【Python高阶开发】7. 工业数据血缘追踪入门到实战:OpenLineage手把手教程
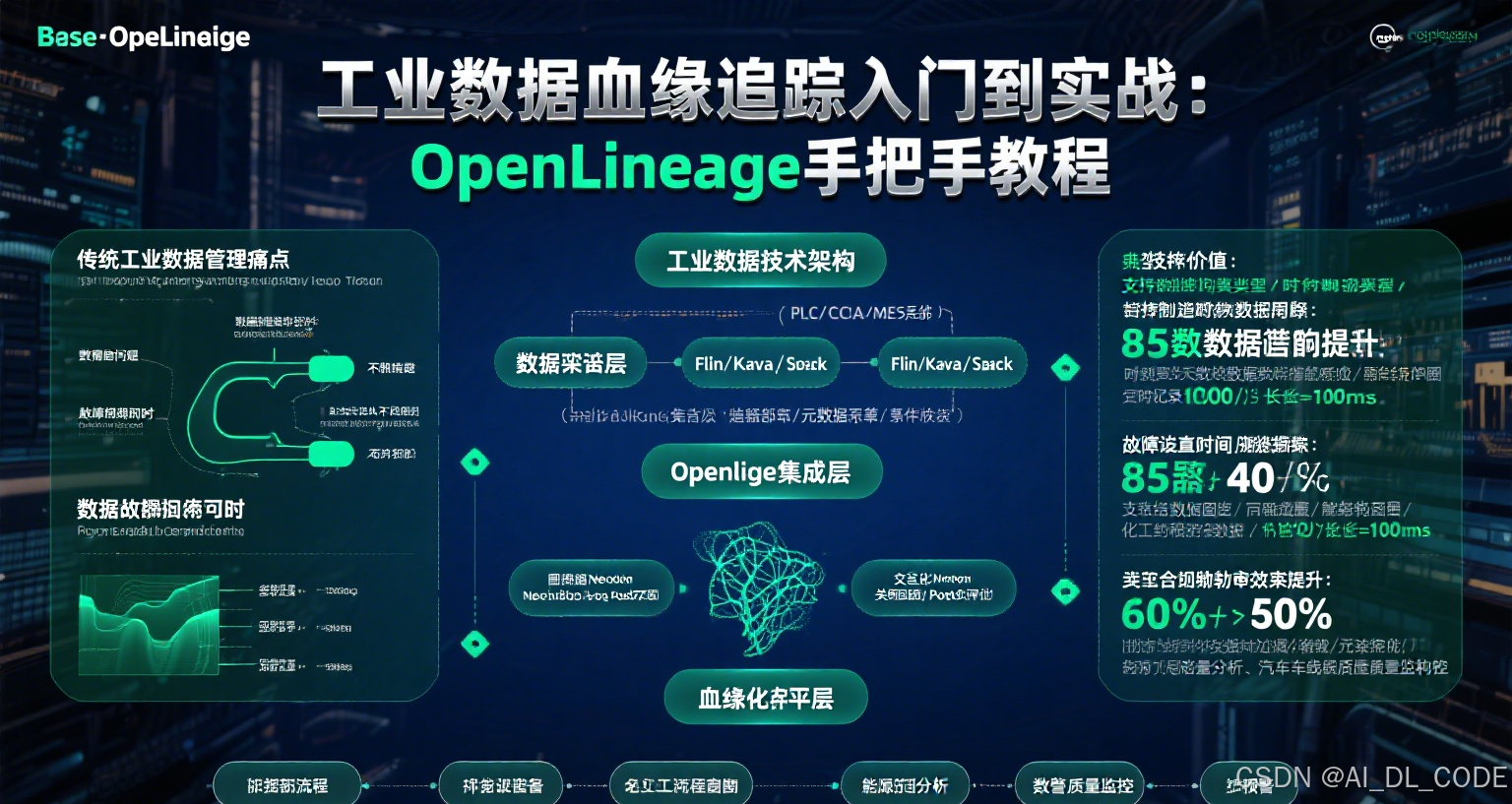
摘要:工业数据从传感器到决策的流转链路复杂,数据血缘追踪是解决“数据从哪来、到哪去、谁处理过”的核心技术。本文从工业场景实际需求出发,用通俗语言讲解数据血缘的价值,介绍开源工具OpenLineage的基本原理,并通过虚拟半导体工厂案例,手把手教你部署OpenLineage、集成工业数据处理流程、追踪设备到模型的全链路数据。内容包括Docker部署、Spark集成、工业设备元数据扩展等实操步骤,附完整代码和执行效果。即使是新手,也能跟着完成从部署到问题排查的全流程,让工业数据真正可追溯、可信任。
优质专栏欢迎订阅!
【DeepSeek深度应用】【Python高阶开发:AI自动化与数据工程实战】
【机器视觉:C# + HALCON】【大模型微调实战:平民级微调技术全解】
【人工智能之深度学习】【AI 赋能:Python 人工智能应用实战】
【AI工程化落地与YOLOv8/v9实战】【C#工业上位机高级应用:高并发通信+性能优化】
【Java生产级避坑指南:高并发+性能调优终极实战】【Coze搞钱实战:零代码打造吸金AI助手】
文章目录
- 【Python高阶开发】7. 工业数据血缘追踪入门到实战:OpenLineage手把手教程
-
- 关键词
- 一、为什么工业数据需要“血缘”?
-
- 1.1 工业数据的“糊涂账”问题
- 1.2 数据血缘能解决什么?
- 二、认识OpenLineage:工业血缘的“记账本”
-
- 2.1 OpenLineage是什么?
- 2.2 OpenLineage核心组件
- 2.3 为什么选OpenLineage做工业血缘?
- 三、OpenLineage实操:从部署到入门
-
- 3.1 环境准备
- 3.2 部署OpenLineage(Docker一键启动)
- 3.3 第一个血缘追踪:记录文件处理链路
-
- 3.3.1 准备Python环境
- 3.3.2 编写数据处理脚本
- 3.3.3 运行并查看结果
- 四、工业场景实战:半导体工厂数据追踪
-
- 4.1 场景说明
- 4.2 步骤1:记录设备数据采集血缘
-
- 4.2.1 自定义工业设备信息模块
- 4.2.2 OPC UA采集与血缘记录
- 4.3 步骤2:Spark处理与血缘集成
-
- 4.3.1 安装Spark与OpenLineage插件
- 4.3.2 编写Spark处理脚本
- 4.4 步骤3:通过血缘排查模型异常
-
- 4.4.1 在Marquez UI中追溯链路


