Java-81 深入浅出 MySQL发展全景:从单机架构到云数据库演进实录
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月21日更新到:
Java-77 深入浅出 RPC Dubbo 负载均衡全解析:策略、配置与自定义实现实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
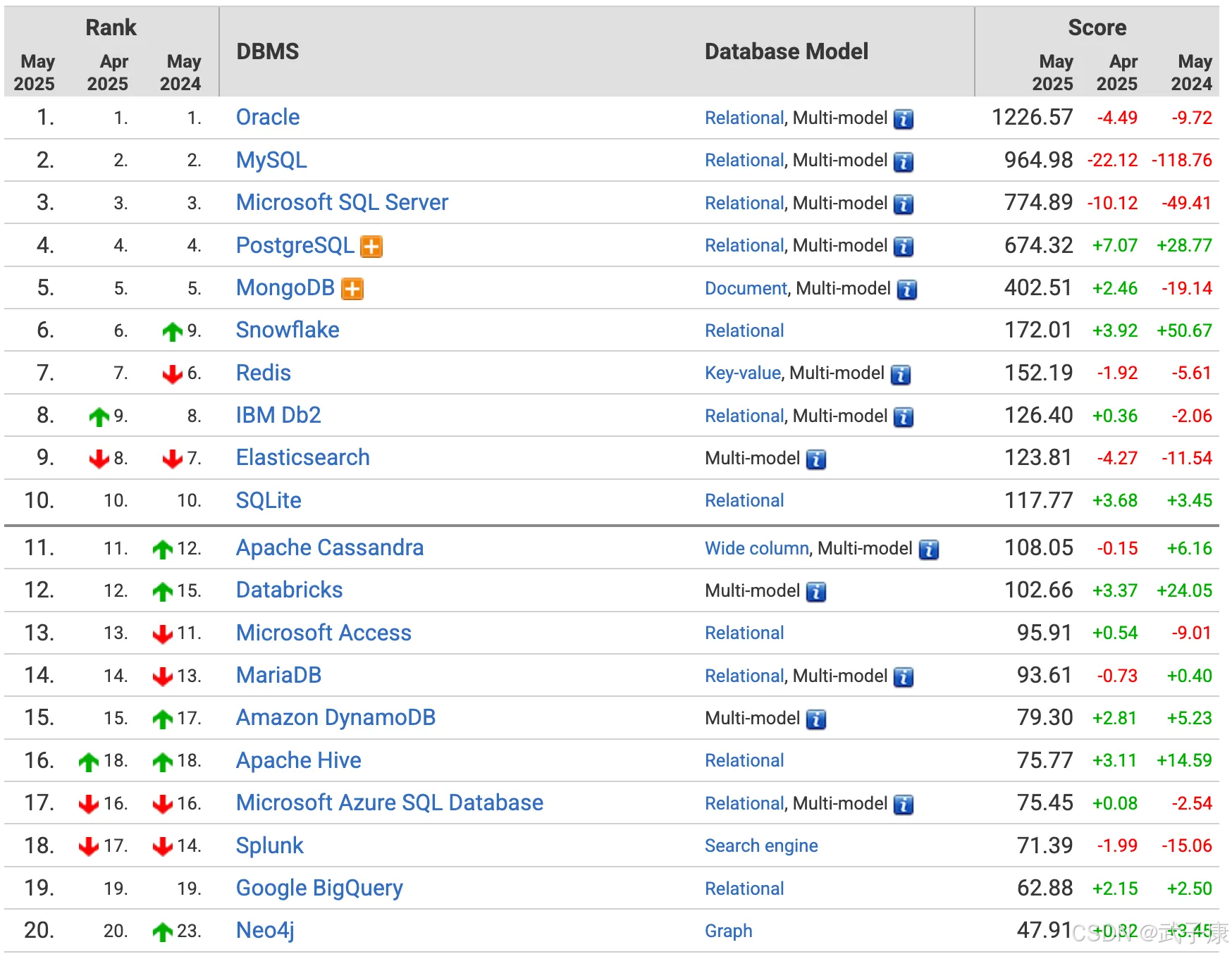
排行榜
https://db-engines.com/en/ranking
发展历程
MySQL 是最流行的关系型数据库之一,由于其体积小、速度快、开源免费、简单易用、维护成本低等等,在集群架构中易于扩展、高可用。
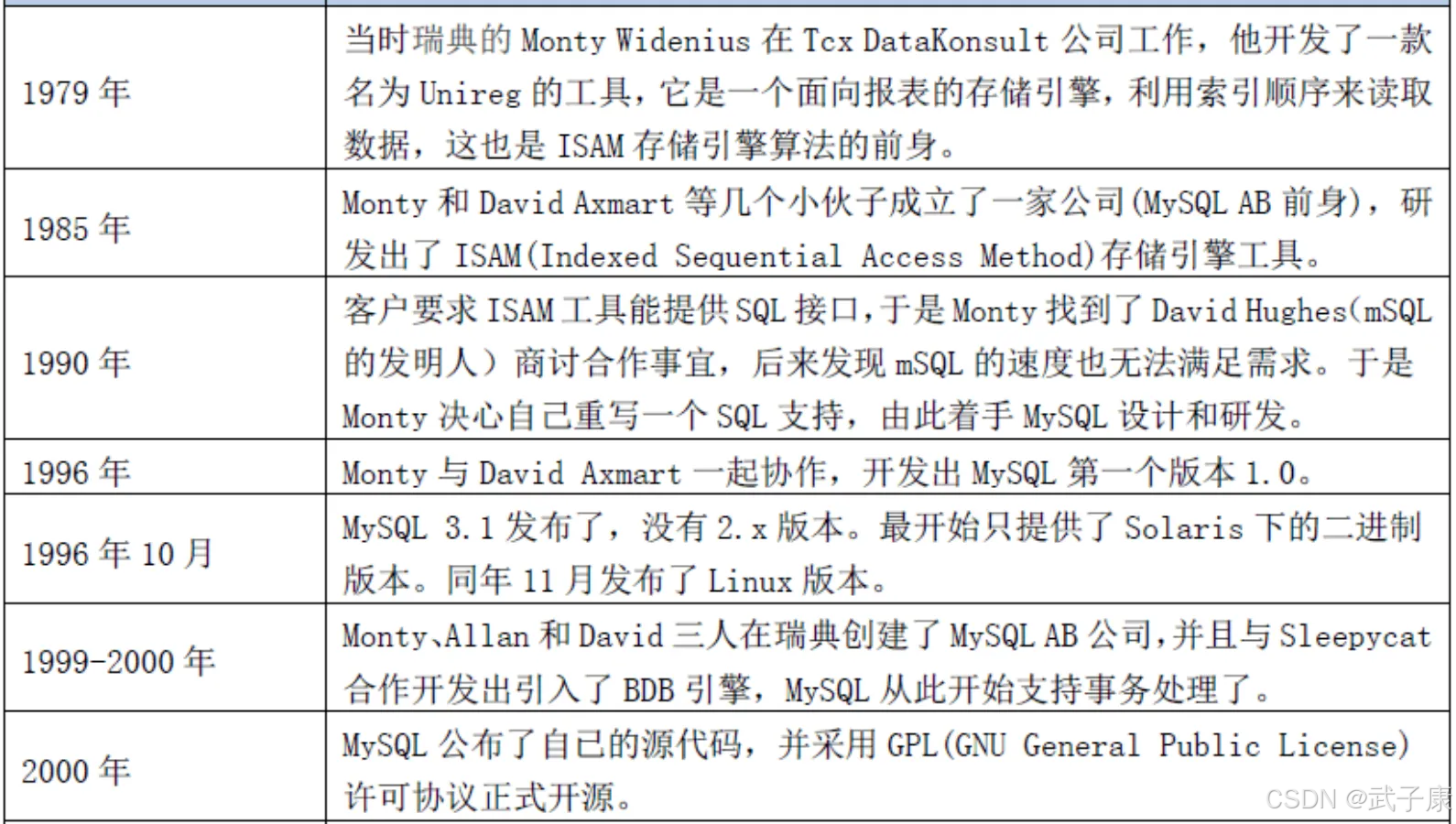
主流分支
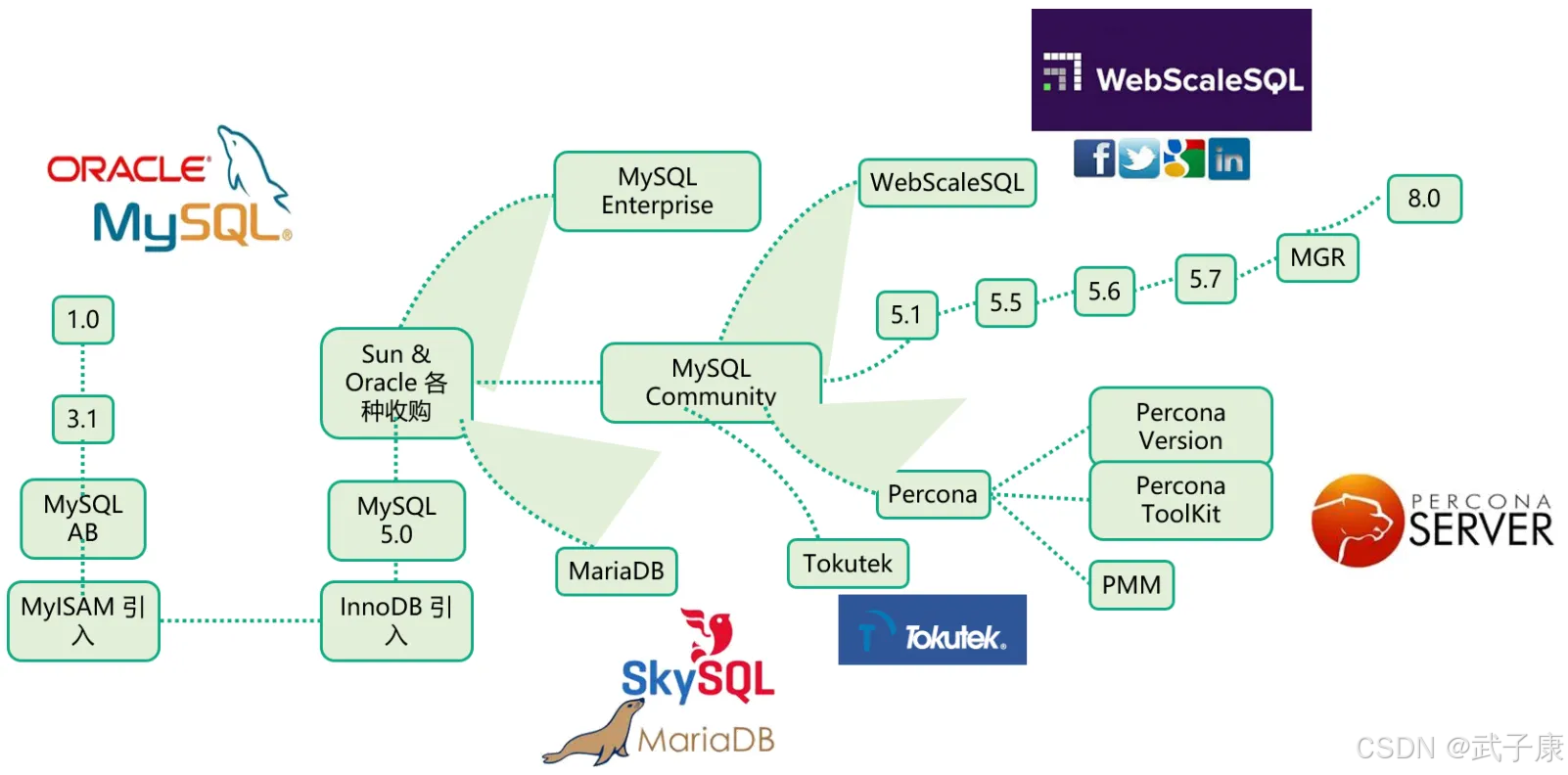
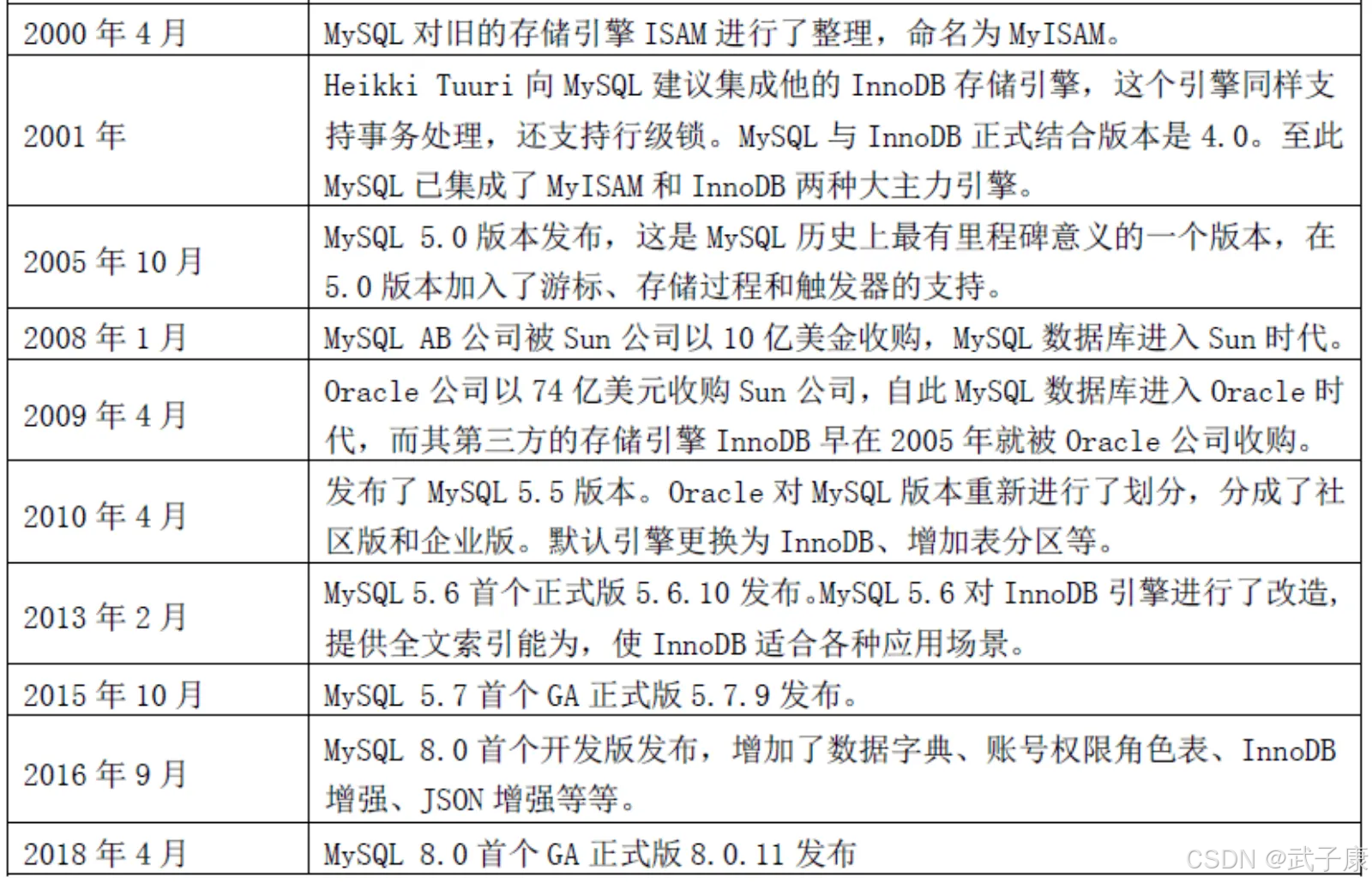
从 MySQL 最初的 1.0 版本(1995年发布)到 3.1 版本(1998年发布),再到如今的 8.0 系列(2018年发布),MySQL 经历了多次重大架构变革和功能升级。2008年 Sun Microsystems 收购 MySQL AB 后,又在 2010 年随 Sun 一起被 Oracle 收购,这直接导致了 MySQL 社区的分裂和多个分支版本的诞生。
在 Oracle 的商业化运营下,MySQL 分化为以下几个主要方向:
- 官方商业版 MySQL Enterprise Edition(需要付费订阅)
- 官方社区版 MySQL Community Edition(GPL 协议)
- 云服务版本 MySQL HeatWave(Oracle 云服务)
在众多社区分支中,最著名的两个是:
- Percona Server:
