【仿RabbitMQ实现消息队列项目】不懂这些库?你的C++项目可能少了点什么!SQLite3、Protobuf、gtest、muduo 简单科普,一文让小白秒懂!
本篇摘要
- 本篇是c++中的一个仿RabbitMQ实现消息队列项目项目的开篇,在本篇我们将介绍这四个好用的“神器”的用法,方便之后,实现后面的项目做铺垫。


欢迎拜访: 点击进入博主主页
本篇主题: SQLite3、Protobuf、gtest、muduo 简单科普
制作日期: 2025.08.19
隶属专栏: 点击进入所属仿RabbitMQ实现消息队列项目专栏
一.SQlite3介绍及简单使用
SQLite简介
- 定义:SQLite 是一个进程内的轻量级数据库,它实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库不一样,我们不需要在系统中配置。像其他数据库, SQLite 引擎不是一个独立的进程,可以按应用程序需求进行静态或动态连接, SQLite 直接访问其存储文件。
- 特点:
- 无需单独服务器进程或操作系统支持。
- 无需配置。
- 整个数据库存储为单一跨平台磁盘文件。
- 体积小,完全配置小于400KiB,省略可选功能小于250KiB。
- 自给自足,无外部依赖。
- 事务兼容ACID,支持多进程或线程安全访问。
- 支持SQL92(SQL2)标准多数查询语言功能。
- 用ANSI - C编写,API简单易用。
- 可在UNIX(Linux、Mac OS - X、Android、iOS)和Windows(Win32、WinCE、WinRT)运行。
安装SQlite3
这段内容展示了在 Linux 系统(从命令风格看大概率是 CentOS/RHEL 类系统)上安装 SQLite 开发包并验证安装结果的步骤,总结如下:
1. 安装 SQLite 开发包
要编译/开发依赖 SQLite 的程序(比如用 C/C++ 操作 SQLite 数据库),通常需要先安装 sqlite-devel 这个开发包(它包含了头文件、库文件等开发所需资源)。
在终端中执行:
sudo yum install sqlite-develsudo:以管理员(root)权限执行命令,因为安装软件包需要系统级权限。yum install:CentOS/RHEL 系统下使用yum包管理器来安装软件包。sqlite-devel:就是 SQLite 的开发包名称。
2. 验证安装是否成功
安装完成后,可以通过查看 SQLite 命令行工具的版本,来确认开发包(以及 SQLite 本身)是否正常安装。在终端执行:
sqlite3 --version如果能看到类似下面的输出(版本号、编译时间等信息),就说明安装成功了:
3.7.17 2013-05-20 00:56:22118a3b35693b134d56ebd780123b7fd6f1497668简单来说,整个流程就是用 yum 安装 sqlite-devel → 执行 sqlite3 --version 验证,以此完成 SQLite 开发环境的搭建与验证(ubuntu就是apt)。
接口解释及使用
这个 我们要使用的Sqlite 类做了三件事:
- 打开/创建一个 SQLite 数据库文件
- 执行一条 SQL 语句(比如建表、插入数据、查询等)
- 关闭数据库连接
SQLite3 函数介绍(通俗版)
1. sqlite3_open_v2(...)
作用:打开(或创建)一个 SQLite 数据库文件
原型(简化理解):
int sqlite3_open_v2( const char *filename, // 数据库文件名(比如 test.db) sqlite3 **ppDb, // 输出参数,返回数据库句柄(操作数据库的“钥匙”) int flags, // 打开方式(读写、创建、线程模式等) const char *zVfs // 一般用 nullptr,表示默认文件系统);通俗解释:
-
你想操作一个数据库文件(比如
test.db),这个函数会:- 如果文件存在 → 打开它;
- 如果文件不存在 → 创建一个新的数据库文件;
-
成功后会返回一个“句柄”(
_handler),后续所有操作都要通过这个句柄来进行; -
如果失败(比如路径不对、权限不够等),会返回错误码,你可以通过
sqlite3_errmsg()查看错误信息。常用标志位(你一定要了解的):
SQLITE_OPEN_READWRITESQLITE_OPEN_READONLYSQLITE_OPEN_CREATESQLITE_OPEN_FULLMUTEXSQLITE_OPEN_SHAREDCACHESQLITE_OPEN_PRIVATECACHE使用如:
int ret = sqlite3_open_v2(_filename.c_str(), &_handler, SQLITE_OPEN_FULLMUTEX | SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE, nullptr);2. sqlite3_exec(...)
作用:执行一条 SQL 语句(比如建表、插入、查询等)
原型(简化理解):
int sqlite3_exec( sqlite3 *db, // 数据库句柄(就是之前打开数据库拿到的 _handler) const char *sql, // 你要执行的 SQL 语句字符串,比如 \"CREATE TABLE xxx\" int (*callback)(void*,int,char**,char**), // 回调函数(查询时用来处理结果,可选) void *arg, // 传给回调函数的参数(一般用不到可以填 nullptr) char **errmsg // 如果出错,这里会返回错误信息(字符串));通俗解释:
- 你想让 SQLite 执行一句 SQL,比如创建表、插入数据、查询等;
- 这个函数可以执行 绝大多数 SQL 命令;
- 如果是查询语句(SELECT),通常需要搭配回调函数来获取返回的数据;
- 如果执行失败,会返回错误码,并可通过
errmsg获取错误信息(不过你代码里这个参数传的是nullptr,所以看不到具体错误信息,建议后续改进);
使用如:
int ret = sqlite3_exec(_handler, sql.c_str(), cb, nullptr, nullptr);这里需要注意的就是这个回调函数:
int callback(void *NotUsed, int argc, char **argv, char **azColName);-
这个接口最终必须返回0,不然出错。
-
当我们exc执行完对应sql语句后拿到的串就会调用这个函数,一般我们把对应的对象传进去然后等查询完就调用这个函数完成想要的操作。
现在根据这个框架解释下:
static int SelectCallback(void *arg, int colnum, char **rowarr, char **segname) { return 0; // 注意返回0 }- 一般只有进行读取操作才用到。
- 首先读出一行数据就去调用它。
- 第一个参数就是我们调用SQlite3_exec()传进来的对应的参数。
- 第二个参数就是有多少列。
- 第三个参数就是当前行的字符串数组。
- 第四个参数就是每个字段名字构成的数组。
假设我们读出数据有5行,相当于遍历走五遍这个回调函数,后面项目会用到。
3. sqlite3_close_v2(...)
作用:安全地关闭数据库连接,释放资源
原型(简化理解):
int sqlite3_close_v2(sqlite3 *db);通俗解释:
- 当你用完数据库(比如程序退出、不再需要操作数据库时),必须调用这个函数来关闭数据库连接;
- 它会安全释放所有相关资源,防止内存泄漏或数据库文件损坏;
- 传入的参数就是之前
sqlite3_open_v2()返回的那个数据库句柄_handler;
总结:这几个函数是干嘛的?
