记录某大型风控系统调研中踩坑
最近在调研某大型风控系统,主要用于承接原有代码(在无原始技术支持情况下),本文主要记录我的调查过程和其中踩到的一些坑:
后端编译阶段
建了nexus的镜像:
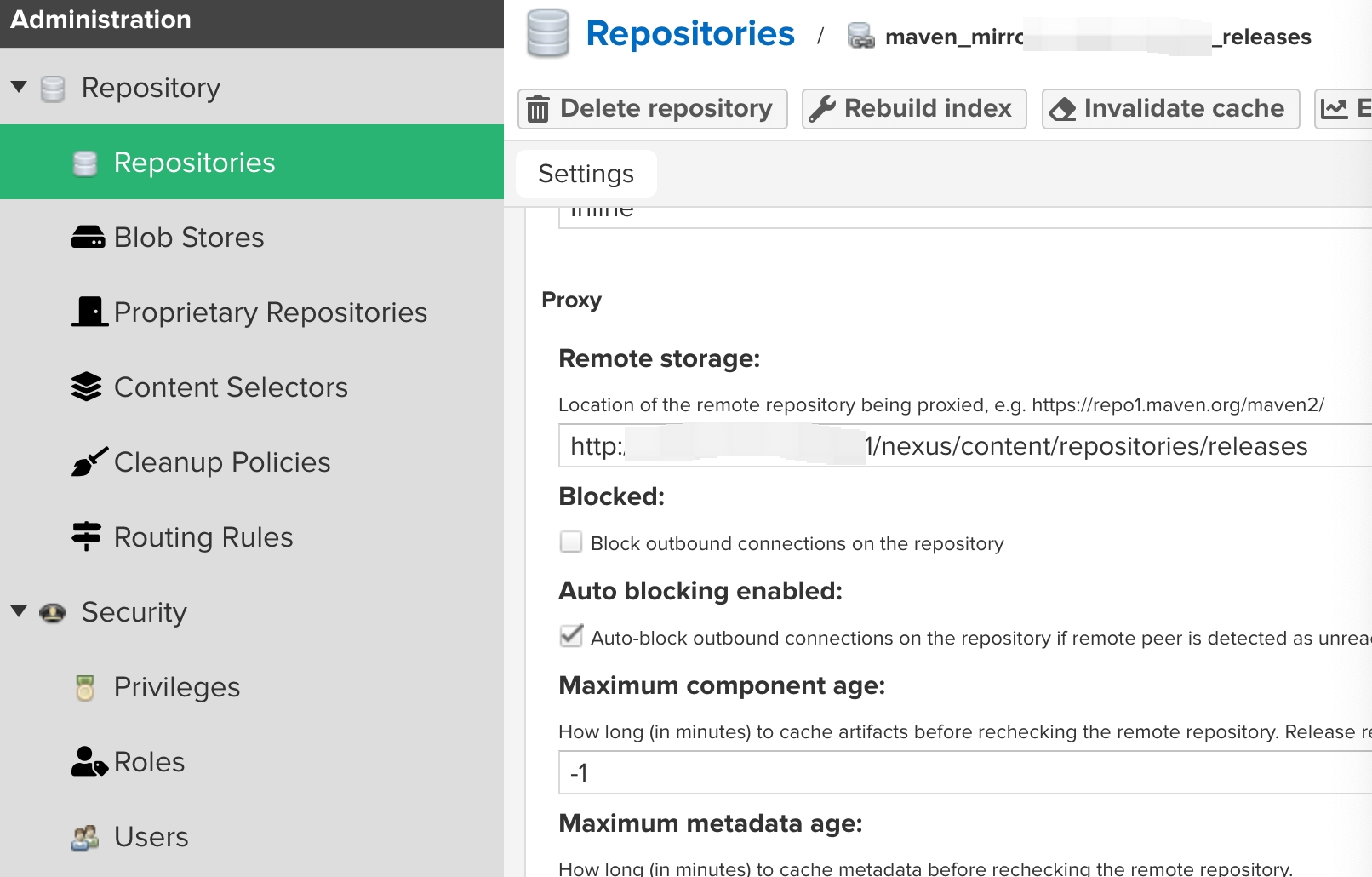
允许http的maven repo
在settings.xml中:
allow-http true http 查看maven依赖
执行命令:mvn dependency:tree 或者在idea的:设置按钮旁边的maven analyzer:
数据库逻辑梳理
mysql依赖相关和特殊设置
1,mysql uuid 和 replace一起使用时会生成一样的UUID问题
参考:stackoverflow
在 MySQL 5.6.46, 5.7.28, nor 8.0.18修复该问题。最好采用对应小版本的最新版。
该问题在老版本会生成相同的UUID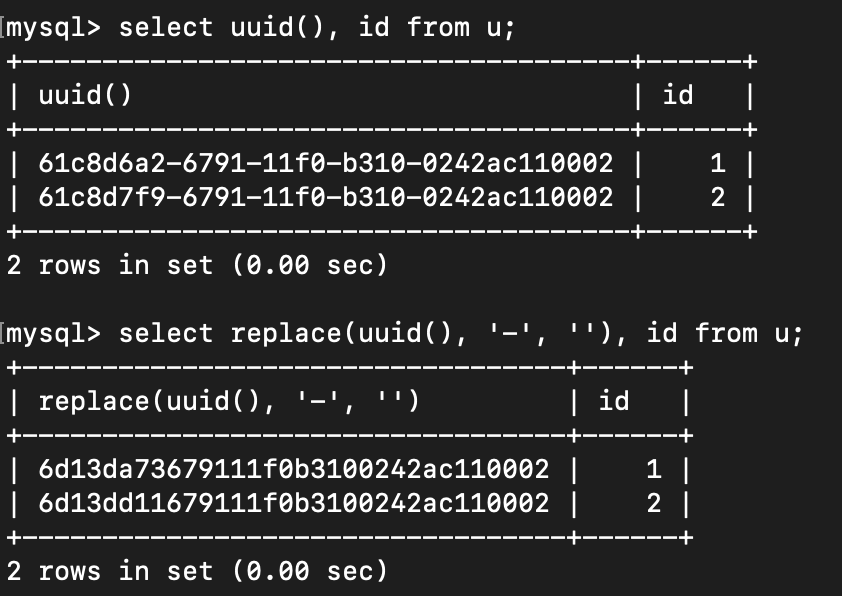
2, 支持授信的不安全的binlog函数:
接受不具有确定性的存储过程方法。
log_bin_trust_function_creators=1比如某个存储过程是对所有的表的id字段生成值:
CREATE DEFINER = userNameXXX@`%` FUNCTION currval(seq_name varchar(50)) RETURNS bigintBEGIN DECLARE VALUE BIGINT; SELECT current_value INTO VALUE FROM sequence WHERE UPPER(NAME) = UPPER(seq_name); -- 大小写不区分. RETURN VALUE;END;3, group concat 超长的问题:
GROUP_CONCAT函数使用时对字符串长度有要求,默认为1024。
group_concat_max_len = 10M4, 动态联邦查询,类似redshift dblink
注:mysql8已经移除,
create table xxx (id int,name varchar) engine = FEDERATED CONNECTION = \'mysql://user:passwd@ip:3306/db1/table1\';mysql8推荐使用(1)dblink扩展 手动安装。 (2)联邦server方式。
联邦server方式:
-- 1. 创建联合服务器CREATE SERVER remote_serverFOREIGN DATA WRAPPER mysqlOPTIONS ( HOST \'remote_host\', DATABASE \'remote_db\', USER \'user\', PASSWORD \'password\', PORT 3306);-- 2. 创建联合表CREATE TABLE federated_table ( id INT, name VARCHAR(50)) ENGINE=FEDERATEDCONNECTION=\'remote_server/remote_table\';-- 3. 直接查询SELECT * FROM local_tableJOIN federated_table ON local_table.id = federated_table.id;5, full group by 问题
如果mysql里面出现了select col1, col2 from t group by col1 没有在groupby的字段会报错,需要修改:
SELECT @@sql_mode;或者select @@GLOBAL.sql_mode;查询出来的值,移除掉:ONLY_FULL_GROUP_BY
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION后端运行阶段
1,mybatis日志过多:
mybatis-plus: #本地调用时启用,远程调用时注释# config-location: classpath:mybatis/mybatis-config.xml mapper-locations: - classpath*:mybatis/${spring.datasource.dialect}/**/*Mapper.xml - classpath*:mybatis/*Mapper.xml configuration: log-impl: ${MYBATIS_LOG_IMPL:com.starter.v1.StdOutImplNoResultLogging} plugins: - xxx.IdMybatisPlugin之前的org.apache.ibatis.logging.stdout.StdOutImpl会打印每行返回的数据,在行数返回很多时会消耗很大的io性能, 如下的类 不打印原始行,其他保持不变:
