AIGC时代算法工程师的面试秘籍(第三十五式2025.4.21-2025.5.4) |【三年面试五年模拟】
写在前面
【三年面试五年模拟】旨在挖掘&沉淀AIGC算法工程师在实习/校招/社招时所需的干货知识点与面试方法,力求让读者在获得心仪offer的同时,持续增强技术基本面。
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
Rocky最新撰写10万字Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章: https://zhuanlan.zhihu.com/p/684068402
AIGC算法岗/开发岗面试面经交流社群(涵盖AI绘画、AI视频、大模型、AI多模态、数字人等AIGC面试干货资源)欢迎大家加入:https://t.zsxq.com/33pJ0
文末更多干货技术福利与资源,欢迎大家查阅。
大家好,我是Rocky。
又到了定期学习《三年面试五年模拟》文章的时候了!本周期我们持续更新了丰富的AIGC面试高频问答,依旧干货满满!诚意满满!
Rocky创办的《三年面试五年模拟》项目在持续帮助很多读者获得了心仪的AIGC科技公司和互联网大厂的算法岗offer,收到了大家非常多的好评,Rocky觉得很开心也很有意义!
现在时间来到2025年,随着DeepSeek的横空出世,AIGC时代的科技浪潮破纪录达到了新高峰,AI行业对AIGC技术人才的需求也日益旺盛。
**为了帮助大家在2025年的实习、秋招、春招以及社招求职时更加从容和有所依靠,Rocky将《三年面试五年模拟》项目进行重大战略架构升级,并承诺《三年面试五年模拟》项目将陪伴大家和码二代们的整个职业生涯,为大家在AI行业中的求职招聘保驾护航!**详细内容大家可以阅读:
2025年,AIGC算法岗面试必备干货资源发布!
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的AIGC面试高频问答已经全部同步更新到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第三十五式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2025年4月21号-2025年5月4号更新的部分高频&干货面试知识点,并配以相应的参考答案(精简版),供大家学习探讨。点赞本文,并star咱们的Github项目,你就收获了半个offer!再转发本文,你就收获了0.75个offer!
So,enjoy:
正文开始
目录先行
AI行业招聘信息汇总
- 本期共有4大公司新展开AIGC/传统深度学习/自动驾驶算法岗位招聘!
AI绘画基础:
-
为什么VAE生成效果不好,但是VAE+Diffusion整体效果就很好?
-
GAN和Stable Diffusion有哪些差异?
AI视频基础:
-
什么是首尾帧生成视频大模型?
-
万相首尾帧模型(Wan2.1-FLF2V-14B)架构是什么样的?
深度学习基础:
-
AIGC时代主流的深度学习框架有哪些?各自有什么特点?
-
Caffe的depthwise为什么慢,该如何优化?Caffe新加一层需要哪些操作?
机器学习基础:
-
在机器学习中降维的方法都有哪些?
-
介绍一下机器学习中的朴素贝叶斯算法
Python编程基础:
-
Python中tuple、list和dict有什么区别?
-
Python中使用迭代器遍历和非迭代器遍历有什么区别?
模型部署基础:
- MACE框架和NCNN框架之间有什么区别?MACE和NCNN各自的加速原理是什么样的?
计算机基础:
- 介绍一下计算机中DOS攻击的概念
AI行业招聘信息汇总
- 滴滴2025春招开启:https://talent.didiglobal.com/
- 神州数码25届春招开启:https://digitalchina.com/aboutus/news/details623.html
- ITC 2025届春季校园招聘开启:https://hr.itc.vip/job/school.html
- 东方财富26届暑期实习开启:https://zhaopin.eastmoney.com/campus-recruitment/eastmoney/57971/#/
更多AIGC算法岗/开发岗面试干货资源,欢迎加入AIGC算法岗/开发岗求职社群(知识星球):https://t.zsxq.com/33pJ0
AI绘画基础
【一】为什么VAE生成效果不好,但是VAE+Diffusion整体效果就很好?
这个问题最本质的回答是:传统深度学习时代的VAE是单独作为生成模型;而在AIGC时代,VAE只是作为特征编码器,提供特征给Diffusion用于图像的生成。其实两者的本质作用已经发生改变。
同时传统深度学习时代的VAE的重构损失只使用了平方误差,而Stable Diffusion中的VAE使用了平方误差 + Perceptual损失 + 对抗损失。在正则项方面,传统深度学习时代的VAE使用了完整的KL散度项,而Stable Diffusion中的VAE使用了弱化的KL散度项。同时传统深度学习时代的VAE将图像压缩成单个向量,而Stable Diffusion中的VAE则将图像压缩成一个 N×M N\\times M N×M 的特征矩阵。
上述的差别都导致了传统深度学习时代的VAE生成效果不佳。
【二】GAN和Stable Diffusion有哪些差异?
