小红书hi lab开源多语言文档布局解析模型dots.ocr,1.7B小模型实现SOTA性能
dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。

dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。尽管其基础模型是一个17亿参数的“小模型”,但它依然实现了业界领先(SOTA)的性能。dots.ocr对多语言识别的良好性能弥补了开源社区的空白,不错的检测、识别能力也为多模态和大模型社区提供了宝贵的基础。
01、简介
dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。尽管其基础仅是一个17亿参数的”小模型“,但依然在多个benchmark上获得了匹配超大参数量闭源模型的业界领先(SOTA)性能。
- 性能强大:dots.ocr 在 OmniDocBench 基准测试上,针对文本、表格和阅读顺序三方面均取得了业界领先(SOTA)的性能,同时其公式识别效果可与豆包-1.5(Doubao-1.5)和 gemini2.5-pro 等更大规模的模型相媲美。
- 多语言支持:dots.ocr 在小语种上展现出强大的解析能力,在我们内部的多语言文档基准测试中,无论是在布局检测还是内容识别方面,都取得了显著的优势。
- 统一且简洁的架构:通过利用单一的视觉语言模型,dots.ocr 提供了一个比依赖复杂多模型流水线的方法更为精简的架构。任务切换仅需通过更改输入提示词(prompt)即可完成,证明了视觉语言模型(VLM)同样可以取得与 DocLayout-YOLO 等传统检测模型相媲美的检测效果。
- 高效与快速:dots.ocr 基于一个17亿参数的大语言模型构建,因此其推理速度优于多种更大规模的 VLM 方案。
github:
https://github.com/rednote-hilab/dots.ocr
hugginface:
https://huggingface.co/rednote-hilab/dots.ocr
demo:
https://dotsocr.xiaohongshu.com
多语种端到端识别性能对比
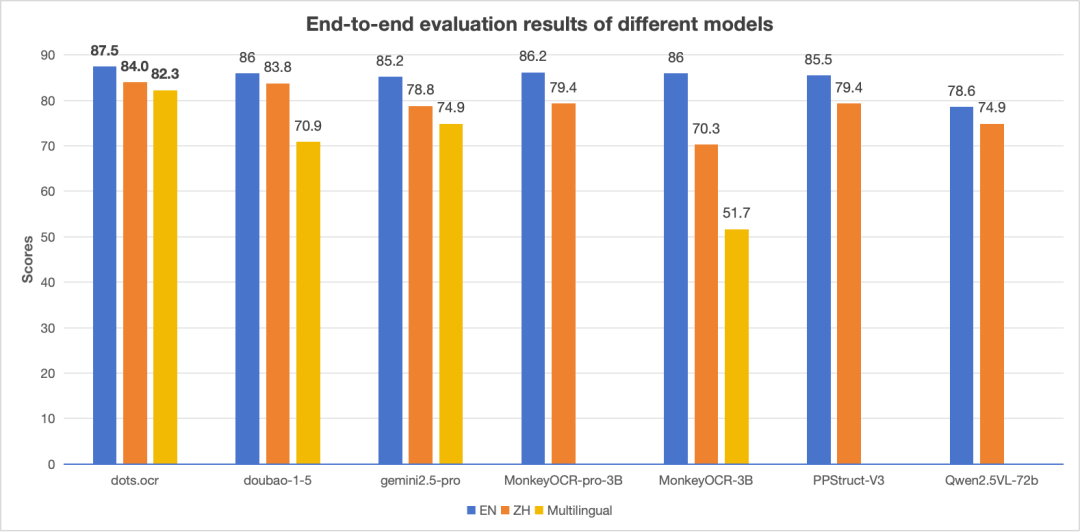
注:英文(EN)和中文(ZH)的指标是 OmniDocBench的端到端指标,多语言(Multilingual)的指标是dots.ocr-bench的端到端指标。
02、样例展示
2.1 公式解析样例



2.2 表格解析样例
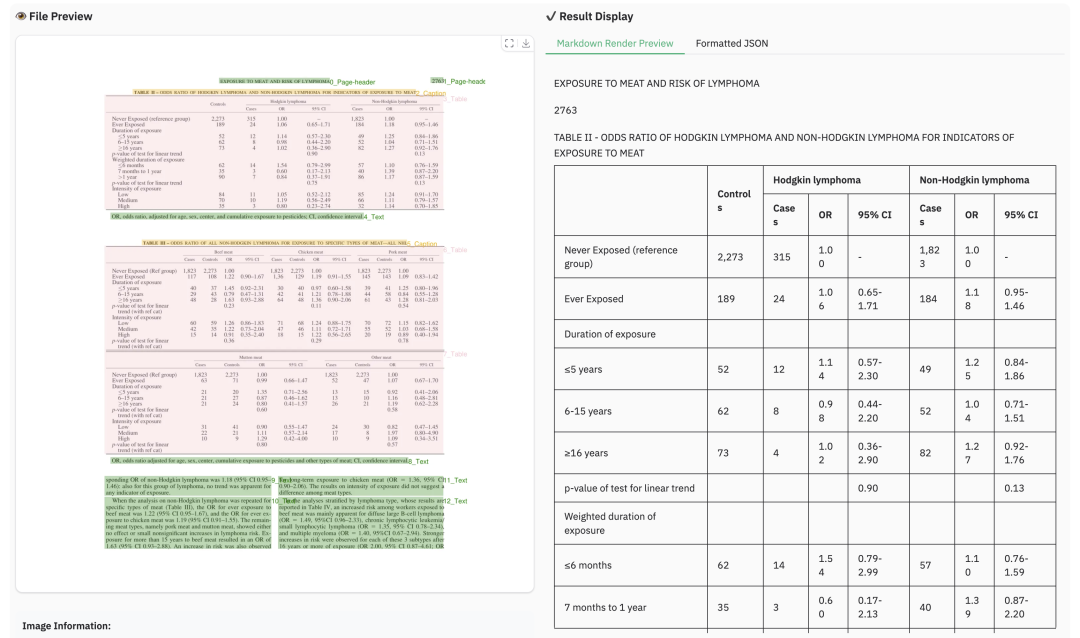
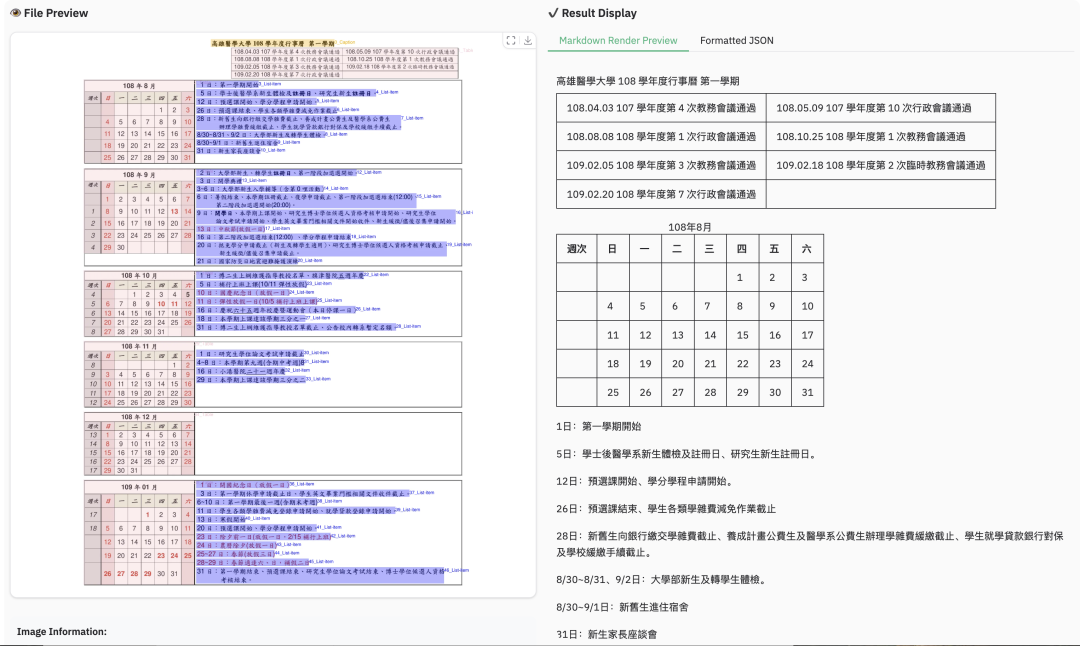
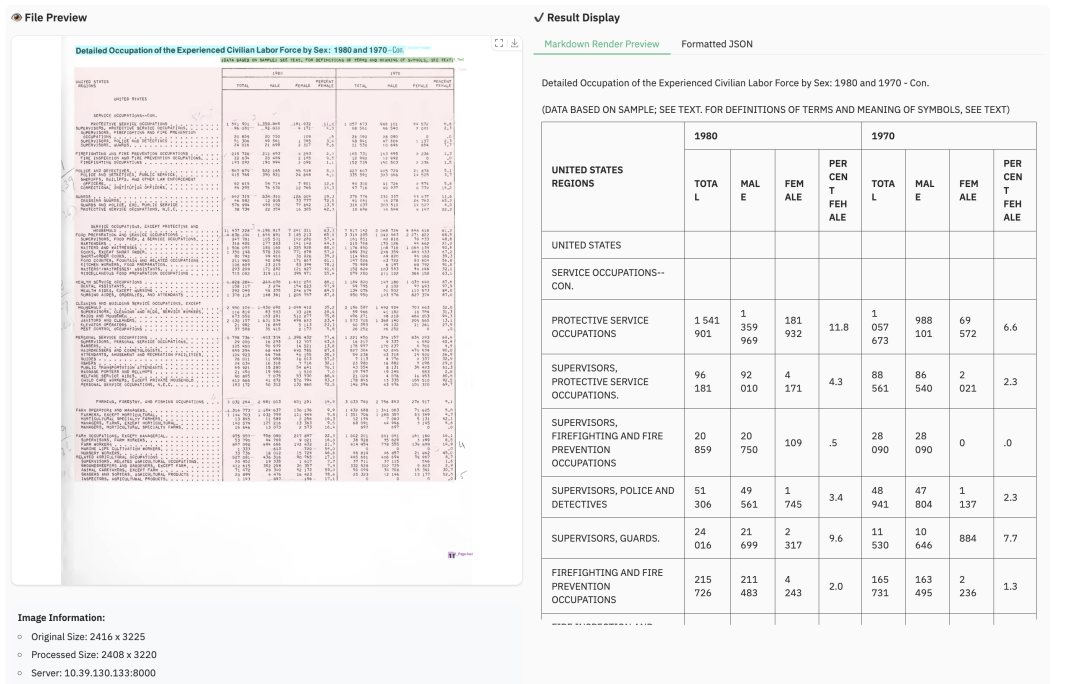