import org.apache.ibatis.logging.stdout.*;/** * dont log the sql each returning row. it\'s too time-consuming */public class StdOutImplNoResultLogging extends StdOutImpl { private static String NO_LOG_CONTENT = \"<== Row:\"; public StdOutImplNoResultLogging(String clazz) { super(clazz); } @Override public void debug(String s) { if (s != null && s.contains(NO_LOG_CONTENT)) { return; } else { super.debug(s); } } @Override public void trace(String s) { if (s != null && s.contains(NO_LOG_CONTENT)) { return; } else { super.trace(s); } }}2, mybatis id 自定义生成插件
参考上面的yaml配置id plugins。
import org.apache.ibatis.executor.Executor;import org.apache.ibatis.mapping.MappedStatement;import org.apache.ibatis.mapping.SqlCommandType;import org.apache.ibatis.plugin.*;import org.springframework.stereotype.Component;import java.lang.reflect.Field;import java.util.Properties;import java.util.UUID;@Intercepts({ @Signature( type = Executor.class, method = \"update\", args = {MappedStatement.class, Object.class} )})@Componentpublic class CustomIdGeneratorInterceptor implements Interceptor { // 需要生成ID的字段名 private String idFieldName = \"id\"; // ID生成策略 private IdGeneratorType idGenerator = IdGeneratorType.UUID; @Override public Object intercept(Invocation invocation) throws Throwable { // 获取当前执行的MappedStatement和参数对象 Object[] args = invocation.getArgs(); MappedStatement ms = (MappedStatement) args[0]; Object parameter = args[1]; // 只处理INSERT操作 if (SqlCommandType.INSERT != ms.getSqlCommandType()) { return invocation.proceed(); } // 处理参数对象(可能是单个对象或Map) if (parameter != null) { // 处理单个实体对象 if (!isCollectionType(parameter.getClass())) { setIdValue(parameter); } // 处理集合类型(List等) else if (parameter instanceof Iterable) { for (Object item : (Iterable<?