Python实现剪映草稿_剪映api
首先,剪映官网并没有提供相应的API和SDK等解决方案,于是乎去找有没有对应的开源项目,找过csdn、gitee、github等平台,最终在gitee上找到了自己想要的解决方案:剪映草稿生成: 一个把数据保存到剪映草稿的小插件
在github上也有相关的解决方案,但是没有添加字幕,这个作者对代码进行了重写,实现了添加字幕的功能,博主本人主要是写Java代码的,本来想看看有没有对应的Java解决方案,但是找遍了全网都没有,看来只能通过Java去调用Python的接口去实现这个功能了,所以针对这个源码需要改写
如何把项目跑起来
下载完源码之后会看到一个 pyproject.toml 文件
[tool.poetry]name = \"JianYingDraft.PY\"version = \"1.0.3\"description = \"帮助剪映快速生成草稿的方案\"authors = [\"聂长安 \"]readme = \"README.md\"packages = [{ include = \"JianYingDraft\" }]include = [\"README.md\", \"LICENSE\"]license = \"MIT\"[tool.poetry.dependencies]python = \"^3.12\"pymediainfo = \"^6.1.0\"basiclibrary-py = \"^0.6.10\"pytest = \"^8.1.1\"[tool.poetry.group.dev.dependencies]pytest = \"^8.1.1\"pylint = \"^3.1.0\"[build-system]requires = [\"poetry-core\"]build-backend = \"poetry.core.masonry.api\"虽然我不知道这个文件是啥,但是我看着有点类似Java的项目的pom.xml文件或者Vue前端的package.json文件,这里是用来管理依赖包版本的,所以这个包肯定有用,顺着这个思路去百度,找到了这样的一段话
越来越多的依赖管理工具开始倾向于使用pyproject.toml。例如poetry,它会把项目依赖信息写在此文件中,取代传统的requirements.txt,让依赖管理更加规范统一看来这个依赖管理工具可能是poetry,于是乎去查询poetry如何使用的,命令如下:
pip install poetrypoetry install执行完这个之后发现缺少BasicLibrary,继续安装
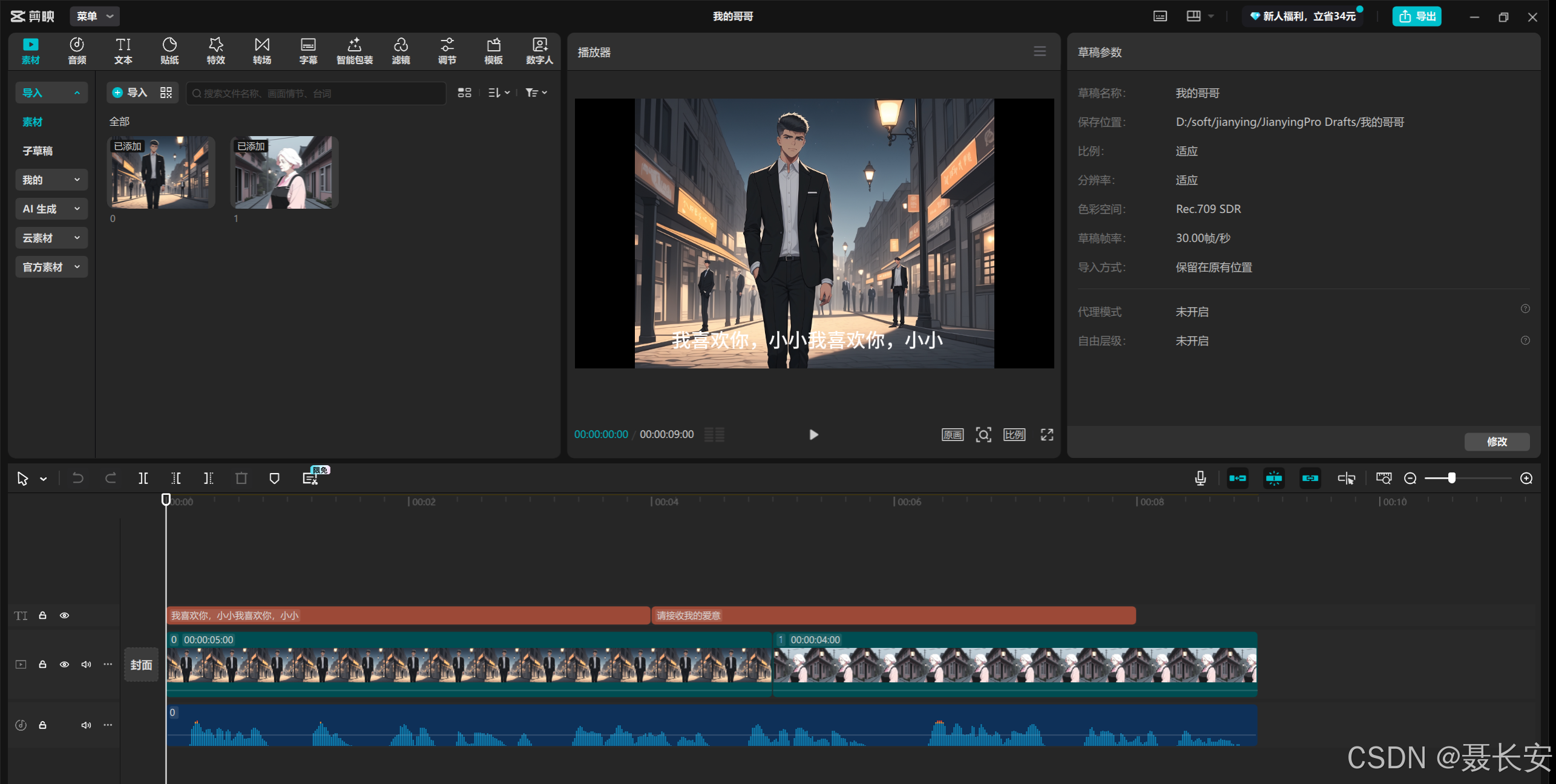
pip install BasicLibrary==1.2.6pip install BasicLibrary.PY==0.6.43pip install pymediainfo==6.1.0反正缺少什么安装什么就行了,直到项目不报错能跑起来就算解决了,启动之前记得配置_projectConfig.ini文件,主要配置的是你剪映的草稿位置,然后执行main.py就会生成两个json文件,这样你去剪映草稿打开就可以进行编辑了,效果如下
改造
因为自己是以Python接口的方式提供给Java那边去调用,所以需要引入Flask,直接贴代码,有问题后面再私聊
import osimport shutilimport zipfilefrom flask import Flask, jsonify, request, send_filefrom JianYingDraft.core.draft import Draftfrom projectHelper import ProjectHelperapp = Flask(__name__)def estimate_reading_time(text, speed_multiplier=1.0, words_per_minute=275): num_characters = len(text) estimated_time_seconds = (num_characters / words_per_minute) * 60 / speed_multiplier return estimated_time_secondsdef zip_folder(folder_path, zip_path): \"\"\"将指定文件夹打包为 ZIP 文件\"\"\" with zipfile.ZipFile(zip_path, \'w\', zipfile.ZIP_DEFLATED) as zipf: for root, dirs, files in os.walk(folder_path): for file in files: file_path = os.path.join(root, file) arcname = os.path.relpath(file_path, folder_path) zipf.write(file_path, arcname)@app.route(\'/basic_using\', methods=[\'POST\'])def basic_using_api(): try: data = request.get_json() story_name = data.get(\'storyName\') base_path = data.get(\'basePath\') real_path = data.get(\'realPath\') jian_ying_path = data.get(\'jianYingPath\') jian_ying_path = jian_ying_path.replace(\"\\\\\", \"\\\\\\\\\") # 验证参数 if not base_path.endswith(\'material\'): raise ValueError(\'资源文件夹必须以 \"material\" 结尾\') if not