2.3 多语言解析样例




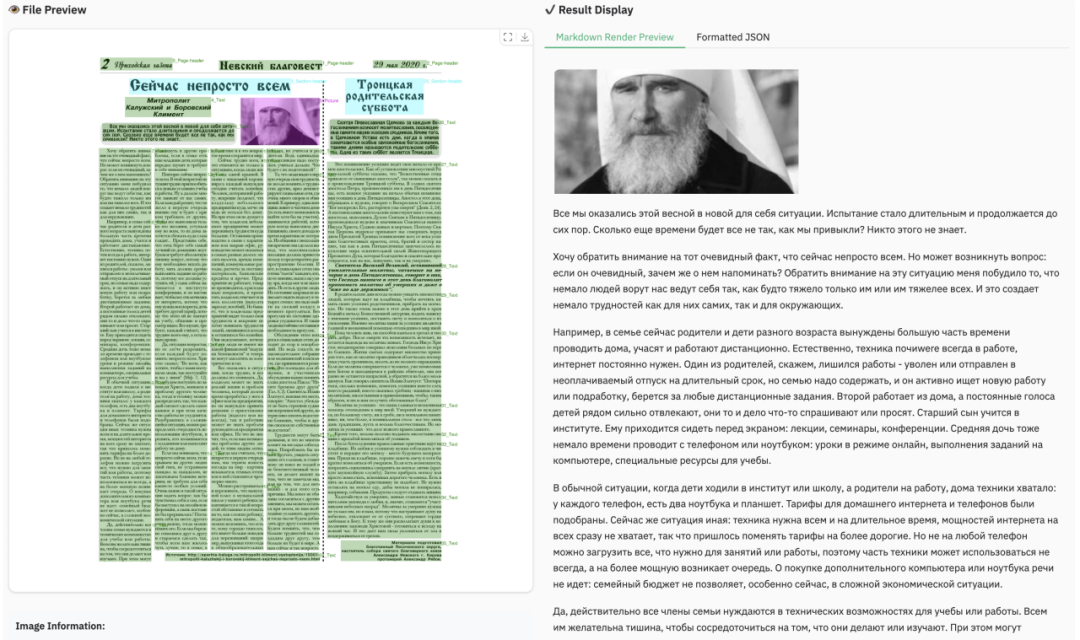
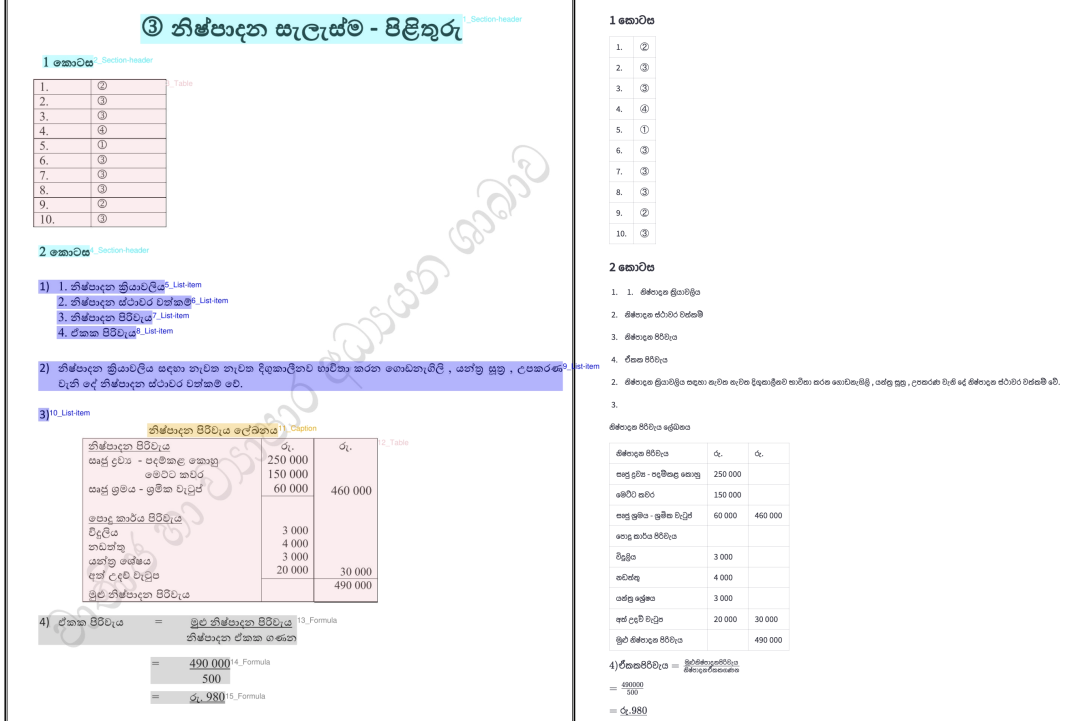
2.4 阅读顺序样例
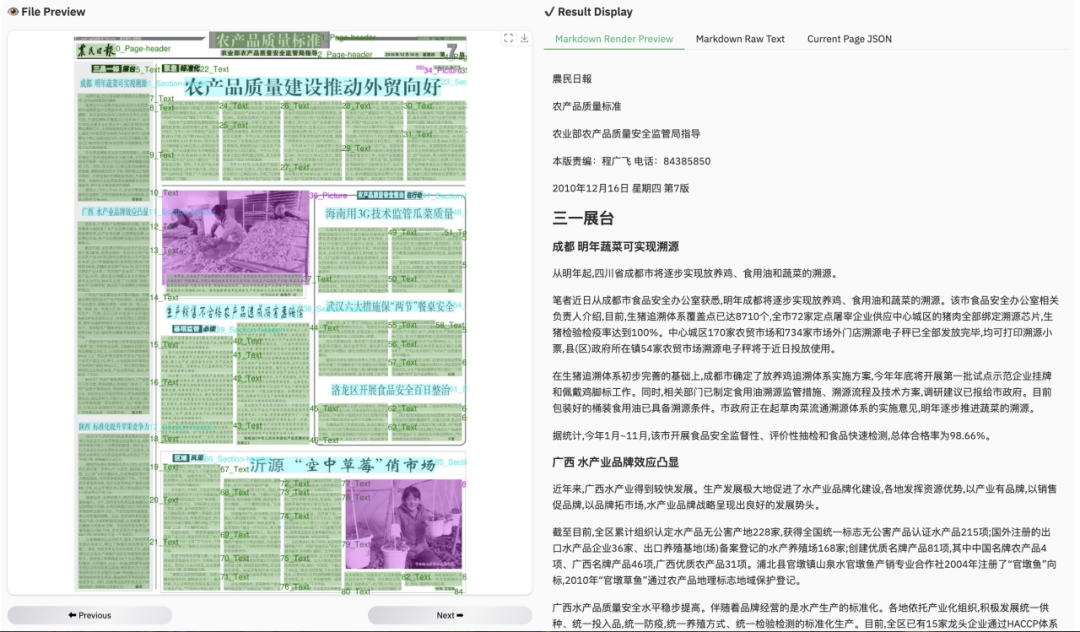
2.5 局部解析样例
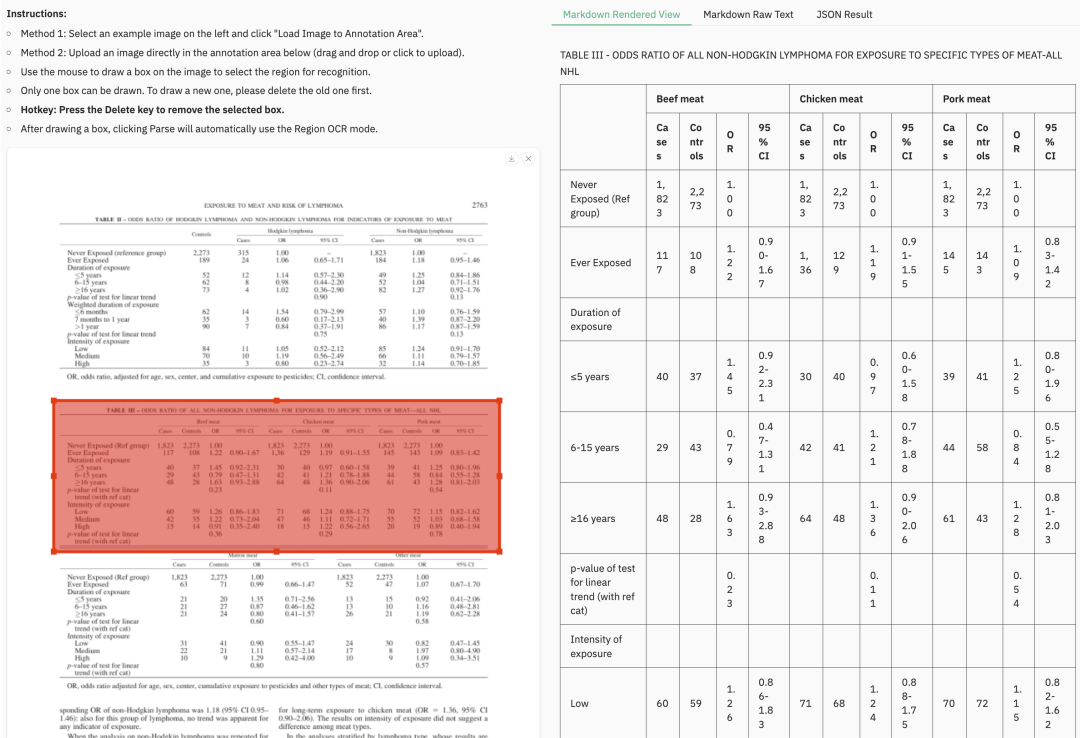
03、评测指标
3.1 OmniDocBench
不同任务的端到端指标
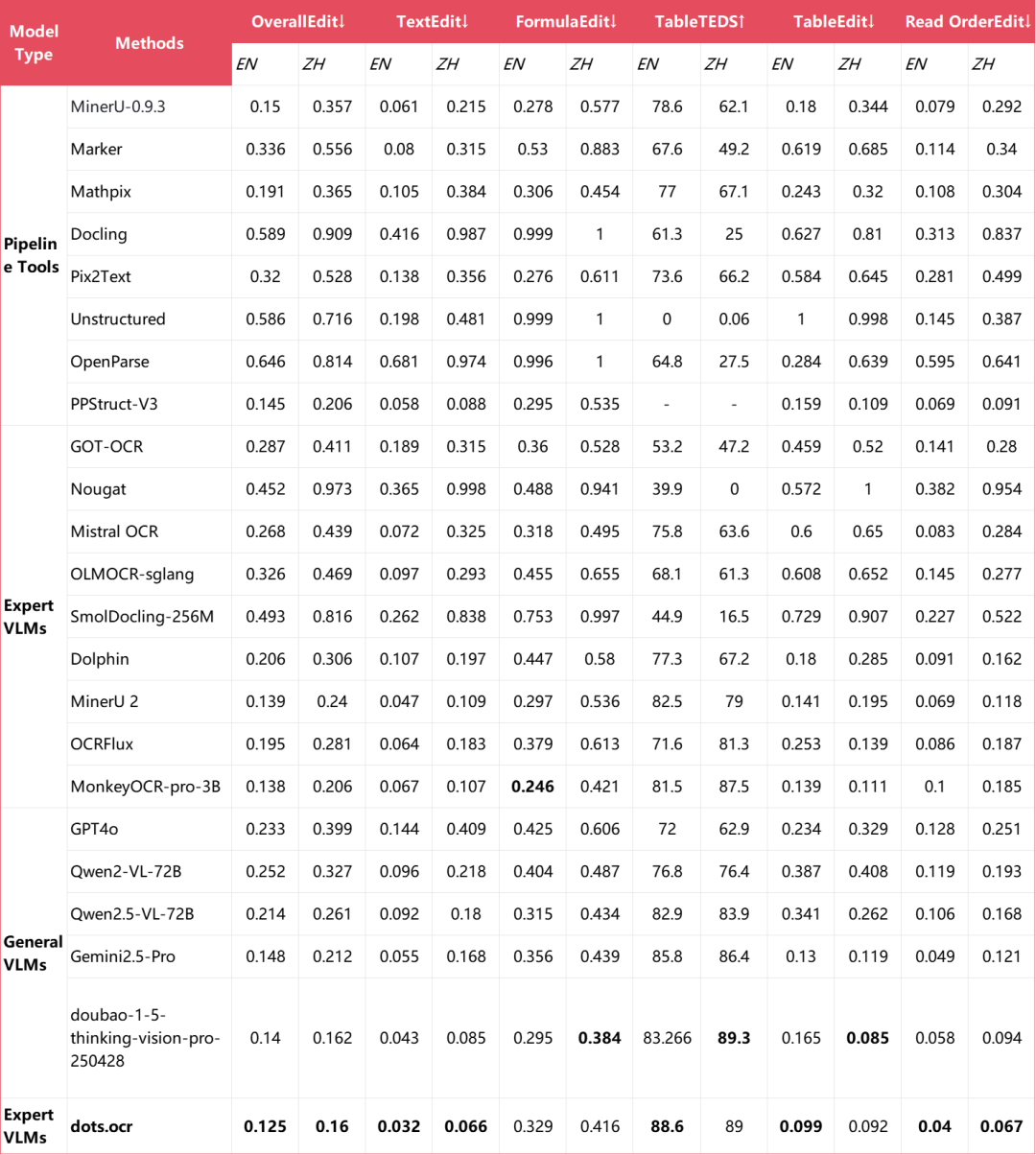
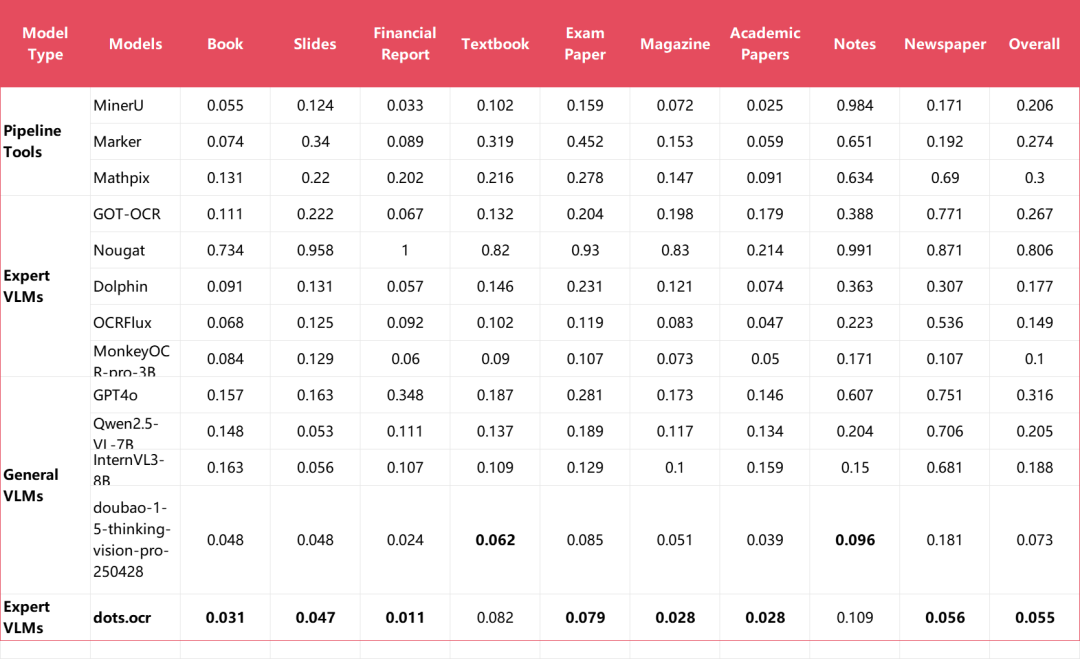
9种PDF类型的文本识别指标
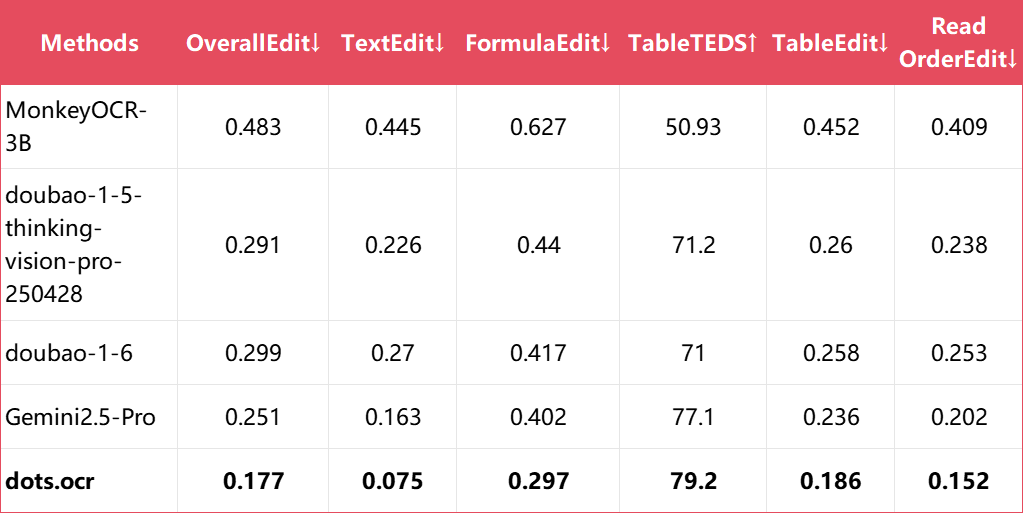
3.2 dots.ocr-bench
不同任务的端到端指标
