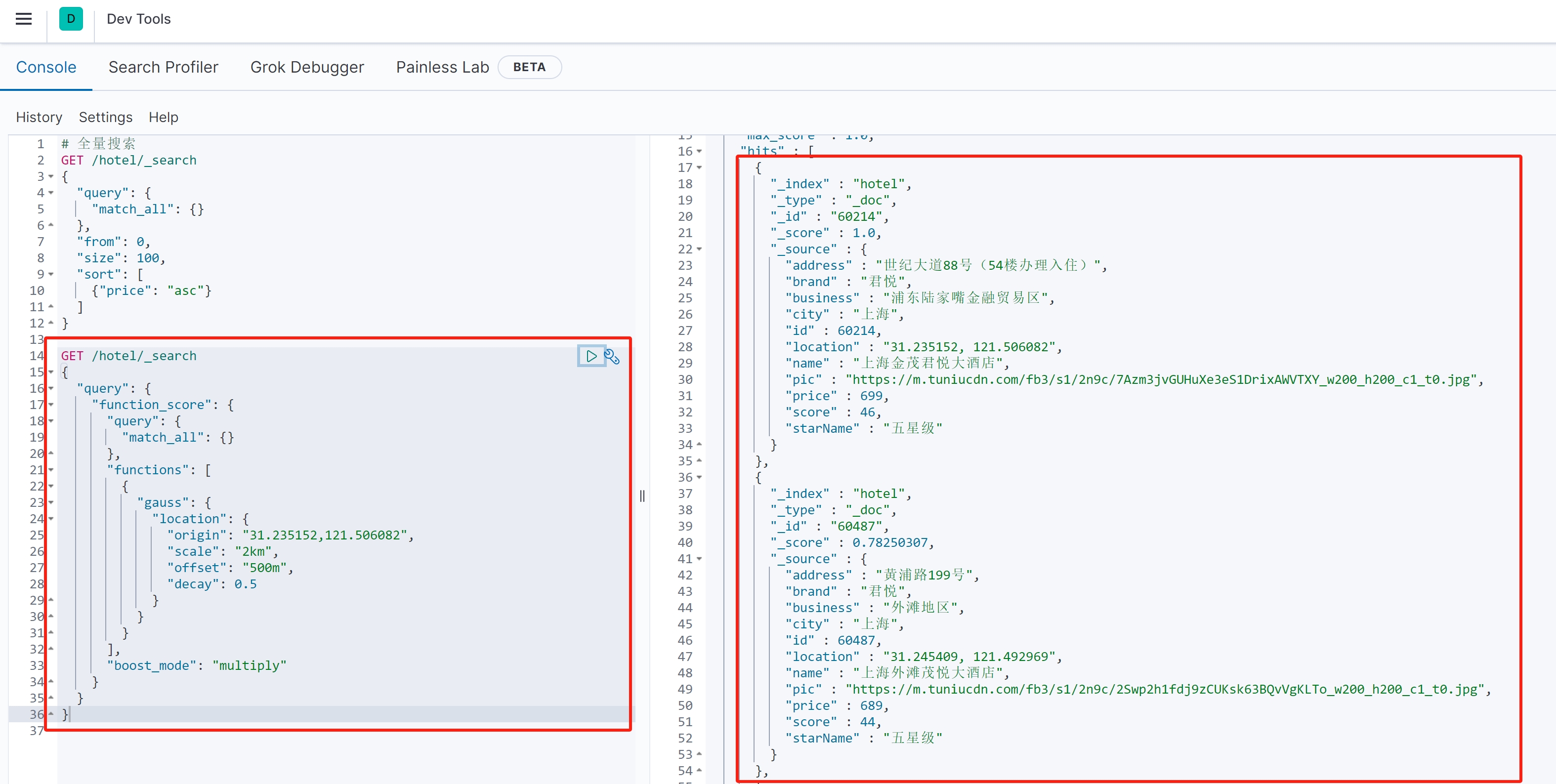
(三)BooleanQuery与FunctionScoreQuery的结合应用
在实际应用中,BooleanQuery和FunctionScoreQuery经常需要结合使用以实现复杂的业务需求。以下是几种典型结合方式:
示例1:先筛选后加权
(1)查询语法
{ \"query\": { \"function_score\": { \"query\": { \"bool\": { \"must\": [ {\"term\": {\"city\": \"上海\"}} ], \"filter\": [ {\"range\": {\"price\": {\"lte\": 1000}}}, {\"range\": {\"score\": {\"gte\": 40}}} ] } }, \"functions\": [ { \"filter\": {\"term\": {\"brand\": \"皇冠假日\"}}, \"weight\": 2 }, { \"filter\": {\"term\": {\"brand\": \"万豪\"}}, \"weight\": 1.5 }, { \"filter\": {\"term\": {\"starName\": \"五星级\"}}, \"weight\": 1.2 } ], \"score_mode\": \"sum\", \"boost_mode\": \"multiply\" } }}(2)语句作用
先筛选上海地区价格≤1000且评分≥40的酒店,然后对不同品牌和星级进行加权。
(3)详细解释
●基础查询:
必须满足:城市=上海
过滤条件:价格≤1000,评分≥40
●加权规则:
皇冠假日品牌:权重2.0
