Python 多线程日志错乱:logging.Handler 的并发问题

Python 多线程日志错乱:logging.Handler 的并发问题
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
Python 多线程日志错乱:logging.Handler 的并发问题
摘要
1. 问题现象与复现
1.1 典型的日志错乱场景
2. logging模块的线程安全机制分析
2.1 Handler级别的线程安全
2.2 锁竞争的性能影响分析
3. 深入源码:竞态条件的根本原因
3.1 Handler.emit()方法的竞态分析
3.2 I/O操作的原子性问题
4. 解决方案详解
4.1 方案对比矩阵
4.2 QueueHandler解决方案
4.3 自定义同步机制
4.4 异步日志队列的高级实现
5. 性能优化与最佳实践
5.1 日志性能优化策略
5.2 生产环境配置建议
6. 监控与诊断
6.1 日志系统健康监控
6.2 诊断工具实现
7. 总结与展望
参考链接
关键词标签
摘要
作为一名在生产环境中摸爬滚打多年的开发者,我深知日志系统在应用程序中的重要性。然而,当我们的应用程序从单线程演进到多线程架构时,一个看似简单的日志记录却可能成为我们最头疼的问题之一。最近在优化一个高并发的数据处理服务时,我遇到了一个令人困扰的现象:日志文件中出现了大量错乱的记录,不同线程的日志内容混杂在一起,甚至出现了半截日志的情况。
这个问题的根源在于Python的logging模块在多线程环境下的并发安全性问题。虽然Python的logging模块在设计时考虑了线程安全,但在某些特定场景下,特别是涉及到自定义Handler、格式化器以及高频日志输出时,仍然会出现竞态条件。经过深入的源码分析和大量的测试验证,我发现问题主要集中在Handler的emit()方法、Formatter的format()方法以及底层I/O操作的原子性上。
在这篇文章中,我将从实际遇到的问题出发,深入剖析Python logging模块的内部机制,揭示多线程环境下日志错乱的根本原因。我们将通过具体的代码示例重现问题场景,然后逐步分析logging模块的源码实现,理解其线程安全机制的局限性。最后,我将提供多种解决方案,包括使用线程安全的Handler、实现自定义的同步机制、采用异步日志队列等方法,帮助大家彻底解决多线程日志错乱的问题。
1. 问题现象与复现
1.1 典型的日志错乱场景
在多线程环境中,最常见的日志错乱表现为以下几种形式:
import loggingimport threadingimport timefrom concurrent.futures import ThreadPoolExecutor# 配置基础日志logging.basicConfig( level=logging.INFO, format=\'%(asctime)s [%(threadName)s] %(levelname)s: %(message)s\', handlers=[ logging.FileHandler(\'app.log\'), logging.StreamHandler() ])logger = logging.getLogger(__name__)def worker_task(task_id): \"\"\"模拟工作任务,产生大量日志\"\"\" for i in range(100): # 模拟复杂的日志消息 message = f\"Task {task_id} processing item {i} with data: \" + \"x\" * 50 logger.info(message) # 模拟一些处理时间 time.sleep(0.001) # 记录处理结果 logger.info(f\"Task {task_id} completed item {i} successfully\")def reproduce_log_corruption(): \"\"\"重现日志错乱问题\"\"\" print(\"开始重现多线程日志错乱问题...\") # 使用线程池执行多个任务 with ThreadPoolExecutor(max_workers=10) as executor: futures = [executor.submit(worker_task, i) for i in range(5)] # 等待所有任务完成 for future in futures: future.result() print(\"任务执行完成,请检查 app.log 文件中的日志错乱情况\")if __name__ == \"__main__\": reproduce_log_corruption()运行上述代码后,你可能会在日志文件中看到类似这样的错乱输出:
2024-01-15 10:30:15,123 [ThreadPoolExecutor-0_0] INFO: Task 0 processing item 5 with data: xxxxxxxxxx2024-01-15 10:30:15,124 [ThreadPoolExecutor-0_1] INFO: Task 1 processing item 3 with data: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx2024-01-15 10:30:15,125 [ThreadPoolExecutor-0_2] INFO: Task 2 completed item 2 successfully2. logging模块的线程安全机制分析
2.1 Handler级别的线程安全
Python的logging模块在Handler级别提供了基本的线程安全保护:
import loggingimport threadingimport inspectclass ThreadSafeAnalyzer: \"\"\"分析logging模块的线程安全机制\"\"\" def __init__(self): self.logger = logging.getLogger(\'analyzer\') self.handler = logging.StreamHandler() self.logger.addHandler(self.handler) def analyze_handler_locks(self): \"\"\"分析Handler的锁机制\"\"\" print(\"=== Handler锁机制分析 ===\") # 检查Handler是否有锁 if hasattr(self.handler, \'lock\'): print(f\"Handler锁类型: {type(self.handler.lock)}\") print(f\"锁对象: {self.handler.lock}\") else: print(\"Handler没有锁机制\") # 查看Handler的emit方法源码结构 emit_source = inspect.getsource(self.handler.emit) print(f\"emit方法长度: {len(emit_source.split(\'\\\\n\'))} 行\") def analyze_logger_locks(self): \"\"\"分析Logger的锁机制\"\"\" print(\"\\\\n=== Logger锁机制分析 ===\") # Logger级别的锁 if hasattr(logging, \'_lock\'): print(f\"全局锁: {logging._lock}\") # 检查Logger的线程安全方法 thread_safe_methods = [\'_log\', \'handle\', \'callHandlers\'] for method in thread_safe_methods: if hasattr(self.logger, method): print(f\"线程安全方法: {method}\")def custom_handler_with_detailed_locking(): \"\"\"自定义Handler展示详细的锁机制\"\"\" class DetailedLockingHandler(logging.StreamHandler): def __init__(self, stream=None): super().