这个由 Percona 公司维护的分支基于官方 MySQL 代码进行了深度优化,特别针对以下方面:
- 性能优化(如改进的查询优化器)
- 稳定性增强(关键补丁提前集成)
- 专用监控工具(如 Percona Monitoring and Management)
- 特有的 XtraBackup 备份工具
典型应用场景包括高并发的电商平台和需要实时分析的大型网站。
- MariaDB:
由 MySQL 创始人 Michael “Monty” Widenius 在 2009 年创建,主要特性包括:
- 完全兼容 MySQL 协议和 API
- 采用 Aria 存储引擎作为默认引擎(后改为 InnoDB)
- 包含更多存储引擎选项(如 ColumnStore)
- 更开放的开发模式
目前已被多个 Linux 发行版(如 RHEL、Debian)选为默认数据库,并在 Wikimedia Foundation 等知名机构中广泛使用。
这些分支虽然同源,但在功能特性和发展重点上已逐渐分化,用户可以根据实际需求在性能、成本、功能等方面进行权衡选择。从 MySQL 最初的 1.0 版本(1995年发布)到 3.1 版本(1998年发布),再到如今的 8.0 系列(2018年发布),MySQL 经历了多次重大架构变革和功能升级。2008年 Sun Microsystems 收购 MySQL AB 后,又在 2010 年随 Sun 一起被 Oracle 收购,这直接导致了 MySQL 社区的分裂和多个分支版本的诞生。
在 Oracle 的商业化运营下,MySQL 分化为以下几个主要方向:
- 官方商业版 MySQL Enterprise Edition(需要付费订阅)
- 官方社区版 MySQL Community Edition(GPL 协议)
- 云服务版本 MySQL HeatWave(Oracle 云服务)
在众多社区分支中,最著名的两个是:
- Percona Server:
这个由 Percona 公司维护的分支基于官方 MySQL 代码进行了深度优化,特别针对以下方面:
- 性能优化(如改进的查询优化器)
- 稳定性增强(关键补丁提前集成)
- 专用监控工具(如 Percona Monitoring and Management)
- 特有的 XtraBackup 备份工具
典型应用场景包括高并发的电商平台和需要实时分析的大型网站。
- MariaDB:
由 MySQL 创始人 Michael “Monty” Widenius 在 2009 年创建,主要特性包括:
- 完全兼容 MySQL 协议和 API
- 采用 Aria 存储引擎作为默认引擎(后改为 InnoDB)
- 包含更多存储引擎选项(如 ColumnStore)
- 更开放的开发模式
目前已被多个 Linux 发行版(如 RHEL、Debian)选为默认数据库,并在 Wikimedia Foundation 等知名机构中广泛使用。
这些分支虽然同源,但在功能特性和发展重点上已逐渐分化,用户可以根据实际需求在性能、成本、功能等方面进行权衡选择。
架构演变
现代互联网应用的架构通常遵循分层设计模式,请求会经过以下几个关键层级:
请求处理流程
-
用户请求层
- 用户通过浏览器、移动App或API客户端发起HTTP/HTTPS请求
- 典型场景:用户在电商网站点击\"购买\"按钮,或在社交App刷新动态
- 请求可能经过CDN、负载均衡器等基础设施
-
应用层(表现层)
- 处理用户界面展示和请求路由
- 包含Web服务器(Nginx/Apache)、应用服务器(Tomcat/Node.js)
- 示例:渲染HTML页面、处理表单提交、管理用户会话
-
服务层(业务逻辑层)
- 实现核心业务逻辑和数据处理
- 包含微服务、API网关、消息队列等组件
- 典型功能:订单处理、支付流程、推荐算法计算
-
存储层(数据持久层)
- 负责数据的持久化存储和检索
- 包含多种数据库类型:
- 关系型数据库(MySQL/PostgreSQL)
