用 Python 调用 Bright Data MCP Server:在 VS Code 中实现实时网页数据抓取


用 Python 调用 Bright Data MCP Server:在 VS Code 中实现实时网页数据抓取,本文介绍了Bright Data的Web MCP Server,这是一款能实现实时、结构化网页数据访问的API,适用于AI应用等场景。其支持静态与动态网页,前3个月每月提供5000次免费请求,有远程托管和本地部署两种方式。文章以在VS Code中用Python调用其API抓取Google搜索结果为例,详解了准备工作、代码编写、参数说明等实战流程,还提及该工具免维护代理池等技术亮点及使用限制。

一、引言:为什么AI时代需要高效的网页数据访问工具?
在大语言模型(LLM)和智能代理(Agent)快速发展的今天,\"实时性\"成为AI应用落地的关键瓶颈。想象一下:当你的AI助手需要回答\"今天上海的天气预警\"或\"某款产品的最新用户评价\"时,它必须依赖实时网页数据才能给出准确答案——而静态的训练数据根本无法满足这类需求。
传统方案却始终绕不开两个痛点:
- 自建爬虫需要维护代理池、处理验证码、应对网站反爬策略,成本高且稳定性差;
- 动态网页(如JavaScript渲染的内容)难以抓取,普通API往往返回不完整的\"壳数据\"。
Bright Data的Web MCP Server(Model Context Protocol Server)正是为解决这些问题而生:它提供\"即插即用\"的网页数据访问能力,让开发者无需关注爬虫底层细节,只需调用API就能获取结构化的实时数据,尤其适合AI应用、智能代理和自动化工作流。
二、Bright Data MCP Server简介:开发者需要知道的核心信息
2.1 什么是MCP Server?
MCP Server是Bright Data推出的网页数据访问API,支持静态网页和动态网页的数据抓取。无论是Google搜索结果、LinkedIn职位信息,还是需要JavaScript渲染的交互式页面,都能通过简单的API调用获取结构化数据。
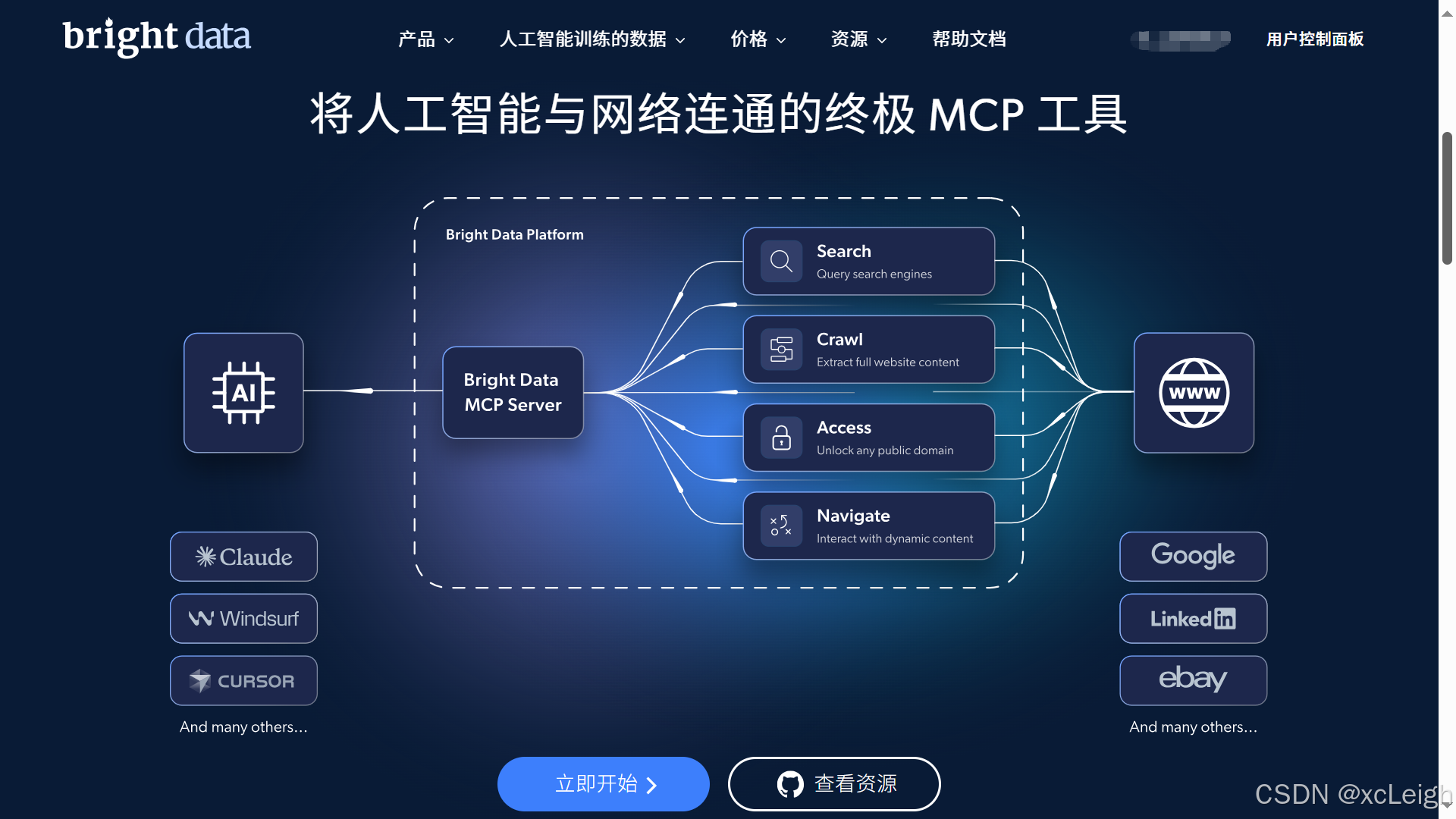