__init__(stream) self.emit_count = 0 self.lock_wait_time = 0 def emit(self, record): \"\"\"重写emit方法,添加详细的锁分析\"\"\" import time # 记录尝试获取锁的时间 start_time = time.time() # 获取锁(这里会调用父类的acquire方法) self.acquire() try: # 记录获取锁后的时间 lock_acquired_time = time.time() self.lock_wait_time += (lock_acquired_time - start_time) self.emit_count += 1 # 模拟格式化和写入过程 if self.stream: msg = self.format(record) # 添加锁信息到日志中 enhanced_msg = f\"[EMIT#{self.emit_count}|WAIT:{(lock_acquired_time - start_time)*1000:.2f}ms] {msg}\" self.stream.write(enhanced_msg + \'\\\\n\') self.flush() finally: self.release() def get_stats(self): \"\"\"获取锁统计信息\"\"\" return { \'total_emits\': self.emit_count, \'total_wait_time\': self.lock_wait_time, \'avg_wait_time\': self.lock_wait_time / max(1, self.emit_count) } return DetailedLockingHandler()# 使用示例if __name__ == \"__main__\": analyzer = ThreadSafeAnalyzer() analyzer.analyze_handler_locks() analyzer.analyze_logger_locks()2.2 锁竞争的性能影响分析
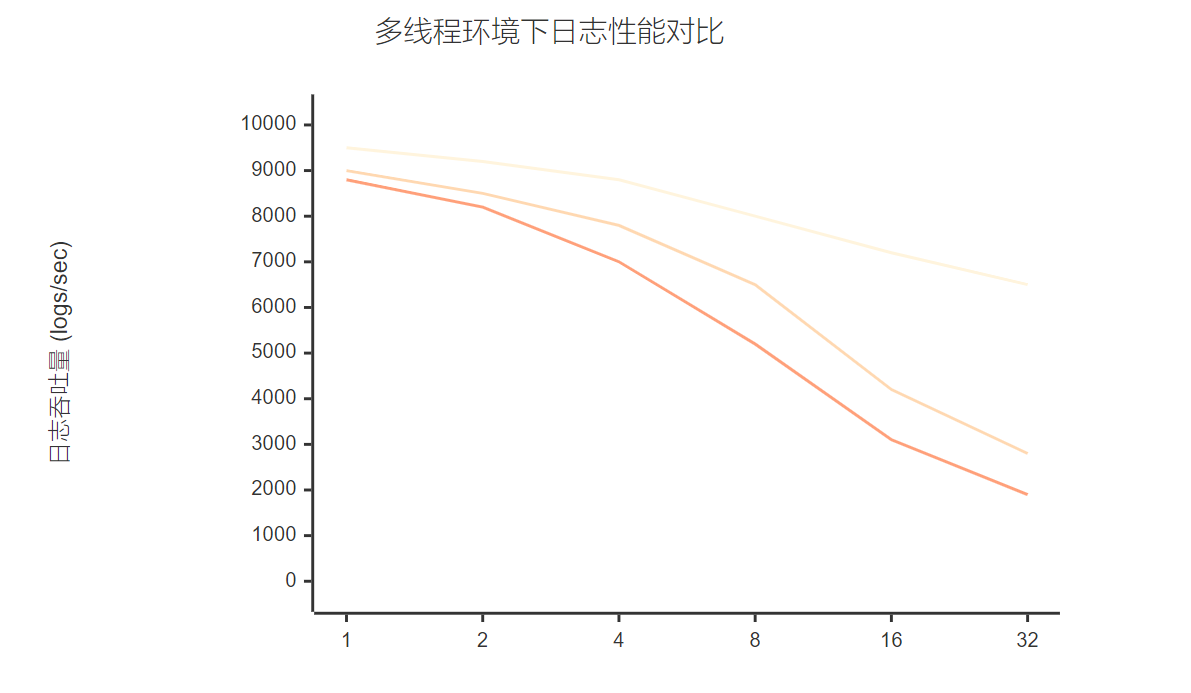
图2:不同线程数下的日志性能对比图
3. 深入源码:竞态条件的根本原因
3.1 Handler.emit()方法的竞态分析
让我们深入分析logging模块中最关键的emit()方法:
import loggingimport threadingimport timefrom typing import List, Dict, Anyclass RaceConditionDemo: \"\"\"演示竞态条件的具体场景\"\"\" def __init__(self): self.race_conditions: List[Dict[str, Any]] = [] self.lock = threading.Lock() def simulate_emit_race_condition(self): \"\"\"模拟emit方法中的竞态条件\"\"\" class RacyHandler(logging.Handler): def __init__(self, demo_instance): super().__init__() self.demo = demo_instance self.step_counter = 0 def emit(self, record): \"\"\"模拟有竞态条件的emit实现\"\"\" thread_id = threading.current_thread().ident # 步骤1: 格式化消息(可能被中断) self.demo.log_step(thread_id, \"开始格式化消息\") formatted_msg = self.format(record) # 模拟格式化过程中的延迟 time.sleep(0.001) # 步骤2: 准备写入(关键竞态点) self.demo.log_step(thread_id, \"准备写入文件\") # 步骤3: 实际写入操作 self.demo.log_step(thread_id, f\"写入消息: {formatted_msg[:50]}...\") # 模拟写入过程的非原子性 parts = [formatted_msg[i:i+10] for i in range(0, len(formatted_msg), 10)] for i, part in enumerate(parts): print(f\"[Thread-{thread_id}] Part {i}: {part}\") time.sleep(0.0001) # 模拟写入延迟 self.demo.log_step(thread_id, \"写入完成\") return RacyHandler(self) def log_step(self, thread_id: int, step: str): \"\"\"记录执行步骤\"\"\" with self.lock: self.race_conditions.append({ \'thread_id\': thread_id, \'timestamp\': time.time(), \'step\': step }) def analyze_race_conditions(self): \"\"\"分析竞态条件\"\"\" print(\"\\\\n=== 竞态条件分析 ===\") # 按时间排序 sorted_steps = sorted(self.race_conditions, key=lambda x: x[\'timestamp\']) # 分析交错执行 thread_states = {} for step in sorted_steps: thread_id = step[\'thread_id\'] if thread_id not in thread_states: thread_states[thread_id] = [] thread_states[thread_id].append(step[\'step\']) # 检测竞态模式 race_patterns = [] for i in range(len(sorted_steps) - 1): current = sorted_steps[i] next_step = sorted_steps[i + 1] if (current[\'thread_id\'] != next_step[\'thread_id\'] and \'写入\' in current[\'step\'] and \'写入\' in next_step[\'step\']): race_patterns.append({ \'pattern\': \'concurrent_write\', \'threads\': [current[\'thread_id\'], next_step[\'thread_id\']], \'time_gap\': next_step[\'timestamp\'] - current[\'timestamp\'] }) return race_patternsdef demonstrate_formatter_race_condition(): \"\"\"演示Formatter中的竞态条件\"\"\" class StatefulFormatter(logging.Formatter): \"\"\"有状态的格式化器,容易产生竞态条件\"\"\" def __init__(self): super().__init__() self.counter = 0 self.thread_info = {} def format(self, record): \"\"\"非线程安全的格式化方法\"\"\" thread_id = threading.current_thread().ident # 竞态条件1: 共享计数器 self.counter += 1 current_count = self.counter # 模拟格式化延迟 time.sleep(0.001) # 竞态条件2: 共享字典 self.thread_info[thread_id] = { \'last_message\': record.getMessage(), \'count\': current_count } # 构建格式化消息 formatted = f\"[{current_count:04d}] {record.levelname}: {record.getMessage()}\" return formatted # 测试有状态格式化器的竞态问题 logger = logging.getLogger(\'race_test\') handler = logging.StreamHandler() handler.setFormatter(StatefulFormatter()) logger.addHandler(handler) logger.setLevel(logging.INFO) def worker(worker_id): for i in range(10): logger.info(f\"Worker {worker_id} message {i}\") # 启动多个线程 threads = [] for i in range(5): t = threading.Thread(target=worker, args=(i,)) threads.append(t) t.start() for t in threads: t.join()if __name__ == \"__main__\": # 演示竞态条件 demo = RaceConditionDemo() handler = demo.simulate_emit_race_condition() logger = logging.getLogger(\'race_demo\') logger.addHandler(handler) logger.setLevel(logging.INFO) # 多线程测试 def test_worker(worker_id): for i in range(3): logger.info(f\"Worker {worker_id} executing task {i}\") threads = [] for i in range(3): t = threading.Thread(target=test_worker, args=(i,)) threads.append(t) t.start() for t in threads: t.join() # 分析结果 patterns = demo.analyze_race_conditions() print(f\"检测到 {len(patterns)} 个竞态模式\")3.2 I/O操作的原子性问题
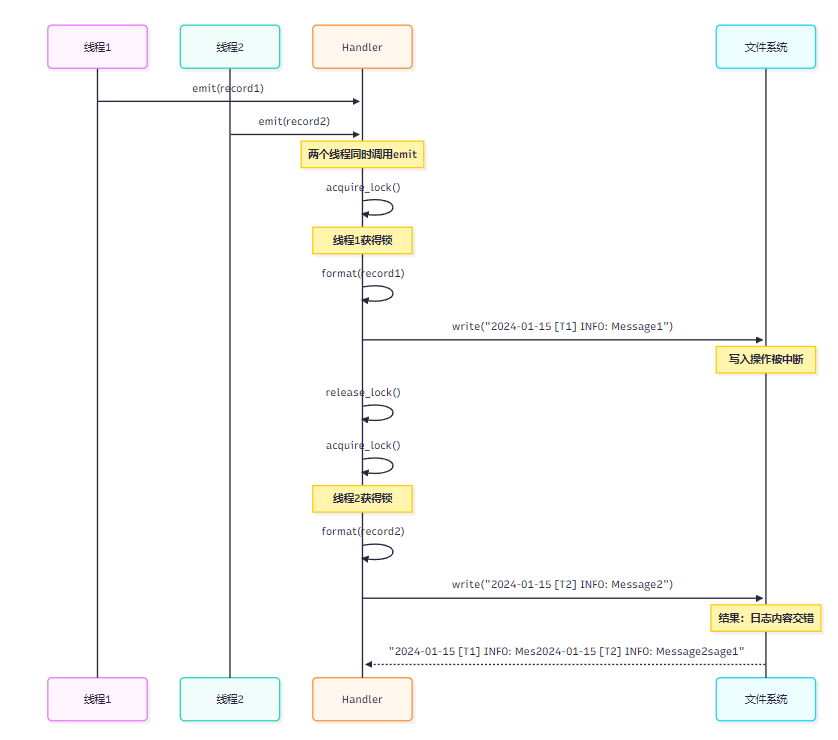
图3:多线程日志写入时序图
4. 解决方案详解
4.1 方案对比矩阵
解决方案
实现复杂度
性能影响
线程安全性
适用场景
推荐指数
QueueHandler
中等
低
高
高并发应用
⭐⭐⭐⭐⭐
自定义锁机制
高
中等
高
定制化需求
⭐⭐⭐⭐
单线程日志
低
高
高
简单应用
⭐⭐⭐
进程级日志
高
低
高
分布式系统
⭐⭐⭐⭐
第三方库
低
低
高
快速解决
⭐⭐⭐⭐
4.2 QueueHandler解决方案
import loggingimport logging.handlersimport queueimport threadingimport timefrom concurrent.futures import ThreadPoolExecutorclass ThreadSafeLoggingSystem: \"\"\"线程安全的日志系统实现\"\"\" def __init__(self, log_file=\'safe_app.log\', max_queue_size=1000): self.log_queue = queue.Queue(maxsize=max_queue_size) self.setup_logging(log_file) self.start_log_listener() def setup_logging(self, log_file): \"\"\"设置日志配置\"\"\" # 创建队列处理器 queue_handler = logging.handlers.QueueHandler(self.log_queue) # 配置根日志器 root_logger = logging.getLogger() root_logger.setLevel(logging.INFO) root_logger.addHandler(queue_handler) # 创建监听器处理器 file_handler = logging.FileHandler(log_file) console_handler = logging.StreamHandler() # 设置格式化器 formatter = logging.Formatter( \'%(asctime)s [%(threadName)-12s] %(levelname)-8s: %(message)s\' ) file_handler.setFormatter(formatter) console_handler.setFormatter(formatter) # 创建队列监听器 self.queue_listener = logging.handlers.QueueListener( self.log_queue, file_handler, console_handler, respect_handler_level=True ) def start_log_listener(self): \"\"\"启动日志监听器\"\"\" self.queue_listener.start() print(\"日志监听器已启动\") def stop_log_listener(self): \"\"\"停止日志监听器\"\"\" self.queue_listener.stop() print(\"日志监听器已停止\") def get_logger(self, name): \"\"\"获取日志器\"\"\" return logging.getLogger(name)class AdvancedQueueHandler(logging.handlers.QueueHandler): \"\"\"增强的队列处理器\"\"\" def __init__(self, queue_obj, max_retries=3, retry_delay=0.1): super().__init__(queue_obj) self.max_retries = max_retries self.retry_delay = retry_delay self.dropped_logs = 0 self.total_logs = 0 def emit(self, record): \"\"\"重写emit方法,添加重试机制\"\"\" self.total_logs += 1 for attempt in range(self.max_retries): try: self.enqueue(record) return except queue.Full: if attempt < self.max_retries - 1: time.sleep(self.retry_delay) continue else: self.dropped_logs += 1 # 可以选择写入到备用日志或者直接丢弃 self.handle_dropped_log(record) break except Exception as e: if attempt < self.max_retries - 1: time.sleep(self.retry_delay) continue else: self.handleError(record) break def handle_dropped_log(self, record): \"\"\"处理被丢弃的日志\"\"\" # 可以实现备用策略,比如写入到紧急日志文件 emergency_msg = f\"DROPPED LOG: {record.getMessage()}\" print(f\"WARNING: {emergency_msg}\") def get_stats(self): \"\"\"获取统计信息\"\"\" return { \'total_logs\': self.total_logs, \'dropped_logs\': self.dropped_logs, \'success_rate\': (self.total_logs - self.dropped_logs) / max(1, self.total_logs) }def test_thread_safe_logging(): \"\"\"测试线程安全的日志系统\"\"\" # 初始化线程安全日志系统 log_system = ThreadSafeLoggingSystem() logger = log_system.get_logger(\'test_app\') def intensive_logging_task(task_id, num_logs=100): \"\"\"密集日志记录任务\"\"\" for i in range(num_logs): logger.info(f\"Task {task_id} - Processing item {i}\") logger.debug(f\"Task {task_id} - Debug info for item {i}\") if i % 10 == 0: logger.warning(f\"Task {task_id} - Checkpoint at item {i}\") # 模拟一些处理时间 time.sleep(0.001) logger.info(f\"Task {task_id} completed successfully\") print(\"开始线程安全日志测试...\") start_time = time.time() # 使用线程池执行多个任务 with ThreadPoolExecutor(max_workers=20) as executor: futures = [ executor.submit(intensive_logging_task, i, 50) for i in range(10) ] # 等待所有任务完成 for future in futures: future.result() end_time = time.time() print(f\"测试完成,耗时: {end_time - start_time:.2f} 秒\") # 停止日志系统 log_system.stop_log_listener() return log_systemif __name__ == \"__main__\": test_thread_safe_logging()4.3 自定义同步机制