- NoSQL数据库(MongoDB/Redis)
- 大数据存储(HBase/Elasticsearch)
- 示例:用户信息存储、商品库存管理、交易记录保存
扩展说明
在大型分布式系统中,每个层级都可能进一步细分:
- 应用层可能分为前端和后端
- 服务层可能拆分为数十个微服务
- 存储层可能包含读写分离、分库分表等设计
流量高峰期时,每个层级都需要考虑:
- 横向扩展能力
- 请求队列管理
- 熔断降级机制
- 缓存策略优化# 架构演变
现代互联网应用的架构通常遵循分层设计模式,请求会经过以下几个关键层级:
请求处理流程
-
用户请求层
- 用户通过浏览器、移动App或API客户端发起HTTP/HTTPS请求
- 典型场景:用户在电商网站点击\"购买\"按钮,或在社交App刷新动态
- 请求可能经过CDN、负载均衡器等基础设施
-
应用层(表现层)
- 处理用户界面展示和请求路由
- 包含Web服务器(Nginx/Apache)、应用服务器(Tomcat/Node.js)
- 示例:渲染HTML页面、处理表单提交、管理用户会话
-
服务层(业务逻辑层)
- 实现核心业务逻辑和数据处理
- 包含微服务、API网关、消息队列等组件
- 典型功能:订单处理、支付流程、推荐算法计算
-
存储层(数据持久层)
- 负责数据的持久化存储和检索
- 包含多种数据库类型:
- 关系型数据库(MySQL/PostgreSQL)
- NoSQL数据库(MongoDB/Redis)
- 大数据存储(HBase/Elasticsearch)
- 示例:用户信息存储、商品库存管理、交易记录保存
扩展说明
在大型分布式系统中,每个层级都可能进一步细分:
- 应用层可能分为前端和后端
- 服务层可能拆分为数十个微服务
- 存储层可能包含读写分离、分库分表等设计
流量高峰期时,每个层级都需要考虑:
- 横向扩展能力
- 请求队列管理
- 熔断降级机制
- 缓存策略优化
单机单库架构详解