GAN(生成对抗网络)和Stable Diffusion(稳定扩散模型)都是AIGC、传统深度学习、自动驾驶领域的核心模型之一,其核心差异体现在模型架构、训练机制、生成质量及应用场景等方面。以下是Rocky总结的详细对比:
1. 核心机制差异
2. 生成质量与多样性
-
GAN的局限性
- 多样性不足:易受训练数据分布限制,生成结果可能重复或缺乏创新(如StyleGAN生成人脸时细节固定)。
- 高分辨率挑战:生成大尺寸图像需复杂架构(如ProGAN逐层训练),资源消耗大。
- 可控性依赖潜在空间:通过调整潜在向量(如StyleGAN的W空间)控制生成,但语义编辑灵活性较低。
-
Stable Diffusion的优势
- 高保真与多样性:扩散过程允许生成更复杂、多样的图像(如复杂场景融合)。
- 文本条件生成:通过CLIP等模型将文本嵌入扩散过程,实现精准的文本到图像控制(如生成“戴墨镜的柯基”)。
- 分辨率扩展性:利用潜在空间(如64x64压缩)降低计算量,结合超分模型生成4K图像。
3. 架构与资源需求
4. 应用场景对比
-
GAN的适用场景
- 快速生成:实时应用(如游戏角色生成、滤镜效果)。
- 小数据集优化:在有限数据下(如医学图像)表现优于扩散模型。
- 特定领域:人脸生成(StyleGAN)、图像风格迁移(CycleGAN)。
-
Stable Diffusion的适用场景
- 复杂条件生成:文本到图像(DALL·E 3)、图像修复(Inpainting)。
- 高质量艺术创作:支持LoRA、ControlNet插件,细化控制构图与风格。
- 数据增强:生成合成数据集提升下游任务性能(如《Stable Diffusion for Data Augmentation》)。
AI视频基础
【一】什么是首尾帧生成视频大模型?
首帧和尾帧生成视频大模型(First-Last Frame to Video, FLF2V)是AI视频领域的核心技术之一,其核心目标是通过用户提供的起始帧和结束帧图像,自动生成中间过渡视频内容。这类AI视频大模型在影视制作、广告创意、游戏开发等地方具有广泛应用价值。
一、技术原理
-
条件控制与时空建模
- 首尾帧语义对齐:通过CLIP等视觉-语言模型提取首帧和尾帧的语义特征,利用交叉注意力机制(Cross-Attention)将特征注入扩散模型的生成过程,确保画面内容与输入图像的一致性。例如,阿里Wan2.1-FLF2V-14B通过首尾帧的CLIP特征引导生成中间帧,实现98%的画面匹配度。
- 运动轨迹预测:模型学习首尾帧之间的潜在运动规律,例如物体形变、镜头推拉等。采用时序扩散模型(Temporal Diffusion Model)结合运动轨迹预测的双支路架构,优化帧间连贯性,如Vidu Q1的“电影级运镜”功能。
-
高效压缩与潜在空间生成
- 3D因果变分自编码器(3D Causal VAE):如阿里Wan-VAE将1080P视频压缩至1/128尺寸,保留动态细节(如毛发颤动、水波纹理),降低显存占用。
- 扩散变换器(Diffusion Transformer, DiT):结合全注意力机制(Full Attention)和Flow Matching训练策略,生成高分辨率视频。例如,Wan2.1的DiT模块支持720P输出,并引入零初始化残差连接,避免干扰原始图像生成能力。
-
多模态条件融合
- 支持文本、音频等多模态输入,通过T5文本编码器或音频特征提取模块,增强生成内容的可控性。例如,Wan2.1可动态嵌入中英文字幕,Vidu Q1支持AI音效生成。
二、模型架构
-
核心组件
- 编码器:负责将输入图像压缩至低维潜在空间。例如,Ruyi的Casual VAE模块将时空分辨率分别压缩至1/4和1/8,采用BF16精度表示。
- 扩散生成模块:基于DiT架构,处理潜在空间序列。阿里Wan2.1的DiT结合3D RoPE位置编码,捕捉时空依赖;图森未来Ruyi的Diffusion Transformer通过运动幅度控制参数调节生成强度。
- 条件控制分支:专门处理首尾帧输入,如Wan2.1的FLF2V模块将首尾帧与噪声拼接,作为模型输入,并通过掩码机制分离控制信号与生成内容。
-
参数规模与训练策略
- 大参数量模型(如Wan2.1-FLF2V-14B)通过三阶段训练(低分辨率预训练→高分辨率微调→细节优化)提升性能;轻量级模型(如Ruyi-Mini-7B)采用混合并行策略适配消费级显卡。
- 训练数据:通常使用数百万至数亿视频片段,覆盖多场景、多风格。例如,Ruyi使用200M视频片段训练,Wan2.1结合WebVid-10M等数据集。
三、生成流程
-
输入处理
- 图像预处理:将首尾帧标准化为统一分辨率(如720P),分割为视频序列的首帧和尾帧,并通过插值或循环叠加扩展时长(如Ruyi支持最长5秒/120帧)。
- 语义特征提取:利用CLIP或ResNet提取图像特征,作为条件输入扩散模型。
-
潜在空间生成
- 噪声注入与去噪:在扩散过程中,模型逐步去除潜在空间中的噪声,同时结合首尾帧特征生成连贯帧序列。例如,Wan2.1通过50步迭代优化细节。