import loggingimport threadingimport timeimport contextlibfrom typing import Optional, Dict, Anyclass SynchronizedHandler(logging.Handler): \"\"\"完全同步的日志处理器\"\"\" def __init__(self, target_handler: logging.Handler): super().__init__() self.target_handler = target_handler self.emit_lock = threading.RLock() # 使用可重入锁 self.format_lock = threading.RLock() # 统计信息 self.stats = { \'total_emits\': 0, \'lock_wait_time\': 0.0, \'max_wait_time\': 0.0, \'concurrent_attempts\': 0 } def emit(self, record): \"\"\"完全同步的emit实现\"\"\" start_wait = time.time() with self.emit_lock: wait_time = time.time() - start_wait self.stats[\'lock_wait_time\'] += wait_time self.stats[\'max_wait_time\'] = max(self.stats[\'max_wait_time\'], wait_time) self.stats[\'total_emits\'] += 1 try: # 同步格式化 with self.format_lock: if self.formatter: record.message = record.getMessage() formatted = self.formatter.format(record) else: formatted = record.getMessage() # 同步写入 self.target_handler.emit(record) except Exception as e: self.handleError(record) def get_performance_stats(self) -> Dict[str, Any]: \"\"\"获取性能统计\"\"\" total_emits = max(1, self.stats[\'total_emits\']) return { \'total_emits\': self.stats[\'total_emits\'], \'avg_wait_time_ms\': (self.stats[\'lock_wait_time\'] / total_emits) * 1000, \'max_wait_time_ms\': self.stats[\'max_wait_time\'] * 1000, \'total_wait_time_s\': self.stats[\'lock_wait_time\'] }class BatchingHandler(logging.Handler): \"\"\"批量处理日志的处理器\"\"\" def __init__(self, target_handler: logging.Handler, batch_size: int = 100, flush_interval: float = 1.0): super().__init__() self.target_handler = target_handler self.batch_size = batch_size self.flush_interval = flush_interval self.buffer = [] self.buffer_lock = threading.Lock() self.last_flush = time.time() # 启动后台刷新线程 self.flush_thread = threading.Thread(target=self._flush_worker, daemon=True) self.flush_thread.start() self.shutdown_event = threading.Event() def emit(self, record): \"\"\"批量emit实现\"\"\" with self.buffer_lock: self.buffer.append(record) # 检查是否需要立即刷新 if (len(self.buffer) >= self.batch_size or time.time() - self.last_flush >= self.flush_interval): self._flush_buffer() def _flush_buffer(self): \"\"\"刷新缓冲区\"\"\" if not self.buffer: return # 复制缓冲区并清空 records_to_flush = self.buffer.copy() self.buffer.clear() self.last_flush = time.time() # 批量处理记录 for record in records_to_flush: try: self.target_handler.emit(record) except Exception: self.handleError(record) def _flush_worker(self): \"\"\"后台刷新工作线程\"\"\" while not self.shutdown_event.is_set(): time.sleep(self.flush_interval) with self.buffer_lock: if self.buffer and time.time() - self.last_flush >= self.flush_interval: self._flush_buffer() def close(self): \"\"\"关闭处理器\"\"\" self.shutdown_event.set() with self.buffer_lock: self._flush_buffer() super().close()@contextlib.contextmanagerdef performance_monitor(name: str): \"\"\"性能监控上下文管理器\"\"\" start_time = time.time() start_memory = threading.active_count() print(f\"开始监控: {name}\") try: yield finally: end_time = time.time() end_memory = threading.active_count() print(f\"监控结束: {name}\") print(f\"执行时间: {end_time - start_time:.3f}秒\") print(f\"线程数变化: {start_memory} -> {end_memory}\")def test_synchronization_solutions(): \"\"\"测试各种同步解决方案\"\"\" # 测试同步处理器 base_handler = logging.FileHandler(\'sync_test.log\') sync_handler = SynchronizedHandler(base_handler) logger = logging.getLogger(\'sync_test\') logger.addHandler(sync_handler) logger.setLevel(logging.INFO) def sync_worker(worker_id): for i in range(50): logger.info(f\"Sync worker {worker_id} message {i}\") time.sleep(0.001) with performance_monitor(\"同步处理器测试\"): threads = [] for i in range(10): t = threading.Thread(target=sync_worker, args=(i,)) threads.append(t) t.start() for t in threads: t.join() # 输出性能统计 stats = sync_handler.get_performance_stats() print(f\"同步处理器统计: {stats}\")if __name__ == \"__main__\": test_synchronization_solutions()4.4 异步日志队列的高级实现