Bright Data MCP 以一站式解决方案助力 AI 模型与代理实时高效获取公共 Web 数据,无论是静态文本还是动态加载内容均可精准抓取,无需开发者自建复杂爬虫架构或攻克反爬技术壁垒,通过集成化的技术架构与智能调度系统,让 AI 轻松突破数据获取技术瓶颈
√ 即插即用零代码部署:标准化接口设计,无需搭建复杂爬虫框架或编写反反爬代码,通过简单配置即可接入全球网页数据源
√ 动态数据全链路解析:针对现代网页普遍采用 JavaScript 渲染、动态加载技术,MCP 内置智能解析引擎,自动识别页面元素变化规律,精准抓取实时价格、评论更新等动态内容
√ 超规模稳定网络支撑:依托 7200 万个 IP、覆盖 195 个国家的商用代理网络,MCP 可实现每秒 17 万次请求的高并发采集,每日处理 1PB 级网络流量,同时保持 99.99% 的系统可用性
√ 合规安全智能防护:通过内置 AI 反指纹技术,MCP 自动模拟真实用户行为,规避网站反爬机制;数据传输全程采用 TLS 加密,严格遵循 GDPR、CCPA 等国际数据法规,为企业数据安全与合规运营提供双重保障
2.2 核心优势
- 免维护底层:自带代理池、自动解锁地理限制、处理验证码和JavaScript渲染,开发者无需关心反爬细节;
- 灵活部署:支持远程托管(推荐新手)和本地部署(适合高级定制);
- 多模式支持:可通过URL参数控制行为(如
unlocker解锁限制、browser启用浏览器渲染),支持SSE(Server-Sent Events)和标准HTTP请求; - 工具集成友好:无缝对接Python、LangChain、n8n等主流开发工具和自动化平台。
2.3 免费额度
对于开发者来说,最具吸引力的是其免费政策:前3个月每月提供5000次免费请求,足够满足开发测试和轻量级应用需求。
三、实战:在VS Code中用Python调用MCP API抓取Google搜索结果
下面以\"实时抓取Google搜索结果\"为例,详解在VS Code中使用Python调用MCP Server的完整流程。
3.1 准备工作
-
注册Bright Data账号并获取API Token
访问Bright Data MCP Server官方页面,登录后在控制台创建MCP项目,获取API Token(类似abc123...的字符串)。
-
配置开发环境
- 确保已安装Python 3.8+和VS Code;
- 安装必要库(
