论文理解《PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images》_petrv2: a unified frameworkfor 3d perception from
摘要
PETRv2 在 PETR 的基础上,探索了时间建模的有效性,利用前几帧的时间信息来增强 3D 目标检测。主要贡献有2点:
-
扩展了 PETR 中的 3D position embedding(3D PE)用于时序建模,实现了不同帧间目标位置的时间对齐。
-
引入了特征引导(feature-guided)的位置编码器,以提高 3D PE 的数据适应性。
代码链接:https://github.com/megvii-research/PETR
相关工作
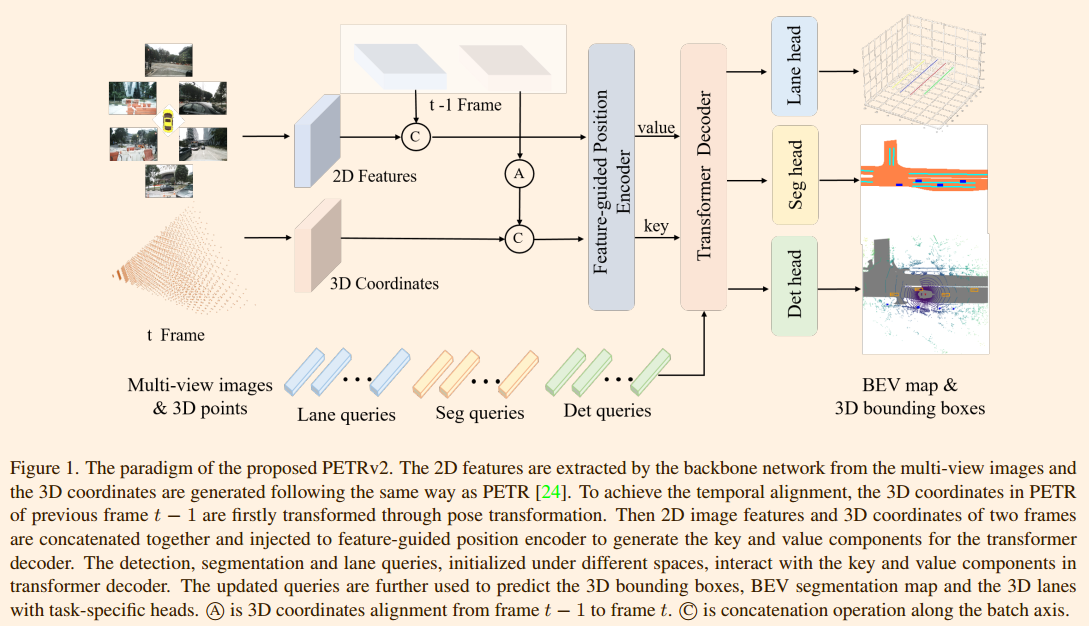
PETRv2 的整体架构基于 PETR,并扩展了时间建模和 BEV 分割。使用二维骨干网络(例如 ResNet-50)从多视角图像中提取二维图像特征,并按照 PETR 中的描述,从相机视锥空间生成三维坐标。考虑到自身运动,首先通过姿态变换将前一帧 t-1 的三维坐标变换到当前帧 t 的坐标系中。然后,将相邻帧的二维特征和三维坐标分别连接在一起,输入到特征引导位置编码器 (FPE)。之后,FPE 用于生成 Transformer 解码器的键和值组件。此外,从不同空间初始化的特定于任务的查询,包括检测查询(det queries)和分割查询(seg queries),被输入到 Transformer 解码器并与多视角图像特征进行交互。最后,更新后的查询被输入到特定任务的主管进行最终预测。
Temporal Modeling
3D坐标对齐 时间对齐是将帧 t-1 的三维坐标转换为帧 t 的坐标系。使用 作为多视角相机三维位置感知特征生成的默认三维空间。从第 i 个相机投影的三维点
可以表示为:
其中 是第 t 帧相机视锥空间网格中的点集,
是第 i 个相机的相机本征矩阵,
为雷达坐标系,
为相机坐标系。给定辅助帧 t − 1,从帧 t − 1 到帧 t 的 3D 点坐标对齐方式为:
以全局坐标空间作为 t − 1 帧和 t 帧之间的桥梁,可以计算出如下,其中,