>) parameter) { setIdValue(item); } } } return invocation.proceed(); } // 设置ID值 private void setIdValue(Object target) throws IllegalAccessException { if (target == null) return; try { // 获取目标字段 Field idField = findIdField(target.getClass()); if (idField == null) return; // 确保字段可访问 idField.setAccessible(true); // 检查字段是否已有值 Object currentValue = idField.get(target); if (currentValue != null) return; // 生成新ID并设置 Object newId = generateId(); idField.set(target, newId); } catch (NoSuchFieldException e) { // 目标类没有ID字段,忽略 } } // 查找ID字段 private Field findIdField(Class<?> clazz) throws NoSuchFieldException { try { return clazz.getDeclaredField(idFieldName); } catch (NoSuchFieldException e) { // 尝试在父类中查找 Class<?> superClass = clazz.getSuperclass(); if (superClass != null && !superClass.equals(Object.class)) { return findIdField(superClass); } throw e; } } // 生成ID private Object generateId() { switch (idGenerator) { case UUID: return UUID.randomUUID().toString().replace(\"-\", \"\"); case SNOWFLAKE: return SnowflakeIdGenerator.nextId(); case NANO_TIME: return System.nanoTime(); default: throw new IllegalArgumentException(\"未知的ID生成策略\"); } } // 判断是否为集合类型 private boolean isCollectionType(Class<?> clazz) { return Iterable.class.isAssignableFrom(clazz); } @Override public Object plugin(Object target) { return Plugin.wrap(target, this); } @Override public void setProperties(Properties properties) { // 从配置读取自定义属性 if (properties.containsKey(\"idFieldName\")) { this.idFieldName = properties.getProperty(\"idFieldName\"); } if (properties.containsKey(\"idGenerator\")) { this.idGenerator = IdGeneratorType.valueOf( properties.getProperty(\"idGenerator\").toUpperCase() ); } } // ID生成策略枚举 public enum IdGeneratorType { UUID, // UUID策略 SNOWFLAKE, // 雪花算法 NANO_TIME // 纳秒时间戳 } // 雪花ID生成器 private static class SnowflakeIdGenerator { }经验部分
1,先看大局,再看细节。 整体应该按照:需求 -》 概要 -》详细/数据设计-》运行的过程。
2,文档和实际可能有一定出入。
3,软件版本的选择可能是有刻意的。 比如 上文提到的uuid生成同样值的问题。和联邦表的问题。
4,备份/恢复数据库必须要演练。最开始用的xtrabackup实际上就没能正常恢复。
5,point time recovery for mysql 这个有时候很有重要。 改天写篇文章来风险风险。

