地瓜机器人智慧医疗——贰贰玖想要分享的关于使用惯导的一些思路_地瓜机器人智慧医疗挑战赛成绩
前言
在第20届全国大学生智能车竞赛(智慧医疗机器人创意赛)中,我们贰贰玖拿下国一。在这里,作为队长兼技术主力兼机师兼……我想分享一下在备赛过程中的一些思路。当然,为了不把比赛搞成全都是20s以内,竞争激烈到前后几名差0.几秒,我不会开源我们的惯导和避障思路(实在太简单,太容易实现了)。
这是我们两年的备赛日记,也有我们第二年区域赛和国赛的全流程。
【贰贰玖|从省三到国一,从巡线到路径规划到惯导+纯视觉避障的贰贰玖智能车日记-哔哩哔哩】 https://b23.tv/IDJyM2P
下面面我会讲一下我们的网络问题怎么解决,上位机的一些辅助处理,如何半场扫码,如何准确返回 P 点,修改stm32,以及修改车的ekf.yaml。
网络问题
我们第一年参赛的时候,也和大家一样,遇到了非常严重的网络问题——上位机延迟(有位湘潭大学的学长帮我们配置了一下路由器,完全没有延时,现在还是非常想感谢他),所以第二年非常重视这个问题。
第二年备赛,我们一开始用的是华为AX3 Pro,在校赛的时候,其他队伍连都连不上小车,我们跑得飞起来,跑出了18s。在校赛拿到第一名之后发了奖金840元,立刻就买了华为BE7 Pro。(一开始买的是华为企业级路由器,但是配了好几天还是没有成功,退掉了)以后调车就是带着这个路由器去调,在实验室没有延时。在赛场上用的是165信道,因为这个信道基本没人用。(也算是运气好,因为区域赛前的调试,在165信道只有4个路由器,但发现有个ROGxxx,跑起来开始延时了)

