LLaMA-Factory 环境搭建学习笔记
目录
LLaMA-Factory 启动docker 容器 报错
解决方法:
如果想启动webui,我们还需要进入llamafactory容器内部。
一、Alpaca 格式(单轮对话)
🔹 示例(JSONL 格式,每行一个 JSON 对象):
🧠 含义:
🔹 示例(JSON):
🧠 含义:
LLaMA-Factory 启动docker 容器 报错
cd ~/LLaMA-Factory-main/docker/docker-cuda
docker compose up -d
报错:
ERROR load metadata for docker.io/hiyouga/pytorch:th2.6.0-cu124-flashattn2.7.4-cxx11abi0 4.0s
解决方法:
docker pull hiyouga/pytorch:th2.6.0-cu124-flashattn2.7.4-cxx11abi0-devel
然后:
docker compose up -d
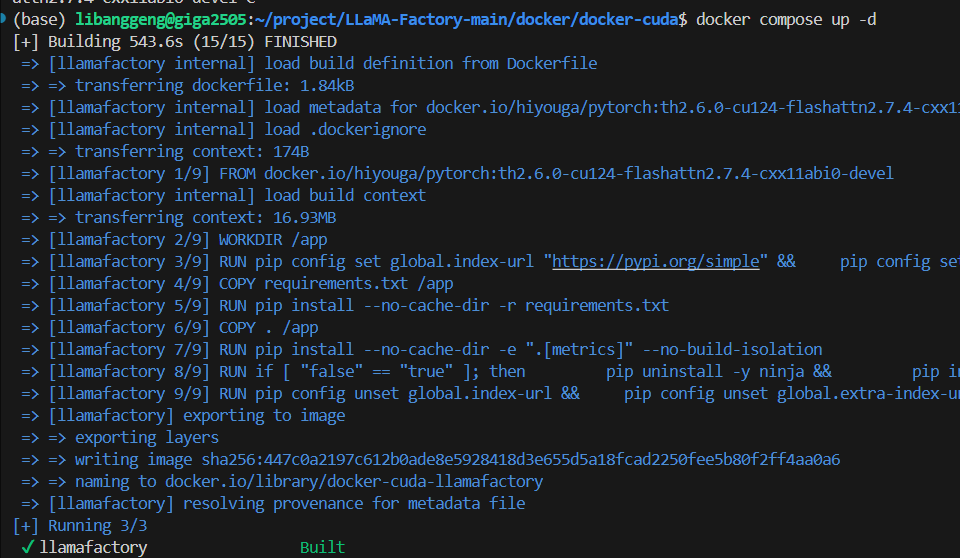
这个过程需要下载很多依赖,最终会构建一个33G左右的docker镜像。
ok的截图:
如果想启动webui,我们还需要进入llamafactory容器内部。
docker compose exec llamafactory bash然后执行
llamafactory-cli webui启动webui。
llama-factory数据格式:Alpaca格式和Sharegpt格式。
有个注意事项,就是llama-factory目前只支持两种格式的数据集。
一、Alpaca 格式(单轮对话)
特点:
-
一问一答
-
常用于 指令微调(Instruction tuning)
-
结构简单,适合监督微调(SFT)
🔹 示例(JSONL 格式,每行一个 JSON 对象):
{
\"instruction\": \"写一个 Python 函数,实现斐波那契数列。\",
\"input\": \"\",
\"output\": \"def fibonacci(n):\\n if n <= 1:\\n return n\\n return fibonacci(n-1) + fibonacci(n-2)\"
}
🧠 含义:
-
instruction: 你希望模型完成的任务(如翻译、写代码等) -
input: 可选的上下文输入,很多时候是空的 -
output: 对应的模型回答(ground truth)
✅ 二、ShareGPT 格式(多轮对话)
特点:
-
多轮对话(可以无限轮)
-
结构为一个
conversation数组 -
每轮对话包含
role(如 user / assistant) 和content
🔹 示例(JSON):
{ \"conversations\": [ {\"role\": \"user\", \"content\": \"你好,可以给我写一段 Python 代码打印 1 到 10 吗?\" }, {\"role\": \"assistant\", \"content\": \"当然可以:\\n\\n```python\\nfor i in range(1, 11):\\n print(i)\\n```\" }, {\"role\": \"user\", \"content\": \"那你能把它改成倒序输出吗?\" }, {\"role\": \"assistant\", \"content\": \"当然,这是倒序输出的版本:\\n\\n```python\\nfor i in range(10, 0, -1):\\n print(i)\\n```\" } ] }🧠 含义:
-
一组完整的问答记录,每个轮次都有明确的角色和内容
-
适合对话模型的训练(如 ChatGPT、Qwen)
🆚 Alpaca vs ShareGPT 区别对比表
instruction + input + outputconversations = [ {role, content} ]拷贝数据到路径:/LLaMA-Factory-main/data
在llama-factory添加数据集
在llama-factory添加数据集,不仅要把数据文件放到data目录下,还需要在配置文件dataset_info.json里面添加一条该数据集的记录。
然后,打开data文件夹中一个名为dataset_info.json的配置文件。
添加一条huanhuan.json的json配置,保存。
这样,我们新添加的数据集才能被llama-factory识别到。