万豪品牌:权重1.5
五星级:权重1.2
多个条件匹配时权重会叠加。
●\"score_mode\": \"sum\":多个函数评分相加
●\"boost_mode\": \"multiply\":加权结果与原始评分相乘
●效果:符合条件的皇冠假日五星级酒店得分=原始_score × 2 × 1.2
(4)查询结果
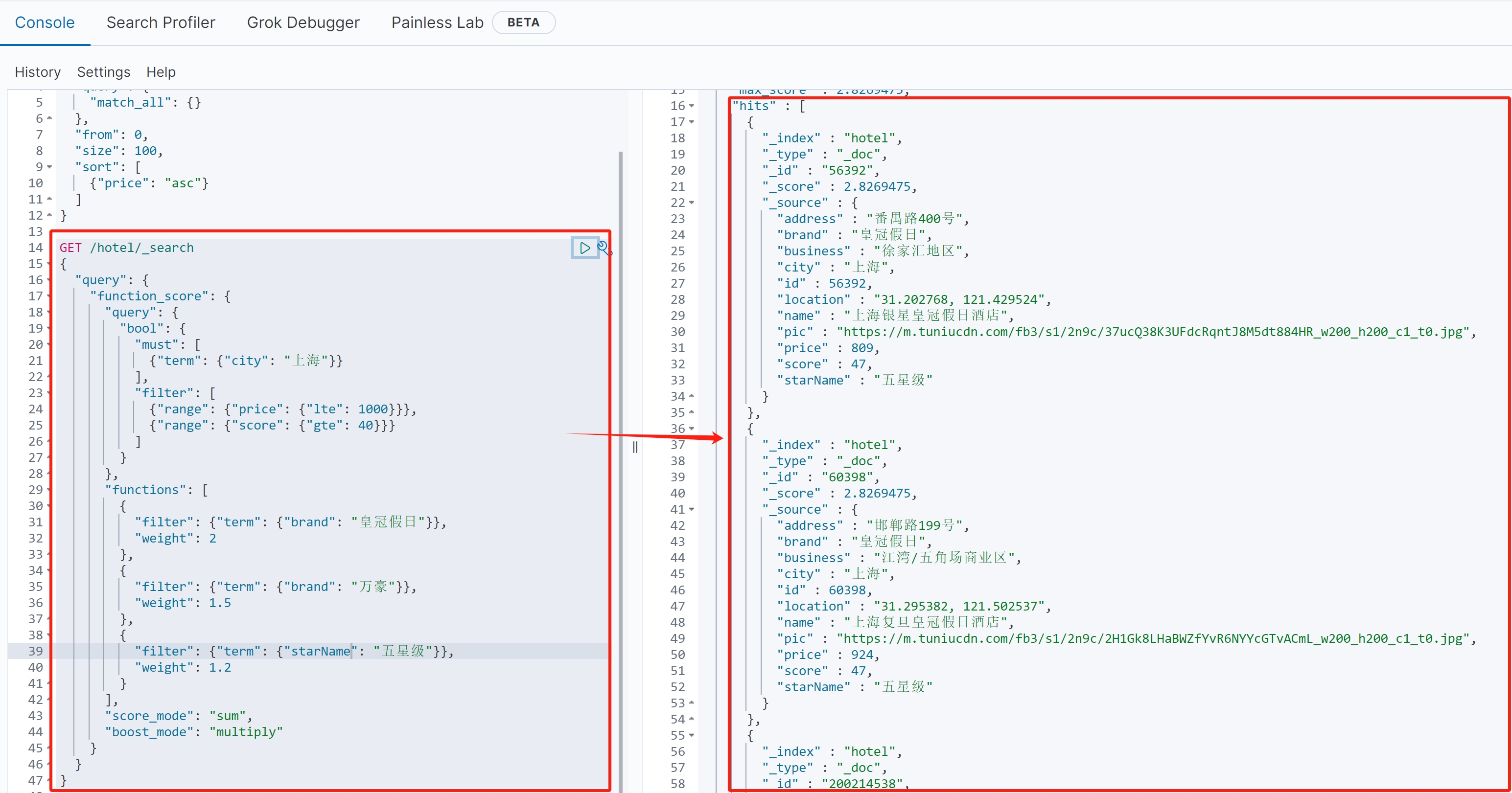
示例2:综合排序(地理位置+评分+价格)
(1)查询语法
{ \"query\": { \"function_score\": { \"query\": { \"bool\": { \"must\": [ {\"term\": {\"city\": \"上海\"}} ], \"should\": [ {\"match\": {\"name\": \"国际\"}}, {\"match\": {\"business\": \"金融\"}} ], \"minimum_should_match\": 1 } }, \"functions\": [ { \"gauss\": { \"location\": { \"origin\": \"31.235152,121.506082\", \"scale\": \"5km\", \"offset\": \"1km\", \"decay\": 0.5 } } }, { \"field_value_factor\": { \"field\": \"score\", \"factor\": 0.2, \"modifier\": \"sqrt\" } }, { \"field_value_factor\": { \"field\": \"price\", \"factor\": 0.005, \"modifier\": \"reciprocal\" } } ], \"score_mode\": \"sum\", \"boost_mode\": \"multiply\" } }}(2)语句作用