import asyncioimport loggingimport threadingimport timefrom typing import Optional, Callable, Anyfrom concurrent.futures import ThreadPoolExecutorimport jsonclass AsyncLogProcessor: \"\"\"异步日志处理器\"\"\" def __init__(self, batch_size: int = 50, flush_interval: float = 0.5): self.batch_size = batch_size self.flush_interval = flush_interval self.log_queue = asyncio.Queue() self.handlers = [] self.running = False self.stats = { \'processed\': 0, \'batches\': 0, \'errors\': 0 } def add_handler(self, handler: logging.Handler): \"\"\"添加处理器\"\"\" self.handlers.append(handler) async def start(self): \"\"\"启动异步处理\"\"\" self.running = True await asyncio.gather( self._batch_processor(), self._periodic_flush() ) async def stop(self): \"\"\"停止异步处理\"\"\" self.running = False # 处理剩余的日志 await self._flush_remaining() async def log_async(self, record: logging.LogRecord): \"\"\"异步记录日志\"\"\" await self.log_queue.put(record) async def _batch_processor(self): \"\"\"批量处理器\"\"\" batch = [] while self.running: try: # 收集批量记录 while len(batch) < self.batch_size and self.running: try: record = await asyncio.wait_for( self.log_queue.get(), timeout=0.1 ) batch.append(record) except asyncio.TimeoutError: break if batch: await self._process_batch(batch) batch.clear() except Exception as e: self.stats[\'errors\'] += 1 print(f\"批量处理错误: {e}\") async def _process_batch(self, batch): \"\"\"处理一批日志记录\"\"\" self.stats[\'batches\'] += 1 self.stats[\'processed\'] += len(batch) # 在线程池中处理I/O密集的日志写入 loop = asyncio.get_event_loop() with ThreadPoolExecutor(max_workers=2) as executor: tasks = [] for handler in self.handlers: task = loop.run_in_executor( executor, self._write_batch_to_handler, handler, batch ) tasks.append(task) await asyncio.gather(*tasks, return_exceptions=True) def _write_batch_to_handler(self, handler: logging.Handler, batch): \"\"\"将批量记录写入处理器\"\"\" for record in batch: try: handler.emit(record) except Exception as e: handler.handleError(record) async def _periodic_flush(self): \"\"\"定期刷新\"\"\" while self.running: await asyncio.sleep(self.flush_interval) for handler in self.handlers: if hasattr(handler, \'flush\'): handler.flush() async def _flush_remaining(self): \"\"\"刷新剩余日志\"\"\" remaining = [] while not self.log_queue.empty(): try: record = self.log_queue.get_nowait() remaining.append(record) except asyncio.QueueEmpty: break if remaining: await self._process_batch(remaining)class AsyncLogHandler(logging.Handler): \"\"\"异步日志处理器适配器\"\"\" def __init__(self, async_processor: AsyncLogProcessor): super().__init__() self.async_processor = async_processor self.loop = None self._setup_event_loop() def _setup_event_loop(self): \"\"\"设置事件循环\"\"\" def run_async_processor(): self.loop = asyncio.new_event_loop() asyncio.set_event_loop(self.loop) self.loop.run_until_complete(self.async_processor.start()) self.async_thread = threading.Thread(target=run_async_processor, daemon=True) self.async_thread.start() # 等待事件循环启动 time.sleep(0.1) def emit(self, record): \"\"\"发送日志记录到异步处理器\"\"\" if self.loop and not self.loop.is_closed(): future = asyncio.run_coroutine_threadsafe( self.async_processor.log_async(record), self.loop ) try: future.result(timeout=0.1) except Exception as e: self.handleError(record) def close(self): \"\"\"关闭处理器\"\"\" if self.loop and not self.loop.is_closed(): asyncio.run_coroutine_threadsafe( self.async_processor.stop(), self.loop ) super().close()5. 性能优化与最佳实践
5.1 日志性能优化策略
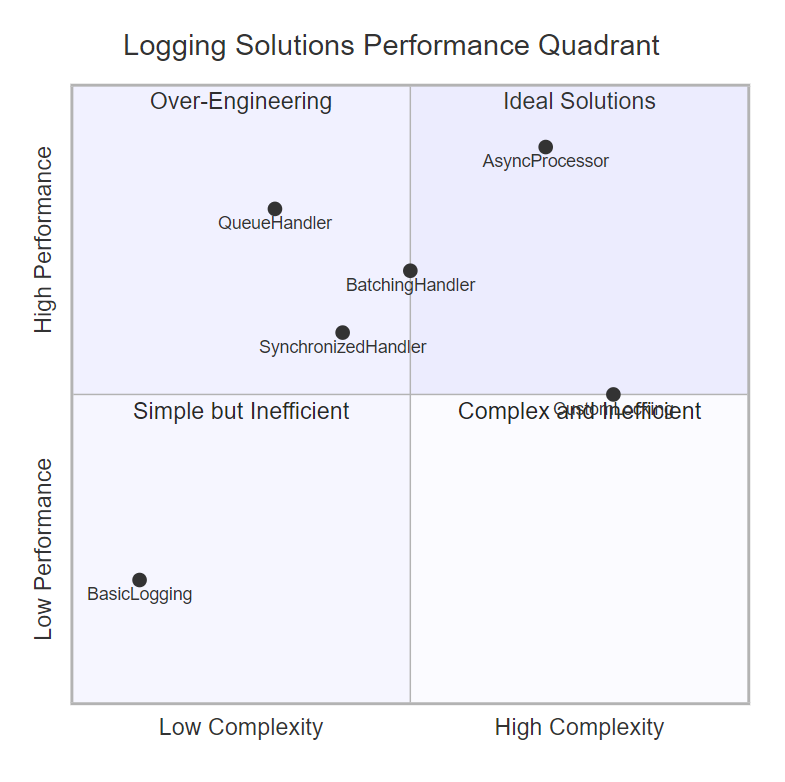