图1 刚到手华为BE7 Pro路由器

图2 华为BE7 Pro路由器
有了路由器,那就不要用电脑的板载无线网卡去连路由器,用就用网线(上位机和开终端的最好都这样)。
在区域赛调试的时候,我们用路由器的中继模式上网,但是开了中继模式之后不能改信道,刚开始2轮是没有延时的,但是第3轮开始就延时,卡成ppt了。当时果断放弃上网,不用云端API了,转用备用方案——本地部署的qwen(特别垃圾,但逼一下它,还是会憋出几个字)。
在现场有很多队很有实力但是没能进国赛,我猜大部分是因为网络问题。我觉得(是我觉得哈,如果有不对的地方不要骂我)今年加的图生文环节不太合理。大家都知道现场网络问题很严重,但是联网调用云端API可以有更快更高质量的结果,本地部署的特别差(除非有钱买卡)。要么用调云端API,在现场卡死;要么铤而走险,用本地部署的大模型赌裁判不会特别关注图生文结果。
上位机辅助处理
如果仔细看我B站发的上位机视角,会发现桶和P点的底部会有红线。其实是我在上位机的bridge_client.py 单独又开了一个py脚本来接收YOLO结果,用python的tkinter库画出来的。画出障碍物的位置可以帮助机师快速确定障碍物的位置。(最初的想法是把障碍物在地图上标出来,就像游戏旁边的小地图,但是效果不好就放弃了。)
import tkinter as tkroot = tk.Tk()root.overrideredirect(True)root.geometry(\"900x680+192+215\")root.attributes(\"-topmost\", True)root.attributes(\"-transparentcolor\", \"white\")canvas = tk.Canvas(root, width=900, height=680, bg=\"white\", highlightthickness=0)canvas.pack()class LLM2Origincar(): def __init__(self, host, port): self.ros = None self.host = host self.port = port self.roadblock_list = [] self.end_list = [] self.init_ros() self.init_topic() self.init_thread() self.keep() ... def init_topic(self): ... self.yolo_sub = Topic(self.ros, \'/hobot_dnn_detection\', \'ai_msgs/msg/PerceptionTargets\', latch = True) self.yolo_sub.subscribe(self.yolo_sub_callback) ... def yolo_sub_callback(self, msg): self.roadblock_list.clear() self.end_list.clear() for target in msg[\'targets\']: if target[\'type\'] == \'roadblock\': rect = target[\'rois\'][0][\'rect\'] self.roadblock_list.append({ \'x\':rect[\'x_offset\'], \'w\':rect[\'width\'], \'b\':rect[\'y_offset\'] + rect[\'height\'], }) elif target[\'type\'] == \'end\':# and target[\'rois\'][0][\'confidence\'] > 0.5: rect = target[\'rois\'][0][\'rect\'] self.end_list.append({ \'x\':rect[\'x_offset\'], \'y\':rect[\'y_offset\'], \'w\':rect[\'width\'], \'b\':rect[\'y_offset\'] + rect[\'height\'], \'c\':target[\'rois\'][0][\'confidence\'], }) def keep(self): try: while True: canvas.delete(\"all\") # 清空画布 canvas.create_line(141, 0, 141, 680, fill=\"red\", width=1) canvas.create_line(689, 0, 689, 680, fill=\"red\", width=1) if self.roadblock_list: for obst in self.roadblock_list: b = int(obst[\'b\'] * 1.42) # 680 / 480 canvas.create_line( int(obst[\'x\'] * 1.41), # 900 / 640 b, int( ( obst[\'x\'] + obst[\'w\'] ) * 1.41 ), # 900 / 640 b, fill=\"red\", width=2 ) if self.end_list: for end in self.end_list: x1 = int(end[\'x\'] * 1.41) y1 = int(end[\'y\'] * 1.41) x2 = int( ( end[\'x\'] + end[\'w\'] ) * 1.41 ) # 900 / 640 y2 = int(end[\'b\'] * 1.42) # 680 / 480 canvas.create_line( x1, y2, x2, y2,fill=\"blue\", width=1) canvas.create_text(int((x1+x2)/2), (y1-20) if (y1-20) > 0 else 0, text=\"conf:{:.2f}\".format(end[\'c\']), fill=\'cyan\') ...除了画出障碍物作为辅助,我们还加了几个按键来辅助任务之间的切换还有调用API
def keyboard_thread(self): # print(help_tips) while True: sleep(0.05) if keyboard.is_pressed(\'b\') or keyboard.is_pressed(\'B\'): # 信号连接正常 self.sign4return_pub.publish(self.sign4return_data) sleep(0.5) if keyboard.is_pressed(\'r\') or keyboard.is_pressed(\'R\'): # 激活键盘控制 self.sign4return_data[\'data\'] = 5 # C 区遥测 self.sign4return_pub.publish(self.sign4return_data) self.sign4return_data[\'data\'] = 0 sleep(0.5) if keyboard.is_pressed(\'p\') or keyboard.is_pressed(\'P\'): # 退出键盘控制 self.sign4return_data[\'data\'] = 6 # Task3 self.sign4return_pub.publish(self.sign4return_data) self.sign4return_data[\'data\'] = 0 sleep(0.5) if keyboard.is_pressed(\'j\') or keyboard.is_pressed(\'J\'): # 车那边处理标志 self.llm_data[\'data\'] = 1 self.llm_pub.publish(self.llm_data) sleep(1)半场扫码
大家应该都知道,小粉小橙前面的USB相机拍出来的照片很模糊。但是小橙有个非常大的优势——深度相机。深度相机可以获取深度信息,但是除了这个,它照出来的照片比USB相机清晰得多得多得多。用深度相机和USB相机同时拍出来的照片被我删掉了,大家可以自己来拍二维码对比一下。大家从下面这2个距离应该可以感受到深度相机扫码的优势:

图3 深度相机扫码

图4 USB相机扫码
还有一点,扫码节点千万不要一直开着,特别耗CPU。我们扫码的条件是,任务状态是任务一,且小车过了半场(即小车全局坐标的x超过2m)。下面就是我们扫码的节点:
import rclpyfrom rclpy.node import Nodeimport cv2import numpy as npfrom sensor_msgs.msg import Imagefrom std_msgs.msg import String, Int32from nav_msgs.msg import Odometryfrom origincar_msg.msg import Signfrom cv_bridge import CvBridgeTASK1 = 1TASK2_WAITFOR_CMD = 2TASK2 = 3TASK3 = 4TASK_STOP = 5class QrCodeDetection(Node): def __init__(self): super().__init__(\'QRcodeSub\') self.Sign4ReturnSub = self.create_subscription(Int32, \'sign4return\', self.sign4return_callback, 10) self.ImageSub = self.create_subscription(Image, \'/aurora/rgb/image_raw\', self.image_callback, 10) self.OdomSub = self.create_subscription(Odometry, \'/odom_combined\', self.Odom_callback, 10) self.qrcode_publisher = self.create_publisher(String, \"/qrcode_information\", 10) self.info_result = String() self.sign_publisher = self.create_publisher(Sign, \'/sign_switch\', 10) self.sign_msg = Sign() self.detector = cv2.wechat_qrcode_WeChatQRCode( \"/userdata/WorkSpace/codes/src/qrcode/qrcode/model/detect.prototxt\", \"/userdata/WorkSpace/codes/src/qrcode/qrcode/model/detect.caffemodel\", \"/userdata/WorkSpace/codes/src/qrcode/qrcode/model/sr.prototxt\", \"/userdata/WorkSpace/codes/src/qrcode/qrcode/model/sr.caffemodel\" ) self.bridge = CvBridge() self.node_run = False self.task = TASK1 def image_callback(self, msg): if self.node_run and ( self.task == TASK1 or self.task == TASK2 ): #cv2_image = self.bridge.imgmsg_to_cv2(msg, desired_encoding=\'bgr8\')[155:,:] cv2_image = self.bridge.imgmsg_to_cv2(msg, desired_encoding=\'mono8\')[155:,:] #cv2.imwrite(\"image.jpg\",cv2_image) res = self.detector.detectAndDecode(cv2_image)[0] if res: self.node_run = False # 停止运行扫码 for r in res: self.info_result.data = str(r) self.qrcode_publisher.publish(self.info_result) self.get_logger().info(\"\\033[94m{}\\033[0m\".format(self.info_result.data)) if self.info_result.data == \"AntiClockWise\":self.sign_msg.sign_data = 4 elif self.info_result.data == \"ClockWise\":self.sign_msg.sign_data = 3 else: # 数字表示try: data = int(r) if data % 2: # 奇数顺时针 self.sign_msg.sign_data = 3 else: # 偶数逆时针 self.sign_msg.sign_data = 4except: pass self.sign_publisher.publish(self.sign_msg) self.info_result.data = \"None\" self.sign_msg.sign_data = 0 else: return def sign4return_callback(self, msg): if msg.data == 0 or msg.data == -1: self.task = TASK1 self.node_run = False if msg.data == 5: # 遥操作 self.task = TASK2 elif msg.data == 6: # 退出遥操作 self.task = TASK3 def Odom_callback(self, msg): if self.task == TASK1 and msg.pose.pose.position.x > 2: self.node_run = True # 若车过了半场且是task1,则开启扫码 def main(args=None): rclpy.init(args=args) qrCodeDetection = QrCodeDetection() while rclpy.ok(): rclpy.spin(qrCodeDetection) qrCodeDetection.destroy_node() rclpy.shutdown()if __name__ == \'__main__\': main()我们没有把整张照片丢给wechat的扫码模型,而是裁掉了一部分,比如下面这张图片,我先取最近的扫码距离,把红线上面的给去掉,这样图像就小了很多。

图5 裁掉一部分图片
准确返回P点
我们准确返回 P 点的思路有 3 个,有一个是另一队的学弟跟我讲的。他们是任务二停车对准 P 点,然后退出遥操作,这样 P 点就在车的正前方,加上YOLO识别 P 点,也可以回去,但是这很看机师的操作(他们最后有一次成功返回,有一次失败了)。
我的思路是:校准 P 点的坐标。
思路1——使用地图的固定元素来校准。
这个思路要重置里程计,每次都在通道重置,那么相当于把原点设在了这里,这里计算出来的相对坐标可以直接用作全局坐标,用作后面的导航。
如果小车每次从任务二出来都停在同一个位置,然后重置里程计,那么一定会有一个终点可以让小车回去的。比如我每次都停在这个位置,那么一定有个坐标是可以回去的(以车头方向为x+,车左边为y+)。

图6 固定小橙的位置,终点是(1.9m, -1.5m)
但是正式比赛的时候,机师是最紧张的,很难做到每次都停的这么准确,所以得想办法校准,用地图的固定元素。
大家可以先想想,通道出来有什么是一定可以识别到的?

图7 大家找找地图固定元素
是不是很明显,前面有线。线在地图的位置绝对是固定的,那么接下来的操作就是在线上了。
有了线,那就先求线的相对位置(相对于小车的,因为重置了里程计)。求线的相对位置可以参考这位大佬发的逆透视变换的文章。
基于透视变换的单目摄像头单一平面障碍物深度信息获取算法 - 火花绝赞摸鱼中✨️![]() https://hibanaw.com/archives/171/我们先把车固定在一个位置,比如图6的位置,用小橙的USB相机拍一张照片,然后给终点让小橙跑过去,多试几次,每次都要放回原来的位置跑过去,小橙正好回去的点就是(1.9m, -1.5m)(记得记得记得是清空里程计之后再跑)。
https://hibanaw.com/archives/171/我们先把车固定在一个位置,比如图6的位置,用小橙的USB相机拍一张照片,然后给终点让小橙跑过去,多试几次,每次都要放回原来的位置跑过去,小橙正好回去的点就是(1.9m, -1.5m)(记得记得记得是清空里程计之后再跑)。