查找上海地区的酒店,优先包含\"国际\"名称或位于金融商圈的酒店,并综合考虑地理位置、评分和价格进行排序。
(3)详细解释
●基础查询:
必须满足:城市=上海
应该满足:名称包含\"国际\"或商圈包含\"金融\"(至少满足一个)
●评分函数:
地理位置衰减:距离陆家嘴1公里内不衰减,5公里外显著衰减
评分加权:评分越高加分越多(使用平方根平滑)
价格加权:价格越高减分越多(使用倒数函数)
●\"score_mode\": \"sum\":多个函数评分相加
●\"boost_mode\": \"multiply\":加权结果与原始评分相乘
●效果:符合条件的皇冠假日五星级酒店得分=原始_score × 2 × 1.2
(4)查询结果

示例3:随机排序+业务加权
(1)查询语法
{ \"query\": { \"function_score\": { \"query\": { \"bool\": { \"must\": [ {\"term\": {\"city\": \"北京\"}} ], \"should\": [ {\"term\": {\"brand\": \"希尔顿\"}}, {\"term\": {\"brand\": \"万豪\"}}, {\"term\": {\"starName\": \"五钻\"}} ], \"minimum_should_match\": 1 } }, \"functions\": [ { \"random_score\": { \"seed\": \"用户ID或会话ID\", \"field\": \"_seq_no\" } }, { \"filter\": {\"term\": {\"brand\": \"皇冠假日\"}}, \"weight\": 1.5 }, { \"filter\": {\"range\": {\"score\": {\"gte\": 45}}}, \"weight\": 1.2 } ], \"score_mode\": \"sum\", \"boost_mode\": \"multiply\", \"max_boost\": 3 } }}(2)语句作用
为北京地区的酒店生成个性化推荐,在保证一定随机性的同时,优先推荐特定品牌和高评分酒店。
(3)详细解释
●基础查询:
必须满足:城市=北京
应该满足:希尔顿/万豪品牌或五钻评级(至少满足一个)
●随机排序:
\"random_score\":基于用户ID或会话ID生成可复现的随机排序
保证不同用户看到不同顺序,但同一用户多次访问顺序一致
●业务加权:
皇冠假日品牌:权重1.5
评分≥45:权重1.2
\"max_boost\": 3:限制最大加权倍数不超过3
●组合方式:
随机分数与业务加权相加后,再与原始评分相乘
最终效果:在随机基础上,优质酒店仍有更高曝光率
(4)查询结果
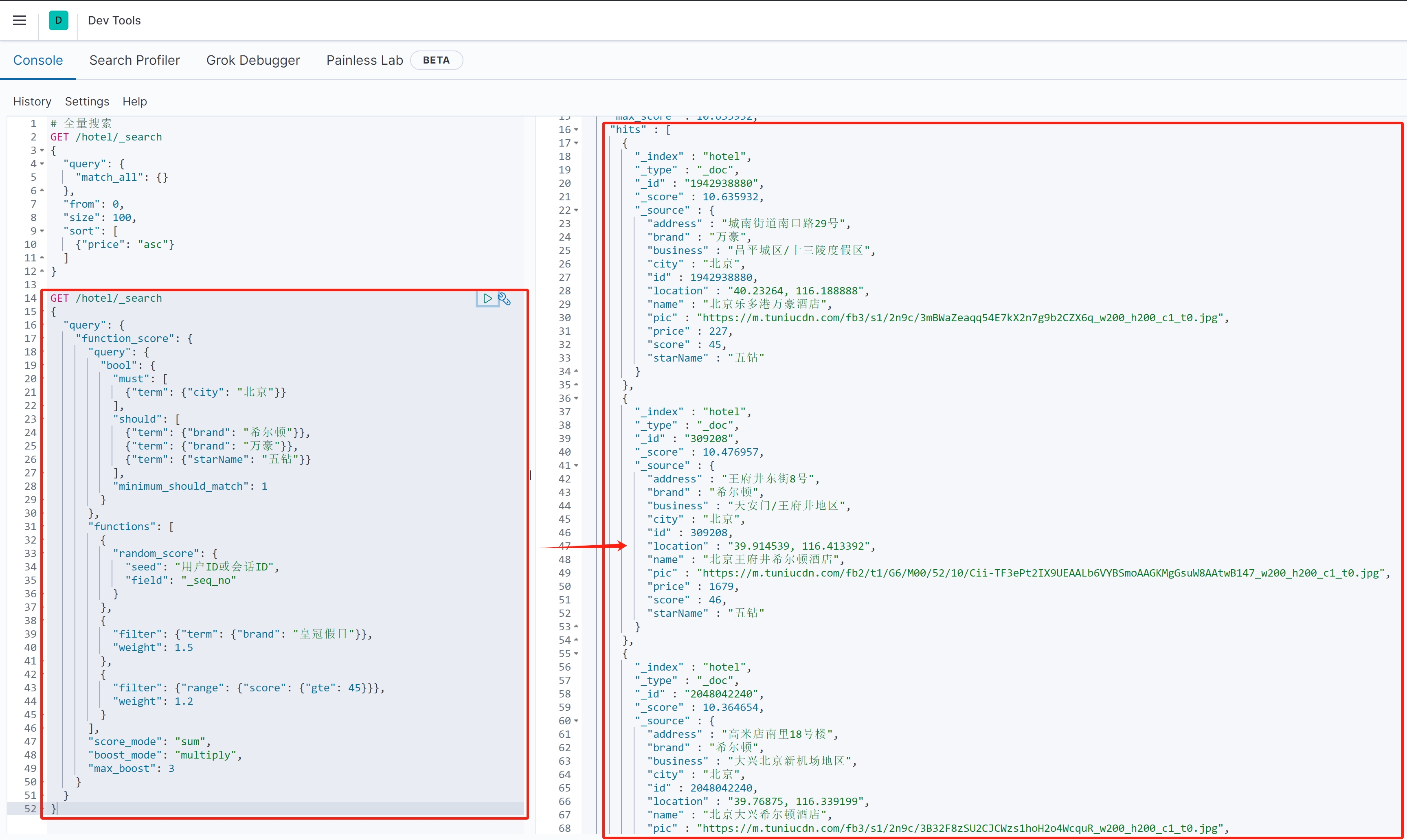
以上就是ElasticSearch的复合查询,以及“相关性算分”、“FunctionScoreQuery”和“BooleanQuery”的全部内容介绍。下一篇我们来学习ElasticSearch的DSL搜索结果处理(排序、分页及高亮)。
转载请注明出处:https://blog.csdn.net/acmman/article/details/148818587


