微软行星云计算:微软研究院城市创新小组领导的低成本空气质量监测网络数据集
项目Eclipse网络概述
项目Eclipse网络是一个低成本的城市空气质量监测网络,由微软研究院城市创新小组领导的研究项目。目前在美国伊利诺伊州芝加哥市部署了超过100个监测点。
部署信息
- 部署时间:2021年7月开始
- 合作机构:
- 芝加哥市政府
- 万物互联项目
- JCDecaux芝加哥
- 环境法律与政策中心
- 当地环境正义组织
数据存储
- 存储位置:Azure Blob Storage西欧区域
- 容器地址:
https://ai4edataeuwest.blob.core.windows.net/eclipse - 数据组织:
- 按日期文件夹存储(Chicago/YYYY-MM-DD)
- 每个快照包含7天的传感器数据(Parquet格式)
- 示例路径:
https://ai4edataeuwest.blob.core.windows.net/eclipse/chicago/2022-01-01/data_*.parquet
其他信息
- 校准文档:提供Pm2.5、O3和NO2校准的PDF文档
- 引用文献:Daepp, Cabral, Ranganathan等(2022)《Eclipse:一种用于城市低成本、超本地环境监测的端到端平台》
- 联系方式:msrurbanops@microsoft.com
- 项目主页:Microsoft Research中的Eclipse项目概述
数据集技术信息
基本信息
数据列说明
数据集资源
案例
项目 Eclipse 网络是一个低成本的城市空气质量监测网络,由微软研究院的城市创新小组领导的研究项目。
clipse 项目数据以一组 parquet 文件形式分布——每周一个。我们可以使用 STAC API 来搜索特定一周的文件。
import pystac_clientimport planetary_computercatalog = pystac_client.Client.open( \"https://planetarycomputer.microsoft.com/api/stac/v1\", modifier=planetary_computer.sign_inplace,)search = catalog.search(collections=[\"eclipse\"], datetime=\"2022-03-01\")items = search.item_collection()print(f\"Found {len(items)} item\")item = items[0]itemimport geopandasimport pandas as pdasset = item.assets[\"data\"]df = pd.read_parquet( asset.href, storage_options=asset.extra_fields[\"table:storage_options\"])df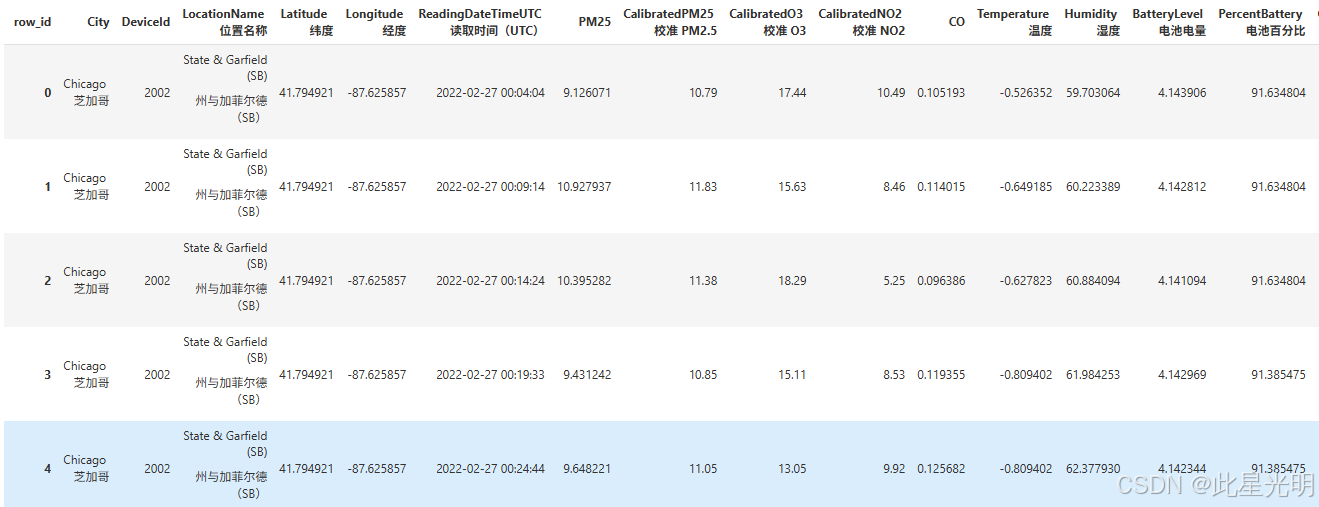
df = df[(df.Longitude > -89) & (df.Longitude < -86)]len(df)df.CalibratedO3ts = df.resample(\"h\", on=\"ReadingDateTimeUTC\")[ [\"CalibratedPM25\", \"Humidity\", \"CalibratedO3\", \"CalibratedNO2\", \"CO\"]].mean()ts.plot(subplots=True, sharex=True, figsize=(12, 12));该数据集包含每个传感器的许多观测值。我们可以使用 geopandas 绘制每个传感器的位置,只需选择该传感器的第一个观测值即可。
gdf = geopandas.GeoDataFrame( df, geometry=geopandas.points_from_xy(df.Longitude, df.Latitude), crs=\"epsg:4326\")gdf[[\"LocationName\", \"geometry\"]].drop_duplicates( subset=\"LocationName\").dropna().explore(marker_kwds=dict(radius=8))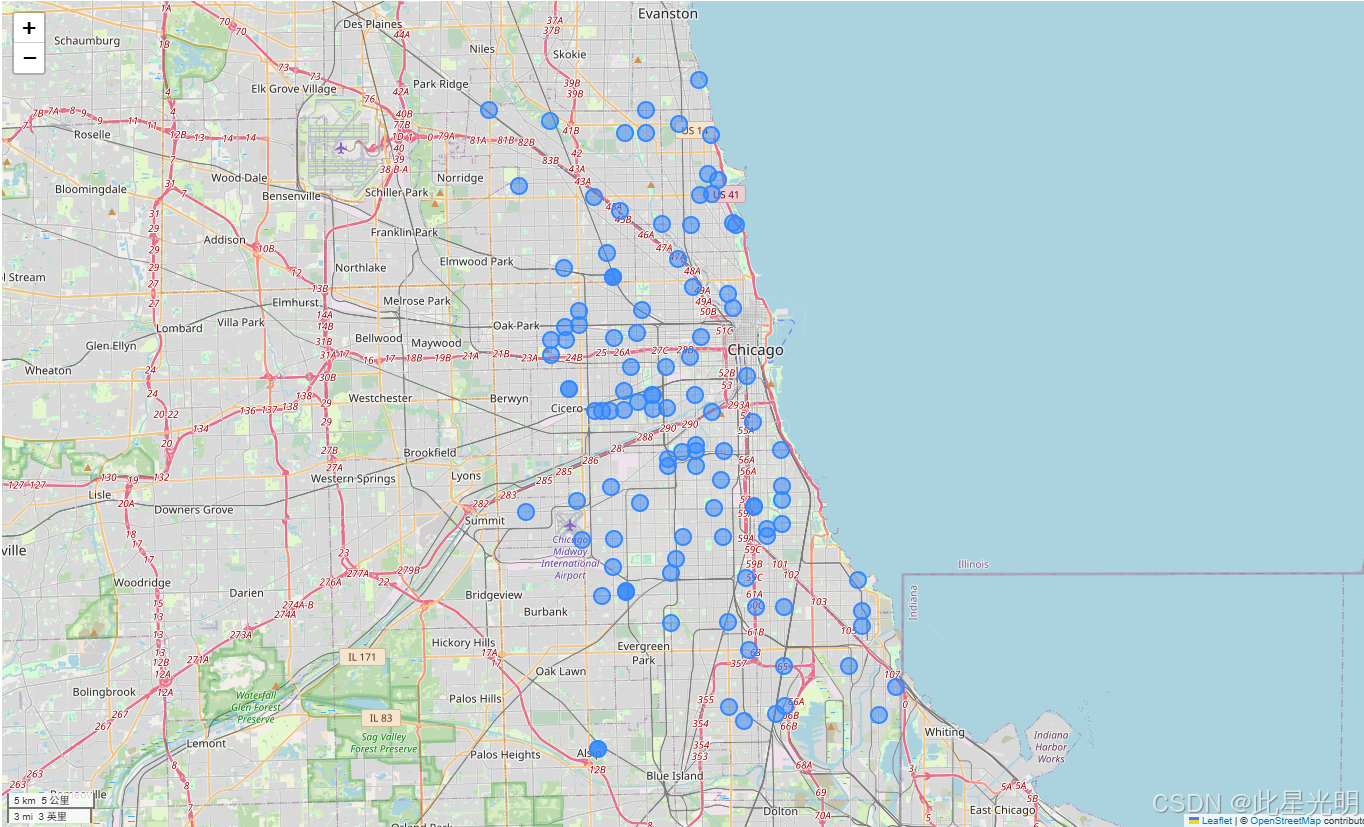
使用命名聚合,我们可以计算每个传感器的汇总数据,并在地图上绘制。将鼠标悬停在标记上,即可查看每个传感器的平均校准 PM2.5 值。
average_pm25 = geopandas.GeoDataFrame( gdf.groupby(\"LocationName\").agg( mean_pm25=(\"CalibratedPM25\", \"mean\"), geometry=(\"geometry\", \"first\") ), crs=\"epsg:4326\",)average_pm25.explore( marker_kwds=dict(radius=10),)读取完整数据集
STAC 集合包含一个 data 资产,它链接到 Parquet 数据集的根目录。这可以用来跨时间读取所有数据。我们将使用 Dask 来读取数据集。
eclipse = catalog.get_collection(\"eclipse\")asset = planetary_computer.sign(eclipse.assets[\"data\"])import adlfsimport dask.dataframe as ddfs = adlfs.AzureBlobFileSystem(**asset.extra_fields[\"table:storage_options\"])files = [f\"az://{x}\" for x in fs.ls(asset.href)]ddf = dd.read_parquet( files, storage_options=asset.extra_fields[\"table:storage_options\"])ddf