图8 固定位置的视角
这个 (1.9m, -1.5m) 是关键。有了一个点,接下来就是用逆透视变换求前面 2 根线的相对位置(必须是最近的 2 根,为什么是 2 根线后面会解释)
这样,我们就有了 3 个点的坐标,分别是 A,B,P。有了这 3 个点,我们再任意摆放车,比如图7的位置,再用逆透视变换计算图7视角下最近的 2 根线的相对位置。这样就又有了 2 个点,分别是A\',B\',一共有了 5 个点,现在就是用这 5 个点来计算 P\'。
问题简化一下:在原来坐标系下,我知道 A,B,P 3个点。原坐标系经过变换之后,我可以知道A\',B\',接下来我想求P’。
要求 P’,那就得先知道前后 2 个坐标系是怎么变换的,也就是前后 2 个坐标系之间的旋转矩阵R和平移变量 t。
利用已知的两个对应点对 (A, A\') 和 (B, B\') 来求解 R 和 t 。
对于点 A 和 A\':
A′ = RA + t (1)
对于点 B 和 B\':
B′ = RB + t (2)
将方程 (1) 和 (2) 相减:
A′ − B′=R( A − B )
令:
ΔAB = A − B
ΔA′B′ = A′ − B′
则:
ΔA′B′ = RΔAB
因此,旋转矩阵 R 可以这样求解:
R = ΔA′B′ ΔAB^(−1)
一旦得到 R,可以通过任一对点求解 t。比如,用 A 和 A\':
t = A′ − RA
最后,对于 P,其在新坐标系中的坐标 P′ 为:
P′ = RP + t
这就是校准的所有步骤了,用 2 根线的坐标去校准 P 点的坐标。
实际情况是二维平面,操作可以更简单:

大家把 C 换成 P 来看就可以了。
最后计算出来这个 P 点是非常准确的,用 python 写的代码(有些参数是固定的,大家可以先离线计算):
def end_point( x1, y1, x2, y2, x3, y3, x1_, y1_, x2_, y2_ ): delta_x = x1 - x2 delta_y = y1 - y2 delta_x_ = x1_ - x2_ delta_y_ = y1_ - y2_ den = delta_x ** 2 + delta_y ** 2 a = ( delta_x * delta_x_ + delta_y * delta_y_ ) / den # 旋转参数 a b = ( delta_x * delta_y_ - delta_y * delta_x_ ) / den # 旋转参数 b tx = x1_ - a * x1 + b * y1 # 平移 tx ty = y1_ - b * x1 - a * y1 # 平移 ty x3_ = a * x3 - b * y3 + tx # 变换后的 x3\' y3_ = b * x3 + a * y3 + ty # 变换后的 y3\' print(f\"(x1, y1): ({x1, y1}), (x2, y2): ({x2, y2}), (x3, y3): ({x3, y3}) delta x: {delta_x}, delta y: {delta_y}, den: {den}\") return x3_, y3_print( f\"end\': {end_point( ptx1, pty1, ptx2, pty2, 1.9, -1.5, ptx3, pty3, ptx4, pty4 )}\" )思路2——不重置里程计,使用YOLO识别 P 点结果来校正终点
我们比赛时候使用的就是这个思路,上一个思路要在通道处停一下,这个是不需要停下来,直接冲出去就行了。这个思路比上一个简单很多,能回去的概率非常大。
这个思路是,使用YOLO识别 P 点,然后还是用逆透视变换计算 P 点相对坐标,再通过小车的坐标计算这个P点的全局坐标。
# 单应性矩阵,计算全局坐标H = np.array([ [-4.66389128e-04, -2.26288030e-04, -4.92300831e-02], [ 7.59821540e-04, 5.20569143e-05, -2.33074608e-01], [-6.59643252e-04, -7.15022786e-03, 1.00000000e+00],]) def pixel2global(self, pixel_x, pixel_y): # 计算全局坐标,从像素到局部再到全局 pixel = np.array([pixel_x, pixel_y, 1], dtype=np.float32) # 应用逆透视变换矩阵 local = np.dot(H, pixel) # 归一化坐标 local /= local[2] local[0] += 0.25 # 摄像头坐标转车底盘坐标 car_cos = np.cos(self.current_pos[2]) car_sin = np.sin(self.current_pos[2]) global_x = self.current_pos[0] + car_cos * local[0] - car_sin * local[1] global_y = self.current_pos[1] + car_sin * local[0] + car_cos * local[1] return global_x, global_y将 P 点中心的像素坐标丢到这个函数里面,输出的就是校正之后的终点了(车头朝向为x+,车左边为y+)。因为全程不重置里程计,所以未校正的终点设为出发的原点(0.5m, 0.2m)。校正之前,小车的终点就是这个。
这种思路对YOLO的要求比较高,所以必须采集非常多的数据,我们在实验室采了 7k ,数据增强之后就有了差不多 2w2 ,训练出来的效果杠杠的。最后在比赛现场采了1k4,增强到7k,一共2w9张,加急训练了22小时。其中数据集有超过一半的是P点的。