Layout检测指标
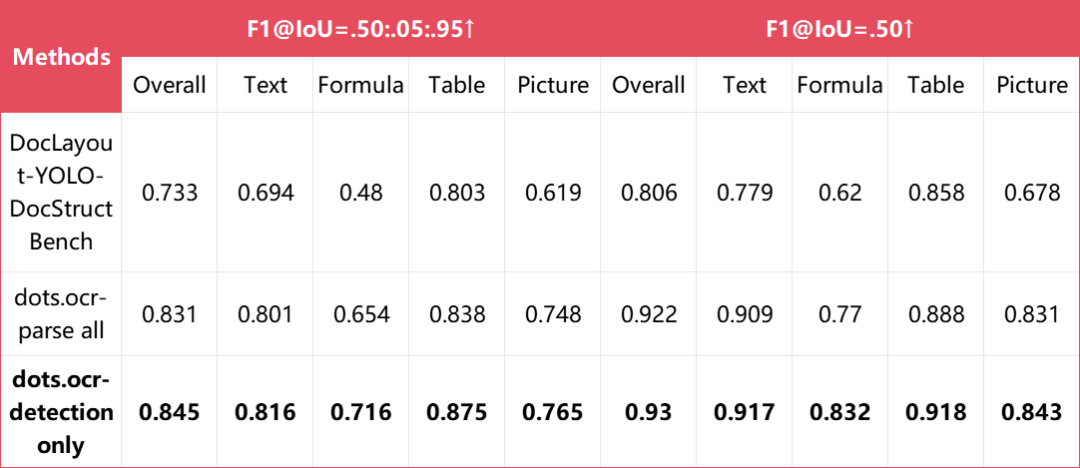
注: parse all和detection only分别使用“全量解析”和“检测only”的prompt。
3.3 olmOCR-bench
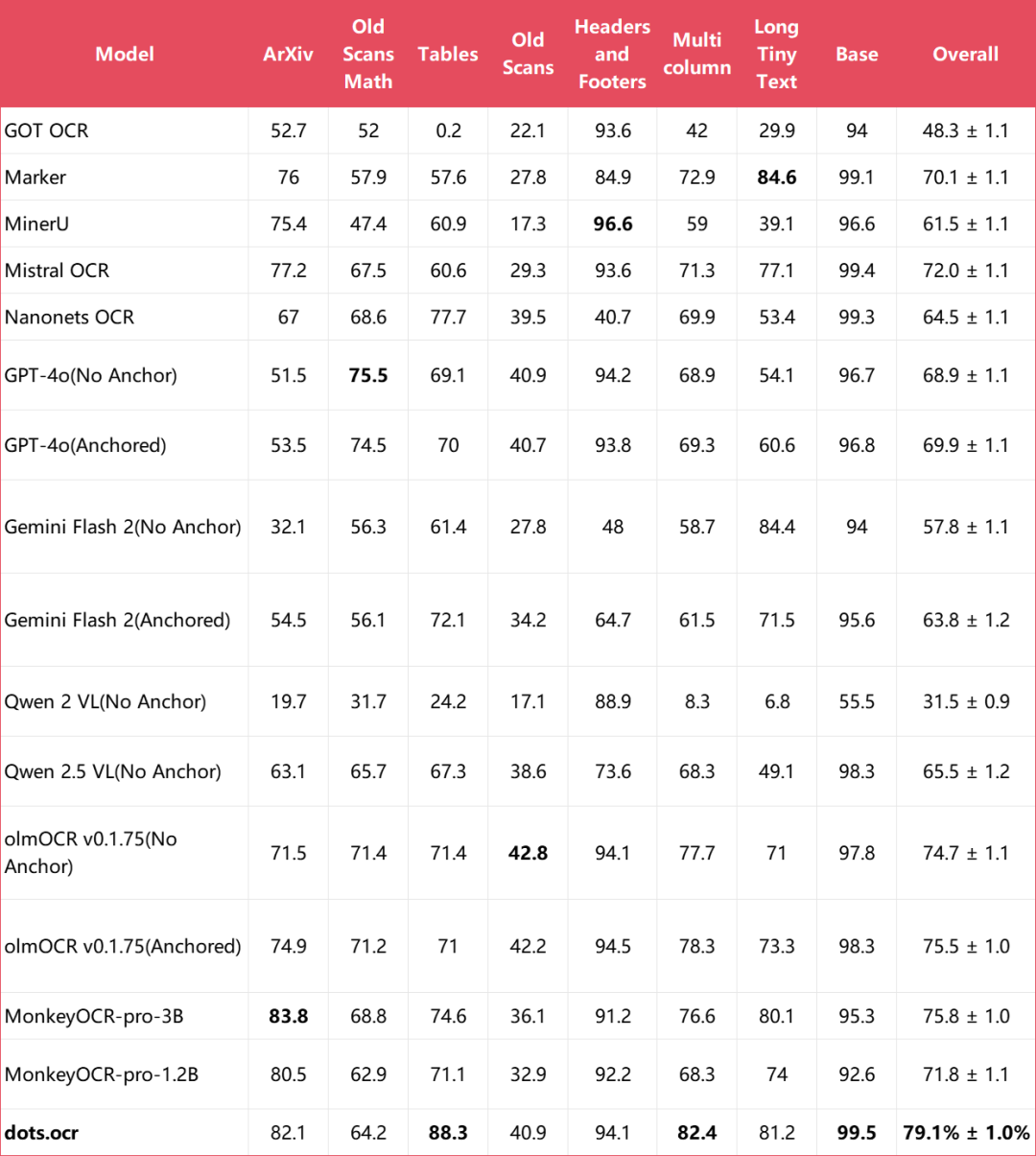
04、方法
4.1 预训练
我们通过一个三阶段的训练过程,开发了一个基座视觉语言模型(VLM):
- 阶段一:视觉编码器预训练
我们基于一个规模庞大且内容丰富的图文对数据集,从零开始训练了一个12亿参数的视觉编码器。 - 阶段二:视觉编码器持续预训练
我们采用NaViT动态分辨率架构支持高达1100万像素的高分辨率输入,同时加入了OCR、视频、定位数据(grounding data)等额外的视觉数据,我们将该视觉编码器与Qwen2.5-1.5B语言模型进行对齐,并在这些多样的视觉数据上训练,最终产出了我们的通用视觉编码器 dots.vit。 - 阶段三:VLM训练