os.path.exists(base_path): raise FileNotFoundError(\'指定的资源文件夹不存在\') # 获取 material 的上级目录(即“重生的复仇”目录) parent_path = os.path.dirname(base_path) # 确保 material 文件夹不会被修改:复制草稿保存路径到临时路径 draft_temp_folder = os.path.join(parent_path, \"draft_temp\") os.makedirs(draft_temp_folder, exist_ok=True) # 初始化草稿对象 draft = Draft(jian_ying_path, story_name) # 收集图片和文本文件 image_files = [] text_files = [] all_files = sorted(os.listdir(base_path), key=lambda x: int(os.path.splitext(x)[0])) for filename in all_files: file_path = os.path.join(base_path, filename) if os.path.isfile(file_path): if filename.endswith((\'.jpg\', \'.png\')): image_files.append(file_path) elif filename.endswith(\'.txt\'): text_files.append(file_path) # 将图片和字幕添加到草稿中 for img_path, txt_path in zip(image_files, text_files): with open(txt_path, \'r\', encoding=\'utf-8\') as f: text = f.read() duration = estimate_reading_time(text) * 1000000 draft.add_media(img_path, duration=duration) draft.add_subtitle(text, duration=duration, color=\"#550000\") # 设置草稿保存路径为临时路径 draft._draft_folder = draft_temp_folder draft.save() # 将生成的草稿文件移动到“重生的复仇”目录 for file_name in os.listdir(draft_temp_folder): file_path = os.path.join(draft_temp_folder, file_name) if os.path.isfile(file_path): with open(file_path, \'r\', encoding=\'utf-8\') as f: content = f.read() updated_content = content.replace(r\"/opt/app/chatgpt/JianYingDraft-master/chaonao\", jian_ying_path) with open(file_path, \'w\', encoding=\'utf-8\') as f: f.write(updated_content) shutil.move(os.path.join(draft_temp_folder, file_name), os.path.join(parent_path, file_name)) # 删除临时目录 shutil.rmtree(draft_temp_folder) # 打包文件夹为 ZIP 文件 zip_file_path = os.path.join(parent_path, f\"{story_name}.zip\") zip_folder(parent_path, zip_file_path) # 返回下载链接 return send_file(zip_file_path, as_attachment=True) except Exception as e: return jsonify({\"error\": str(e)}), 500if __name__ == \'__main__\': app.run(debug=True, host=\'0.0.0.0\', port=7158)Java调用方的代码:
@Override public void getJianYingDraft(String storyId, String jianYingPath, HttpServletResponse res) { try { jianYingPath = URLDecoder.decode(jianYingPath, StandardCharsets.UTF_8.name()); } catch (UnsupportedEncodingException e) { throw new RuntimeException(e); } String BaseURL = \"/opt/app/chatgpt/JianYingDraft-master/chaonao\"; ChatStory chatStory = chatStoryService.getById(storyId); String storyName = chatStory.getStoryName(); // 1. 创建故事名称的文件夹,地址为 BaseURL\\\\storyName\\\\material File storyFolder = new File(BaseURL + File.separator + storyName + File.separator + \"material\"); if (!storyFolder.exists()) { storyFolder.mkdirs(); } // 2. 