sqlite3_open_v2()bool Open(...)sqlite3_exec()bool Exec(...)sqlite3_close_v2()void Close()封装Sqlite3类
#include #include #include #include // 模拟封装个简单的sqliteclass Sqlite{public: using callback = int (*)(void *, int, char **, char **); // typedef int (*callback)(void*,int,char**,char**); Sqlite(const std::string name) : _filename(name) {} bool Open(int level = SQLITE_OPEN_FULLMUTEX) { int ret = sqlite3_open_v2(_filename.c_str(), &_handler, level | SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE, nullptr); if (ret != SQLITE_OK) { std::cout << \"创建/打开sqlite数据库失败: \"; std::cout << sqlite3_errmsg(_handler) << std::endl; return false; } else return true; } bool Exec(const std::string sql, callback cb, void *arg) { int ret = sqlite3_exec(_handler, sql.c_str(), cb, nullptr, nullptr); if (ret != SQLITE_OK) { std::cout << sql << std::endl; std::cout << \"执行语句失败: \"; std::cout << sqlite3_errmsg(_handler) << std::endl; return false; } return true; } void Close() { if (_handler) sqlite3_close_v2(_handler); }private: std::string _filename; sqlite3 *_handler;};基于封装SQlite3类的测试
下面执行这两条语句:
string sql_create= \"create table if not exists stu( num int primary key , name varchar(32),age int);\"; string sql_add=\"insert into stu values (0,\'张三\',18),(1,\'李四\',11) ,(2,\'王五\',10);\"; sq.Exec(sql_create,nullptr,nullptr); sq.Exec(sql_add,nullptr,nullptr);编译链接下:
g++ test.cc -lsqlite3运行后可以看到创建成功:
然后我们打开对应的SQlite3对应的文件(sqlite3 test.db3 ,内部使用语法基本和mysql一致,但是查询比如是.tables,退出是.exit,然后就是这类语句都没有分号;而一些如select,创建等操作都要有分号):
效果:
root@hsyq:/home/youxing/cpp_project-2/message_queue_project/ready_demo/sqlite# sqlite3 test.db3SQLite version 3.37.2 2022-01-06 13:25:41Enter \".help\" for usage hints.sqlite> .tablesstusqlite> select * from stu;0|张三|181|李四|112|王五|10sqlite> 下面执行:
string sql_del=\"delete from stu where num=0\";string sql_up=\"update stu set name=\'篱笆\'where num=1;\";sq.Exec(sql_del,nullptr,nullptr);sq.Exec(sql_up,nullptr,nullptr);效果:
SQLite version 3.37.2 2022-01-06 13:25:41Enter \".help\" for usage hints.sqlite> select * from stu;1|篱笆|112|王五|10sqlite> .exit这里就先使用到这,毕竟后面项目用到的也就这些。
二. Protobuf的介绍及简单使用
安装Protobuf
1. 安装依赖库(适用于 C++)
sudo yum install -y autoconf automake libtool curl make gcc-c++ unzip2. 下载 Protobuf 包
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.20.2/protobuf-all-3.20.2.tar.gz# 若 GitHub 下载慢,改用:# wget https://gitee.com/qigezi/bitmq/blob/master/mqthird/protobuf-all-3.20.2.tar.gz3. 编译安装
tar -zxf protobuf-all-3.20.2.tar.gz && \\cd protobuf-3.20.2 && \\./autogen.sh && \\./configure && \\make -j$(nproc) && \\sudo make install && \\protoc --version说明:
-j$(nproc):多核加速编译- 若仅需特定语言支持(如 Python/Java),可跳过
autogen.sh步骤 - 安装路径默认为
/usr/local/,可通过./configure --prefix=/your/path自定义
基于Protobuf的简单介绍
1. Protobuf 是什么?
Protobuf(Protocol Buffers) 是 Google 开发的一种高效的数据序列化格式,用于结构化数据存储和网络通信。
简单来说,它就像一个更小、更快、更省空间的 JSON/XML 替代品,但比它们更高效!
对比理解
2·Protobuf 的核心优势
体积小:二进制格式,比 JSON/XML 小很多
速度快:解析和序列化比 JSON 快得多
跨语言:支持 C++、Java、Python、Go、C# 等
强类型:定义数据结构(.proto 文件),编译后生成代码
兼容性好:可以向后兼容(旧代码能读新数据,新代码也能读旧数据)
3. Protobuf 基本使用步骤
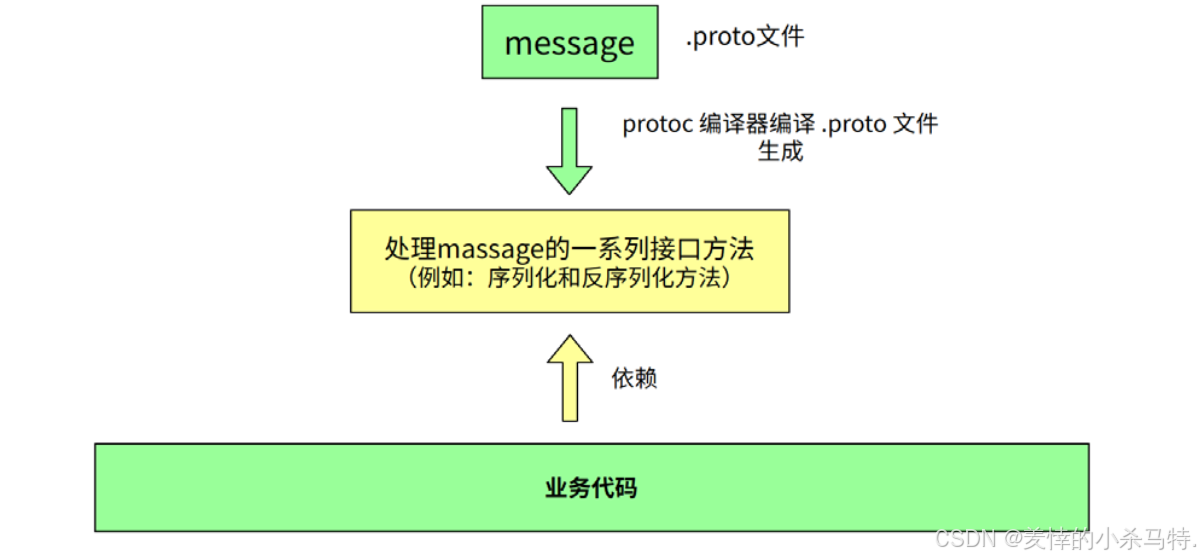
步骤 1:定义数据结构(.proto 文件)
先写一个 .proto 文件,定义你要传输的数据格式,例如:
示例:person.proto
syntax = \"proto3\"; // 使用 Protobuf 3 语法// 定义一个消息(类似 C++ 的 struct / Python 的 class)message Person { string name = 1; // 字段名 = 字段编号(唯一) int32 id = 2; // 编号不能重复 string email = 3;}syntax = \"proto3\":表示使用 Protobuf 3 语法(推荐)。message:类似于 C++ 的 struct / Python 的 class,用于定义数据结构。string name = 1;:name是字段名,string是类型,1是唯一编号(不能重复)。- 编号(1, 2, 3…) 用于二进制编码,不能改,但可以改字段名!
步骤 2:编译 .proto 文件(生成代码)
用 protoc(Protobuf 编译器) 把 .proto 文件编译成 C++/Python/Java 等代码。
安装 protoc(Linux/macOS)