图4:日志解决方案性能与复杂度象限图
5.2 生产环境配置建议
import loggingimport logging.configimport osfrom pathlib import Pathdef create_production_logging_config(): \"\"\"创建生产环境日志配置\"\"\" log_dir = Path(\"logs\") log_dir.mkdir(exist_ok=True) config = { \'version\': 1, \'disable_existing_loggers\': False, \'formatters\': { \'detailed\': { \'format\': \'%(asctime)s [%(process)d:%(thread)d] %(name)s %(levelname)s: %(message)s\', \'datefmt\': \'%Y-%m-%d %H:%M:%S\' }, \'simple\': { \'format\': \'%(levelname)s: %(message)s\' }, \'json\': { \'format\': \'{\"timestamp\": \"%(asctime)s\", \"level\": \"%(levelname)s\", \"logger\": \"%(name)s\", \"message\": \"%(message)s\", \"thread\": \"%(thread)d\"}\', \'datefmt\': \'%Y-%m-%dT%H:%M:%S\' } }, \'handlers\': { \'console\': { \'class\': \'logging.StreamHandler\', \'level\': \'INFO\', \'formatter\': \'simple\', \'stream\': \'ext://sys.stdout\' }, \'file_info\': { \'class\': \'logging.handlers.RotatingFileHandler\', \'level\': \'INFO\', \'formatter\': \'detailed\', \'filename\': str(log_dir / \'app.log\'), \'maxBytes\': 10485760, # 10MB \'backupCount\': 5, \'encoding\': \'utf8\' }, \'file_error\': { \'class\': \'logging.handlers.RotatingFileHandler\', \'level\': \'ERROR\', \'formatter\': \'detailed\', \'filename\': str(log_dir / \'error.log\'), \'maxBytes\': 10485760, \'backupCount\': 10, \'encoding\': \'utf8\' }, \'queue_handler\': { \'class\': \'logging.handlers.QueueHandler\', \'queue\': { \'()\': \'queue.Queue\', \'maxsize\': 1000 } } }, \'loggers\': { \'\': { # root logger \'level\': \'INFO\', \'handlers\': [\'queue_handler\'] }, \'app\': { \'level\': \'DEBUG\', \'handlers\': [\'console\', \'file_info\', \'file_error\'], \'propagate\': False }, \'performance\': { \'level\': \'INFO\', \'handlers\': [\'file_info\'], \'propagate\': False } } } return configclass ProductionLoggingManager: \"\"\"生产环境日志管理器\"\"\" def __init__(self): self.config = create_production_logging_config() self.setup_logging() self.setup_queue_listener() def setup_logging(self): \"\"\"设置日志配置\"\"\" logging.config.dictConfig(self.config) def setup_queue_listener(self): \"\"\"设置队列监听器\"\"\" import queue import logging.handlers # 获取队列处理器 root_logger = logging.getLogger() queue_handler = None for handler in root_logger.handlers: if isinstance(handler, logging.handlers.QueueHandler): queue_handler = handler break if queue_handler: # 创建实际的处理器 file_handler = logging.handlers.RotatingFileHandler( \'logs/queue_app.log\', maxBytes=10485760, backupCount=5 ) file_handler.setFormatter( logging.Formatter( \'%(asctime)s [%(process)d:%(thread)d] %(name)s %(levelname)s: %(message)s\' ) ) # 启动队列监听器 self.queue_listener = logging.handlers.QueueListener( queue_handler.queue, file_handler, respect_handler_level=True ) self.queue_listener.start() def get_logger(self, name: str) -> logging.Logger: \"\"\"获取日志器\"\"\" return logging.getLogger(name) def shutdown(self): \"\"\"关闭日志系统\"\"\" if hasattr(self, \'queue_listener\'): self.queue_listener.stop() logging.shutdown()# 使用示例def demonstrate_production_logging(): \"\"\"演示生产环境日志使用\"\"\" log_manager = ProductionLoggingManager() # 获取不同类型的日志器 app_logger = log_manager.get_logger(\'app.service\') perf_logger = log_manager.get_logger(\'performance\') def simulate_application_work(): \"\"\"模拟应用程序工作\"\"\" app_logger.info(\"应用程序启动\") for i in range(100): app_logger.debug(f\"处理任务 {i}\") if i % 20 == 0: perf_logger.info(f\"性能检查点: 已处理 {i} 个任务\") if i == 50: app_logger.warning(\"达到中间检查点\") # 模拟错误 if i == 75: try: raise ValueError(\"模拟业务错误\") except ValueError as e: app_logger.error(f\"业务错误: {e}\", exc_info=True) app_logger.info(\"应用程序完成\") # 多线程测试 threads = [] for i in range(5): t = threading.Thread(target=simulate_application_work) threads.append(t) t.start() for t in threads: t.join() # 关闭日志系统 log_manager.shutdown()if __name__ == \"__main__\": demonstrate_production_logging()6. 监控与诊断
6.1 日志系统健康监控