采集数据的时候,这种只有一个小角或被桶挡住了或比较远看起来很扁的也贴上(凡是小车可以看到 P 点,哪怕是一点点也要标上,而且尽量采集多一些),这样训练出来也是可以识别到的,回去更轻松。不过要注意一下任务三出来的位置,可能会误识成 P 点,所以在任务三出来(包括白色网格那里)也要采集一点,不需要太多。




修改STM32源码
stm32源码我基本上都看过了,也找到了很多可以修改的地方。
最重要的是舵机转角。我找到了舵机转角的限制,但是转角对不对称跟有没有限制是没关系的,如果去掉限制,反而有可能会把前轮给跑坏。

所以,问题应该是出在了计算上面,计算舵机转角的地方也就只有这个多项式了。
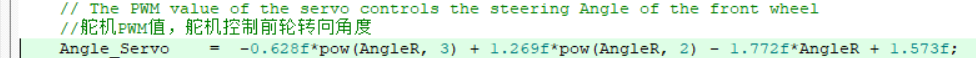
它的输入是右前轮的转角,输出是舵机角度。

右前轮的转向角度的限幅是(-0.49,0.32)(0.32是左转最大的角度,-0.49是右转最大角度),说明右前轮的角度在 -0.49 和 0.32 的时候,小车的舵机量应该是相同的。但是,直接把这 2 个值带入原来的多项式中,得到的舵机量是这样的:

这就说明小车左转转角小,右转转角大。用上位机跑的时候,确实是左转小,右转大。
调整多项式的二次项系数之后,大概让左右转的舵机量相同。


经过这样的调整之后,小车左转和右转是差不多的角度了。在上位机跑起来,左右转是对称的。
为了提高惯导的计算频率,我把串口发送的频率提高到了 50Hz,串口波特率提高到了 921600,而且也把其他没用到的外设(比如CAN,蓝牙)给关了,只留下串口1和串口3。