# 下载 protoc(以 3.20.2 为例)wget https://github.com/protocolbuffers/protobuf/releases/download/v3.20.2/protobuf-all-3.20.2.tar.gztar -xzf protobuf-all-3.20.2.tar.gzcd protobuf-3.20.2./configuremake -j$(nproc)sudo make installprotoc --version # 检查是否安装成功编译 .proto 文件(生成 C++ 代码)
protoc --cpp_out=. person.proto--cpp_out=.:生成 C++ 代码(.pb.h和.pb.cc文件)- 其他语言:
--python_out=.→ Python--java_out=.→ Java--go_out=.→ Go
编译后会生成:
person.pb.h(头文件)person.pb.cc(实现文件,C++)
4. Protobuf 语法详解
基本数据类型
int32 / int64int32_t / int64_tintuint32 / uint64uint32_t / uint64_tintfloatfloatfloatdoubledoublefloatboolboolboolstringstd::stringstrbytesstd::stringbytes字段规则
requiredoptionalrepeatedstd::vector)示例(带 repeated):
message Person { string name = 1; repeated int32 phone_numbers = 2; // 可以存多个电话号码}如:
Person person;person.add_phone_numbers(123456789); // 添加一个号码person.add_phone_numbers(987654321); // 再添加一个5.常用函数接口:
Person person;set_xxx(value)set_name(\"Alice\"))add_xxx(value)repeated 字段(如 add_phone_numbers(123))xxx()person.name())xxx(index)repeated 字段的某个元素(如 person.phone_numbers(0))SerializeToString(&str)SerializeToArray(buffer, size)ParseFromString(str)ParseFromArray(buffer, size)clear_xxx()6. Protobuf vs JSON
基于Protobuf的简单测试
首先写一个proto后缀的文件(按照上面的规则):
syntax=\"proto3\";//规定语法package test;//声明作用域//probuf对象类message stu{ int32 age=1; string name=2;//每个类唯一编码 float socre=3;}然后对应命令编译:
protoc --cpp_out=. test.proto然后得到两个文件:
- 一个是放着一些对应函数接口的.h文件和它对应调用的.c文件。
- 我们只需要包含对应.h然后运行的时候连同.cc一起编译链接即可。
测试代码:
#include#include\"test.pb.h\"int main(){ test::stu s; s.set_age(1); s.set_socre(99.5); s.set_name(\"马得\"); std::string str= s.SerializeAsString(); std::cout<<\"序列化结果是: \"<<str<<std::endl; int ret=s.ParseFromString(str); if(ret==-1) { std::cout<<\"反序列化失败\"<<std::endl; return -1; } std::cout<<s.name()<<std::endl; std::cout<<s.socre()<<std::endl; std::cout<<s.age()<<std::endl;}下面编译链接并运行下:

简单使用到此为止,用到的也就这些。
三.gtest的介绍即简单应用
安装步骤
# 步骤1:安装EPEL软件源扩展sudo yum install epel-release# 步骤2:安装DNF包管理器sudo yum install dnf# 步骤3:安装DNF核心插件集sudo dnf install dnf-plugins-core# 步骤4:安装Google Test及其开发包sudo dnf install gtest gtest-devel基于gtest用法简单介绍
GTest是什么
- GTest是Google发布的一个跨平台C++单元测试框架。
- 用于在不同平台上编写C++单元测试,提供丰富断言、致命/非致命判断、参数化等功能(对应头文件#include )。
GTest使用 - TEST宏
TEST(test_case_name, test_name):创建简单测试,定义测试函数,可在其中用C++代码和框架断言检查。TEST_F(test_fixture,test_name):用于多样测试,当多个测试场景需相同数据配置(相同数据测不同行为)时使用。
断言
- 断言宏分两类:
ASSERT_系列:检测失败则退出当前函数。EXPECT_系列:检测失败则继续往下执行。
- 常用断言介绍:
- bool值检查:
ASSERT_TRUE(参数):期待结果为true。ASSERT_FALSE(参数):期待结果为false。
- 数值型数据检查:
ASSERT_EQ(参数1, 参数2):传入两数比较,相等返回true。ASSERT_NE(参数1, 参数2):不相等返回true。ASSERT_LT(参数1, 参数2):小于返回true。ASSERT_GT(参数1, 参数2):大于返回true。ASSERT_LE(参数1, 参数2):小于等于返回true。ASSERT_GE(参数1, 参数2):大于等于返回true。
- bool值检查:
- 自定义错误信息:若对自动输出错误信息不满意,可通过
operator<<在失败时打印自定义日志。
它是基于一套测试用例可以有许多测试用例组:
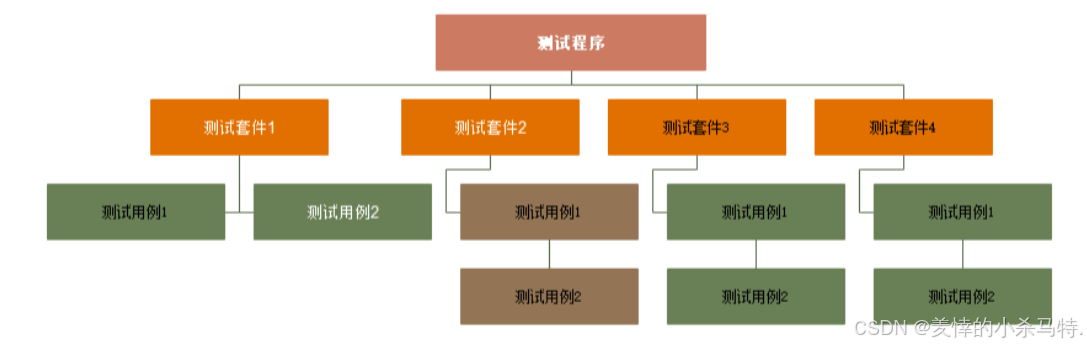
- 测试程序:一个测试程序只有一个 main 函数,也可以说是一个可执行程序是一个测试程序。该级别的事件机制是在程序的开始和结束执行
- 测试套件:代表一个测试用例的集合体,该级别的事件机制是在整体的测试案例开始和结束执行
- 测试用例:该级别的事件机制是在每个测试用例开始和结束都执行(每个TEST)
下面简单的test测试:
源码:
#include #include int abs(int x) { return x > 0 ? x : -x; } TEST(abs_test, test1) { ASSERT_TRUE(abs(1) == 1) << \"abs(1)=1\"; ASSERT_TRUE(abs(-1) == 1); ASSERT_FALSE(abs(-2) == -2); ASSERT_EQ(abs(1),abs(-1)); ASSERT_NE(abs(-1),0); ASSERT_LT(abs(-1),2); ASSERT_GT(abs(-1),0); ASSERT_LE(abs(-1),2); ASSERT_GE(abs(-1),2); } int main(int argc,char *argv[]) { //将命令行参数传递给gtest testing::InitGoogleTest(&argc, argv); // 运行所有测试案例 return RUN_ALL_TESTS(); } 运行结果:
可以看到也是非常人性化的:
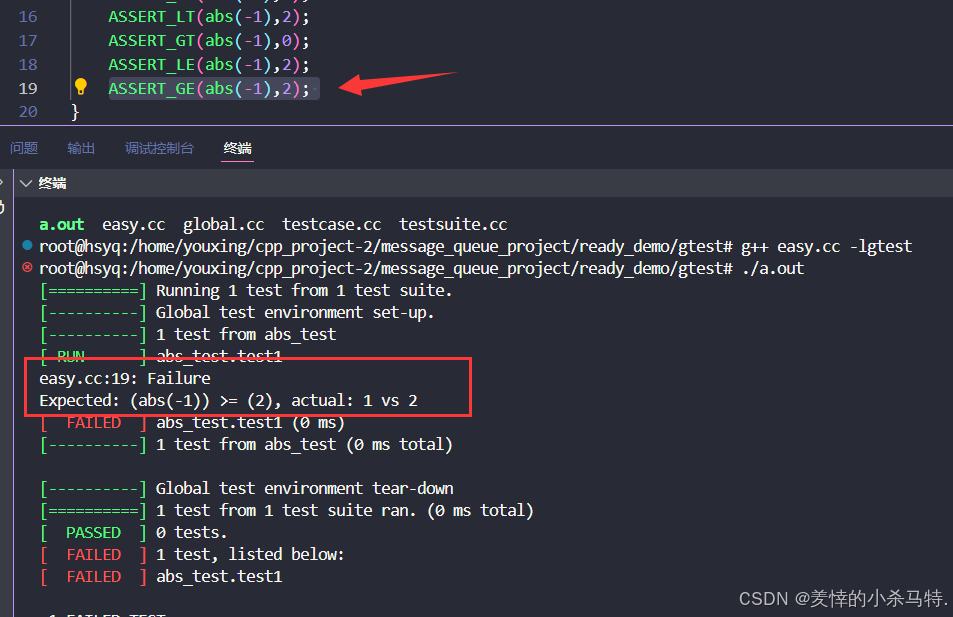
gtest使用的三种情况
1·全局事件
简单来说:
- 定义一个类继承全局类(
class Globaltest : public testing::Environment) - 实现对应虚函数(
SetUp+TearDown) - 大环境之前调用SetUp函数,测试用例组结束后,也就是大环境准备析构调用TearDown。