requests用于HTTP请求):
在VS Code终端执行:pip install requests
3.2 步骤1:编写Python代码(核心逻辑)
在VS Code中新建mcp_google_demo.py文件,代码如下(含详细注释):
import requestsimport json# 1. 配置基础参数API_TOKEN = \"你的API Token\" # 替换为实际TokenMCP_ENDPOINT = \"https://mcp.brightdata.com\" # 远程托管端点SEARCH_QUERY = \"2025年AI行业趋势\" # 要搜索的关键词# 2. 构造API请求参数params = { \"token\": API_TOKEN, \"url\": f\"https://www.google.com/search?q={SEARCH_QUERY}\", \"browser\": \"true\", # 启用浏览器渲染(处理动态内容) \"unlocker\": \"true\", # 自动解锁地理限制和反爬 \"format\": \"json\" # 指定返回格式为JSON}# 3. 发送请求并获取响应try: response = requests.get(MCP_ENDPOINT, params=params) response.raise_for_status() # 检查请求是否成功 result = response.json() # 解析JSON响应 # 4. 处理并打印结果 print(\"Google搜索结果抓取成功:\") # 提取前3条结果(标题、链接、摘要) for i, item in enumerate(result.get(\"organic_results\", [])[:3]): print(f\"\\n结果{i+1}:\") print(f\"标题:{item.get(\'title\')}\") print(f\"链接:{item.get(\'url\')}\") print(f\"摘要:{item.get(\'snippet\')}\")except requests.exceptions.RequestException as e: print(f\"请求失败:{e}\")except json.JSONDecodeError: print(\"响应格式错误,无法解析为JSON\")3.3 步骤2:关键参数说明