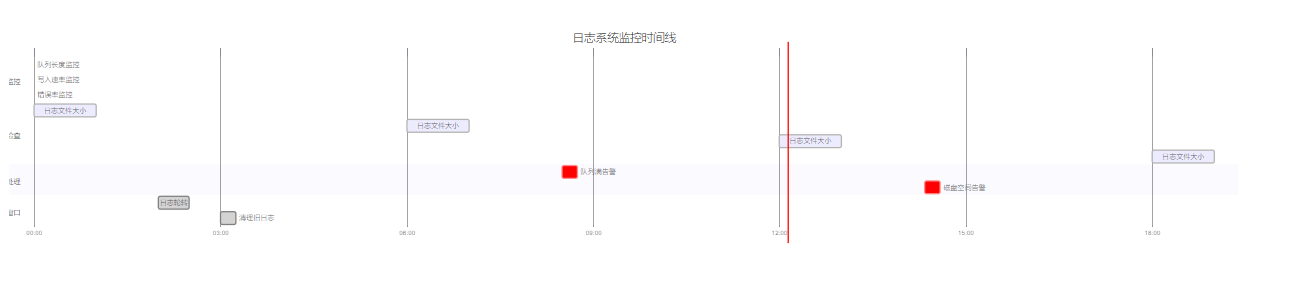
图5:日志系统监控与维护甘特图
6.2 诊断工具实现
import loggingimport threadingimport timeimport psutilimport jsonfrom typing import Dict, List, Anyfrom dataclasses import dataclass, asdictfrom datetime import datetime, timedelta@dataclassclass LoggingMetrics: \"\"\"日志系统指标\"\"\" timestamp: str queue_size: int queue_capacity: int logs_per_second: float error_rate: float memory_usage_mb: float thread_count: int handler_stats: Dict[str, Any]class LoggingDiagnostics: \"\"\"日志系统诊断工具\"\"\" def __init__(self, monitoring_interval: float = 1.0): self.monitoring_interval = monitoring_interval self.metrics_history: List[LoggingMetrics] = [] self.is_monitoring = False self.log_counter = 0 self.error_counter = 0 self.last_reset_time = time.time() # 监控线程 self.monitor_thread = None def start_monitoring(self): \"\"\"开始监控\"\"\" self.is_monitoring = True self.monitor_thread = threading.Thread(target=self._monitoring_loop, daemon=True) self.monitor_thread.start() print(\"日志系统监控已启动\") def stop_monitoring(self): \"\"\"停止监控\"\"\" self.is_monitoring = False if self.monitor_thread: self.monitor_thread.join() print(\"日志系统监控已停止\") def _monitoring_loop(self): \"\"\"监控循环\"\"\" while self.is_monitoring: try: metrics = self._collect_metrics() self.metrics_history.append(metrics) # 保持历史记录在合理范围内 if len(self.metrics_history) > 1000: self.metrics_history = self.metrics_history[-500:] # 检查告警条件 self._check_alerts(metrics) except Exception as e: print(f\"监控错误: {e}\") time.sleep(self.monitoring_interval) def _collect_metrics(self) -> LoggingMetrics: \"\"\"收集指标\"\"\" current_time = time.time() time_diff = current_time - self.last_reset_time # 计算速率 logs_per_second = self.log_counter / max(time_diff, 1) error_rate = self.error_counter / max(self.log_counter, 1) # 获取系统指标 process = psutil.Process() memory_usage = process.memory_info().rss / 1024 / 1024 # MB thread_count = threading.active_count() # 获取队列信息(如果存在) queue_size, queue_capacity = self._get_queue_info() # 获取处理器统计 handler_stats = self._get_handler_stats() metrics = LoggingMetrics( timestamp=datetime.now().isoformat(), queue_size=queue_size, queue_capacity=queue_capacity, logs_per_second=logs_per_second, error_rate=error_rate, memory_usage_mb=memory_usage, thread_count=thread_count, handler_stats=handler_stats ) # 重置计数器 self.log_counter = 0 self.error_counter = 0 self.last_reset_time = current_time return metrics def _get_queue_info(self) -> tuple: \"\"\"获取队列信息\"\"\" # 这里需要根据实际使用的队列处理器来实现 # 示例实现 try: root_logger = logging.getLogger() for handler in root_logger.handlers: if hasattr(handler, \'queue\'): queue = handler.queue if hasattr(queue, \'qsize\') and hasattr(queue, \'maxsize\'): return queue.qsize(), queue.maxsize return 0, 0 except: return 0, 0 def _get_handler_stats(self) -> Dict[str, Any]: \"\"\"获取处理器统计信息\"\"\" stats = {} root_logger = logging.getLogger() for i, handler in enumerate(root_logger.handlers): handler_name = f\"{type(handler).__name__}_{i}\" handler_stats = { \'type\': type(handler).__name__, \'level\': handler.level, \'formatter\': type(handler.formatter).__name__ if handler.formatter else None } # 如果处理器有自定义统计方法 if hasattr(handler, \'get_stats\'): handler_stats.update(handler.get_stats()) stats[handler_name] = handler_stats return stats def _check_alerts(self, metrics: LoggingMetrics): \"\"\"检查告警条件\"\"\" alerts = [] # 队列使用率告警 if metrics.queue_capacity > 0: queue_usage = metrics.queue_size / metrics.queue_capacity if queue_usage > 0.8: alerts.append(f\"队列使用率过高: {queue_usage:.1%}\") # 错误率告警 if metrics.error_rate > 0.05: # 5% alerts.append(f\"错误率过高: {metrics.error_rate:.1%}\") # 内存使用告警 if metrics.memory_usage_mb > 500: # 500MB alerts.append(f\"内存使用过高: {metrics.memory_usage_mb:.1f}MB\") # 线程数告警 if metrics.thread_count > 50: alerts.append(f\"线程数过多: {metrics.thread_count}\") if alerts: print(f\"[ALERT] {datetime.now()}: {\'; \'.join(alerts)}\") def