- main函数中先拿参数初始化gtest,然后new下Environment对象,再跑测试。
基于Global下的测试:
源码:
#include #include using namespace std;class Globaltest : public testing::Environment{public: virtual void SetUp() override { std::cout << \"测试前:提前准备数据!!\\n\"; } virtual void TearDown() override { std::cout << \"测试结束后:清理数据!!\\n\"; } static size_t cnt;};size_t Globaltest::cnt = 1;TEST(test1, cnt1){ ASSERT_EQ(Globaltest::cnt, 1);}TEST(test1, cnt2){ Globaltest::cnt = 2; ASSERT_EQ(Globaltest::cnt, 2);}int main(int argc, char *argv[]){ testing::AddGlobalTestEnvironment(new Globaltest() ); testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}测试结果:
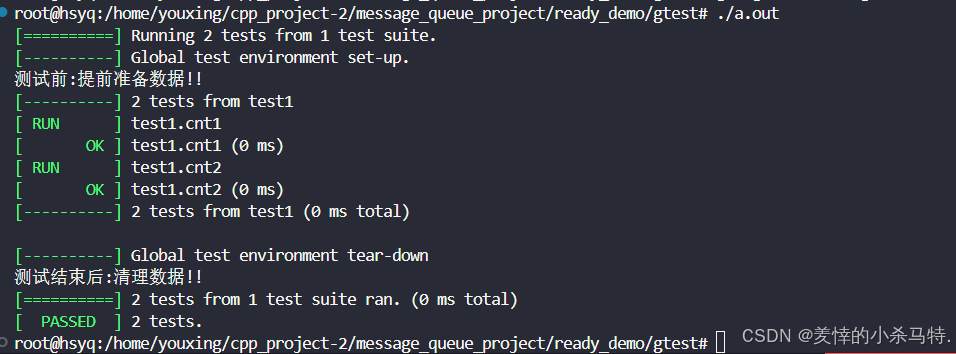
- 这里可以发现多个测试用例全局值初始化一次环境。
2·testsuite事件
针对一个个测试套件。测试套件的事件机制我们同样需要去创建
一个类,继承自 testing::Test,实现两个静态函数 SetUpTestCase 和TearDownTestCase,测试套件的事件机制不需要像全局事件机制一样在 main 注册,而是需要将我们平时使用的 TEST 宏改为 TEST_F 宏然后第一个参数传递我们子类,第二个就是每个测试用例名称,还有就是不需要new大环境对象了。
基于testsuite下的测试:
源码:
#include #include using namespace std;class Suite : public testing::Test{public: static void SetUpTestCase() { std::cout << \"测试前:提前准备数据!!\\n\"; } static void TearDownTestCase() { std::cout << \"测试结束后:清理数据!!\\n\"; } static size_t cnt;};size_t Suite::cnt = 1;TEST_F(Suite, cnt1){ ASSERT_EQ(Suite::cnt, 1); cnt++;}TEST_F(Suite, cnt2){ ASSERT_EQ(Suite::cnt, 2);}int main(int argc, char *argv[]){ testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}测试结果:
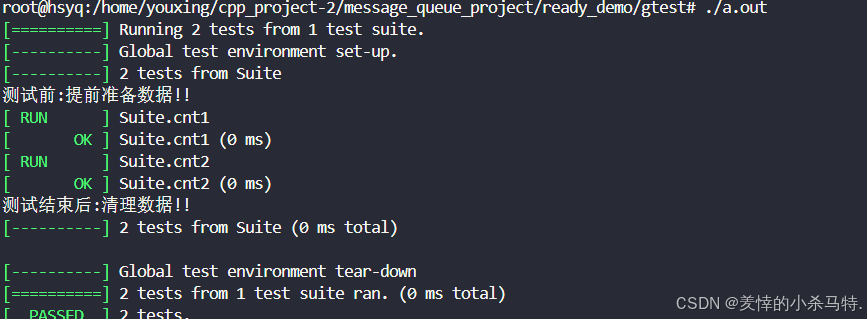
- 可以发现是在两个测试用例都结束后调用的静态的那俩函数。
- 这样使用可以如上面那样,把一个用例对全局的改变让另一个用例看到。
3.testcase事件
TestCase 事件: 针对一个个测试用例。测试用例的事件机制的创建和测试套件的基本一样,不同地方在于测试用例实现的两个函数分别是 SetUp 和 TearDown, 这两个函数也不是静态函数。
- 简单来说就是和testsuite其他地方相同,但是比它多了个继承重写的
SetUp和TearDown函数,然后这俩是每个测试开始前和结束调用;而对应之前的SetUpTestCase与TearDownTestCase这俩仍是大环境开始和结束调用了。
基于testcase下的测试:
源码:
#include #include using namespace std;class TestCase : public testing::Test{public: virtual void SetUp() override { std::cout << \"每组测试用例前:提前准备数据!!\\n\"; cnt++; } virtual void TearDown() override { std::cout << \"每组测试用例测试结束后:清理数据!!\\n\"; } static void SetUpTestCase() { std::cout << \"测试前:提前准备数据!!\\n\"; } static void TearDownTestCase() { std::cout << \"测试结束后:清理数据!!\\n\"; } static size_t cnt;};size_t TestCase::cnt = 0;TEST_F(TestCase, cnt1){ ASSERT_EQ(TestCase::cnt, 1);}TEST_F(TestCase, cnt2){ ASSERT_EQ(TestCase::cnt, 2);}int main(int argc, char *argv[]){ testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}测试结果:
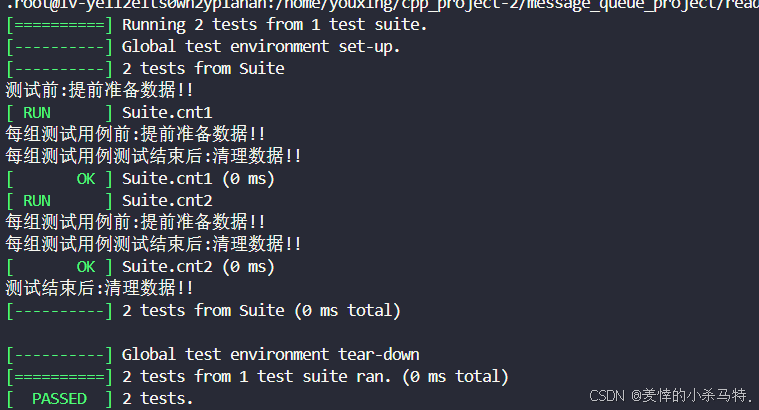
基于testsuite和testcase总结下:
其实这两个用法都是一样的(对应SetUpTestCase TearDownTestCase是对于大环境,而SetUp TearDown是针对每个测试用例而言),只不过我们用testsuite的时候,其实就是对整套进行的,故只使用SetUpTestCase TearDownTestCase,但是当testcase,明显用到了测试用例,故使用SetUp TearDown,但是大环境也要用故其他俩也要用到。
即 testsuite模式只用SetUpTestCase TearDownTestCase来全局初始和清理;而testcase 既要用它,还要用SetUp TearDown来对每个测试用例进行初始化和销毁。
四.muduo库的介绍及简单使用
Muduo库是陈硕开发的一个用于C++的高性能网络编程库,主要用于构建高并发的TCP网络应用。以下是对Muduo库的简单介绍:
1. 基本定义与设计思想
- 基于非阻塞IO与事件驱动:Muduo采用非阻塞I/O模型,配合事件驱动机制,能高效处理大量并发连接,避免传统阻塞I/O中“一个连接对应一个线程”带来的资源浪费与性能瓶颈。
- 主从Reactor模式:它借鉴了Reactor设计模式并做了扩展,采用“主从Reactor”架构。主Reactor负责监听新连接,当有客户端连接到来时,把连接分发给子Reactor;子Reactor则专门处理已建立连接的读写事件。
2. 线程模型:one loop per thread(epoll那里提到过)
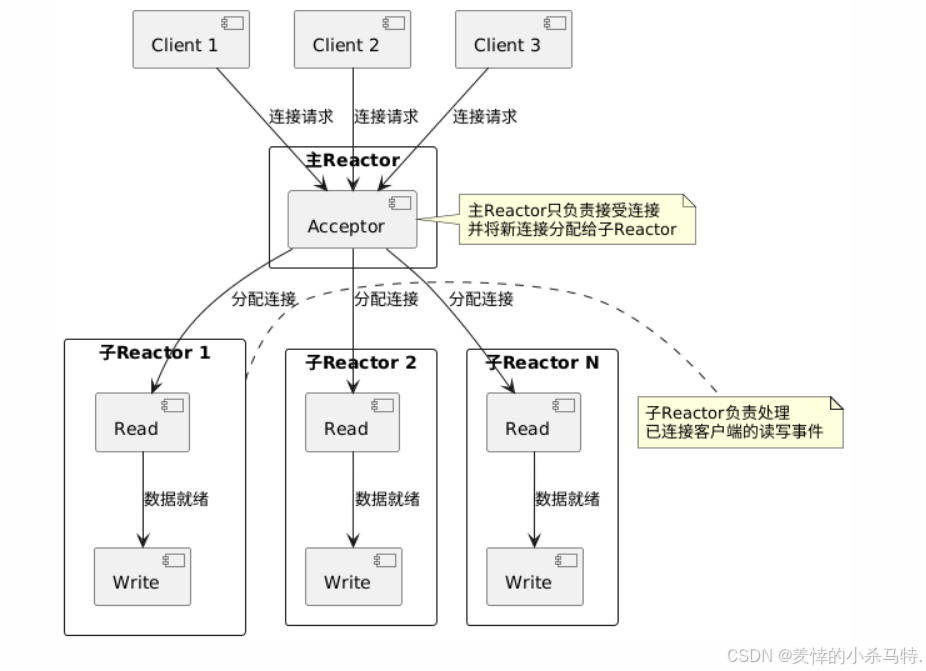
Muduo的核心线程模型是 “one loop per thread”,意思是:
- 每个线程有且只有一个
EventLoop(事件循环),这个EventLoop负责响应定时器事件和I/O事件(比如套接字的读、写就绪)。 - 一个文件描述符(对应一个TCP连接)只会由一个线程来读写。也就是说,某个TCP连接从建立到断开,全程由某一个
EventLoop(某个线程)来管理,避免了多线程同时操作同一个连接带来的竞态问题。
3. 核心组件与工作流程
- Acceptor:负责监听端口、接受新连接。当有客户端
connect过来时,Acceptor会创建一个新的TcpConnection对象,并把这个连接“交给”某个子Reactor去管理。 - EventLoop:每个线程的事件循环中枢,不断轮询注册在其上的I/O事件(读、写、定时器等),一旦有事件就绪,就回调对应的处理函数。
- TcpConnection:封装了一条TCP连接的状态与操作(比如读数据、写数据、连接建立/断开回调等)。每个
TcpConnection会绑定到某一个EventLoop上,由该EventLoop负责它的读写事件分发。
4. 为什么选择Muduo?
