Kafka在Springboot项目中的实践_kafaka与boot项目
目录
1、kafka原理介绍
1.1、Kafka的ack机制
1.2、kafka集群组成
2、原生kafka消费
3、SpringBoot集成
前言:
在之前的介绍中,kafka里面的Topic可以进行多个分区:每个Partion内部是有顺序的、不可变的消息队列, 并且可以持续的添加。
每个 partition 是一个 append-only 的日志文件,消息按写入顺序严格排序。
基于以上诸多因素:Kafka 适合高吞吐量和流式数据处理。
如下图所示:
关于更多kafka消费模式的介绍,可参考:
kafka消费的模式及消息积压处理方案_kafka消费的三种模式-CSDN博客文章浏览阅读1.1k次,点赞24次,收藏27次。 Kafka消费积压(Consumer Lag)是指消费者处理消息的速度跟不上生产者发送消息的速度,导致消息在Kafka主题中堆积。1. 如果是Kafka消费能力不足,则可以考虑增加 topic 的 partition 的个数(提高kafka的并行度),同时提升消费者组的消费者数量,消费数 = 分区数 (二者缺一不可)2. 若是下游数据处理不及时,则提高每批次拉取的数量。批次拉取数量过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。_kafka消费的三种模式https://dyclt.blog.csdn.net/article/details/148747641?spm=1011.2415.3001.5331
关于kafka的原理介绍,可参考:
关于MQ之kafka的深入研究_mq kafaka-CSDN博客文章浏览阅读1.6k次,点赞22次,收藏15次。Kafka、RabbitMQ、RocketMQ 和 ActiveMQ 是流行的消息队列解决方案,它们在架构设计、性能、特性和适用场景上各有不同。Kafka 适合高吞吐量和流式数据处理,RabbitMQ 适合需要复杂路由和灵活性场景,RocketMQ 适用于高并发的应用场景,而 ActiveMQ 则适合企业级 Java 应用集成。_mq kafakahttps://dyclt.blog.csdn.net/article/details/148535599?spm=1011.2415.3001.5331
1、kafka原理介绍
1.1、Kafka的ack机制
producer在向kafka写入消息的时候,可以设置参数来确定是否确认kafka接收到数据,这个参数可设置 的值为 0,1,all。
0:
代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效 率最高。
1:
代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
all:
代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保 leader发送成功和所有的副本都完成备份。安全性最⾼高,但是效率最低。
⚠️注意:
如果往不存在的topic写数据,kafka会⾃动创建topic,partition和replication的数量 默认配置都是1。
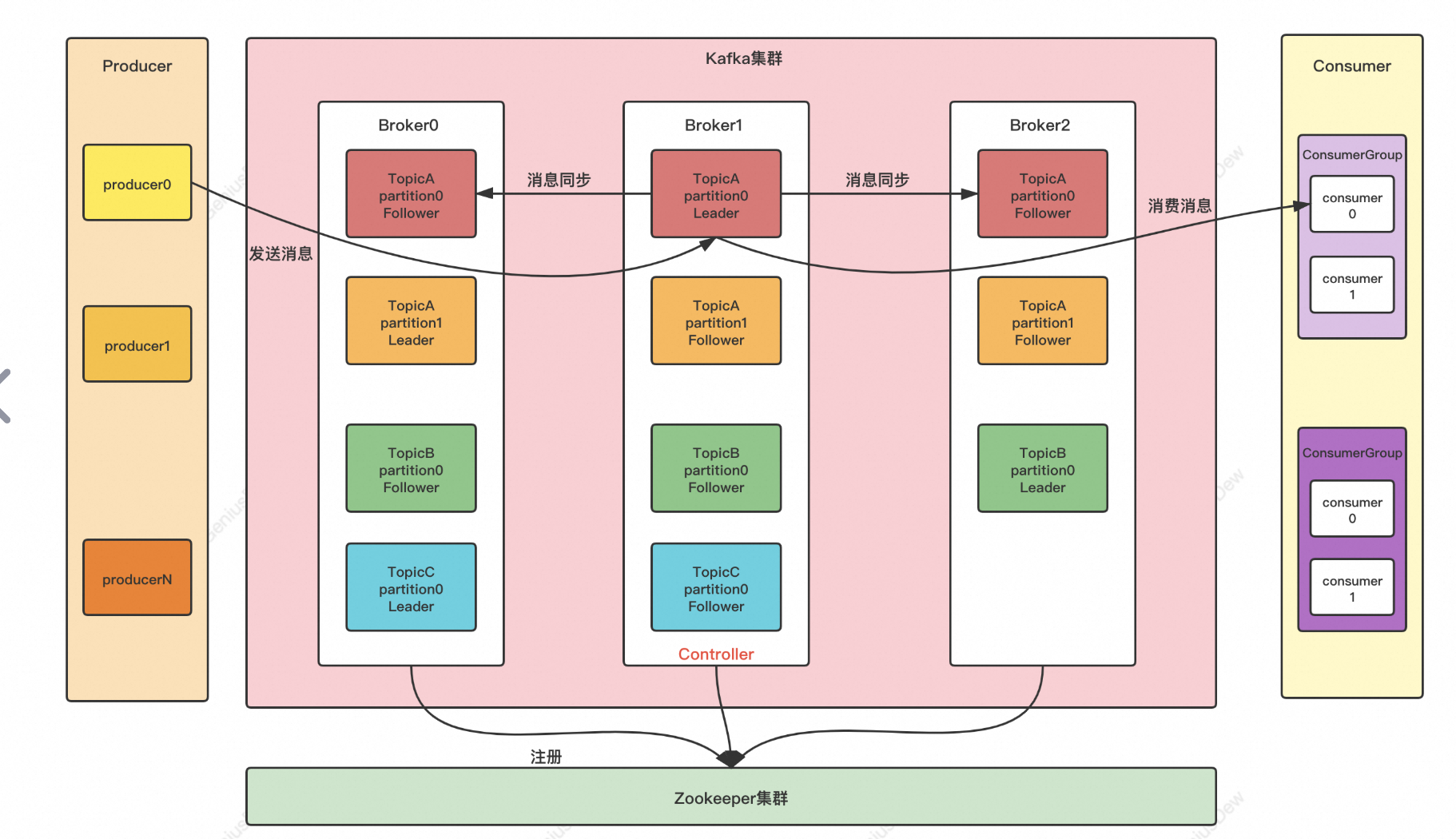
1.2、kafka集群组成
当消息从producer推送给broker,消费者会从broker的leader节点去读取数据。每个broker对应的不同的节点。
如下所示:
2、原生kafka消费
1、pom 引入核心依赖
引入依赖时,尽量选择和 kafka 版本对应的依赖版本。
org.apache.kafka kafka_2.13 4.0.02、提供者客户端代码
- 设置提供者客户端属性(可选属性都被定义在 ProducerConfig 类中)
- 设置要发送的消息
- 发送(有三种发送方式,下面代码中都有)
代码如下所示:
public class MyProducer { public static void main(String[] args) throws ExecutionException, InterruptedException { // 第一步:设置提供者属性 Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, \"192.168.2.28:9092\"); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); try (Producer producer = new KafkaProducer(props)) { // 第二步:设置要发送的消息 ProducerRecord record = new ProducerRecord(\"testTopic\", \"testKey\", \"testValue\"); // 第三部:发送消息 // send(producer, record); // sendSync(producer, record); sendASync(producer, record); } } /** * 发送方式1:单向推送,不关心服务器的应答 */ private static void send(Producer producer, ProducerRecord record) { producer.send(record); } /** * 发送方式2:同步推送,得到服务器的应答前会阻塞当前线程 */ private static void sendSync(Producer producer, ProducerRecord record) throws ExecutionException, InterruptedException { RecordMetadata metadata = producer.send(record).get(); System.out.println(metadata.topic()); System.out.println(metadata.partition()); System.out.println(metadata.offset()); } /** * 发送方式3:异步推送,不需等待服务器应答,当服务器有应答后会触发函数回调 */ private static void sendASync(Producer producer, ProducerRecord record) { producer.send(record, (metadata, exception) -> { if (exception != null) { throw new RuntimeException(\"向 kafka 推送失败\", exception); } System.out.println(metadata.topic()); System.out.println(metadata.partition()); System.out.println(metadata.offset()); }); }}3、消费者客户端代码:
消费者客户端要做三件事:
- 设置消费者客户端属性(可选属性都被定义在 ConsumerConfig 类中)
- 设置消费者订阅的主题
- 拉取消息
- 提交 offset(有两种提交方式,下面代码中都有)
public class MyConsumer { public static void main(String[] args) { // 第一步:设置消费者属性 Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, \"192.168.2.28:9092\"); props.put(ConsumerConfig.GROUP_ID_CONFIG, \"testGroup\"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); try (Consumer consumer = new KafkaConsumer(props)) { // 第二步:设置要订阅的主题 consumer.subscribe(Collections.singletonList(\"testTopic\")); while (true) { // 第三步:拉取消息,100 代表最大等待时间,如果时间到了还没有拉取到消息就不阻塞了继续往后执行 ConsumerRecords records = consumer.poll(Duration.ofNanos(100)); for (ConsumerRecord record : records) { System.out.println(record.value()); } // 第四步:提交 offset // consumer.commitSync(); // 同步提交,表示必须等到 offset 提交完毕,再去消费下⼀批数据 consumer.commitSync(); // 异步提交,表示发送完提交 offset 请求后,就开始消费下⼀批数据了。不⽤等到Broker的确认。 } } }}3、SpringBoot集成
springboot 版本是最常用的,比原生客户端使用方便。但是道理是一样的,底层也是原生客户端。
1、pom引入依赖
org.springframework.boot spring-boot-starter-parent 3.1.0 org.springframework.boot spring-boot-starter-web org.springframework.kafka spring-kafka 2、yaml 配置文件
把原生客户端中的属性配置,配置在 yaml 中。
如下所示:
spring: kafka: bootstrap-servers: 192.168.2.28:9092 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: testGroup key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer3、客户端代码
- 注入 KafkaTemplate
- 发送
@RestControllerpublic class ProducerController { /** * kafka */ private KafkaTemplate kafkaTemplate; @Autowired public void setKafkaTemplate(KafkaTemplate kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } @GetMapping(\"/test\") public void send() { // 发送 kafka 消息 kafkaTemplate.send(\"testTopic\", \"testKey\", \"testValue\"); }}4、消费者
只需要监听主题就可以,如下所示:
@RestControllerpublic class ConsumerController { // 监听 kafka 消息 @KafkaListener(topics = {\"testTopic\"}) public void test(ConsumerRecord record) { System.out.println(record.value()); }}总结
Kafka 是一个强大的分布式流处理平台,凭借其 高吞吐量、持久化、水平扩展 和 实时处理能力,成为大数据和实时系统的核心组件。
参考文章:
1、Kafka 在 java 中的基本使用_java kafka-CSDN博客文章浏览阅读973次,点赞5次,收藏5次。Kafka 在 java 中的基本使用、原生客户端、集成 springboot_java kafkahttps://blog.csdn.net/ougaii_/article/details/146944003?spm=1000.2115.3001.10526&utm_medium=distribute.pc_feed_blog_category.none-task-blog-classify_tag-19-146944003-null-null.nonecase&depth_1-utm_source=distribute.pc_feed_blog_category.none-task-blog-classify_tag-19-146944003-null-null.nonecase