为t时刻的车身坐标系。
Multi-task Learning
为 PETR 配备了 seg queries 和 lane queries,以支持高质量的 BEV 分割和 3D 车道检测。
BEV Segmentation 高分辨率 BEV 图可以划分为少量的patches。我们引入了 seg query用于 BEV 分割,每个 seg query对应一个特定的patches(例如,BEV 图左上角的 25 × 25 像素)。如图 3 (b) 所示,seg query在 BEV 空间中使用固定的锚点进行初始化,类似于 PETR 中检测查询 (det query) 的生成。然后,一个包含两个线性层的简单 MLP 将这些锚点投影到 seg query中。之后,seg query被输入到 Transformer 解码器并与图像特征进行交互。对于 Transformer 解码器,我们使用与检测任务相同的框架。最后,更新后的 seg query被输入到分割头(类似于 CVT 中的解码器),以预测最终的分割结果。我们使用focal loss分别监督每个类别的预测。

3D Lane Detection 在 PETR 上添加了lane queries 以支持 3D 车道检测(见图 3 (c))。定义 3D 锚车道(3D anchor lanes),每个锚车道表示为一组有序的 3D 坐标:,其中 n 是每个车道的采样点数。为了提高 3D 车道的预测能力,我们使用沿 Y 轴均匀采样的固定采样点集,类似于 Persformer。与 Persformer 不同的是,我们的锚车道与 Y 轴平行,而 Persformer 为每条锚线预定义了不同的斜率。来自 Transformer 解码器的更新后的lane queries用于预测 3D 车道实例。 3D车道头预测车道类别C以及相对于锚车道沿x轴和z轴的相对偏移量
。由于3D车道的长度不固定,我们还预测大小为n的可见性向量
来控制车道的起点和终点。我们使用focal loss函数来监督车道类别和可见性的预测。我们还使用L1损失函数来监督偏移量的预测。
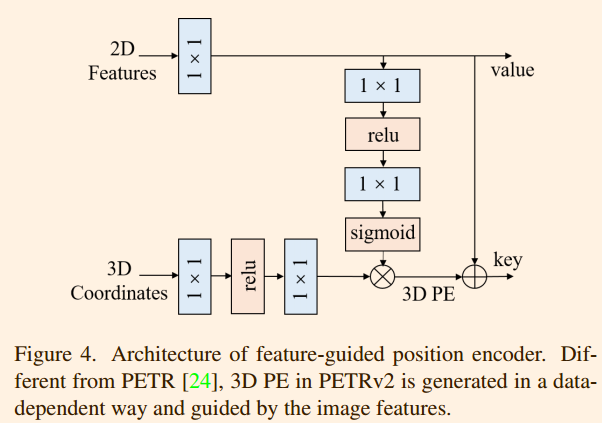
Feature-guided Position Encoder
PETR 将 3D 坐标转换为 3D position embedding(3D PE)。3D position embedding的生成过程可以表示为:
其中 是一个简单的多层感知器 (MLP)。PETR 中的 3D PE 与输入图像无关。我们认为 3D PE 应该由 2D 特征驱动,因为图像特征可以提供一些信息指导(例如深度)。在本文中,我们提出了一种特征引导的位置编码器,它隐式地引入了视觉先验。特征引导的 3D position embedding的生成可以表述为:
其中 也是一个小型多层感知器 (MLP) 网络。
是第 i 个摄像头的二维图像特征。如图 4 所示,经 1×1 卷积投影后的二维图像特征被输入到小型多层感知器 (MLP) 网络
和 Sigmoid 函数中,以获得注意力权重。三维坐标经另一个多层感知器 (MLP) 网络变换后,与注意力权重相乘,生成3D PE。该3D PE与2D 特征相加,得到 Transformer decoder的key值。投影后的2D features用作 Transformer decoder的value分量。
实验
模型训练环境为:模型使用 AdamW 优化器进行训练,权重衰减为 0.01。学习率初始化为 2.0 × 10−4,并采用余弦退火策略进行衰减。除消融研究外,所有实验均在 8 块 Tesla A100 GPU 上训练 24 个 epoch(2 倍训练集),总批次大小为 8。推理过程中未使用任何测试时间增强方法。
表 1 将其性能与 nuScenes 验证集上的最新研究进行了比较。
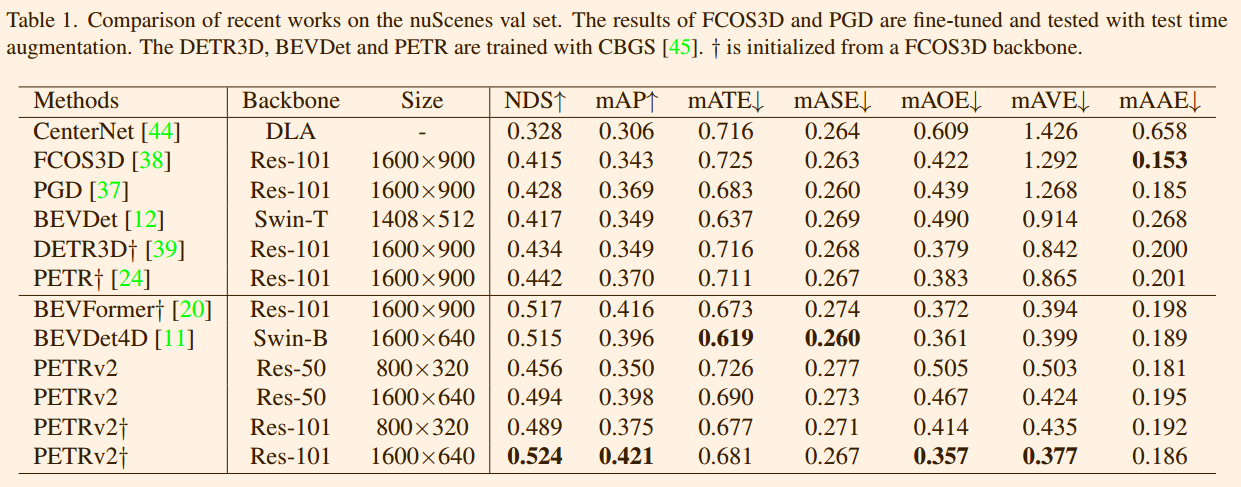
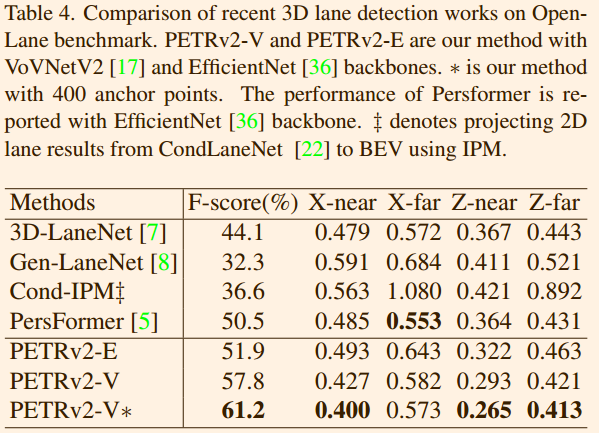
表 2 展示了 nuScenes 测试集上的性能比较。
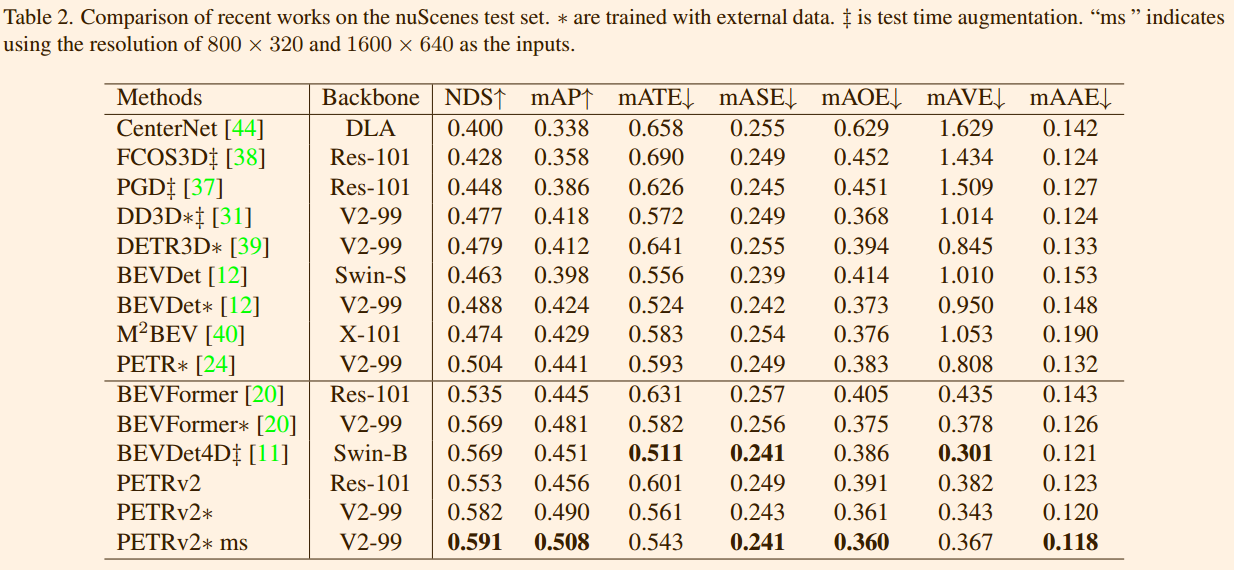
表 3. 近期在 nuScenes 验证集上进行的 BEV 分割工作的比较。
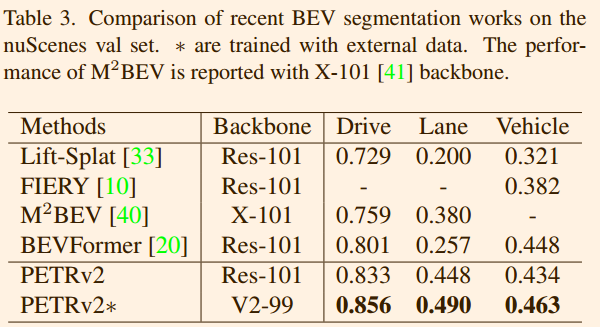
表 4. OpenLane 基准上近期 3D 车道检测工作的比较。
Ablation Study