我们使用纯OCR数据集训练。为提升训练效率,我们首先在冻结VE参数的情况下,训练一定量的tokens;随后,我们放开全部参数继续训练了1/5的token量,最终产出了我们的OCR基座模型 dots.ocr.base。
4.2 监督微调
SFT阶段采用了以下关键策略:
- 多样化的SFT数据集:我们构建了一个包含数十万样本的数据集,该数据集整合了我们内部的人工标注数据、合成数据(表格、公式、多语言OCR)以及开源数据集。
- 迭代式数据飞轮:我们采用反馈循环机制,构建了一个包含1.5万样本的内部多语言结构化layout数据集。这个过程经过了三次迭代,包含以下步骤:
- 根据模型表现,筛选出“坏样本”(bad cases)。
- 对这些样本进行人工标注。
- 将它们重新加入训练集。
- 阅读顺序:我们采用“大模型排序 + 规则后验”的方法修正了所有版面布局(layout)数据中元素框的顺序。我们发现,在数据质量和多样性足够的情况下,将元素列表按阅读顺序排列后进行训练,即可获得出色的效果。
- 质量与鲁棒性:我们构建了一个多专家系统,用于数据清洗和蒸馏,并应用了数据增强(如缩放、旋转、加噪声)来提升模型的鲁棒性。
- 多任务训练:我们利用单一的结构化布局数据源,构造不同提示词(prompts)的SFT数据。这种方法使得模型能根据提供的特定提示词,执行不同的任务,例如检测和识别。
最终得到的 dots.ocr 模型,其性能可与参数量远超于它的模型相媲美。
05、局限性和未来工作
虽然有不错的性能,但模型仍存在一些局限性和未来可改进之处:
- 复杂的文档元素:
a.表格与公式:对于高复杂度的表格和公式提取,dots.ocr 的表现尚不完美。
b.图片:目前模型还无法解析文档中的图片信息。
- 解析失败: 在特定条件下,模型可能会解析失败:
a.当字符与像素的比率过高时。建议尝试放大图片或提高PDF解析的DPI(推荐设置为200)。但请注意,模型在分辨率低于11,289,600像素的图像上表现最佳。
b.连续的特殊字符,如省略号(...)和下划线(_),可能会导致预测输出无限重复。在这种情况下,可以考虑使用其他提示词,详见github仓库。
- 性能瓶颈:
a.尽管dots.ocr基于17亿参数的LLM开发,但相对于PDF文件庞大的规模而言,它的效率仍然不够高。
未来,我们将进一步提升模型对表格和公式解析能力,并增强模型在不同场景的泛化能力,打造一个更强大、更高效的模型。此外,我们正考虑基于单视觉语言模型(VLM)完成更通用和广泛的感知任务,包括通用检测、图像描述和OCR任务等。解析文档中图片的内容也是我们未来工作的重点之一。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