token:必填,用于身份验证的API Token;url:目标网页URL(此处为Google搜索链接,含关键词);browser=\"true\":启用无头浏览器渲染,确保动态加载的内容(如Google的异步搜索结果)被完整抓取;unlocker=\"true\":自动绕过Google的反爬限制(如IP封锁、地区限制)。
3.4 步骤3:运行代码并查看结果
在VS Code终端执行:
python mcp_google_demo.py成功运行后,将输出类似以下的结构化结果(JSON格式示例):
{ \"organic_results\": [ { \"title\": \"2025年AI行业发展趋势报告 - 科技智库\", \"url\": \"https://test.com/ai-trends-2025\", \"snippet\": \"2025年AI将在自动驾驶、医疗诊断等地方实现规模化落地,生成式AI市场规模预计突破千亿...\" }, // 更多结果... ], \"total_results\": 1280000, \"processed_at\": \"2025-08-18T10:30:00Z\"}3.5 处理动态网页的核心逻辑
对于需要JavaScript渲染的页面(如Google搜索结果、LinkedIn动态),MCP Server通过browser=\"true\"参数启用远程浏览器环境,模拟真实用户浏览行为:
- 自动执行页面JavaScript;
- 等待动态内容加载完成后再抓取;
- 避免被网站识别为爬虫(通过模拟真实设备指纹、浏览器特征)。
四、技术亮点:为什么MCP Server适合开发者?
-
零维护成本
无需自建代理池、处理验证码或更新反爬策略,MCP Server的底层基础设施会自动适配网站变化。 -
高度可扩展
支持从单条请求到每秒数千次的大规模抓取,无需担心服务器压力。 -
无缝集成自动化工具
除了Python,还可与n8n(定时任务)、LangChain(AI Agent)等工具结合,例如:- 用n8n+MCP实现\"每小时抓取行业新闻\"的自动化流程;
- 结合LangChain构建\"实时网页问答Agent\",让LLM能直接调用MCP获取最新信息。