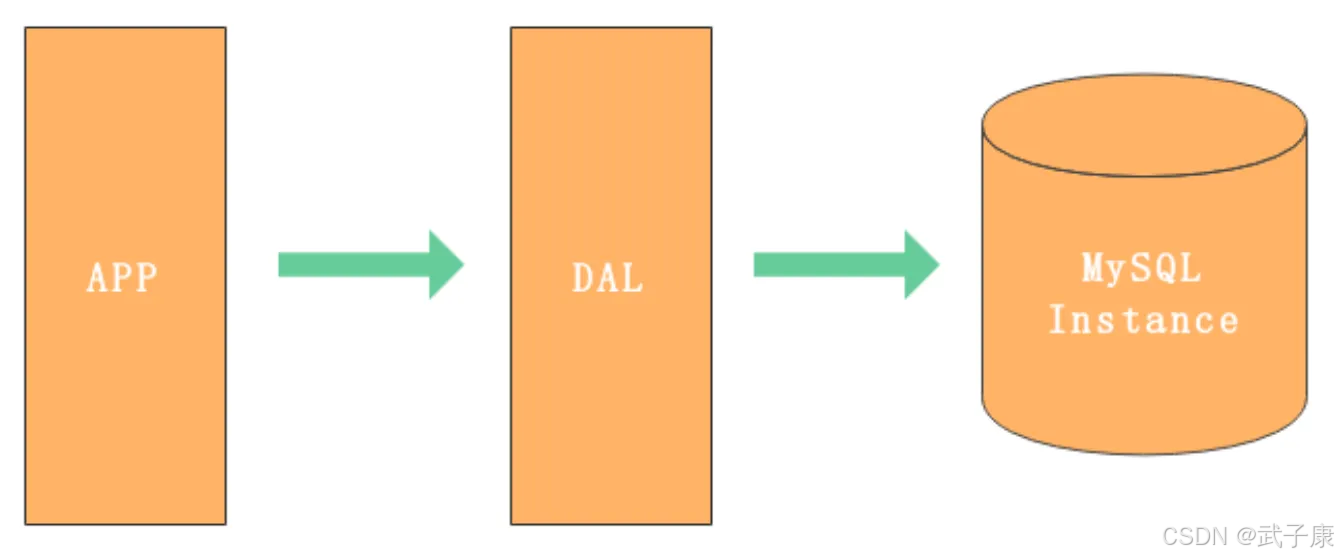
当前的系统是有一定瓶颈的:
● 数据量太大,超出一台服务器的承受范围
● 读写操作量太大,超出一台服务器的承受范围
● 一台服务器挂掉了,导致整个应用都会挂掉
基础架构组成
单机单库是最基础的数据库架构方案,由以下核心组件构成:
- 应用服务器:运行网站或应用程序的业务逻辑
- 数据库服务器:部署单个MySQL实例(Instance)
- 存储设备:用于持久化数据的硬盘存储
典型应用场景
这种架构非常适合以下情况:
- 日均访问量在1万以下的小型网站
- 开发测试环境
- 初创企业的MVP(最小可行产品)阶段
- 个人博客或小型CMS系统
数据存储特点
在这种架构中:
- 所有业务数据表(用户表、订单表、日志表等)都存放在同一个数据库实例中
- 通常采用默认的InnoDB存储引擎
- 数据量一般在100GB以内
- 使用简单的单机备份策略
性能表现
- 可支持每秒约200-500次的读写操作(QPS)
- 响应时间通常在10-100毫秒级别
- 连接数上限取决于MySQL配置,默认约150个
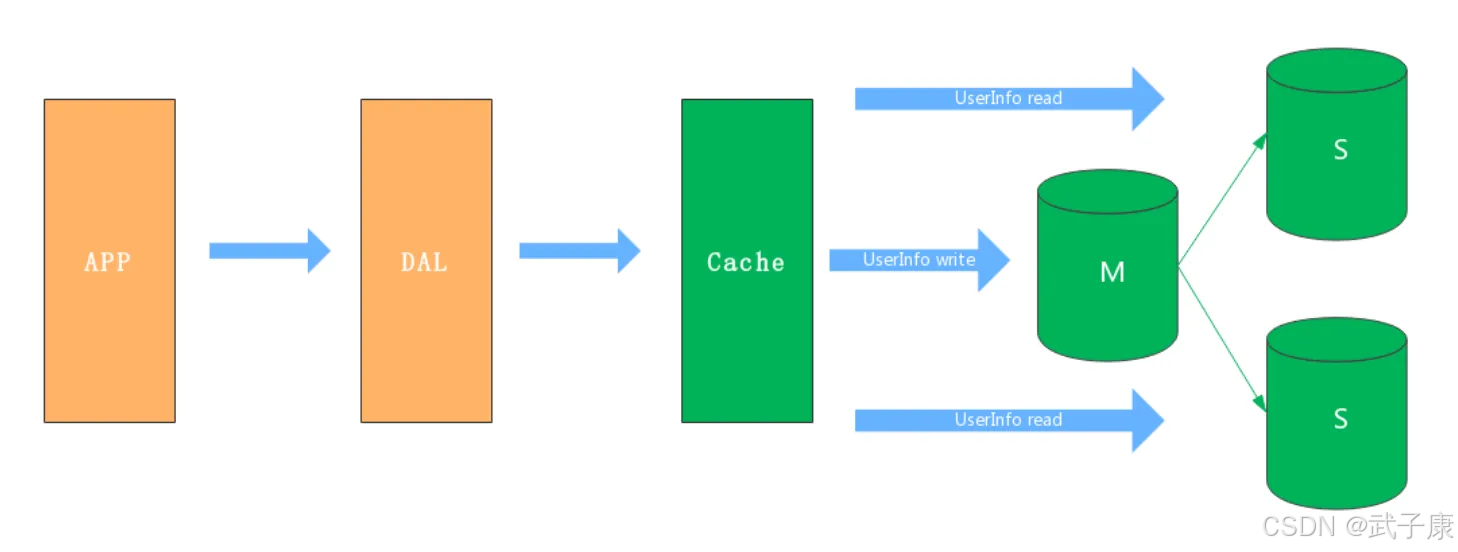
主从架构
1. 架构概述
主从架构(Master-Slave Architecture)是数据库系统中常见的架构模式,主要用于解决单机数据库的性能瓶颈和高可用性问题。该架构由至少两个数据库实例组成:一个主库(Master)和多个从库(Slave)。
2. 核心优势
-
读写分离:
- 主库处理所有写操作(INSERT、UPDATE、DELETE等)
- 从库处理读操作(SELECT),有效分担主库压力
- 典型应用场景:电商平台的商品浏览(读多)与订单提交(写少)
-
高可用性:
- 自动/手动故障转移机制
- 主库宕机时可快速提升从库为新主库
- 故障恢复时间从小时级降至分钟级
-
数据备份:
- 从库实时同步主库数据
- 可作为\"热备份\"使用
- 不影响主库性能的情况下进行备份操作
3. MySQL实现方案
3.1 主从复制
-
配置流程:
- 主库开启binary log
- 从库配置主库连接信息
- 启动复制线程(IO Thread和SQL Thread)
- 监控复制状态(SHOW SLAVE STATUS)
-
同步方式:
- 异步复制(默认)
- 半同步复制(5.7+)
- 组复制(8.0+)
3.2 双主架构
- 互为主从关系
- 适用于需要双向同步的特殊场景
- 需注意避免循环复制问题
4. 适用场景
-
读密集型应用:
- 新闻网站(90%读+10%写)
- 博客平台
- 商品展示页
-
数据分析:
- 报表查询
- 大数据分析
- 不影响线上业务的查询操作
-
灾备方案:
- 异地容灾
- 数据冷备份
5. 性能指标
- 标准配置下:
- 读性能提升300-500%
- 写性能保持单机水平
- 延迟通常在毫秒级(取决于网络状况)
6. 局限性
- 主库仍是写性能瓶颈
- 主从同步存在延迟
- 从库数量增加会加大主库同步负担
- 不解决数据分片问题
7. 最佳实践
- 建议读写比>8:1时采用
- 监控复制延迟(Seconds_Behind_Master)
- 定期校验主从数据一致性
- 建议从库数量不超过5个(视硬件配置而定)## 主从架构
1. 架构概述
主从架构(Master-Slave Architecture)是数据库系统中常见的架构模式,主要用于解决单机数据库的性能瓶颈和高可用性问题。该架构由至少两个数据库实例组成:一个主库(Master)和多个从库(Slave)。
2. 核心优势
-
读写分离:
- 主库处理所有写操作(INSERT、UPDATE、DELETE等)
- 从库处理读操作(SELECT),有效分担主库压力
- 典型应用场景:电商平台的商品浏览(读多)与订单提交(写少)
-
高可用性:
- 自动/手动故障转移机制
- 主库宕机时可快速提升从库为新主库
- 故障恢复时间从小时级降至分钟级
-
数据备份:
- 从库实时同步主库数据
- 可作为\"热备份\"使用
- 不影响主库性能的情况下进行备份操作
3. MySQL实现方案
3.1 主从复制
-
配置流程:
- 主库开启binary log
- 从库配置主库连接信息
- 启动复制线程(IO Thread和SQL Thread)
- 监控复制状态(SHOW SLAVE STATUS)
-
同步方式:
- 异步复制(默认)
- 半同步复制(5.7+)
- 组复制(8.0+)
3.2 双主架构
- 互为主从关系
- 适用于需要双向同步的特殊场景
- 需注意避免循环复制问题
分库分表
在数据库架构设计中,当单库单表性能达到瓶颈时,分库分表是常见的解决方案。具体可以分为垂直拆分和水平拆分两种方式:
垂直拆分
垂直拆分是按照业务维度将不同的表拆分到不同的数据库实例中。例如:
- 将用户信息表(user_info)和订单表(order_info)拆分到不同的数据库
- 将商品基础信息(product)和商品库存(stock)拆分到不同的数据库
垂直拆分的特点是:
- 每个数据库实例都包含完整的业务数据
- 拆分后各库的表结构不同
- 适合业务模块间耦合度低的场景
水平拆分
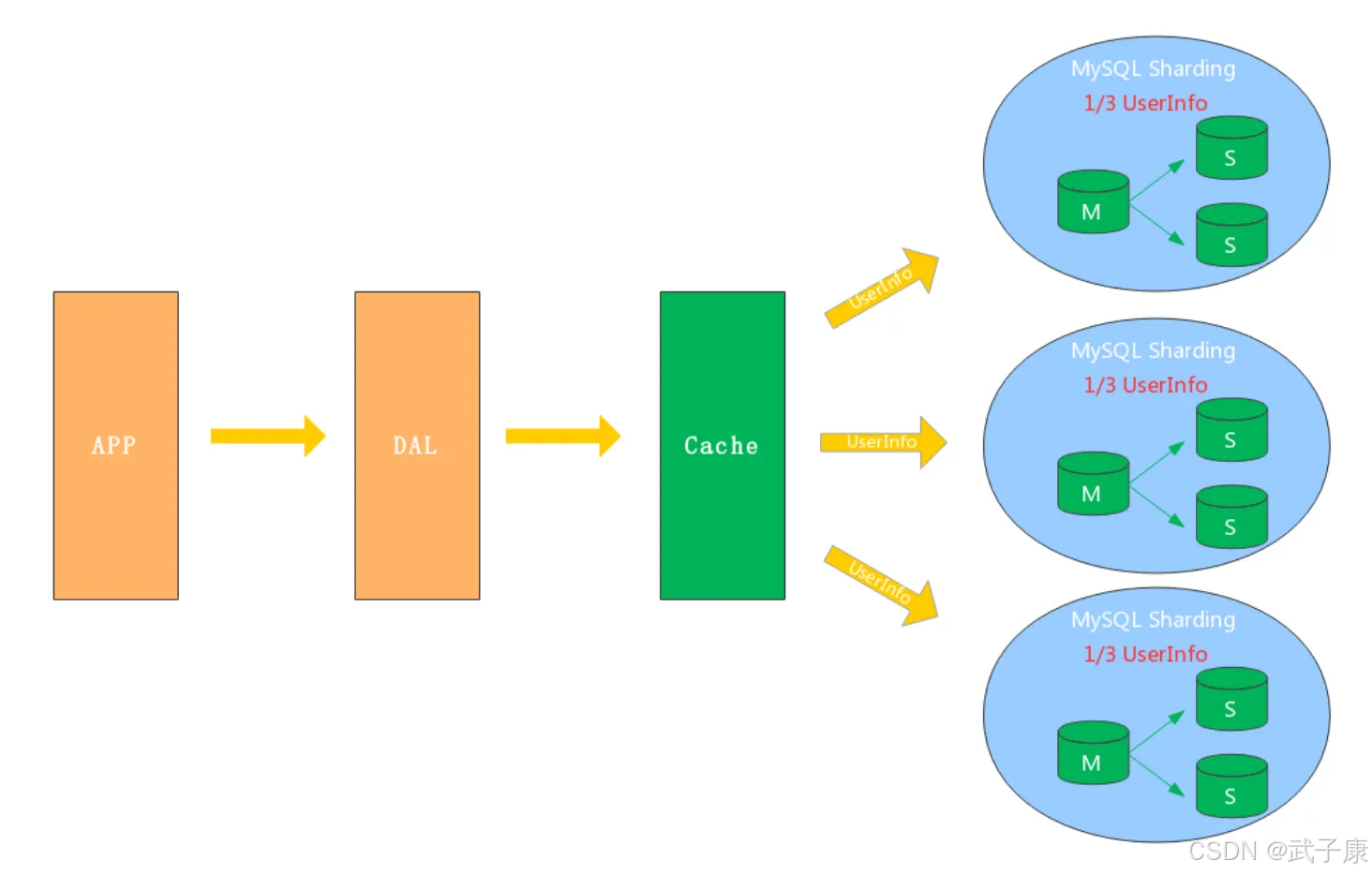
水平拆分是将同一个表的数据按照某种规则分散到不同的数据库实例中。例如:
- 用户表按照用户ID取模分成4个库
- 订单表按照创建时间范围分成月度表
水平拆分的特点是:
- 每个数据库实例只包含部分数据(1/n)
- 拆分后各库的表结构完全相同
- 适合单表数据量巨大的场景
水平拆分常见策略
-
哈希分片:如user_id % 4
- 优点:数据分布均匀
- 缺点:扩容困难
-
范围分片:如按时间范围
- 优点:易于扩容
- 缺点:可能存在热点问题
-
目录分片:使用路由表维护映射关系
- 灵活性高但维护成本也高
应用场景对比
-
电商系统:
- 垂直拆分:用户/商品/订单分到不同库
- 水平拆分:订单表按用户ID哈希分片
-
社交平台:
- 垂直拆分:用户信息/好友关系/动态内容分离
- 水平拆分:用户动态按时间分片
注意:实际应用中经常需要结合两种拆分方式,先垂直拆后水平拆,以达到最优的扩展效果。## 分库分表
在数据库架构设计中,当单库单表性能达到瓶颈时,分库分表是常见的解决方案。具体可以分为垂直拆分和水平拆分两种方式:
垂直拆分
垂直拆分是按照业务维度将不同的表拆分到不同的数据库实例中。例如:
- 将用户信息表(user_info)和订单表(order_info)拆分到不同的数据库
- 将商品基础信息(product)和商品库存(stock)拆分到不同的数据库
垂直拆分的特点是:
- 每个数据库实例都包含完整的业务数据
- 拆分后各库的表结构不同
- 适合业务模块间耦合度低的场景
水平拆分
水平拆分是将同一个表的数据按照某种规则分散到不同的数据库实例中。例如:
- 用户表按照用户ID取模分成4个库
- 订单表按照创建时间范围分成月度表
水平拆分的特点是:
- 每个数据库实例只包含部分数据(1/n)
- 拆分后各库的表结构完全相同
- 适合单表数据量巨大的场景
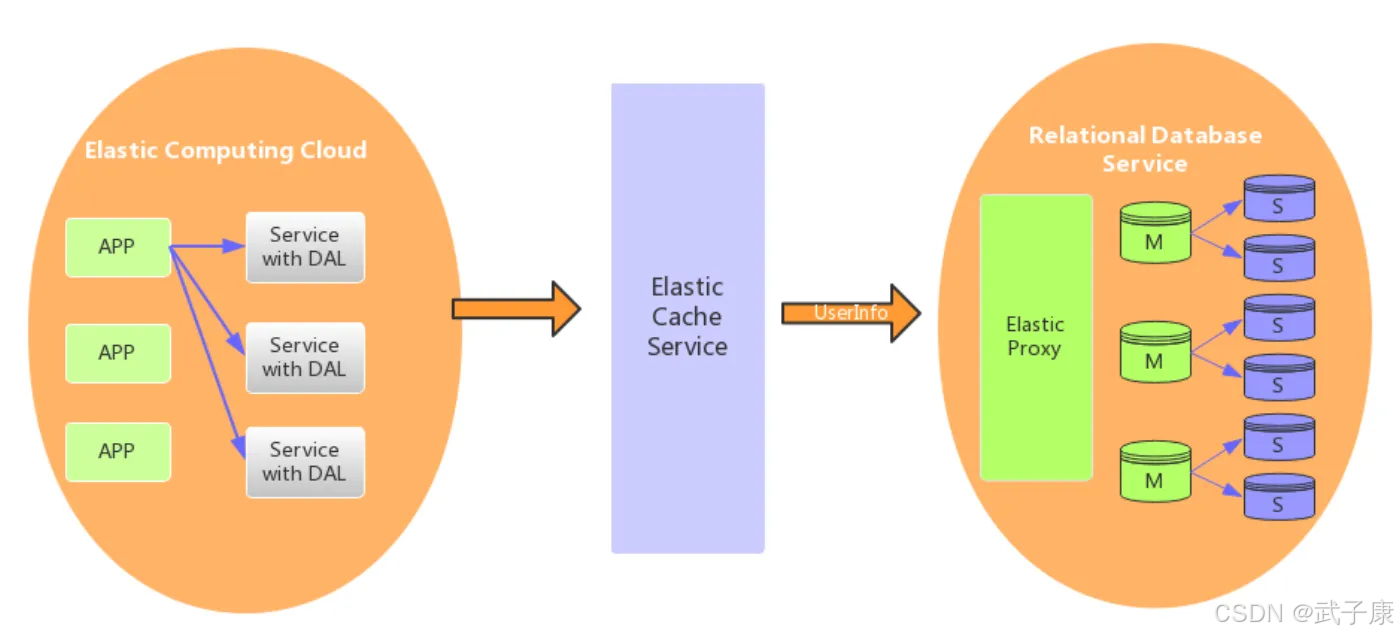
云数据库:数字化转型的关键基础设施
云数据库已成为现代企业数字化转型的核心组件,作为当前数据库技术的主流发展方向,它通过云计算模式重新定义了数据存储和管理的范式。根据Gartner最新报告,预计到2025年,超过75%的数据库将部署在云平台上,相比2021年增长近300%。
成本优化与效率提升
云数据库为企业提供了显著的节约成本优势,主要体现在:
- CAPEX转OPEX:消除前期硬件采购成本,转为按需付费模式
- 弹性扩展:根据业务负载自动调整资源,避免过度配置
- 运维简化:自动化备份、监控和故障转移,降低人力成本
- 全球部署:利用云服务商的全球基础设施,减少跨境数据延迟
典型案例:某电商平台采用云数据库后,年度IT支出降低42%,同时峰值处理能力提升8倍。