- 高性能:非阻塞I/O + 事件驱动 + 主从Reactor + one loop per thread,这些设计让它在高并发场景下(比如成千上万的TCP连接)依然能保持较低的延迟与较高的吞吐量。
- 线程安全与易用性:Muduo通过合理的线程模型(一个连接只由一个线程管理),减少了多线程同步的复杂度;同时提供了简洁的接口,让开发者可以更专注于业务逻辑,而非底层网络细节。
5. 简单应用场景
Muduo非常适合用来开发高并发的服务器程序,例如:
- 即时通讯服务器(IM)
- 游戏服务器
- 分布式系统中的RPC框架
- 各种需要处理大量长连接/短连接的网络服务
总之,Muduo通过精心设计的线程模型与事件驱动机制,在C++生态里为高并发TCP网络编程提供了一套高效、易用的解决方案,让开发者能以相对低的成本写出性能强劲的网络服务端程序。
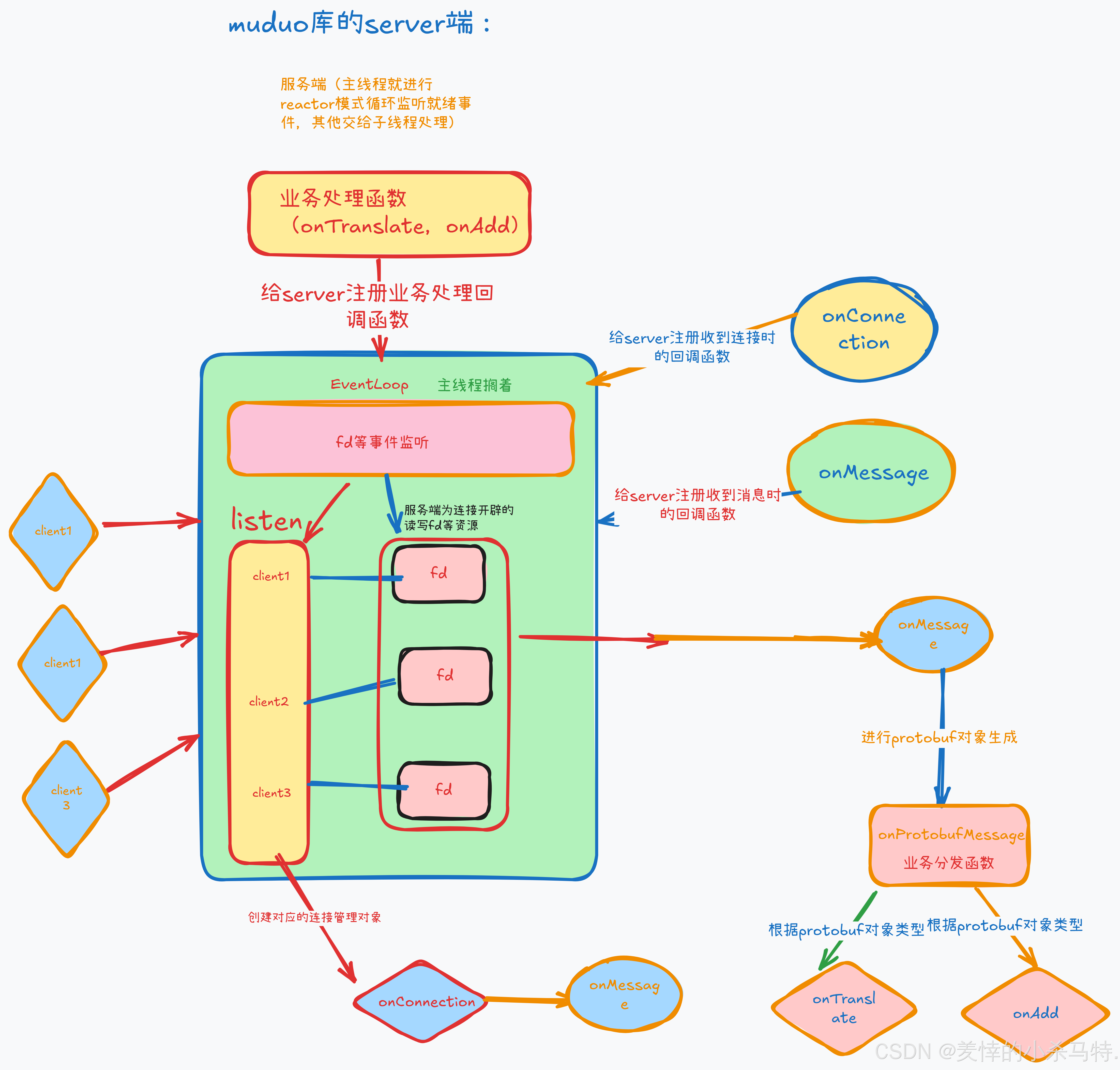
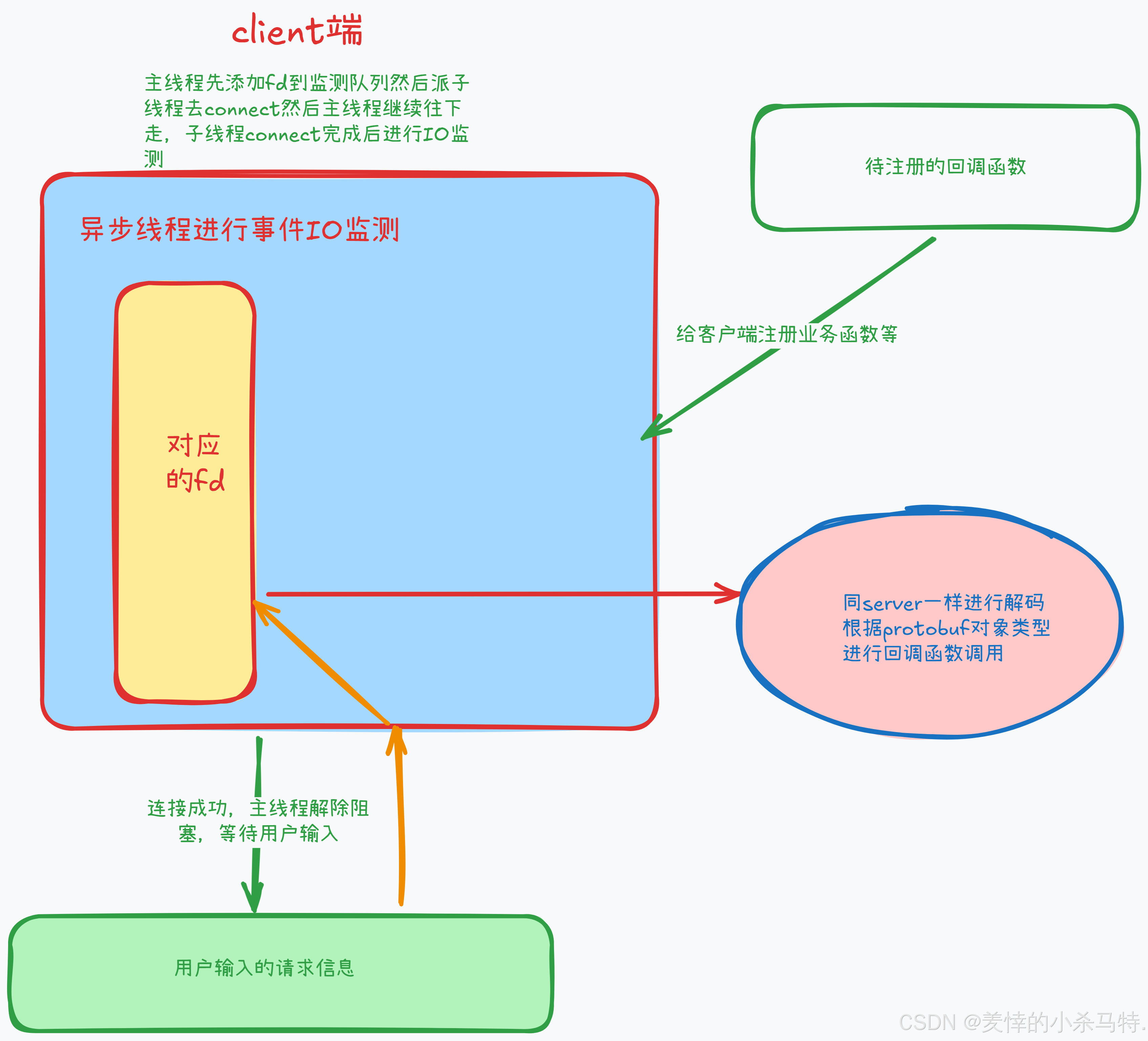
6.认识下基于muduo库的server和client端大致流程(博主亲自手画通俗易懂):
server端流程手绘:
client端流程手绘:
基于muduo库简单使用:
流程如上,下面看测试效果(模拟实现的业务加法与翻译):
- client的请求:

- 对话结果:

- 符合预期
以上就是对muduo库的简单应用,项目用到的也就只有这些,把上面的模版搞定,后面项目的使用没丝毫难度(如果没看懂请看上图,秒懂)
五.这里追增下关于异步操作的一些知识
std::future
1.与 std::async 配合使用(最常用)
作用: 异步启动一个任务,并通过 std::future 获取它的返回值。
用法:
- 用
std::async(std::launch::......, 函数)启动一个异步任务,返回一个std::future对象。 - 用
future.get()获取任务结果(会阻塞,直到结果返回,且只能调用一次)。
适用场景: 想简单异步执行一个函数并获取结果时用。
而它由分为三种选择情况(async deferred 不选)。
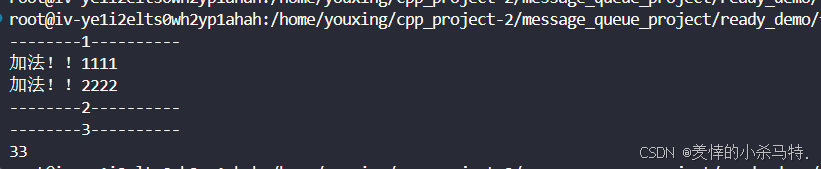
默认不选择选项(这里):
- 这里就是直接就是主线程去执行,再去获取,没有异步线程的意思。
代码如下:
#include #include #include #include int Add(int num1, int num2){ //std::this_thread::sleep_for(std::chrono::seconds(1)); std::cout << \"加法!!1111\\n\"; // std::this_thread::sleep_for(std::chrono::seconds(5)); //无 std::cout << \"加法!!2222\\n\"; return num1 + num2;}int main(){ std::cout << \"--------1----------\\n\"; std::future<int> result = std::async(Add, 11, 22); // 派线程去执行并把结果保存到result里(但是不能保证访问这个函数是异步安全的,) std::this_thread::sleep_for(std::chrono::seconds(1)); // 主线程休眠 std::cout << \"--------2----------\\n\"; int sum = result.get(); // 主线程阻塞式等待 std::cout << \"--------3----------\\n\"; std::cout << sum << std::endl;测试效果:
async选项:
- 派线程去执行并把结果保存到result里(但是不能保证访问这个函数是异步安全的)。
代码如下:
#include #include #include #include int Add(int num1, int num2){ std::cout << \"加法!!1111\\n\"; std::this_thread::sleep_for(std::chrono::seconds(5)); //无 std::cout << \"加法!!2222\\n\"; return num1 + num2;}int main(){ ////// async: 可以发现这个函数是立刻被执行而不是等到调用get的时候 std::cout << \"--------1----------\\n\"; std::future<int> result = std::async(std::launch::async, Add, 11, 22); // 派异步线程去执行并把结果保存到result里,立刻执行 std::this_thread::sleep_for(std::chrono::seconds(2)); // 主线程休眠 std::cout << \"--------2----------\\n\"; int sum = result.get(); // std::cout << \"--------3----------\\n\"; std::cout << sum << std::endl;测试效果:

- 异步进行符合预期。
deferred选项:
- 保存起这个任务到result里面,等到外界调用get才去执行,也就是这个异步线程只有主线程get后才去执行任务。
测试代码:
#include #include #include #include int Add(int num1, int num2){ std::cout << \"加法!!1111\\n\"; std::this_thread::sleep_for(std::chrono::seconds(5)); //无 std::cout << \"加法!!2222\\n\"; return num1 + num2;}int main(){ ////deferred: std::cout << \"--------1----------\\n\"; std::future<int> result = std::async(std::launch::deferred, Add, 11, 22); // 保存起这个任务到result里面,等到外界调用get才去执行 std::this_thread::sleep_for(std::chrono::seconds(1)); // 主线程休眠 std::cout << \"--------2----------\\n\"; int sum = result.get(); // 主线程阻塞式等待 std::cout << \"--------3----------\\n\"; std::cout << sum << std::endl; return 0;}测试效果:

- 符合预期。
2.与 std::promise 配合使用
作用: 手动设置一个值,让其他线程或代码通过 std::future 获取这个值。
用法:
- 创建一个
std::promise对象。 - 通过
promise.set_value(值)设置结果。 - 用
promise.get_future()得到关联的std::future,之后用future.get()获取值。
适用场景: 当你在一个线程中计算或得到某个值,想手动“传递”给另一个线程时用。
也就是说让一个future的对象保存promise对象未来的值,然后promise对象只要设置了后,就能被future对象get到。
测试代码:
#include #include #include // 通过在线程中对promise对象设置数据,其他线程中通过future获取设置数据的方式实现获取异步任务执行结果的功能void Add(int num1, int num2, std::promise<int> &prom){ std::this_thread::sleep_for(std::chrono::seconds(3)); prom.set_value(num1 + num2);//设置对应的值方便fu提取 return;}int main(){ //操作: fu里面保存prom里面设置的值,到时候fu调用get如果prom还没设置就等待,设置完就得到! std::promise<int> prom; std::future<int> fu = prom.get_future(); std::thread thr(Add, 11, 22, std::ref(prom)); //把prom传递进去,方便设置对应的值 (以引用方式穿进去,保证后续的正确性) int res = fu.get();//主线程阻塞,等待子线程完成任务 std::cout << \"sum: \" << res << std::endl; thr.join(); return 0;}测试效果:

- 可以发现是被设置完成之后才能get到对应的值。
3.与 std::packaged_task 配合使用
作用: 把一个函数打包成一个任务,异步执行后通过 std::future 获取返回值。
用法:
- 把某个函数(比如普通函数、lambda)包装进
std::packaged_task。 - 调用
packaged_task(参数)执行任务,并通过get_future()得到std::future。 - 之后用
future.get()获取返回值。
适用场景: 想把某个函数变成可异步调用的“任务”,并获取其结果时用。
同样,这里是把对应的函数封装成task对象,然后能直接调用,还是通过future对象获得结果。
但是这样需要注意,如果传递的是线程执行(线程执行的是函数,因此需要把task封装成lamda等)。
测试代码:
#include #include #include #include //pakcaged_task的使用// pakcaged_task 是一个模板类,实例化的对象可以对一个函数进行二次封装,//pakcaged_task可以通过get_future获取一个future对象,来获取封装的这个函数的异步执行结果 -->只是可调用对象不嫩当做普通函数使用int Add(int num1, int num2) { std::this_thread::sleep_for(std::chrono::seconds(3)); return num1 + num2;}int main(){ std::packaged_task<int(int,int)> pt(Add); std::future<int> f= pt.get_future(); pt(1,2);//派异步线程去执行 std::cout<<f.get()<<std::endl; //但是不能直接当成函数传给线程,只能封装: auto ptask =std::make_shared<std::packaged_task<int(int,int)>> (Add); std::future<int> ff= ptask->get_future(); // std::thread t((*(Add))(1,1)); std::thread t([ptask](){ (*ptask)(1,2);//类似穿了个普通函数然后调用的可调用对象 }); std::cout<<ff.get()<<std::endl; t.join(); return 0;}测试效果:

- 符合预期,但是如果把这个task对象直接传给线程呢?
