【百度拥抱开源】百度真的把文心一言开源了哦!一口气开源 10 个模型

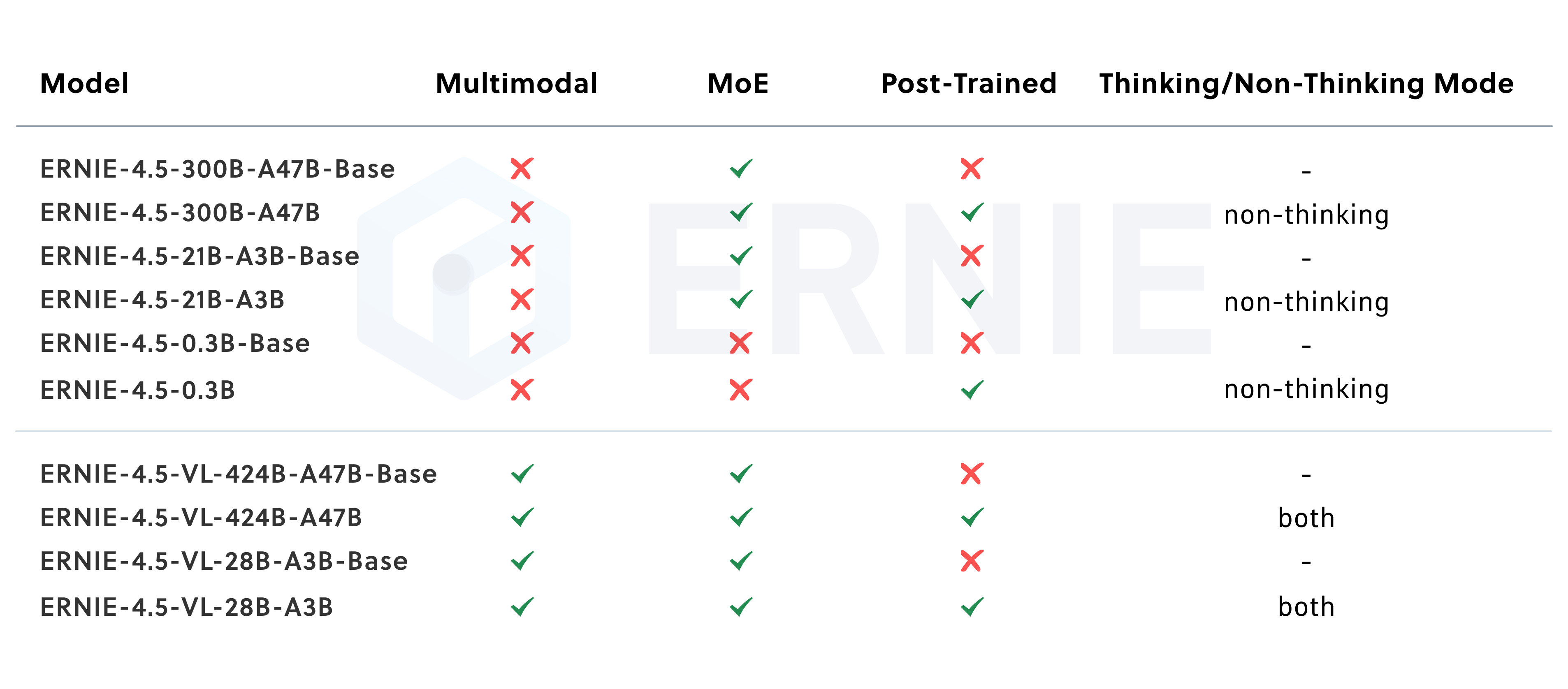
百度于2025年6月30日正式开源了其文心大模型4.5系列,推出了10款不同的模型。这一系列模型的参数范围从47B的混合专家(MoE)模型到轻量级的0.3B稠密型模型,涵盖了文本和多模态任务,标志着百度在AI领域的一次重大转变。
而且模型不仅有开源标准的Pytorch模型,还有百度自研的PaddlePaddle模型(支持国产显卡适配)。
文心大模型4.5版本(尤其是基于混合专家系统的A47B和A3B系列)的先进能力,源于以下核心技术创新:
-
多模态异构混合专家预训练:我们的模型通过文本与视觉模态联合训练,以更精准捕捉跨模态信息细微差异,提升文本理解生成、图像理解及跨模态推理任务的性能。为避免模态间学习相互干扰,我们设计了异构混合专家架构,引入模态隔离路由机制,并采用路由正交损失与多模态令牌平衡损失。这些创新结构确保双模态高效表征,实现训练过程中的协同增强效果。
-
高效扩展的基础设施:我们提出了一种新颖的异构混合并行与分层负载均衡策略,用于高效训练ERNIE 4.5模型。通过采用节点内专家并行、内存优化的流水线调度、FP8混合精度训练以及细粒度重计算技术,我们实现了卓越的预训练吞吐量。在推理方面,我们提出多专家并行协作方法与卷积编码量化算法,实现了4比特/2比特无损量化。此外,我们引入具有动态角色切换的PD解耦技术,以提升ERNIE 4.5 MoE模型的资源利用率和推理性能。基于PaddlePaddle框架,ERNIE 4.5能在广泛的硬件平台上提供高性能推理服务。
-
特定模态的后训练:为了满足实际应用中的多样化需求,我们对预训练模型的不同变体进行了特定模态的微调。我们的LLM针对通用语言理解和生成进行了优化,而VLM则专注于视觉语言理解,并支持思维模式和非思维模式。每个模型在后训练阶段均采用了监督微调(SFT)、直接偏好优化(DPO)或改进的强化学习方法——统一偏好优化(UPO)的组合策略。
这里我就简单介绍其中两个模型:ERNIE-4.5-21B-A3B-PT 和 ERNIE-4.5-VL-28B-A3B-PT
ERNIE-4.5-21B-A3B-PT
模型概述
ERNIE-4.5-21B-A3B 是一个文本混合专家(MoE)后训练模型,总参数量为210亿,每个token激活参数量为30亿。以下是模型配置详情:
快速入门
使用 transformers 库
注意:使用模型前,请确保已安装 transformers 库(版本需 4.50.0 或更高)
以下代码片段展示了如何根据给定输入内容使用模型生成文本。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = \"baidu/ERNIE-4.5-21B-A3B-PT\"# load the tokenizer and the modeltokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)# prepare the model inputprompt = \"Give me a short introduction to large language model.\"messages = [ {\"role\": \"user\", \"content\": prompt}]text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], add_special_tokens=False, return_tensors=\"pt\").to(model.device)# conduct text completiongenerated_ids = model.generate( model_inputs.input_ids, max_new_tokens=1024)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()# decode the generated idsgenerate_text = tokenizer.decode(output_ids, skip_special_tokens=True).strip(\"\\n\")print(\"generate_text:\", generate_text)vLLM 推理
vllm GitHub 仓库。纯 Python 构建。
vllm serve baidu/ERNIE-4.5-21B-A3B-PT --trust-remote-codeERNIE-4.5-VL-28B-A3B-PT
模型概述
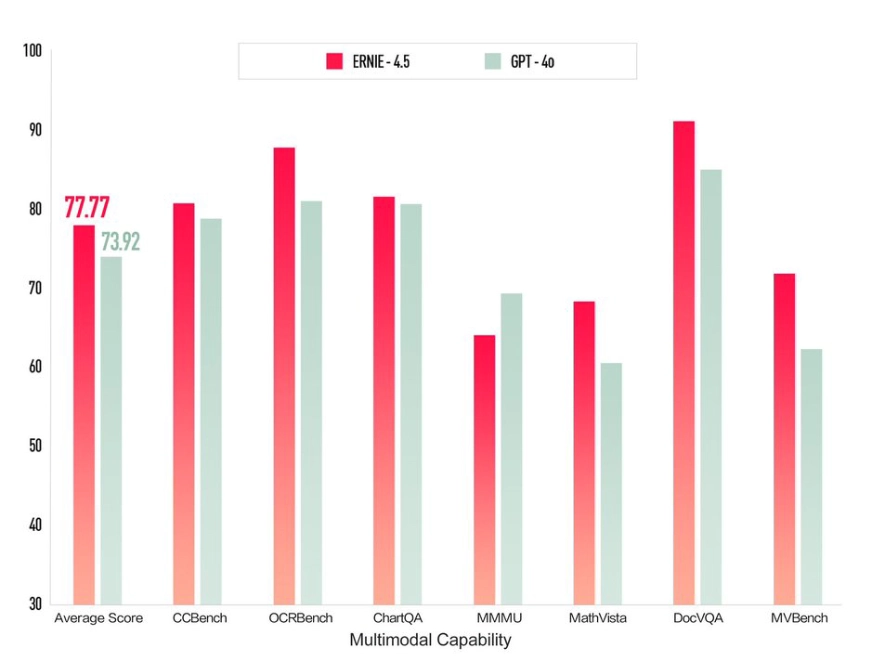
ERNIE-4.5-VL-28B-A3B是一款多模态MoE聊天模型,总参数量280亿,单token激活参数量30亿。以下是模型配置详情:
快速入门
使用 transformers 库
以下示例展示了如何使用transformers库进行推理:
import torchfrom transformers import AutoProcessor, AutoTokenizer, AutoModelForCausalLMmodel_path = \'baidu/ERNIE-4.5-VL-28B-A3B-PT\'model = AutoModelForCausalLM.from_pretrained( model_path, device_map=\"auto\", torch_dtype=torch.bfloat16, trust_remote_code=True)processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)processor.eval()model.add_image_preprocess(processor)messages = [ { \"role\": \"user\", \"content\": [ {\"type\": \"text\", \"text\": \"Describe the image.\"}, {\"type\": \"image_url\", \"image_url\": {\"url\": \"https://paddlenlp.bj.bcebos.com/datasets/paddlemix/demo_images/example1.jpg\"}}, ] },]text = processor.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False)image_inputs, video_inputs = processor.process_vision_info(messages)inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors=\"pt\",)device = next(model.parameters()).deviceinputs = inputs.to(device)generated_ids = model.generate( inputs=inputs[\'input_ids\'].to(device), **inputs, max_new_tokens=128 )output_text = processor.decode(generated_ids[0])print(output_text)vLLM推理
我们正与社区合作,以全面支持ERNIE4.5模型,敬请期待。