- 多帧并行生成:所有帧的潜在张量同时初始化,通过自注意力机制保证帧间一致性,避免闪烁问题。
-
解码与后处理
- 潜在空间解码:利用VAE解码器将潜在序列转换为像素空间视频帧。
- 超分辨率与插值:使用FILM算法或超分模型提升画质,如Vidu Q1支持1080P直出。
四、代表模型对比
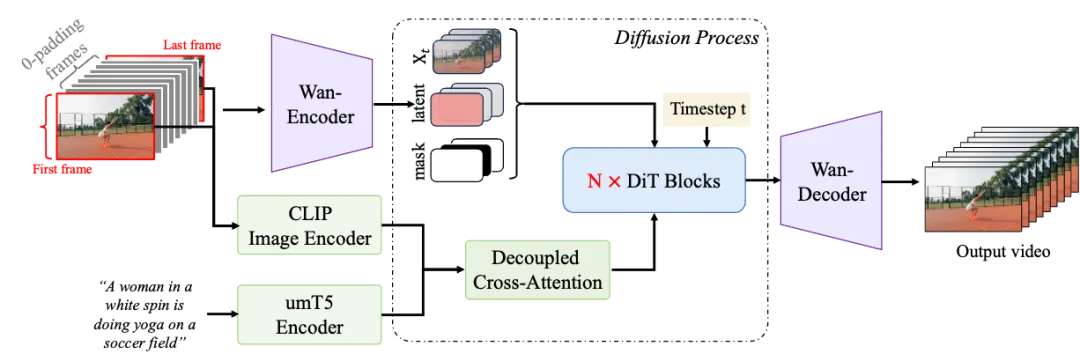
【二】万相首尾帧模型(Wan2.1-FLF2V-14B)架构是什么样的?
万相首尾帧大模型是一个百亿参数规模(14B)的首尾帧生视频大模型,其核心架构设计旨在实现高可控性、高质量的视频生成。
1. 核心架构:Diffusion in Time(DiT)
- 基础框架:基于扩散模型(Diffusion Model)与Transformer的融合架构,专为AI视频生成设计。DiT通过Full Attention机制捕捉视频的长时程时空依赖关系,确保生成视频在时间(帧间连贯性)和空间(画面细节一致性)上的高度统一。
2. 视频压缩VAE(变分自编码器)
- 功能:将输入视频压缩至低维潜在空间,减少计算复杂度。支持720p高清视频的无损压缩,压缩比达256倍。
- 创新设计:
- 因果性约束:在编码和解码过程中引入时间维度的因果性约束,防止信息泄漏,确保首尾帧与中间帧的逻辑连贯性。
3. 条件控制机制
- 首尾帧输入处理:用户提供的首帧和尾帧图像与若干零填充中间帧拼接,形成控制视频序列。该序列与噪声及掩码(Mask)拼接后,作为DiT的输入。
- 指令遵循:通过文本提示词(如“镜头移动”“特效变化”)控制生成内容,模型结合CLIP语义特征与交叉注意力机制动态调整生成细节。
4. 交叉注意力机制(Cross-Attention)
- 功能:将首尾帧的语义特征(通过CLIP编码器提取)注入DiT生成过程,强化条件控制。
- 实现方式:
- 首尾帧的CLIP特征与扩散模型的潜在特征进行注意力交互。
深度学习基础
【一】AIGC时代主流的深度学习框架有哪些?各自有什么特点?
主流深度学习框架的特点及行业应用分析

1. TensorFlow
特点:
- 灵活性与工业部署:支持静态图与动态图混合编程(Eager Execution),提供SavedModel格式实现跨平台部署(移动端、嵌入式设备)。
- 生态系统完善:集成TensorBoard可视化工具、TFX流水线工具,支持分布式训练和TPU加速。
- 多语言支持:核心为C++,上层API支持Python、Java等,适合大规模生产环境。
实际案例:
- 医疗影像分类:使用预训练的ResNet模型(TensorFlow Hub),在肺部CT图像中快速实现肺癌检测,准确率提升15%。
领域应用:
- AIGC:Stable Diffusion的底层优化中,利用TensorFlow Lite将模型压缩至移动端,实时生成高清图像。
- 传统深度学习:ImageNet图像分类任务中,通过Keras API快速构建InceptionV3模型。
- 自动驾驶:Waymo使用TensorFlow部署多传感器融合模型,实时处理激光雷达与摄像头数据。
2. PyTorch
特点:
- 动态计算图:支持即时调试,适合研究场景;Autograd机制简化反向传播实现。
- 社区与科研支持:学术界主流框架,提供TorchScript实现模型序列化,兼容ONNX格式。
- GPU加速优化:原生支持CUDA,混合精度训练效率提升30%。
实际案例:
- 自然语言处理:基于Transformer架构(Hugging Face库),训练GPT-3模型实现文本生成,参数量达1750亿。
领域应用:
- AIGC:Meta的Make-A-Video工具使用PyTorch动态图特性,实现文本到视频的跨模态生成。
- 传统深度学习:Fast.ai库简化图像分类任务,5行代码完成CIFAR-10数据集训练。
- 自动驾驶:特斯拉Autopilot采用PyTorch构建BEV(鸟瞰图)感知模型,优化多目标跟踪算法。
3. Keras
特点:
- 高层抽象与易用性:提供模块化API(如
Sequential和Functional),10分钟内可搭建完整神经网络。 - 多后端支持:兼容TensorFlow、Theano等,适合快速原型开发。
- 性能局限:过度封装导致灵活性不足,大规模训练速度较慢。
实际案例:
- 手写数字识别:通过MNIST数据集训练LeNet-5模型,代码量仅20行,准确率达99%。
领域应用:
- AIGC:快速试验生成对抗网络(GAN)结构,如DCGAN生成动漫头像。
- 传统深度学习:教育领域用于教学演示,如LSTM时间序列预测。
- 自动驾驶:小规模车载系统(如停车标志检测)的轻量级模型部署。
4. Caffe/Caffe2
特点:
- 高效与模块化:专精计算机视觉,模型Zoo提供预训练权重(如AlexNet、VGG)。
- 工业级优化:支持单GPU每日处理6000万张图像,延迟低至1ms/帧。
- 扩展性差:新增网络层需手动实现C++/CUDA代码,对RNN支持薄弱。
实际案例:
- 图像分类:2014年ImageNet冠军模型GoogLeNet基于Caffe实现。
领域应用:
- AIGC:较少使用,但在早期风格迁移(如Neural Style)中有应用。
- 传统深度学习:工业质检中快速部署ResNet进行缺陷检测。
- 自动驾驶:Mobileye使用Caffe2优化车载视觉模型,实现实时车道线识别。
5. MXNet
特点:
- 分布式性能:支持多GPU/多节点训练,内存占用优化(较TensorFlow减少20%)。
- 多语言接口:兼容Python、Scala、Julia,适合云平台(如AWS)。
- 文档不足:社区活跃度低,新手学习成本高。
实际案例:
- 推荐系统:亚马逊使用MXNet构建深度因子分解机(DeepFM),提升广告点击率预测精度。
领域应用:
- AIGC:结合Apache TVM编译器,优化Stable Diffusion推理速度。
- 传统深度学习:大规模NLP任务(如BERT预训练)的分布式加速。
- 自动驾驶:百度Apollo早期版本采用MXNet处理高精地图生成。
6. 其他框架
- PaddlePaddle:百度开发的国产框架,侧重工业落地,支持模型压缩(如PaddleSlim)。
- JAX:谷歌科研框架,基于自动微分和XLA编译器,适合高性能计算(如AlphaFold)。
总结:框架选择建议
- 科研与快速迭代:优先选择PyTorch(动态图+社区资源)。
- 工业部署与跨平台:TensorFlow(生态系统+生产工具链)。
- 轻量级原型开发:Keras(易用性+快速验证)。
- 计算机视觉专项:Caffe/Caffe2(性能优化+预训练模型)。
通过结合具体场景需求与框架特性,我们可最大化AIGC技术方案的部署效率与推理效果。
【二】Caffe的depthwise为什么慢,该如何优化?Caffe新加一层需要哪些操作?
一、Depthwise卷积速度瓶颈原因
-
内存访问模式低效
Caffe默认采用NCHW数据布局,Depthwise卷积的逐通道计算导致内存访问跳跃性高,无法充分利用缓存局部性。例如,输入尺寸为[N, C, H, W]时,每个通道独立处理,导致相邻内存地址的数据无法批量加载。 -
缺乏专用算法优化
- 标准卷积通常使用im2col + GEMM优化,但Depthwise的通道间无交互,GEMM效率低下。
- 未应用Winograd算法(可减少乘加运算量),导致计算密度不足。
-
并行化不足
Caffe的OpenMP线程调度在逐通道处理时粒度较粗,无法有效利用多核CPU。例如,当通道数C=32时,可能仅分配4线程,导致负载不均。 -
指令集未充分使用
未针对ARM NEON或Intel AVX2进行汇编级优化,例如未展开循环或使用SIMD向量化指令。
案例验证:
在MobileNetV1的Depthwise卷积层(3x3 kernel,输入尺寸112x112x32)中,Caffe原始实现耗时15ms,而TensorFlow Lite优化后仅需3ms。
二、Depthwise卷积加速方案
-
算法级优化
-
Winograd变换:将3x3卷积转换为4x4矩阵运算,减少60%乘法操作。
F ( 4 , 3 ) Winograd : 需要 16 次乘法(原需 3 x 3 = 9 次 / 点,总 16 x 9 = 144 → 16 x 16 = 256 ) F(4,3) \\text{ Winograd}: 需要16次乘法(原需3x3=9次/点,总16x9=144 → 16x16=256) F(4,3) Winograd:需要16次乘法(原需3x3=9次/点,总16x9=144→16x16=256)
-
直接卷积优化:避免im2col,通过滑动窗口直接计算,减少内存占用。
-
-
数据布局调整
将NCHW转为NHWC,提升内存连续性。例如,输入[N, H, W, C]更适应Depthwise的逐通道处理模式。 -
指令集加速
- ARM NEON:使用SIMD指令并行处理4个通道(float32x4_t)。
- CPU多线程:细粒度划分任务,如按行或通道块分配线程。
-
集成加速库
调用Intel MKL-DNN或NVIDIA CuDNN的Depthwise专用API(如CuDNN的cudnnDepthwiseConvolutionForward)。
优化效果:
经上述优化后,同一MobileNetV1层的推理时间从15ms降至2.5ms,提升6倍。
三、Caffe添加新层操作步骤
-
定义层参数(Proto)
在caffe.proto中新增层的参数消息,例如添加MyLayerParameter:message LayerParameter { optional MyLayerParameter my_layer_param = 12345;}message MyLayerParameter { optional float scale = 1 [default = 1.0];} -
实现层类(C++)
- 头文件
my_layer.hpp:继承Layer类,声明Forward/Backward函数。 - 源文件