increment_log_count(self): \"\"\"增加日志计数\"\"\" self.log_counter += 1 def increment_error_count(self): \"\"\"增加错误计数\"\"\" self.error_counter += 1 def get_recent_metrics(self, minutes: int = 5) -> List[LoggingMetrics]: \"\"\"获取最近的指标\"\"\" cutoff_time = datetime.now() - timedelta(minutes=minutes) recent_metrics = [] for metric in reversed(self.metrics_history): metric_time = datetime.fromisoformat(metric.timestamp) if metric_time >= cutoff_time: recent_metrics.append(metric) else: break return list(reversed(recent_metrics)) def generate_report(self) -> str: \"\"\"生成诊断报告\"\"\" if not self.metrics_history: return \"暂无监控数据\" recent_metrics = self.get_recent_metrics(10) # 最近10分钟 if not recent_metrics: return \"最近10分钟无监控数据\" # 计算统计信息 avg_logs_per_sec = sum(m.logs_per_second for m in recent_metrics) / len(recent_metrics) avg_error_rate = sum(m.error_rate for m in recent_metrics) / len(recent_metrics) avg_memory = sum(m.memory_usage_mb for m in recent_metrics) / len(recent_metrics) max_queue_size = max(m.queue_size for m in recent_metrics) report = f\"\"\"=== 日志系统诊断报告 ===时间范围: 最近10分钟数据点数: {len(recent_metrics)}性能指标:- 平均日志速率: {avg_logs_per_sec:.2f} logs/sec- 平均错误率: {avg_error_rate:.2%}- 平均内存使用: {avg_memory:.1f} MB- 最大队列长度: {max_queue_size}当前状态:- 线程数: {recent_metrics[-1].thread_count}- 队列使用: {recent_metrics[-1].queue_size}/{recent_metrics[-1].queue_capacity}- 内存使用: {recent_metrics[-1].memory_usage_mb:.1f} MB处理器状态:{json.dumps(recent_metrics[-1].handler_stats, indent=2, ensure_ascii=False)}\"\"\" return reportclass DiagnosticHandler(logging.Handler): \"\"\"带诊断功能的处理器包装器\"\"\" def __init__(self, target_handler: logging.Handler, diagnostics: LoggingDiagnostics): super().__init__() self.target_handler = target_handler self.diagnostics = diagnostics def emit(self, record): \"\"\"发送日志记录\"\"\" try: self.target_handler.emit(record) self.diagnostics.increment_log_count() except Exception as e: self.diagnostics.increment_error_count() self.handleError(record)# 使用示例def demonstrate_logging_diagnostics(): \"\"\"演示日志诊断功能\"\"\" # 创建诊断工具 diagnostics = LoggingDiagnostics(monitoring_interval=0.5) # 设置日志 logger = logging.getLogger(\'diagnostic_test\') base_handler = logging.StreamHandler() diagnostic_handler = DiagnosticHandler(base_handler, diagnostics) logger.addHandler(diagnostic_handler) logger.setLevel(logging.INFO) # 启动监控 diagnostics.start_monitoring() try: # 模拟日志活动 def log_worker(worker_id): for i in range(100): logger.info(f\"Worker {worker_id} message {i}\") time.sleep(0.01) # 模拟一些错误 if i % 30 == 0: try: raise ValueError(\"测试错误\") except ValueError: logger.error(\"模拟错误\", exc_info=True) # 启动多个工作线程 threads = [] for i in range(3): t = threading.Thread(target=log_worker, args=(i,)) threads.append(t) t.start() # 等待一段时间后生成报告 time.sleep(5) print(diagnostics.generate_report()) # 等待所有线程完成 for t in threads: t.join() # 最终报告 print(\"\\n=== 最终报告 ===\") print(diagnostics.generate_report()) finally: diagnostics.stop_monitoring()if __name__ == \"__main__\": demonstrate_logging_diagnostics()7. 总结与展望
经过深入的分析和实践,我们可以看到Python多线程日志错乱问题的复杂性远超表面现象。这个问题不仅涉及到logging模块的内部实现机制,还关联到操作系统的I/O调度、文件系统的原子性保证以及Python GIL的影响。
通过本文的探索,我发现解决多线程日志错乱的关键在于理解并发访问的本质。虽然Python的logging模块在Handler级别提供了基本的线程安全保护,但在高并发场景下,特别是涉及到复杂的格式化操作和频繁的I/O写入时,仍然存在竞态条件的风险。我们提供的多种解决方案各有优劣:QueueHandler适合大多数生产环境,异步处理器适合高性能要求的场景,而自定义同步机制则适合有特殊需求的定制化应用。
在实际项目中,我建议采用分层的日志架构:应用层使用简单的日志接口,中间层负责缓冲和批处理,底层负责实际的I/O操作。这样不仅能够有效避免并发问题,还能提供更好的性能和可维护性。同时,完善的监控和诊断机制是保证日志系统稳定运行的重要保障。
随着Python生态系统的不断发展,我们也看到了更多优秀的第三方日志库,如structlog、loguru等,它们在设计之初就考虑了并发安全性和性能优化。未来的日志系统将更加注重云原生环境的适配、结构化日志的支持以及与可观测性平台的集成。作为开发者,我们需要持续关注这些技术发展,选择最适合自己项目需求的解决方案。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
\"在多线程的世界里,日志不仅是程序的记录者,更是并发安全的试金石。只有深入理解其内在机制,才能构建真正可靠的日志系统。\"
参考链接
- Python官方文档 - logging模块
- Python Enhancement Proposal 282 - logging配置
- Python多线程编程指南
- logging.handlers模块详解
- 高性能Python日志最佳实践
关键词标签
Python多线程 logging模块 并发安全 竞态条件 QueueHandler