下载图片和字幕文件到 material 文件夹 List<JianYingDraftVO> jianYingDraftVOList = baseMapper.getJianYingDraftList(storyId); for (int i = 0; i < jianYingDraftVOList.size(); i++) { JianYingDraftVO draftVO = jianYingDraftVOList.get(i); if (draftVO != null) { try { // 下载图片 if (org.springframework.util.StringUtils.hasText(draftVO.getImageUrl())) { URL imageUrl = new URL(draftVO.getImageUrl()); String imageFileName = i + \".\" + getFileExtension(draftVO.getImageUrl()); FileUtils.copyURLToFile(imageUrl, new File(storyFolder + File.separator + imageFileName)); } // 创建字幕文件 if (org.springframework.util.StringUtils.hasText(draftVO.getContent())) { File subtitleFile = new File(storyFolder + File.separator + i + \".txt\"); FileUtils.writeStringToFile(subtitleFile, draftVO.getContent(), \"UTF-8\"); } } catch (IOException e) { log.error(\"Error downloading material: \" + e.getMessage()); } } } // 3. 调用 Python 接口 Map<String, Object> requestBody = new HashMap<>(); requestBody.put(\"storyName\", storyName); requestBody.put(\"basePath\", storyFolder.getAbsolutePath()); requestBody.put(\"realPath\", BaseURL); requestBody.put(\"jianYingPath\", jianYingPath); OkHttpClient client = OkHttpUtils.okHttpClient; okhttp3.RequestBody body = okhttp3.RequestBody .create(okhttp3.MediaType.parse(\"application/json; charset=utf-8\"), JSON.toJSONString(requestBody)); Request request = new Request.Builder() .url(\"http://xxx.xxx.xxx.xxx:7158/basic_using\") .post(body) .addHeader(\"content-type\", \"application/json\") .build(); try (Response response = client.newCall(request).execute()) { if (response.code() == 200 && response.body() != null) { // 获取返回的 ZIP 文件流 InputStream inputStream = response.body().byteStream(); // 定义下载文件的路径 String zipFilePath = BaseURL + File.separator + storyName + \".zip\"; File zipFile = new File(zipFilePath); // 保存 ZIP 文件到指定路径 try (FileOutputStream outputStream = new FileOutputStream(zipFile)) { byte[] buffer = new byte[1024]; int bytesRead; while ((bytesRead = inputStream.read(buffer)) != -1) { outputStream.write(buffer, 0, bytesRead); } } // 设置 HTTP 响应,返回 ZIP 文件 res.setContentType(\"application/zip\"); res.setHeader(\"Content-Disposition\", \"attachment; filename=\" + storyName + \".zip\"); try (InputStream fileInputStream = new FileInputStream(zipFile)) { org.apache.commons.io.IOUtils.copy(fileInputStream, res.getOutputStream()); res.flushBuffer(); } } else { log.error(\"Error calling basic_using API: \" + response.message()); } } catch (IOException e) { log.error(\"Error calling Python API: \" + e.getMessage()); } }这样就完成了草稿导出的功能,浏览器直接会下载一个zip文件,导入到剪映草稿就可以使用了,中间其实还是有很多细节的,也花了不少时间,不过都在代码中体现了,注释也写好了