my_layer.cpp:实现CPU/GPU逻辑,例如:template <typename Dtype>void MyLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { const Dtype* input = bottom[0]->cpu_data(); Dtype* output = top[0]->mutable_cpu_data(); caffe_cpu_scale(count, scale_, input, output);}
- 头文件
-
注册层工厂
在layer_factory.cpp中添加注册宏:INSTANTIATE_CLASS(MyLayer);REGISTER_LAYER_CLASS(My); -
编译与测试
- 修改
Makefile或CMakeLists.txt,包含新层源码。 - 编写测试用例,验证数值正确性(如梯度检查)。
- 修改
案例:添加ScaleLayer实现通道加权,用于风格迁移模型的细节增强。
四、三大领域应用
-
AIGC(生成式AI)
- 应用场景:移动端实时风格迁移
- 技术实现:
优化Depthwise卷积加速轻量级GAN模型(如MobileStyleGAN),在Snapchat等App中实现60FPS滤镜生成。
-
传统深度学习
- 应用场景:工业质检
- 技术实现:
在Caffe中新增DefectDetectLayer,融合Depthwise优化后的MobileNetV2,实现芯片缺陷检测(吞吐量提升3倍)。
-
自动驾驶
- 应用场景:车载实时语义分割
- 技术实现:
使用优化后的Depthwise卷积构建轻量级DeepLabV3+,在NVIDIA Jetson平台达到30FPS,添加BilinearUpsampleLayer提升边缘精度。
机器学习基础
【一】在机器学习中降维的方法都有哪些?
机器学习中的降维方法详解
一、常见降维方法分类
降维的核心目标是减少数据特征数量,同时保留关键信息。以下是主要方法及其特点:
二、通俗易懂的案例:电商用户行为分析
场景:某电商平台收集了用户的10个维度的数据(年龄、性别、购买频率、浏览时长、点击商品数、购物车添加次数等),需对用户分群以制定营销策略。
问题:直接使用10维数据进行聚类会导致“维度灾难”,计算复杂且难以可视化。
解决方案:
-
使用PCA进行无监督降维:
- 通过PCA提取前2个主成分,保留85%的方差。
- 将数据投影到2维平面,发现用户分为3个群体:
- 高频高价值用户(高购买频率、长浏览时间),
- 低频浏览用户(高点击次数但低购买),
- 潜在流失用户(近期无活动)。
-
使用t-SNE可视化:
- 若PCA分群不清晰,可用t-SNE进一步降维,保留局部结构,直观展示用户分布。
结果:运营团队针对不同群体推出定向优惠(如向流失用户发送折扣券),提升转化率15%。
三、三大领域中的应用
1. AIGC(生成式AI)
- 应用场景:生成高质量图像或文本。
- 方法:变分自编码器(VAE)学习低维潜在空间,控制生成内容。例如,Stable Diffusion通过潜在空间编码文本提示,生成符合语义的图像。
- 案例:在文本生成中,VAE将输入文本压缩为低维向量,解码时结合注意力机制生成连贯段落。
2. 传统深度学习
- 应用场景:图像分类与特征提取。
- 方法:自编码器用于去噪或特征压缩。例如,在MNIST手写数字识别中,自编码器将28x28图像压缩为10维向量,再通过全连接网络分类。
- 案例:医学影像分析中,PCA预处理MRI数据,减少噪声并加速模型训练。
3. 自动驾驶
- 应用场景:实时处理传感器数据。
- 方法:PCA或随机投影处理激光雷达点云数据。例如,Velodyne雷达每秒生成百万级点云,降维后保留关键障碍物轮廓,提升实时检测速度。
- 案例:在目标跟踪中,t-SNE可视化多目标轨迹,辅助算法优化路径预测。
【二】介绍一下机器学习中的朴素贝叶斯算法
一、算法原理与公式推导
朴素贝叶斯是一种基于贝叶斯定理的分类算法,其核心思想是假设特征之间相互独立(“朴素”假设),从而简化概率计算。以下是公式推导与关键步骤:
1. 贝叶斯定理
贝叶斯定理描述了如何通过已知条件概率计算后验概率:
P ( C i ∣ X ) = P ( X ∣ C i ) ⋅ P ( C i ) P ( X ) P(C_i | X) = \\frac{P(X | C_i) \\cdot P(C_i)}{P(X)} P(Ci∣X)=P(X)P(X∣Ci)⋅P(Ci)
- P ( C i ) P(C_i) P(Ci) :类别 C i C_i Ci 的先验概率。
- P ( X ∣ C i ) P(X | C_i) P(X∣Ci) :在类别 C i C_i Ci 下,特征 X X X 的条件概率。
- P ( C i ∣ X ) P(C_i | X) P(Ci∣X) :后验概率,即在特征 X X X 下样本属于 C i C_i Ci 的概率。
- P ( X ) P(X) P(X) :证据因子,对所有类别相同,可忽略比较。
2. 朴素假设
假设特征 X=( X 1 , X 2 ,..., X n ) X = (X_1, X_2, ..., X_n) X=(X1,X2,...,Xn) 相互独立,则联合条件概率可分解为:
P ( X ∣ C i ) = ∏ j = 1 n P ( X j ∣ C i ) P(X | C_i) = \\prod_{j=1}^n P(X_j | C_i) P(X∣Ci)=j=1∏nP(Xj∣Ci)
3. 分类决策规则
选择使后验概率最大的类别:
C p r e d= arg max C iP ( C i ) ∏ j = 1 n P ( X j ∣ C i ) C_{pred} = \\arg\\max_{C_i} P(C_i) \\prod_{j=1}^n P(X_j | C_i) Cpred=argCimaxP(Ci)j=1∏nP(Xj∣Ci)
4. 概率估计方法
-
离散特征:通过频率统计。
P ( X j = x j ∣ C i ) = 类别 C i 中特征 X j = x j 的样本数 类别 C i 的总样本数 P(X_j = x_j | C_i) = \\frac{\\text{类别 } C_i \\text{ 中特征 } X_j = x_j \\text{ 的样本数}}{\\text{类别 } C_i \\text{ 的总样本数}} P(Xj=xj∣Ci)=类别 Ci 的总样本数类别 Ci 中特征 Xj=xj 的样本数
-
连续特征:假设服从高斯分布,用均值和方差估计概率密度。
P ( X j = x j ∣ C i ) = 1 2 π σ i , j 2 exp ( − ( x j − μ i , j ) 2 2 σ i , j 2 ) P(X_j = x_j | C_i) = \\frac{1}{\\sqrt{2\\pi\\sigma_{i,j}^2}} \\exp\\left(-\\frac{(x_j - \\mu_{i,j})^2}{2\\sigma_{i,j}^2}\\right) P(Xj=xj∣Ci)=2πσi,j21exp(−2σi,j2(xj−μi,j)2)
5. 平滑技术(解决零概率问题)
使用拉普拉斯平滑(Laplace Smoothing)避免未出现特征导致概率为零:
P ( X j = x j ∣ C i ) = 计数 + α 总样本数 + α ⋅ N P(X_j = x_j | C_i) = \\frac{\\text{计数} + \\alpha}{\\text{总样本数} + \\alpha \\cdot N} P(Xj=xj∣Ci)=总样本数+α⋅N计数+α
- α \\alpha α :平滑参数(通常取1)。
- N N N :特征 X j X_j Xj 的可能取值数。
6. 对数概率(解决数值下溢)
将连乘转换为求和,避免小数相乘导致下溢:
log P ( C i ∣ X ) ∝ log P ( C i ) + ∑ j = 1 n log P ( X j ∣ C i ) \\log P(C_i | X) \\propto \\log P(C_i) + \\sum_{j=1}^n \\log P(X_j | C_i) logP(Ci∣X)∝logP(Ci)+j=1∑nlogP(Xj∣Ci)
二、通俗易懂的案例:垃圾邮件分类
假设训练数据包含以下邮件,判断新邮件是否为垃圾邮件。
训练数据
1. 特征提取
选择关键词:“免费”和“赢取”作为特征。
2. 计算概率
-
先验概率:
P ( 垃圾邮件 ) = 2 4 = 0.5 , P ( 正常邮件 ) = 2 4 = 0.5 P(\\text{垃圾邮件}) = \\frac{2}{4} = 0.5, \\quad P(\\text{正常邮件}) = \\frac{2}{4} = 0.5 P(垃圾邮件)=42=0.5,P(正常邮件)=42=0.5
-
条件概率(使用拉普拉斯平滑, α = 1 \\alpha = 1 α=1 ):
-
垃圾邮件:
P ( 免费 = 1 ∣ 垃圾 ) =1 + 1 2 + 2 = 0.5 P(\\text{免费}=1 | \\text{垃圾}) = \\frac{1 + 1}{2 + 2} = 0.5 P(免费=1∣垃圾)=2+21+1=0.5
P ( 赢取 = 1 ∣ 垃圾 ) =1 + 1 2 + 2 = 0.5 P(\\text{赢取}=1 | \\text{垃圾}) = \\frac{1 + 1}{2 + 2} = 0.5 P(赢取=1∣垃圾)=2+21+1=0.5
-
正常邮件:
P ( 免费 = 1 ∣ 正常 ) =0 + 1 2 + 2 = 0.25 P(\\text{免费}=1 | \\text{正常}) = \\frac{0 + 1}{2 + 2} = 0.25 P(免费=1∣正常)=2+20+1=0.25
P ( 赢取 = 1 ∣ 正常 ) =0 + 1 2 + 2 = 0.25 P(\\text{赢取}=1 | \\text{正常}) = \\frac{0 + 1}{2 + 2} = 0.25 P(赢取=1∣正常)=2+20+1=0.25
-
3. 预测新邮件
新邮件内容:“免费赢取现金”,包含“免费”和“赢取”。
-
计算后验概率:
-
垃圾邮件:
log P ( 垃圾 ∣ X ) = log 0.5 + log 0.5 + log 0.5 = − 1.732 \\log P(\\text{垃圾} | X) = \\log 0.5 + \\log 0.5 + \\log 0.5 = -1.732 logP(垃圾∣X)=log0.5+log0.5+log0.5=−1.732
-
正常邮件:
log P ( 正常 ∣ X ) = log 0.5 + log 0.25 + log 0.25 = − 2.773 \\log P(\\text{正常} | X) = \\log 0.5 + \\log 0.25 + \\log 0.25 = -2.773 logP(正常∣X)=log0.5+log0.25+log0.25=−2.773
-
-
结果:选择后验概率更大的类别,即垃圾邮件。
三、实际应用场景
1. 文本分类(如AIGC)
- 应用:自动生成文本的类别标注(如新闻分类、情感分析)。
- 实现:将文本分词后统计词频,通过朴素贝叶斯判断所属类别。
2. 传统深度学习
- 应用:作为基线模型验证特征有效性。
- 实现:与TF-IDF结合,用于垃圾邮件过滤或用户评论分类。
3. 自动驾驶
- 应用:传感器数据分类(如障碍物识别)。
- 实现:将激光雷达点云或摄像头图像提取特征后,分类为“车辆”“行人”等。
Python编程基础
【一】Python中tuple、list和dict有什么区别?
一、核心概念与区别对比
(1, 2, 3)[1, 2, 3]{\"key\": value}二、通俗易懂的案例:学生管理系统
假设需要管理学生的基本信息、课程列表和各科成绩:
- 学号:一旦分配不可更改 → 使用Tuple存储:
student_id = (2023001, \"张三\")。 - 课程列表:可能动态增减(如新增选修课) → 使用List存储:
courses = [\"数学\", \"物理\", \"化学\"]。 - 成绩记录:需通过科目名称快速查询分数 → 使用Dict存储:
scores = {\"数学\": 90, \"物理\": 85}。
三、性能与使用场景总结
(loss, acc))【二】Python中使用迭代器遍历和非迭代器遍历有什么区别?
一、核心概念与区别
__iter__()和__next__()方法实现惰性计算for i in range(len(list)))二、关键代码对比
for item in iter_list:for i in range(len(list)): item = list[i]yieldfor line in file:lines = file.readlines()模型部署基础
【一】MACE框架和NCNN框架之间有什么区别?MACE和NCNN各自的加速原理是什么样的?
一、核心差异总结
二、加速原理对比
1. MACE的加速原理
- 异构计算融合:
- CPU:ARM NEON指令加速卷积/池化,支持big.LITTLE调度优化能效。
- GPU:通过OpenCL实现并行计算,针对Adreno/Mali GPU优化内核。
- DSP:集成高通Hexagon HVX库,加速矩阵运算(如语音识别中的MFCC特征提取)。
- 算法优化:
- Winograd卷积:减少乘法运算量,提升卷积速度30%以上。
- 内存依赖分析:动态复用中间结果内存,降低峰值内存占用50%。
- 系统级优化:
- 任务分片:将长时GPU计算拆分为子任务,避免阻塞UI渲染。
案例:在小米手机的人像模式中,MACE同时调用CPU(人脸检测)+ GPU(背景虚化渲染)+ DSP(景深计算),整体延迟降低40%。
2. NCNN的加速原理
- 指令级优化:
- ARM NEON汇编:手动编写汇编代码优化卷积/全连接层,相比C++实现提速2-3倍。
- 内存池技术:预分配内存并复用,减少动态内存分配开销。
- 计算图优化:
- 算子融合:将Conv+BN+ReLU合并为单一算子,减少中间数据传递。
- 量化支持:8-bit整数量化模型,体积缩小4倍,推理速度提升1.5倍。
- 多线程并行:
- 分块计算:将大矩阵拆分为子块,利用多核CPU并行处理。
案例:在微信的视频通话背景虚化功能中,NCNN通过NEON优化实时处理1080P视频流,单帧处理时间从15ms降至6ms。
三、实际应用场景对比
1. AIGC领域
- MACE应用:
- 移动端Stable Diffusion轻量化:将图像生成模型部署到手机端,利用DSP加速潜在空间解码,生成512x512图像仅需3秒。
- NCNN应用:
- 实时AI滤镜:在天天P图中,通过量化后的StyleGAN模型实现实时风格迁移,支持10种滤镜并行计算。
2. 传统深度学习
- MACE应用:
- 工业质检:在工厂边缘设备部署ResNet-18,通过Hexagon DSP加速缺陷检测,吞吐量达200帧/秒。
- NCNN应用:
- 移动端OCR:在QQ扫描功能中,使用CRNN+CTC模型识别文字,NEON优化使识别速度提升至30ms/行。
3. 自动驾驶
- MACE应用:
- 多传感器融合:在车载平台中,CPU处理激光雷达点云,GPU渲染BEV地图,延迟控制在50ms内。
- NCNN应用:
- 车载障碍物检测:通过YOLOv9模型+Vulkan加速,在车机端实现60FPS的实时检测。
四、选择建议
- 选MACE:需跨CPU/GPU/DSP协同、强调功耗控制(如手机端复杂AI任务)。
