【大模型面试高频考点】GRPO、DAPO、GSPO,一文看懂最新对比!_grpo dapo gspo
前两天 qwen 团队发布 GSPO,从一个新的方向改进了 GRPO 的目标函数。最初的目标是解决 GRPO 及其改进算法在训 moe 的时候对 routing replay 的依赖问题。
01.routing replay 的依赖问题
所有类 PPO 的 RL 更新算法,都遵循着“少量多次” 的更新原则。通过对 π_θ/π_θ_old 做 clip 来限制模型对单 batch 训练过度,多次更新。
而 moe 在 π_θ 出现修改的情况下,同一个 token 被分配到的专家可能会出现变化。
举个简单的例子,比如我想 offline 更新五次,正常我需要对同一个专家更新四次之后才会被 clip 掉,算更新完全。
但是如果我第一次的更新的时候就因为参数变化导致路由变化,该 token 由专家 A 切换到专家 B,并且最终导致后续 token 都会被路由到 B。
注意,此时可能会导致 π_θ 值骤变,导致 clip。导致路由到 B 但是 B 不进行任何更新!
因此 moe 训练中需要让 π_θ 中的路由遵循 π_θ_old 中的路由,凭空多了大量 infra 成本,这会导致很多框架需要单独对 moe 做大量适配。
02.GRPO v.s. DAPO v.s. GSPO 公式对比
DAPO 和 GSPO 都是在 GRPO 的目标函数的基础上魔改的,这里对比一下目标函数的变化便于理解。具体符号含义参考原文。
(1)GRPO
https://arxiv.org/abs/2402.03300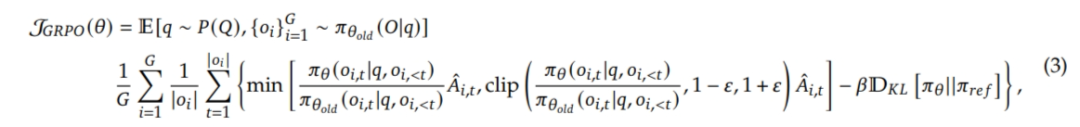
(2)DAPO
https://arxiv.org/abs/2503.14476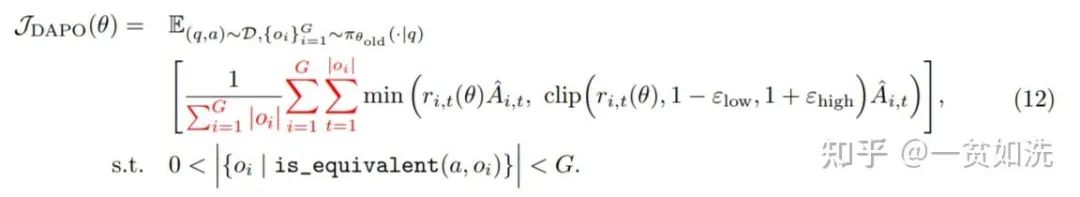
GRPO 中,每个response 的损失,是在句子层面求均值,然后再加到 group 内。
相当于,组内每个句子对最终目标函数的贡献平等看待。但是这会导致长序列中,每个 token 拿到的上游梯度小于短序列中的 token。
于是 DAPO 表示:这不行啊,我要在 token 层面一视同仁。于是乎,DAPO 中是把所有的句子的 token 加起来后再求均值,保证了每个 token 拿到的 credit 是一致的,但是句子间会有差异。
这实际上是对最终 loss 的聚合模式的不同,对应的就是 verl 中的 loss_agg_mode 配置。
def agg_loss(loss_mat: torch.Tensor, loss_mask: torch.Tensor, loss_agg_mode: str):\"\"\"Aggregate the loss matrix into a scalar.Args:loss_mat: `(torch.Tensor)`:shape: (bs, response_length)loss_mask: `(torch.Tensor)`:shape: (bs, response_length)loss_agg_mode: (str) choices:method to aggregate the loss matrix into a scalar.Returns:loss: `a scalar torch.Tensor`aggregated loss\"\"\"if loss_agg_mode == \"token-mean\":loss = verl_F.masked_mean(loss_mat, loss_mask)elif loss_agg_mode == \"seq-mean-token-sum\":seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) # token-sumloss = torch.mean(seq_losses) # seq-meanelif loss_agg_mode == \"seq-mean-token-mean\":seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) / torch.sum(loss_mask, dim=-1) # token-meanloss = torch.mean(seq_losses) # seq-meanelif loss_agg_mode == \"seq-mean-token-sum-norm\":seq_losses = torch.sum(loss_mat * loss_mask, dim=-1)loss = torch.sum(seq_losses) / loss_mask.shape[-1] # The divisor# (loss_mask.shape[-1]) should ideally be constant# throughout training to well-replicate the DrGRPO paper.# TODO: Perhaps add user-defined normalizer argument to# agg_loss to ensure divisor stays constant throughout.else:raise ValueError(f\"Invalid loss_agg_mode: {loss_agg_mode}\")return loss
(3)GSPO
https://www.arxiv.org/abs/2507.18071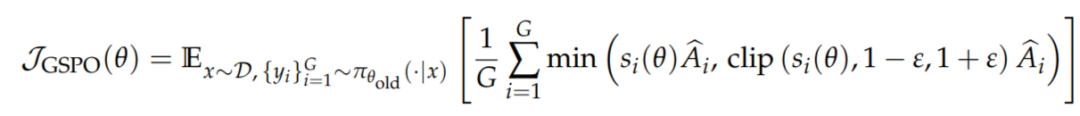
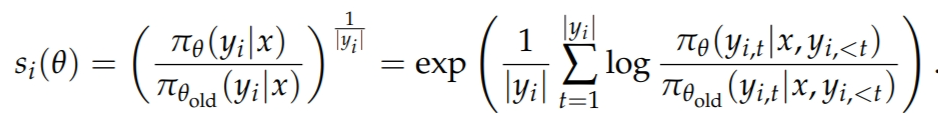
GSPO 式子中其实还是 GRPO 的大致思想,序列内归一化,序列间保持一致性。
但是其把序列取均值这一步放到了 clip 内,也就是说以后 offline 更新时,只关注序列整体的策略变化,而不是逐 token 做 clip。
03.为什么 GSPO 能缓解 moe 训练带来的问题
前面说到,moe 训练中需要 routing replay 的重要原因是路由切换会导致 token 级别的 clip 导致更新不稳定。而 GSPO 把 clip 拉到了序列级别。
即,路由变化导致的 π_θ/π_θ_old 的方差融化在序列中,使得 clip 更加有效。
04.GSPO 在 dense model 上会有什么效果
无论是 DAPO 的 clip higher,还是 minimax 的 CISPO,都在针对 clip 出手。
因为原来 token 级别的 clip 自带高概率 token 自我增强,低概率 token 翻身难的偏好。
推导过程见:
https://rethink-rlvr.notion.site/Spurious-Rewards-Rethinking-Training-Signals-in-RLVR-1f4df34dac1880948858f95aeb88872f#1f6df34dac1880c2b28affa71f5616c5ok,but why random 小节,简单来讲就是,clip 的 episilon 开 0.2 的时候,0.1 概率的 token 的增长上限是涨到 0.12,而 0.8 概率的 token 的增长上限高达 0.96。
RLVR 训练过程中的理想状况是模型通过探索,修改自身策略,实现更高的样本利用率甚至“造轨迹”的效果。
但是时间训练中,大部分实验都是单纯的高概率 token 自我增强,模型熵单调递减,模型通过让分布更集中来提高 pass@1,逼近 pass@8。
这样达不到让模型进行探索的目的。
而 GSPO 把对模型分布的 clip 拉到了句子层级,来对新旧策略完整序列级别的似然差做 clip,缓解了 clip 偏好高概率 token 的特点,理论上有助于鼓励模型学到新探索的路径。
举个经典例子,比如说模型发现,输出\"wait\" 有助于纠正输出提高正确率。但是\"wait\" token 出现的概率不高,对应的熵较高,一次更新后概率也高不到哪里去。
在后续 rollout 中如果没能出现并且有效提高 reward,它就会在其它高概率 token 的自我增强中被”淹没“、”遗忘“。
但是如果是序列级别的 clip,\"wait\"由于其低概率特性,更容易“抢夺”序列中其它高概率 token 的似然差的份额。
因此笔者猜测 GSPO 实验更容易出现熵增现象,模型的探索能力也更强。(还没做实验,叠甲...)
05.碎碎念
刚开始看的时候抱有疑问,因为如果按照 GSPO 公式主要生效的点是对序列做 clip,那为什么要用这么怪的公式求均值,为什么长这样(下二图)。
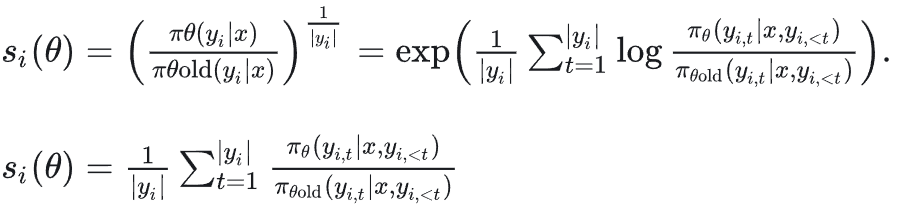
后面经义父指点,GSPO 的式子可以表示为两种策略的对数似然插值,十分优美且含义明确,因此会更好一些。
而且为了数值稳定性,实际到 compute policy loss 阶段进来的也都是 log_probability ,这样处理也比较方便,没有式子看起来那么恶心。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

之前商界有位名人说过:“站在风口,猪都能吹上天”。这几年,AI大模型领域百家争鸣,百舸争流,明显是这个时代下一个风口!
那如何学习大模型&AI产品经理?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起\"前沿课程+智能实训+精准就业\"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