-
灵活控制抓取行为
通过URL参数调整模式:pro=1:启用高级模式(更精准的动态内容处理);geo:指定地理位置(如geo=us获取美国地区数据)。
五、使用建议与限制说明
- 免费额度范围:前3个月每月5000次请求,适合开发测试;团队账号的免费额度为多用户共享。
- 付费说明:超出免费额度或使用
mcp_browser等高级功能会产生费用,具体可参考官方定价。 - 合规性:仅支持抓取公共领域数据,需遵守目标网站的robots协议和相关法律法规。
六、在线体验
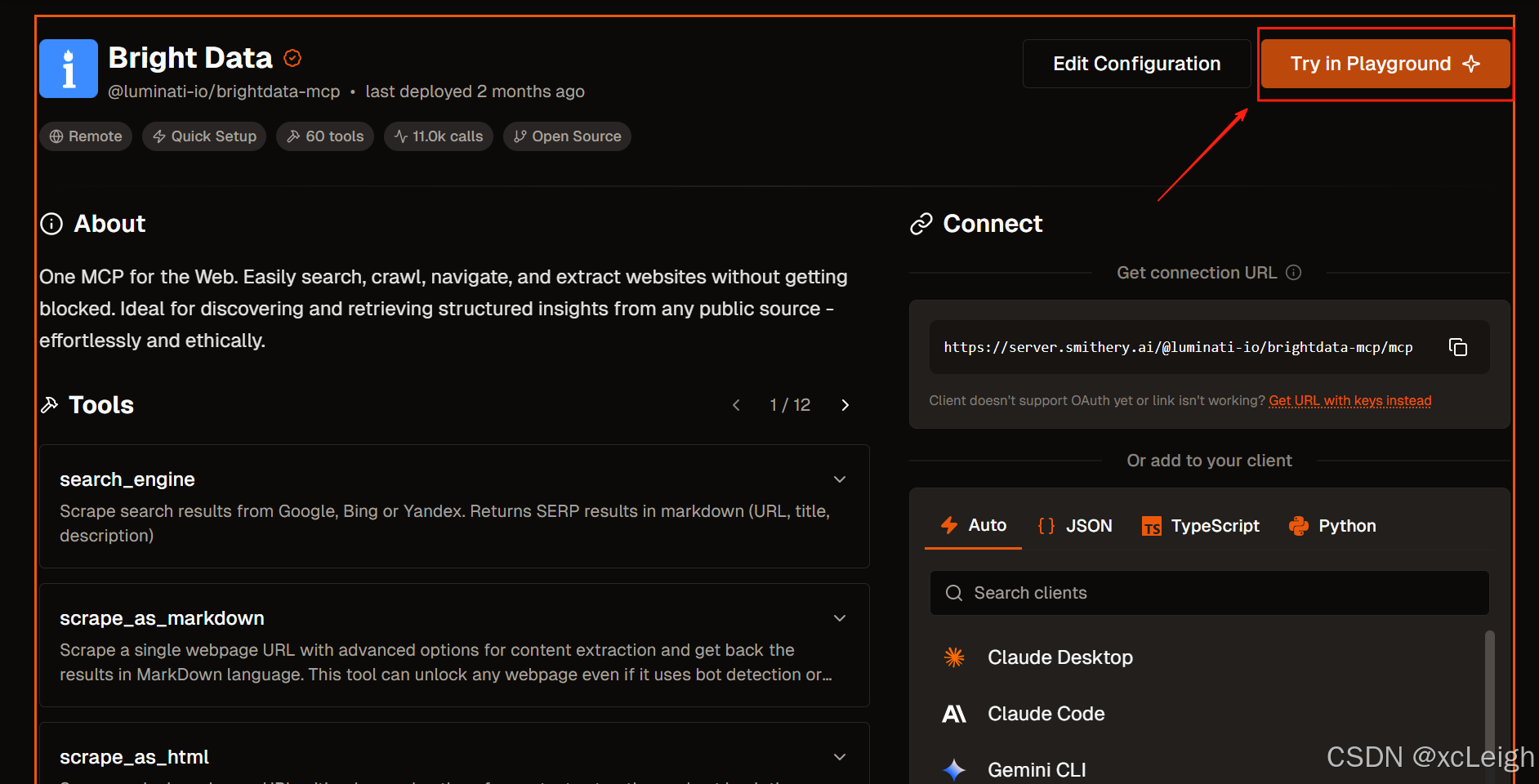
进入演示环境后,在界面中找到 “Try in Playground” 按钮并点击,进入到实际操作的 playground 区域。

在 playground 里,能看到多种工具选项,像 search_engine(可从谷歌、必应等搜索引擎抓取结果)、scrape_as_markdown(抓取单网页并以 Markdown 格式返回内容)、scrape_as_html(抓取单网页并以 HTML 格式返回内容)等。根据抓取亚马逊商品数据的需求,选择合适的工具。
在输入框中输入类似 “帮我抓取亚马逊商品折扣价大的衣服” 这样的请求。此时,助手会进一步询问你关注的亚马逊站点(如美国、英国等)、具体服装类型(如男装、女装等)以及是否有价格区间或品牌偏好等信息。
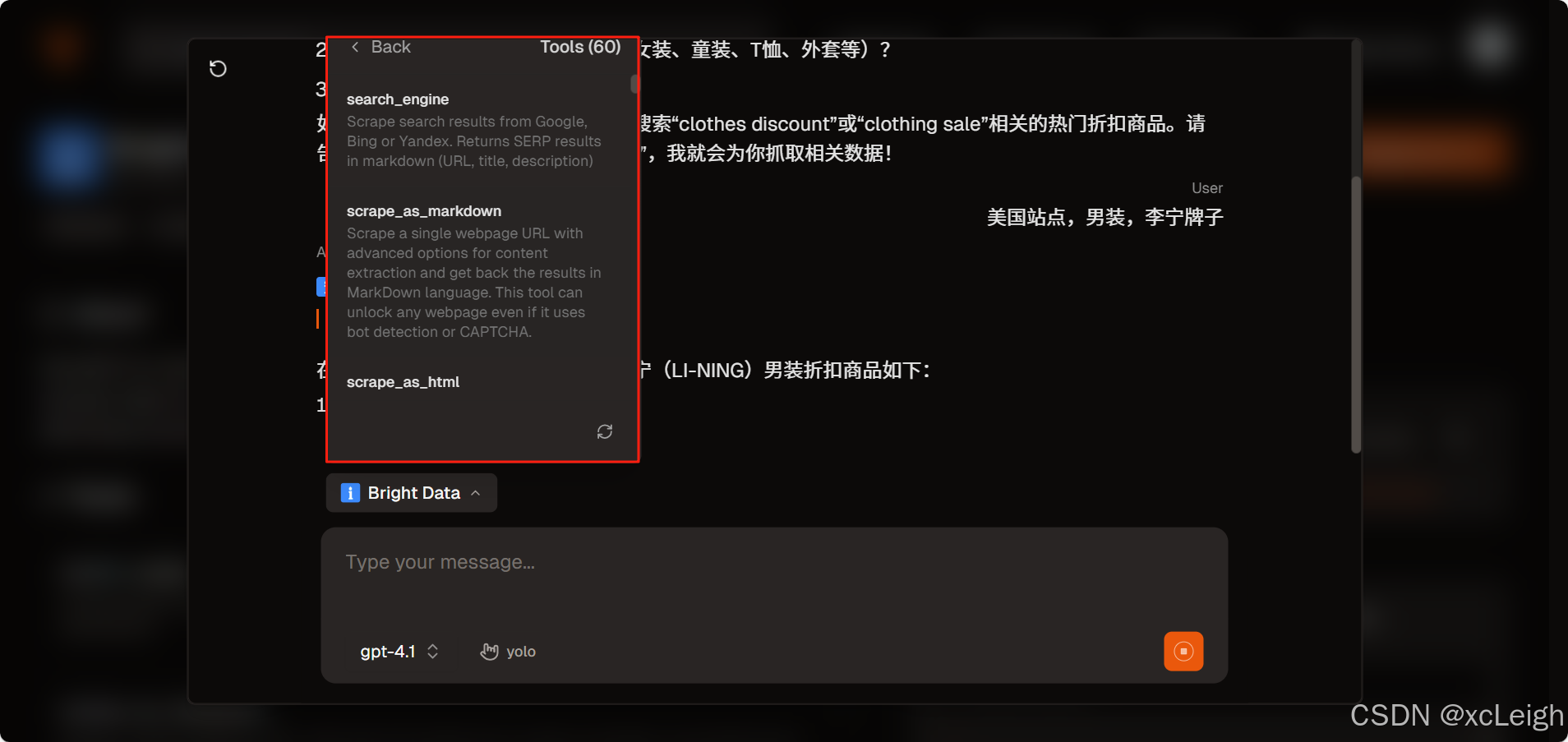
以抓取美国站点李宁男装折扣商品为例,在你提供相关信息后,Bright Data 会快速为你返回抓取到的商品数据,包括商品名称、价格、配送信息等内容,还会给出一些相关建议,比如关注促销活动页面或尝试其他电商平台获取更多信息。


七、立即尝试:获取你的免费额度
访问 Bright Data MCP Server,通过专属链接注册即可享受3个月免费额度(每月5000次请求)。无论是构建AI智能体、开发自动化工具,还是搭建数据管道,MCP Server都能帮你快速实现实时网页数据访问。

👆 快来领取你的武功秘籍!点击领取 Bright Data MCP 服务器,送你每月免费额度!
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌