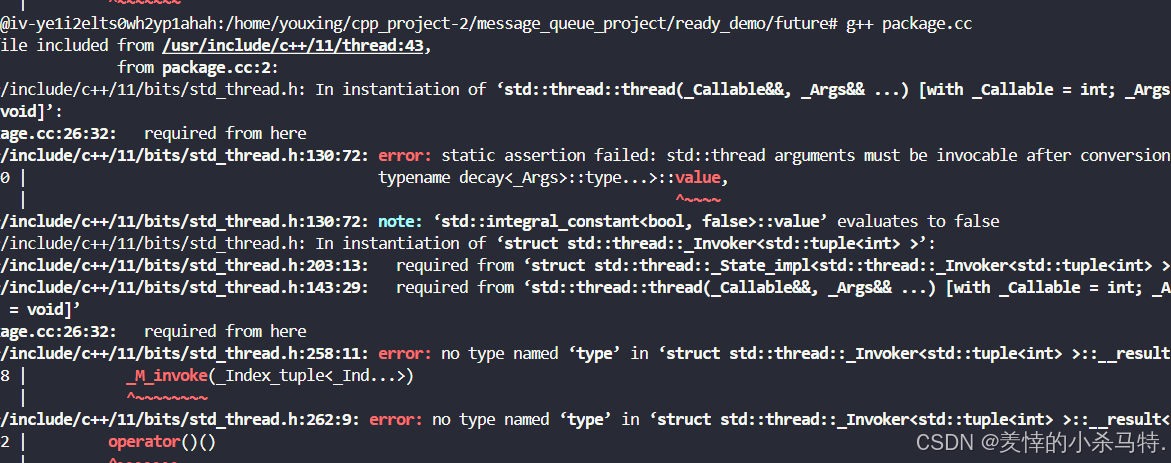
- 发现这里是不允许的,因此需要封装一下。
总结一句话:
std::future 就像一张“取货单”,你可以用它从别的地方(比如另一个线程)取回一个结果,具体怎么“送货”有三种方式:std::async(自动送)、std::promise(手动送)、std::packaged_task(把函数打包送)。
4.基于future的packaged_task的用法实现多参线程池
实现要点:
- 多线程基于互斥锁与条件变量的帮助下实现同步从任务队列提取任务。
- 基于
future的packaged_task的用法以及decltype实现任务push操作。 - 执行任务的时候,一个线程进入后把所有任务都拿走,然后解锁去执行自己的任务(采取数组
swap方法+线程局部存储的应用来实现)。 - 其他详细见代码。
操作流程:
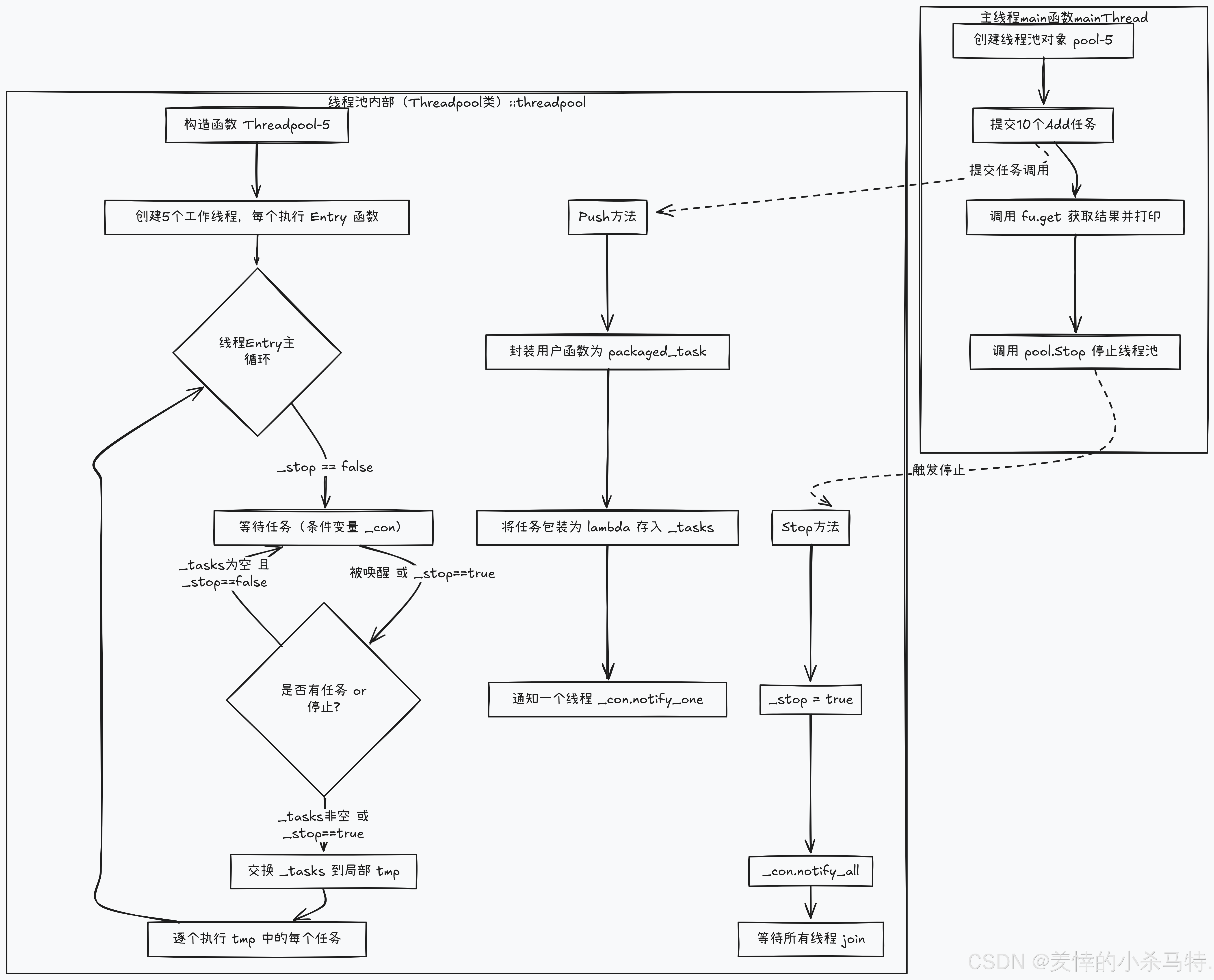
代码实现:
#include #include #include #include #include #include #include #include #include class Threadpool{public: using func = std::function<void(void)>; void Stop() // 如果外界直接调用stop,还会进行析构就会出问题需要避免 { if (_stop == true) // 可以保证里面线程安全 return; _stop = true; _con.notify_all(); for (auto &thread : _threads) { thread.join(); } } Threadpool(int thr_count = 1) : _stop(false) { for (int i = 0; i < thr_count; i++) { _threads.emplace_back(&Threadpool::Entry, this); } } ~Threadpool() { Stop(); } template <typename pfunc, typename... Args> //自动推导类型保证完美转发的成功 auto Push(pfunc &&pf, Args && ... args) -> std::future<decltype(pf(args...))> { auto bind_task = std::bind(std::forward<pfunc>(pf), std::forward< Args>(args)...); using re_type = decltype(pf(args...)); auto ptask = std::make_shared<std::packaged_task<re_type(void)>>(bind_task); std::future<re_type> fu = ptask->get_future();//保存对应的可调用对象调用完后的返回值 { std::unique_lock<std::mutex> lock(_mutex); _tasks.push_back([ptask]() { (*ptask)(); }); _con.notify_one(); } return fu; }private: void Entry() { //这里让每个线程全部取出当前任务数组的任务去执行(无论多少全部取完) while (!_stop) { std::vector<func> tmp;//这里是个声明 { std::unique_lock<std::mutex> lock(_mutex); _con.wait(lock, [this]() { return _stop || !_tasks.empty(); }); tmp.swap(_tasks);//交换后,当线程1在进行对应任务的时候,放入进_tasks任务不会落空 } //因为tmp是线程局部存储,所以多线程遍历的时候不会出问题,拿到的都是自己的! for (auto task : tmp) { task(); } } } std::atomic<bool> _stop; std::mutex _mutex; std::condition_variable _con; std::vector<func> _tasks; std::vector<std::thread> _threads;};int Add(int num1, int num2){ return num1 + num2;}int main(){ Threadpool pool(5); for (int i = 0; i < 10; i++) { std::future<int> fu = pool.Push(Add, 11, i); std::cout << fu.get() << std::endl; } pool.Stop(); return 0;}简单测试:
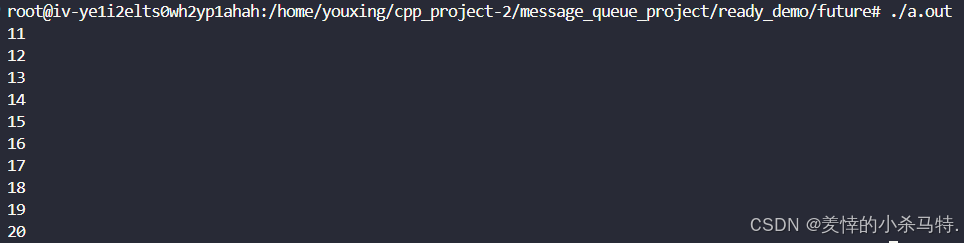
- 十个线程放出去执行加法任务,符合预期。
六.关于项目通用类的设计
1·字符串分割操作
因为在进行路由是否匹配过程需要:
如下:
class Split{public: static size_t split(std::string s, std::string sep, std::vector<std::string> &res) { int idx = 0, pos = 0; while (idx < s.size()) { pos = s.find(sep.c_str(), idx); // 如果找不到就是到头了: if (pos == std::string::npos) { res.push_back(s.substr(idx)); break; } else { // 防止找到重复的sep,并跳过sep长度 if (pos == idx) { idx = pos + sep.size(); continue; } else { res.push_back(s.substr(idx, pos - idx)); idx = pos + sep.size(); } } } return res.size(); }};2.UUID生成
- 定义与组成:UUID(Universally Unique Identifier),即通用唯一识别码,通常由32位16进制数字字符组成。
- 标准型式:标准形式包含32个16进制数字字符,以连字号分为五段,形式为8 - 4 - 4 - 4 - 12的32个字符,例如550e8400 - e29b - 41d4 - a716 - 446655440000。
- 生成方式及目的:通过生成8个随机数字(十六进制则十六个)和8字节序号(共16字节数组)来生成32位16进制字符组合形式,既确保全局唯一,又能够根据序号分辨数据。
- 这里我们采取C++相关生成库和对应IO流完成,详细见代码:
代码生成:
class Uuid{public: static std::string uuid() { std::random_device r; // 生成一个机器随机数,效率较低 std::mt19937_64 mt(r()); // 通过梅森旋转算法,生成一个伪随机数(把种子穿进去) std::uniform_int_distribution<int> d(0, 255); // 把随机数区间确定 std::stringstream ss; // 进行前16个数生成 for (int i = 0; i <= 7; i++) { ss << std::setw(2) << std::setfill(\'0\') << std::hex << d(mt); if (i == 3 || i == 5 || i == 7) { ss << \"-\"; } } //统计个数:十六进制: static std::atomic<size_t> cnt (1);//保证原子性 线程安全 64位;也就是16个16进制 size_t num = cnt.fetch_add(1); for (int i = 7; i >= 0; i--) { //0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 1000 0001--->这里采取每次取前八位转成16进制形式。 ss << std::setw(2) << std::setfill(\'0\') << std::hex << ((num >> (i * 8)) & 0xff); if (i == 6) ss << \"-\"; } return ss.str(); }};3.文件操作
对应接口功能: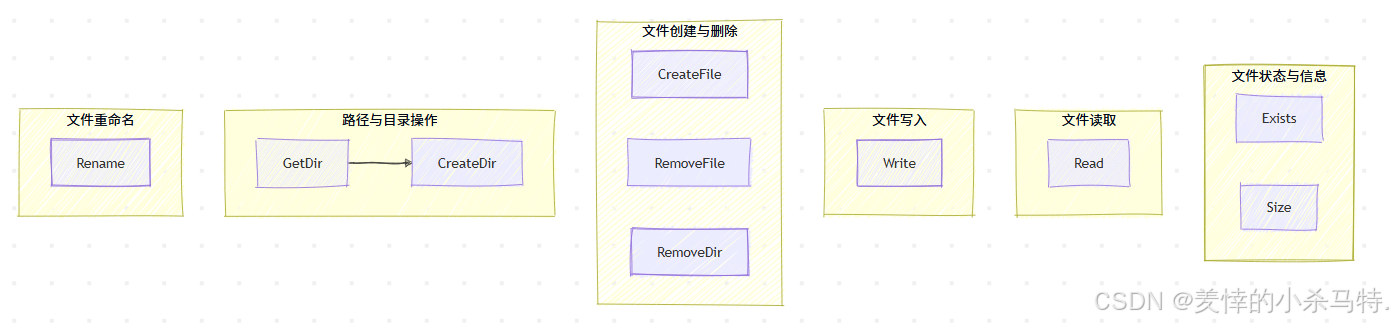
代码实现:
class File{ public: File(std::string name) : _file(name) {} bool Exists() { //既能判断目录又能判断文件 struct stat st; return (stat(_file.c_str(), &st) == 0); } size_t Size() { struct stat st; int ret = stat(_file.c_str(), &st); if (ret < 0) { return 0; } return st.st_size; } bool Read(char *buff, size_t offset, size_t num) { std::ifstream ifs; ifs.open(_file, std::ios::binary | std::ios::in); if (ifs.is_open() == false) { Elog(\"%s 文件打开失败!\", _file.c_str()); return false; } ifs.seekg(offset, std::ios::beg); ifs.read(buff, num); if (ifs.good() == false) { Elog(\"%s 文件读取数据失败!!\", _file.c_str()); ifs.close(); return false; } ifs.close(); return true; } // 一口气全部读出 bool Read(std::string &buff) { size_t size = this->Size(); // 及时更新buff对应的尺寸: buff.resize(size); return Read(&buff[0], 0, size); } bool Write(const char *buff, size_t offset, size_t num) { std::fstream ios;//偏移文件指针必须有读权限 ios.open(_file, std::ios::binary | std::ios::in | std::ios::out); if (ios.is_open() == false) { Elog(\"%s 文件打开失败!\", _file.c_str()); return false; } ios.seekp(offset, std::ios::beg); ios.write(buff, num); if (ios.good() == false) { Elog(\"%s 文件写入数据失败!!\", _file.c_str()); ios.close(); return false; } ios.close(); return true; } bool Write(const std::string &buff) { return Write(buff.c_str(), 0, buff.size()); } static bool CreateFile(const std::string name) { std::fstream ios; ios.open(name.c_str(), std::ios::binary | std::ios::out); if (ios.is_open() == false) { Elog(\"%s 文件打开失败!\", name.c_str()); return false; } ios.close(); return true; } static std::string GetDir(const std::string &filename) { // /aaa/bb/ccc/ddd/test.txt size_t pos = filename.find_last_of(\"/\"); if (pos == std::string::npos) { // test.txt return \"./\"; } std::string path = filename.substr(0, pos); return path; } static bool CreateDir(const std::string &path) // /aa/bb/ccc/ddd { size_t idx=0, pos = 0; while (idx < path.size()) { pos = path.find(\'/\', idx); // 找到最后一个了: if (pos == std::string::npos) { return (mkdir(path.c_str(), 0775) == 0); } std::string tmp = path.substr(0, pos); int ret = mkdir(tmp.c_str(), 0775); // 有可能当前目录存在,此时ret也返回非0,但是error会被标记EEXIST if (!ret && errno != EEXIST) { Elog(\"创建目录 %s 失败: %s\", path.c_str(), strerror(errno)); return false; } idx = pos + 1; } return true; } bool Rename(const std::string &nname) { return (::rename(_file.c_str(), nname.c_str()) == 0); } static bool RemoveFile(const std::string &filename) { return (::remove(filename.c_str()) == 0); } static bool RemoveDir(const std::string dir) { const std::string s = \"rm -rf \" + dir; return (system(s.c_str()) != -1); }private: std::string _file; // 传入完整文件名字};4·SQlite3相关操作
之前封装过,这里就不再多拿了。
七.本篇小结
本篇介绍了基于消息队列实现的时候用到的四个库,和一些新知识,通过对他们的基本了解,大致工作流程,已经有了一定认识,下篇就开始来正式实现仿RabbitMQ实现消息队列。