- 选NCNN:追求极致CPU性能、快速部署轻量模型(如移动App嵌入式AI)。
通过框架特性与场景需求的精准匹配,可最大化AI算法在移动端的落地效率。
计算机基础
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结归纳AI行业所需的计算机基础干货知识。这些干货知识不仅能在面试中帮助我们,还能让我们在AI行业中提高工作效率。
【一】介绍一下计算机中DOS攻击的概念
1. DOS攻击(拒绝服务攻击)基本概念
DOS(Denial of Service)攻击是一种通过耗尽目标系统的资源(如带宽、内存、CPU等)或利用系统漏洞,使其无法正常提供服务的网络攻击行为。攻击者通过发送大量无效或恶意请求,导致合法用户无法访问目标服务,从而实现“拒绝服务”的目的。
2. DOS与DDOS的区别
- DOS:攻击源为单一主机或少量主机,攻击流量集中,容易被识别和阻断。
- DDOS(分布式拒绝服务攻击):攻击源为分布在多个地理位置的僵尸网络(Botnet),攻击流量分散且规模更大,防御难度显著增加。
3. 攻击原理与常见类型
(1)资源耗尽型攻击
-
SYN洪水攻击(SYN Flood)
- 原理:利用TCP三次握手的漏洞。攻击者发送大量伪造源IP的SYN请求,服务器响应后等待客户端的ACK确认包。由于攻击者不完成握手,服务器资源被未完成的半连接耗尽。
- 影响:服务器无法处理新的合法连接。
-
UDP洪水攻击(UDP Flood)
- 原理:向目标服务器发送大量UDP数据包,占用网络带宽或消耗服务器处理能力。
- 典型工具:LOIC(Low Orbit Ion Cannon)。
-
HTTP洪水攻击(HTTP Flood)
- 原理:模拟合法用户发送大量HTTP请求(如GET/POST),耗尽服务器资源。
- 特点:请求内容可能合法,难以与正常流量区分。
(2)漏洞利用型攻击
-
Ping of Death
- 原理:发送超大的ICMP数据包(超过IP协议规定的最大长度),导致目标系统崩溃或重启。
- 现代防御:现代操作系统已修复此漏洞。
-
Slowloris攻击
- 原理:通过缓慢发送不完整的HTTP请求头,保持与服务器的连接长时间开放,耗尽并发连接数。
- 特点:攻击流量小但效率高。
4. 防御措施
(1)流量过滤与限速
- 防火墙与IPS/IDS:识别异常流量并阻断恶意IP。
- 速率限制(Rate Limiting):限制单个IP的请求频率。
(2)资源优化
- 负载均衡:将流量分散到多台服务器,避免单点过载。
- CDN(内容分发网络):缓存静态内容,分担源站压力。
(3)协议加固
- SYN Cookie:防御SYN洪水攻击,无需在服务器保存半连接状态。
- TCP/IP协议栈调优:调整半连接队列长度、超时时间等参数。
(4)云服务防护
- 云清洗服务:由云服务商自动过滤恶意流量,仅转发合法请求。
- 弹性带宽:动态扩展带宽以应对突发流量。
5. 总结
- DOS攻击本质:通过资源耗尽或漏洞利用,使目标系统丧失服务能力。
- 防御核心:结合流量分析、协议优化和分布式架构,提升系统抗压能力。
- 技术趋势:随着AI和机器学习的发展,攻击检测与防御将更加智能化。
推荐阅读
1、加入AIGCmagic社区知识星球!
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100+应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等干货。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。与此同时,我们也重磅推出了知识星球2025年惊喜价:原价199元,前200名限量立减50!特惠价仅149元!(每天仅4毛钱)
时长:一年(从我们加入的时刻算起)


2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、Transformer核心基础知识,核心网络结构,AIGC时代的Transformer新内涵,各AI领域Transformer的应用落地,Transformer未来发展趋势等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Transformer文章地址:https://zhuanlan.zhihu.com/p/709874399
9、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
10、50万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
11、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
12、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
13、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)