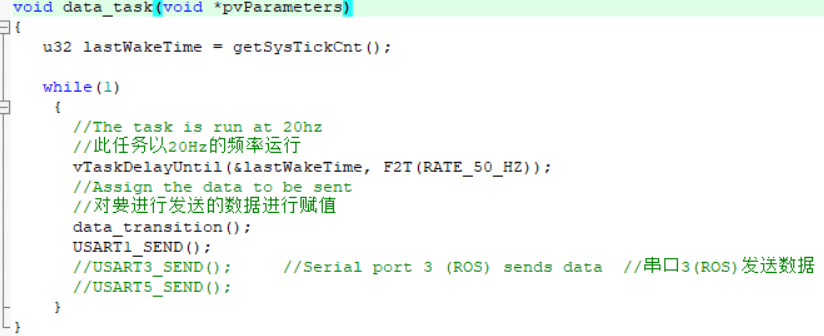
这里为什么用串口1呢?因为我们小橙底板的串口3有问题,会出现断连,干脆直接换成串口1了,也就是烧录口。(不知道为什么,把串口3关掉之后,oled会卡住,只能打开它了)
在X5上面,找到/root/dev_ws/origincar/origincar_base/launch/base_serial.launch.py,波特率改成921600,再编译一下就可以正常通信了(不用管clear_flag)。
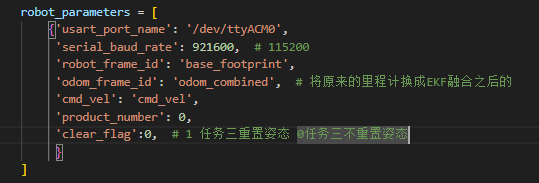
因为提高串口发送的频率到50Hz,所以,小车上EKF的计算频率也要设为50Hz。
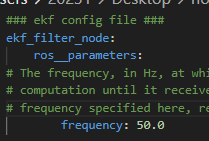
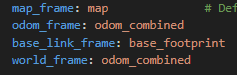
我们实际用下来,发现小车的odom_combined挺准的,一圈下来x和y偏得都不算太大。我们也改了一下ekf.yaml,大家可以参考一下我们改的地方。
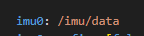
原来的/imu/data_raw是原始数据,/imu/data是经过滤波之后的。
除了删掉一些外设,我们还把电位器决定车型号的部分也删掉了,固定车型号为Ackerman;oled刷屏显示也把跟Ackerman无关的给删掉了。
补充
忘记把处理数据的代码放上来了,就在这里补充一下吧。
我们贴标签不是傻乎乎地全部自己来贴。我们先用以前训练过的模型贴一遍,然后再人工检查一遍。这样子操作,一个人不用一天时间就可以贴差不多6k(因为当时我一个人花了半天来贴)。
除此之外,我们还写了删除无效图片和无效标签的脚本(图片没有对应同名的标签或者标签没有对应同名的图片)、数据增强的脚本(没有旋转)和将数据分批次让队友来帮忙的脚本。
最好在检查完模型贴的标签之后,再进行数据增强。
代码我都放在后面。
后记
希望这份分享可以帮助大家接下来的比赛。
附:
这份是让模型贴标签的:
import argparseimport osimport shutilimport timefrom pathlib import Pathimport torchimport torch.backends.cudnn as cudnnimport cv2from models.experimental import attempt_loadfrom utils.datasets import LoadImagesfrom utils.utils import non_max_suppression, scale_coords, xyxy2xywhfrom utils.torch_utils import select_device, time_synchronized\'\'\' 用训练过的模型贴标签\'\'\'def auto_annotate(source, weights, output, img_size=640, conf_thres=0.25, iou_thres=0.45, device=\'\', view_img=False): \"\"\" 使用YOLOv5模型自动标注图像 参数: source (str): 输入图像文件夹路径 weights (str): 模型权重路径 output (str): 输出文件夹路径 img_size (int): 推理尺寸 conf_thres (float): 置信度阈值 iou_thres (float): IOU阈值 device (str): 使用的设备 (cpu, 0, 1, ...) view_img (bool): 是否显示结果图像 \"\"\" # 初始化 device = select_device(device) half = device.type != \'cpu\' # 半精度仅在CUDA上支持 # # 创建输出文件夹 # if os.path.exists(output): # shutil.rmtree(output) # 删除输出文件夹 # os.makedirs(output) # 创建新的输出文件夹 # os.makedirs(os.path.join(output, \'labels\')) # 创建标签文件夹 # 加载模型 model = attempt_load(weights, map_location=device) # 加载FP32模型 imgsz = img_size if half: model.half() # 转换为FP16 # 获取类别名称 names = model.module.names if hasattr(model, \'module\') else model.names # 设置数据加载器 dataset = LoadImages(source, img_size=imgsz) # 运行推理 t0 = time.time() img = torch.zeros((1, 3, imgsz, imgsz), device=device) # 初始化图像 _ = model(img.half() if half else img) if device.type != \'cpu\' else None # 运行一次 for path, img, im0s, _ in dataset: img = torch.from_numpy(img).to(device) img = img.half() if half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # 推理 t1 = time_synchronized() pred = model(img, augment=False)[0] # 应用NMS pred = non_max_suppression(pred, conf_thres, iou_thres, classes=None, agnostic=False) t2 = time_synchronized() # 处理检测结果 p, im0 = path, im0s.copy() txt_path = str(Path(output) / Path(p).stem) + (\'.txt\') # 标签保存路径 # 确保标签文件存在(即使为空) open(txt_path, \'w\').close() # 创建空文件或清空现有文件 # 归一化增益 whwh gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # 处理检测结果(如果有) if pred is not None: for i, det in enumerate(pred): # 每张图像的检测结果 if det is not None and len(det): # 将边界框从img_size调整到im0大小 det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round() # 写入结果 # 修改写入标签的部分: with open(txt_path, \'w\') as f: if det is not None and len(det): for *xyxy, conf, cls in reversed(det): xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 格式化输出:6位小数,无行末空格 line = \"%d %.6f %.6f %.6f %.6f\" % (cls, *xywh) f.write(line + \"\\n\") # 注意:换行符前无空格 else: f.write(\"\") # 空文件(或按需写入占位符) # 打印时间 (推理 + NMS) print(f\'{Path(p).name} done. ({t2 - t1:.3f}s)\') # 显示结果(可选) if view_img: cv2.imshow(Path(p).name, im0) if cv2.waitKey(1) == ord(\'q\'): # 按q退出 raise StopIteration print(f\'Done. ({time.time() - t0:.3f}s)\')if __name__ == \'__main__\': parser = argparse.ArgumentParser() parser.add_argument(\'--source\', type=str, default=\'dataset_process/new1/images\', help=\'输入图像文件夹路径\') parser.add_argument(\'--weights\', type=str, default=\'runs/2025.7.28/weights/last.pt\', help=\'模型权重路径\') parser.add_argument(\'--output\', type=str, default=\'dataset_process/new1/labels\', help=\'输出标签路径\') parser.add_argument(\'--img-size\', type=int, default=640, help=\'推理尺寸 (像素)\') parser.add_argument(\'--conf-thres\', type=float, default=0.25, help=\'目标置信度阈值\') parser.add_argument(\'--iou-thres\', type=float, default=0.45, help=\'NMS的IOU阈值\') parser.add_argument(\'--device\', default=\'\', help=\'cuda设备, 如 0 或 0,1,2,3 或 cpu\') parser.add_argument(\'--view-img\', action=\'store_true\', help=\'显示结果\') opt = parser.parse_args() print(opt) with torch.no_grad(): auto_annotate( source=opt.source, weights=opt.weights, output=opt.output, img_size=opt.img_size, conf_thres=opt.conf_thres, iou_thres=opt.iou_thres, device=opt.device, view_img=opt.view_img )这份是删除无效数据的:
import osfrom pathlib import Pathdef remove_invalid_images_labels(image_dir, label_dir): \"\"\" 删除无效的图片和标签文件(标签为空或不存在) 参数: image_dir (str): 图片文件夹路径 label_dir (str): 标签文件夹路径 \"\"\" deleted_images = 0 deleted_labels = 0 # 遍历图片文件夹 for image_file in os.listdir(image_dir): if image_file.lower().endswith((\'.jpg\', \'.png\', \'.jpeg\')): image_path = os.path.join(image_dir, image_file) label_path = os.path.join(label_dir, Path(image_file).stem + \'.txt\') # 检查标签文件是否存在或为空 if not os.path.exists(label_path): os.remove(image_path) deleted_images += 1 print(f\"删除图片(无标签): {image_file}\") else: with open(label_path, \'r\') as f: content = f.read().strip() if not content: # 标签文件为空 os.remove(image_path) os.remove(label_path) deleted_images += 1 deleted_labels += 1 print(f\"删除无效数据: {image_file} 和对应标签\") print(f\"\\n操作完成!共删除: {deleted_images} 张图片, {deleted_labels} 个标签\")if __name__ == \'__main__\': # 设置路径(修改为你的实际路径) image_dir = os.path.join(os.path.dirname(__file__), \"new1/images/\") label_dir = os.path.join(os.path.dirname(__file__), \"new1/labels/\") # 确认操作 print(f\"即将检查:\\n图片目录: {image_dir}\\n标签目录: {label_dir}\") confirm = input(\"是否继续?(y/n): \").lower() if confirm == \'y\': remove_invalid_images_labels(image_dir, label_dir) else: print(\"操作已取消\")
这份是数据增强的:
import torchimport torchvision.transforms as Timport torchvision.transforms.functional as TFfrom pathlib import Pathimport shutilfrom PIL import Imageimport randomfrom multiprocessing import Poolimport os\'\'\' 数据增强\'\'\'class YOLOAugment: def __init__(self, output_dir): self.output_dir = output_dir Path(f\"{output_dir}/images\").mkdir(parents=True, exist_ok=True) Path(f\"{output_dir}/labels\").mkdir(parents=True, exist_ok=True) # 定义基础增强(仅影响图像) self.img_augment = T.Compose([ T.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.2), T.GaussianBlur(kernel_size=(3, 7)) ]) def apply_augment(self, img_path, label_path, aug_id): \"\"\"处理单张图像和对应标签\"\"\" # 读取原始数据 img = Image.open(img_path).convert(\'RGB\') with open(label_path) as f: bboxes = [list(map(float, line.strip().split())) for line in f] # 转换为Tensor格式 img_tensor = TF.to_tensor(img) bboxes_tensor = torch.tensor(bboxes) # 应用图像增强(不影响框) img_tensor = self.img_augment(img_tensor) # 保存增强结果 stem = Path(img_path).stem self._save_results(img_tensor, bboxes_tensor, stem, aug_id) return img, bboxes def _save_results(self, img_tensor, bboxes, stem, aug_id): \"\"\"保存增强图像和标签\"\"\" # 保存图像 aug_img = TF.to_pil_image(img_tensor) aug_img.save(f\"{self.output_dir}/images/{stem}_aug{aug_id}.jpg\") # 保存标签(YOLO格式) with open(f\"{self.output_dir}/labels/{stem}_aug{aug_id}.txt\", \'w\') as f: for bbox in bboxes.numpy(): line = \' \'.join(map(str, bbox)) f.write(line + \'\\n\') def process_file(args): \"\"\"多进程处理函数\"\"\" img_path, label_path, output_dir, aug_per_image = args augmenter = YOLOAugment(output_dir) for i in range(1, aug_per_image + 1): augmenter.apply_augment(img_path, label_path, i) # 保留原始文件 shutil.copy(img_path, f\"{output_dir}/images/{Path(img_path).name}\") shutil.copy(label_path, f\"{output_dir}/labels/{Path(label_path).name}\")if __name__ == \"__main__\": root_path = os.path.dirname(__file__) # 配置参数 TUDO input_dir = os.path.join(root_path, \"new1\") # 原始数据集路径 output_dir = os.path.join(root_path, \"new1_aug\") # 输出路径 aug_per_image = 3 # 每张图片生成4个增强版本 num_workers = 4 # 并行进程数 # 准备列表 tasks = [] for img_file in Path(f\"{input_dir}/images\").glob(\"*.*\"): if img_file.suffix.lower() in (\'.jpg\', \'.png\', \'.jpeg\'): label_file = Path(f\"{input_dir}/labels/{img_file.stem}.txt\") if label_file.exists(): tasks.append((str(img_file), str(label_file), output_dir, aug_per_image)) # 多进程处理 print(f\"开始增强 {len(tasks)} 张图像...\") with Pool(processes=num_workers) as pool: pool.map(process_file, tasks) # 统计结果 orig_count = len(tasks) aug_count = orig_count * aug_per_image print(f\"处理完成!\\n\" f\"- 原始图像保留: {orig_count} 张\\n\" f\"- 增强图像生成: {aug_count} 张\\n\" f\"- 总数据量: {orig_count + aug_count} 张\")这份是让队友打工的:
import osimport zipfileimport mathfrom pathlib import Path\'\'\' 将数据集分好份打包好\'\'\'def create_task_packs(images_dir, labels_dir, output_dir, tasks=3, label_txt=False): \"\"\" 创建包含匹配images和labels的task压缩包 :param images_dir: 图片文件夹路径 :param labels_dir: 标注文件夹路径 :param output_dir: 输出目录 :param tasks: 需要划分的任务数 \"\"\" # 获取匹配的文件对(确保严格对应) image_files = sorted([f for f in os.listdir(images_dir) if f.endswith((\'.jpg\', \'.png\'))]) label_files = sorted([f for f in os.listdir(labels_dir) if f.endswith(\'.txt\') ]) # 验证一致性 image_stems = {Path(f).stem for f in image_files} label_stems = {Path(f).stem for f in label_files} unmatched = image_stems.symmetric_difference(label_stems) if unmatched: print(f\"⚠️ 警告: 发现 {len(unmatched)} 个不匹配文件(示例: {list(unmatched)[:3]})\") print(\"建议先运行数据校验脚本修复不一致问题!\") return # 计算每个task应包含的文件数 total_pairs = len(image_files) pairs_per_task = math.ceil(total_pairs / tasks) print(f\"数据集统计:\") print(f\"- 图片数量: {len(image_files)}\") print(f\"- 标注数量: {len(label_files)}\") print(f\"- 将分成 {tasks} 个任务包,每个约 {pairs_per_task} 对数据\\n\") # 创建输出目录 os.makedirs(output_dir, exist_ok=True) for task_num in range(1, tasks + 1): start_idx = ( task_num - 1 ) * pairs_per_task end_idx = min( start_idx + pairs_per_task, total_pairs ) task_images = image_files[start_idx:end_idx] task_labels = [Path(f).stem + \'.txt\' for f in task_images ] # 自动匹配对应的labels zip_path = os.path.join(output_dir, f\"task_{task_num}.zip\") print(f\"创建任务包 {task_num}:\") print(f\"- 包含图片: {len(task_images)} 张\") print(f\"- 包含标注: {len(task_labels)} 个\") print(f\"- 保存到: {zip_path}\") with zipfile.ZipFile(zip_path, \'w\', zipfile.ZIP_DEFLATED) as zipf: # 添加图片 for img in task_images: img_path = os.path.join(images_dir, img) zipf.write(img_path, f\"images/{img}\") # 添加对应的标注 for label in task_labels: label_path = os.path.join(labels_dir, label) if os.path.exists(label_path): # 双重验证 zipf.write(label_path, f\"labels/{label}\") else: print(f\"⚠️ 缺失标注文件: {label}\") if label_txt is not False: label_info = Path(label_txt).open(\"r\").read() zipf.writestr(f\"labels/labels.txt\", label_info) # 每个任务里面都放进一个 labels.txt print(\"-\" * 50) print(f\"\\n🎉 任务包创建完成!共生成 {tasks} 个压缩包,保存在: {output_dir}\")if __name__ == \"__main__\": root_path = os.path.dirname(__file__) # 配置参数 dataset_dir = os.path.join(root_path, \"new1\") # 数据集根目录 output_dir = os.path.join(root_path, \"package\") # 输出目录 label_txt = os.path.join(root_path, \"labels.txt\") # 标签文件 num_tasks = 4 # 需要划分的任务数量 # 运行打包 create_task_packs( images_dir=os.path.join(dataset_dir, \"images\"), labels_dir=os.path.join(dataset_dir, \"labels\"), output_dir=output_dir, tasks=num_tasks, # label_txt=label_txt, )

